使用RCU技术实现读写线程无锁
在一个系统中有一个写线程和若干个读线程,读写线程通过一个指针共用了一个数据结构,写线程改写这个结构,读线程读取该结构。在写线程改写这个数据结构的过程中,加锁情况下读线程由于等待锁耗时会增加。
可以利用RCU (Read Copy Update What is rcu )的思想来去除这个锁。本文提到的主要实现代码: gist
RCU
RCU可以说是一种替代读写锁的方法。其基于一个事实:当写线程在改变一个指针时,读线程获取这个指针,要么获取到老的值,要么获取到新的值。RCU的基本思想其实很简单,参考 What is RCU 中Toy implementation可以很容易理解。一种简单的RCU流程可以描述为:
写线程:
old_ptr = _ptr tmp_ptr = copy(_ptr) // copy change(tmp_ptr) // change _ptr = tmp_ptr // update synchroize(tmp_ptr) 写线程要更新 _ptr 指向的内容时,先复制一份新的,基于新的进行改变,更新 _ptr 指针,最后同步释放老的内存。
读线程:
tmp_ptr = _ptr use(tmp_ptr) dereference(tmp_ptr) 读线程直接使用 _ptr ,使用完后需要告诉写线程自己不再使用 _ptr 。读线程获取 _ptr 时,可能会获取到老的也可能获取到新的,无论哪种RCU都需要保证这块内存是有效的。重点在 synchroize 和 dereference 。 synchroize 会等待所有使用老的 _ptr 的线程 dereference ,对于新的 _ptr 使用者其不需要等待。这个问题说白了就是写线程如何知道 old_ptr 没有任何读线程在使用,可以安全地释放。
这个问题实际上在 wait-free 的各种实现中有好些解法, how-when-to-release-memory-in-wait-free-algorithms 这里有人总结了几种方法,例如 Hazard pointers 、 Quiescence period based reclamation 。
简单地使用引用计数智能指针是无法解决这个问题的,因为智能指针自己不是线程安全的,例如:
tmp_ptr = _ptr // 1 tmp_ptr->addRef() // 2 use tmp_ptr->release() 代码1/2行不是原子的,所以当取得 tmp_ptr 准备 addRef 时, tmp_ptr 可能刚好被释放了。
Quiescence period based reclamation 方法指的是读线程需要声明自己处于 Quiescence period ,也就是不使用 _ptr 的时候,当其使用 _ptr 的时候实际是进入了一个逻辑上的临界区,当所有读线程都不再使用 _ptr 的时候,写线程就可以对内存进行安全地释放。
本文正是描述了一种 Quiescence period based reclamation 实现。这个实现可以用于有一个写线程和多个读线程共用若干个数据的场景。
实现
该方法本质上把数据同步分解为基本的内存单元读写。使用方式上可描述为:
读线程:
tmp_ptr = _ptr use update() // 标识自己不再使用任何共享数据 写线程:
old_ptr = _ptr tmp_ptr = copy(_ptr) change(tmp_ptr) _ptr = tmp_ptr gc() defer_free(old_ptr) 以下具体描述读写线程的实现。
写线程
写线程负责标识内存需要被释放,以及检查何时可以真正释放内存。其维护了一个释放内存队列:
void *_pending[8] uint64_t _head, _tail void defer_free(void *p) { _head ++ _pending[PENDING_POS(_head)] = p } gc() { for (_tail -> find_free_pos()) free(_pending[_tail]) } find_free_pos 找到一个可释放内存位置,在 [_tail, find_free_pos()) 这个区间内所有内存是可以安全被释放的。
队列位置 _head/_tail 一直增大, PENDING_POS 就是对这个位置取模,限定在队列大小范围内也是可行的,无论哪种方式, _head 从逻辑上说一直 >=_tail ,但在实际中可能小于 _tail ,所以实现时不使用大小判定,而是:
gc() { pos = find_free_pos() while (_tail != pos) { free(_pending[PENDING_POS(_tail)]) _tail ++ } }读线程
读线程不再使用共享内存时,就标识自己:
update() { static __thread int tid _tmark[tid] = _head }读线程的状态会影响写线程的回收逻辑,其状态分为:
- 初始
- 活跃,会调用到
update - 暂停,其他地方同步,或被挂起
- 退出
