写给自己的Kettle笔记7
====================www.ayjs.net 杨洋 wpfui.com ayui ay aaronyang=======请不要转载谢谢了。=========
例23 Switch/Case
输入->自定义常量
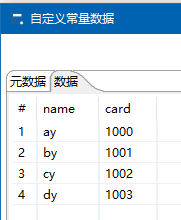
流程->Switch / Case
然后
流程->拖动4个 空操作(什么也不做)
然后双击Switch
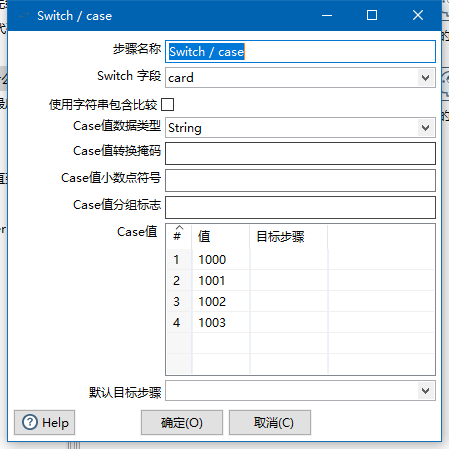
点击确定,
然后按住Shift键拖动到 条件满足后的步骤
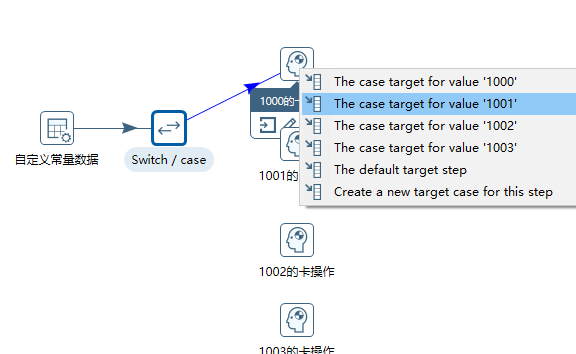
开始设置
然后再次打开Switch设置
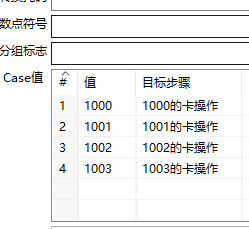
例24 识别流最后一行
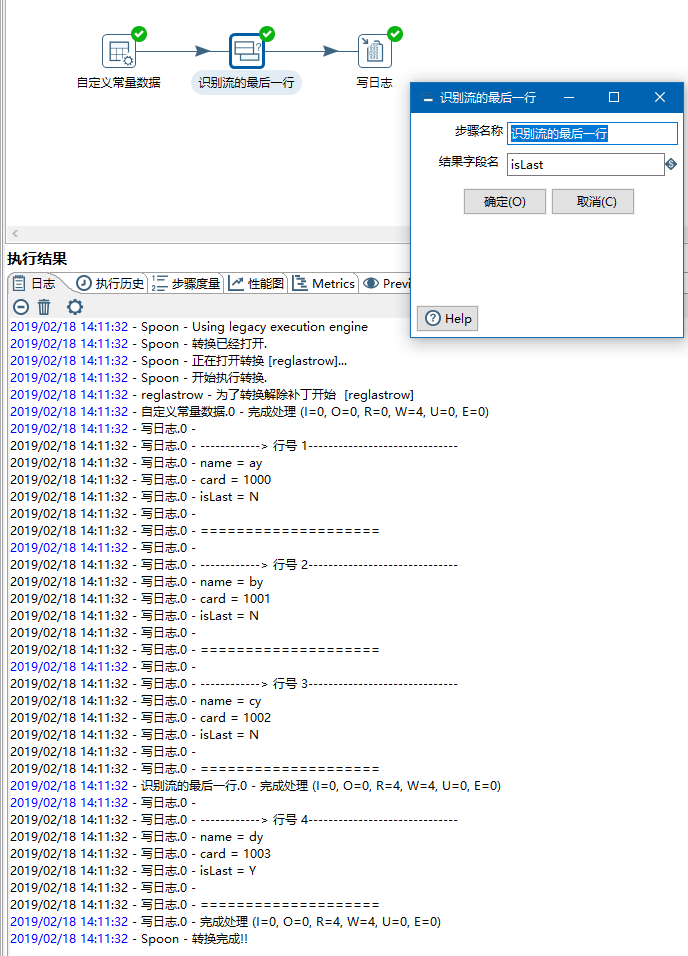
例25 过滤记录
功能:通过使用表达式从输入流中过滤数据,将结果是TURE或FALSE的流输出到不同的节点。用户可以增加多个表达式,并用AND或OR连接
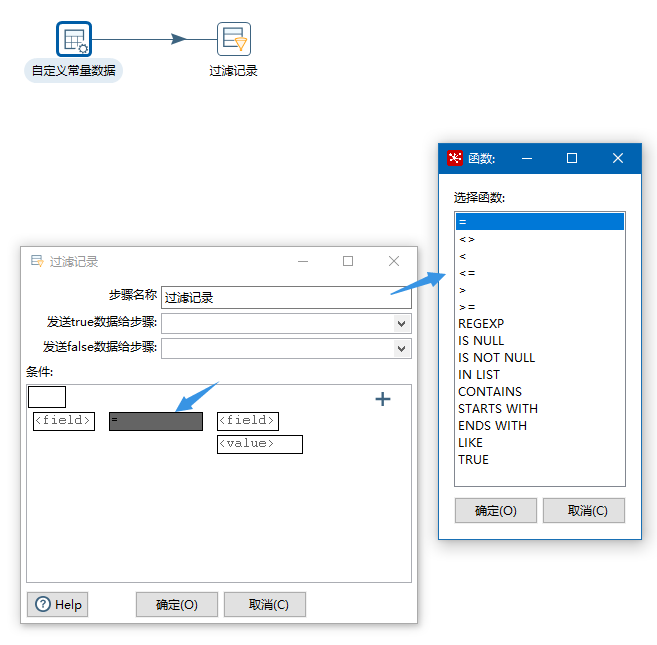
等于If的条件语句
选择字段,比较符,参考值
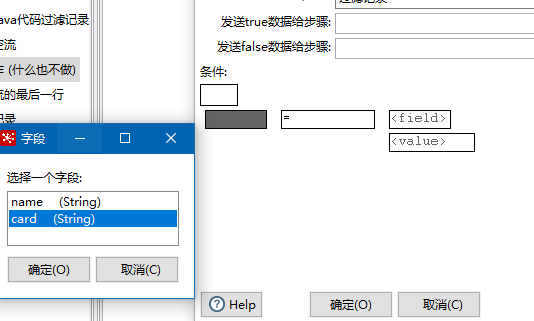
我设置的当Card等于1000时候
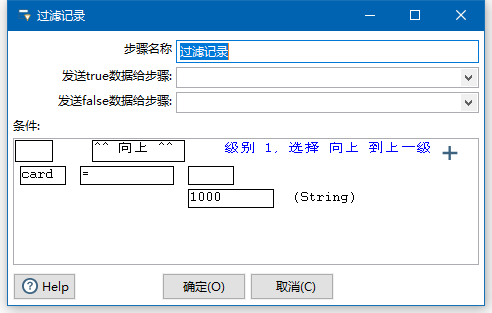
这里支持And,Or,也支持字段参考比较
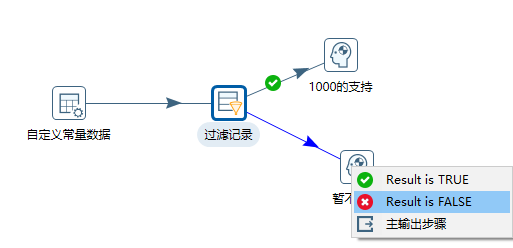