读线程处于活跃状态时,它会不断地更新自己可释放内存位置( _tmark[tid] )。写线程检查所有读线程的 _tmark[tid] , [_tail, min(_tmark[])) 是所有读线程都不再使用的内存区间,可以被安全释放。
find_free_pos() { min = MAX_INTEGER pos = 0 for (tid = 0; tid < max_threads; ++tid) { tpos = _tmark[tid] offset = tpos - tail if (offset < min) { min = offset pos = tpos } } return pos } 当读线程暂停时,其 _tmark[tid] 可能会在很长一段时间里得不到更新,此时会阻碍写线程释放内存。所以需要方法来标识读线程是否进入暂停状态。通过设置一个上次释放内存位置 _tfreeds[tid] ,标识每个线程当前内存释放到的位置。如果一个线程处于暂停状态了,那么在一定时间后, _tfreeds[tid] == _tmark[tid] 。在查找可释放位置时,就需要忽略暂停状态的读线程:
find_free_pos() { min = MAX_INTEGER pos = _head for (tid = 0; tid < max_threads; ++tid) { tpos = _tmark[tid] if (tpos == _tfreeds[tid]) continue offset = tpos - tail if (offset < min) { min = offset pos = tpos } } for (tid = 0; tid < max_threads; ++tid) { if (_tfreeds[tid] != _tmark[tid]) _tfreeds[tid] = pos } return pos } 但是当所有线程都处于暂停状态时,写线程可能还在工作,上面的实现就会返回 _head ,此时写线程依然可以正常释放内存。
小结,该方法原理可用下图表示:
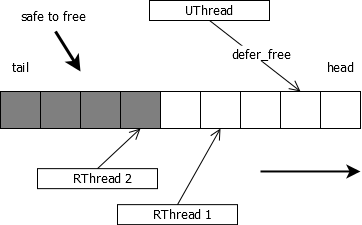
线程动态增加/减少
如果读线程可能中途退出,中途动态增加,那么 _tmark[] 就需要被复用,此时线程 tid 的分配调整为动态的即可:
class ThreadIdPool { public: // 动态获取一个线程tid,某线程每次调用该接口返回相同的值 int get() // 线程退出时回收该tid void put(int id) } ThreadIdPool 的实现无非就是利用TLS,以及在线程退出时得到通知以回收tid。那么对于读线程的 update 实现变为:
update() { tid = _idPool->get() _tmark[tid] = _head } 当某个线程退出时, _tmark[tid] 和 _tfreeds[tid] 不需要做任何处理,当新创建的线程复用了该 tid 时,可以立即复用 _tmark[tid] 和 _tfreeds[tid] ,此时这2个值必然是相等的。
以上,就是整个方法的实现。
线程可读可写
以上方法适用场景还是不够通用。在 nbds 项目(实现了一些无锁数据结构的toy project)中有一份虽然简单但也有启发的实现(rcu.c)。该实现支持任意线程 defer_free ,所有线程 update 。 update 除了声明不再使用任何共享内存外,还可能回收内存。任意线程都可能维护一些待释放的内存,任意一块内存可能被任意其他线程使用。那么它是如何内存回收的?
本文描述的方法是所有读线程自己声明自己,然后由写线程主动来检查。不同于此方法, nbds的实现,基于一种 通知扩散 的方式。该方式以这样一种方式工作:
当某个线程尝试内存回收时,它需要知道所有其他线程的空闲位置(相当于 _tmark[tid] ),它通知下一个线程我需要释放的范围。当下一个线程 update 时(离开临界区),它会将上个线程的通知继续告诉下一个线程,直到最后这个通知回到发起线程。那么对于发起线程而言,这个释放请求在所有线程中走了一遍,得到了大家的认可,可以安全释放。每个线程都以这样的方式工作。
void rcu_defer_free (void *x) { ... rcu_[next_thread_id][tid_] = rcu_last_posted_[tid_][tid_] = pending_[tid_]->head; ... } void rcu_update (void) { ... for (i = 0; i < num_threads_; ++i) { ... uint64_t x = rcu_[tid_][i]; // 其它线程发给自己的通知 rcu_[next_thread_id][i] = rcu_last_posted_[tid_][i] = x; // 扩散出去 ... } ... while (q->tail != rcu_[tid_][tid_]) { free } ... } 这个实现相对简单,不支持线程暂停,以及线程动态增加和减少。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