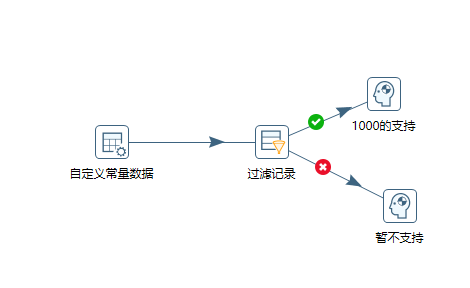
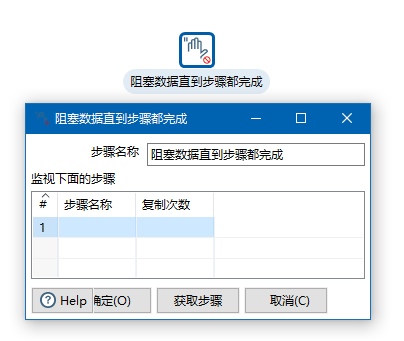
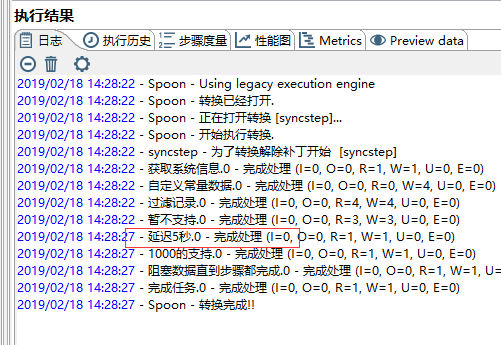
例26 阻塞数据直到步骤都完成
这里我们模拟两条执行线路
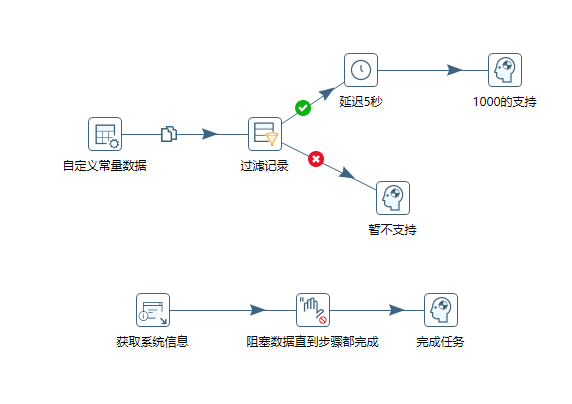
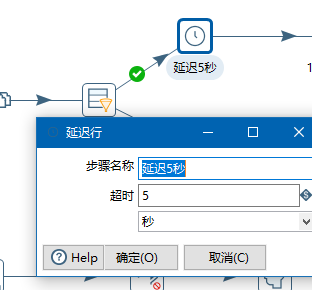
延迟5秒,是在这里
这个时候我们单击阻塞数据知道步骤都完成,可以选择要同步都完成的步骤
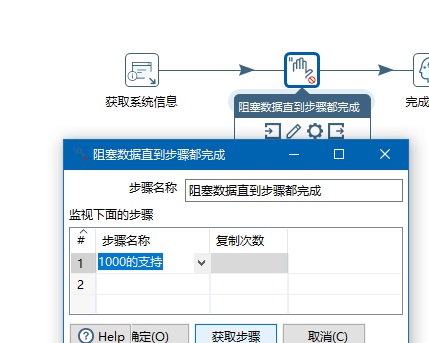
运行转换后,第二个步骤开始时候,等待1000的支持步骤完成,才会继续执行
例27 Javascript/JAVA脚本
功能描述:执行JS脚本,并且提供了很多函数
注意事项:
结果必须再赋给一个字段;
新字段的类型一定要给出,要不报错;
新字段添加为流的新列
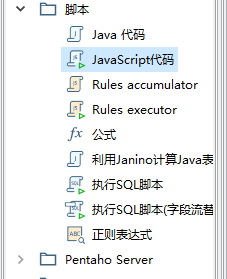
js转换时间
var datString = date2str(datOriginal, "yyyyMMdd");
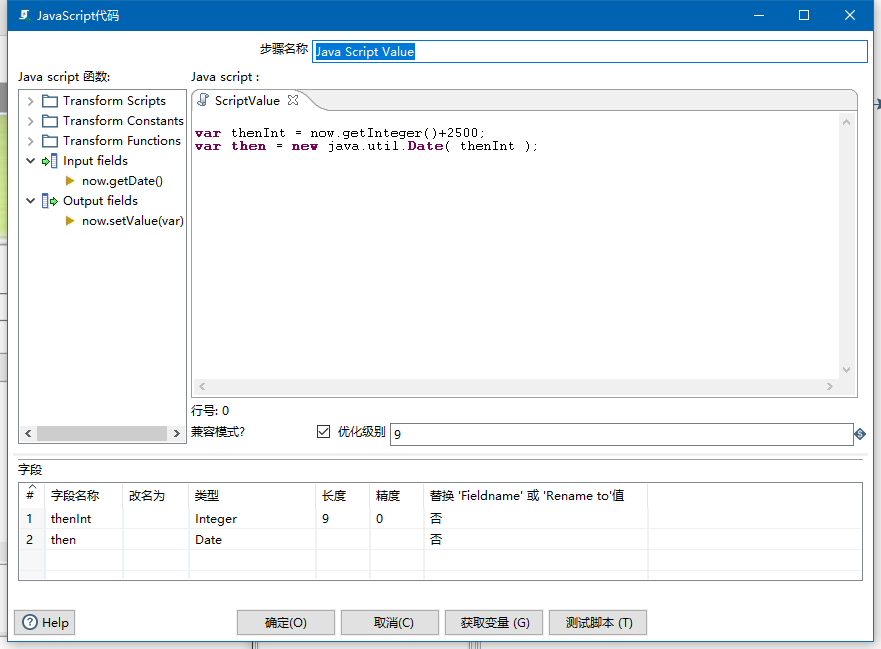
java脚本
那么也可以java过滤器
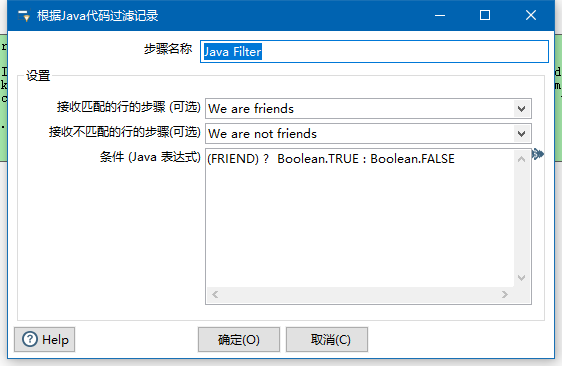
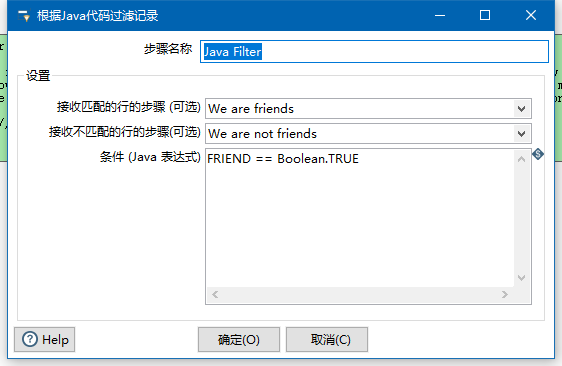
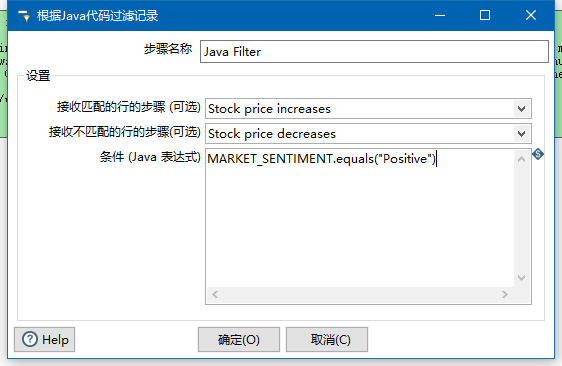
感觉就是个java中的if的条件语句编写。
例28 执行SQL脚本
包括DDL语句和DML语句,这里可以创建表
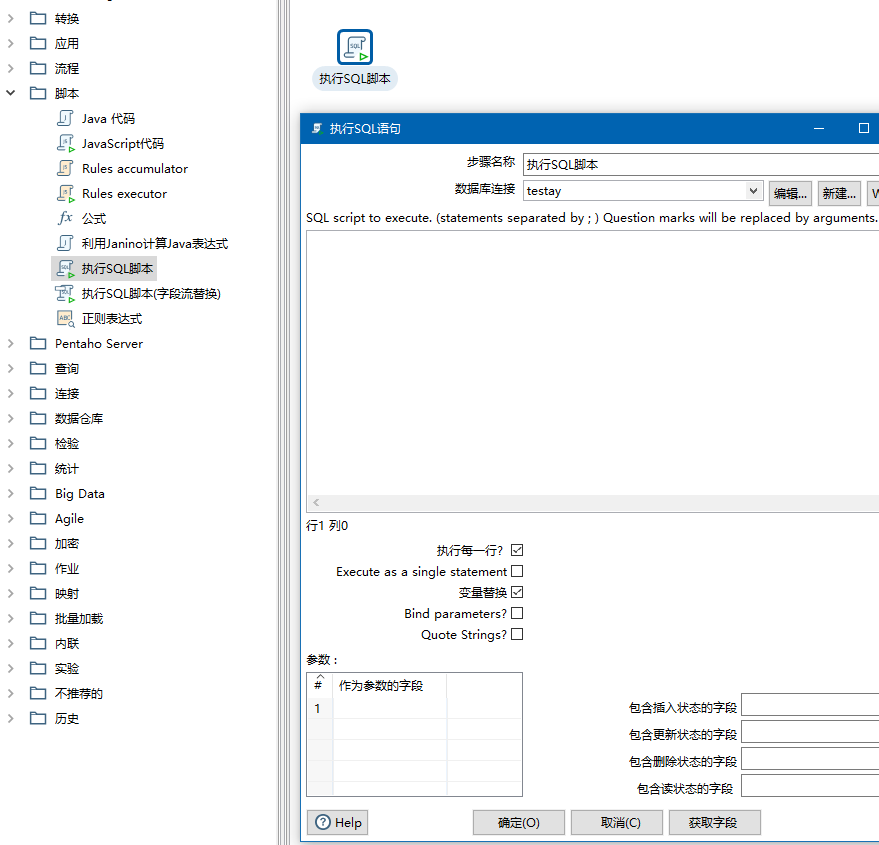
SQL语句中的第一个问号,会被下面
参数表格,按照行索引对应的字段的值替换。
检查表是否存在
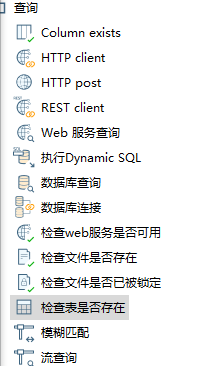
发现 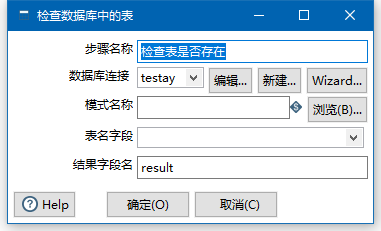 表名字段无法输入。
表名字段无法输入。
判断表是否含有某个列也无法操作
例29 调用存储过程
现在测试库,创建个存储过程
create procedure p1 @UN varchar(255) as SELECT * FROM UserInfo where Username=@UN Go
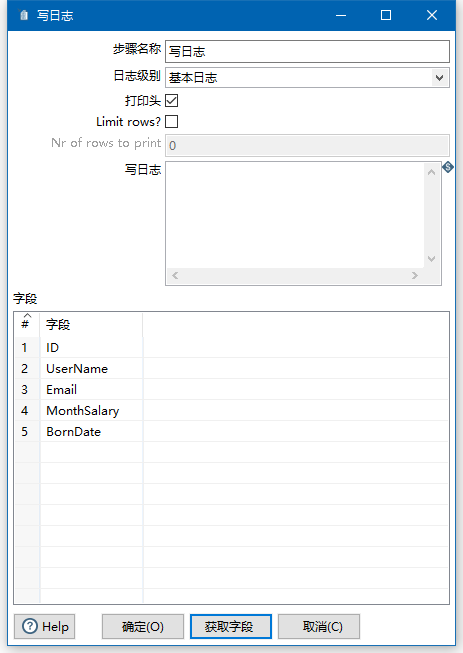
功能描述:执行存储过程并获得返回值,返回值只有一个,参数可以多个
注意事项:返回值只有一个,并且只针对函数;当调用的过程时,返回值名称要删除
如果是返回列表类型的
使用表输入
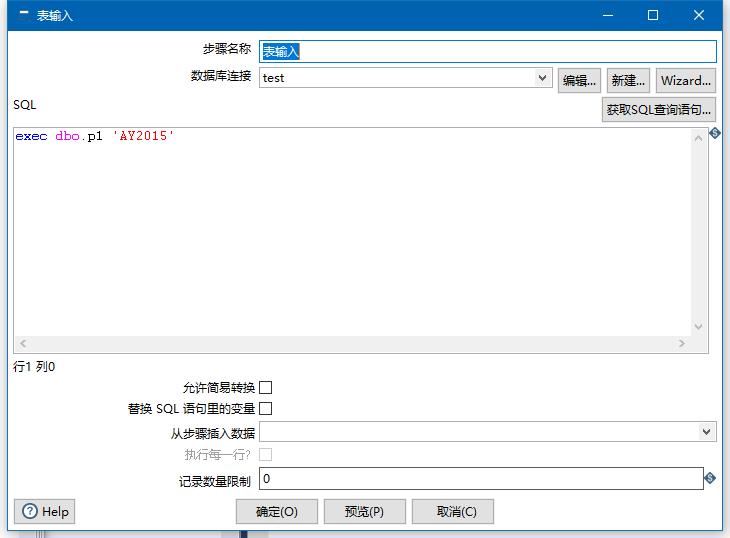
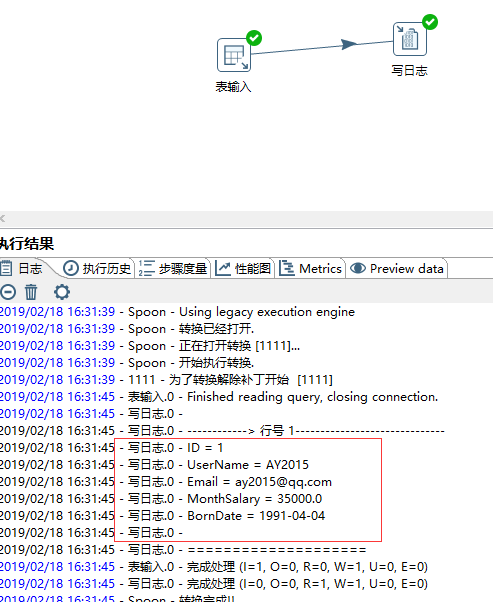
然后就可以拿到值了
如果是 不带返回值的
ALTER procedure [dbo].[p3] @id int as update UserInfo set Email='newEmail' where id=@id go
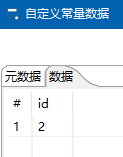
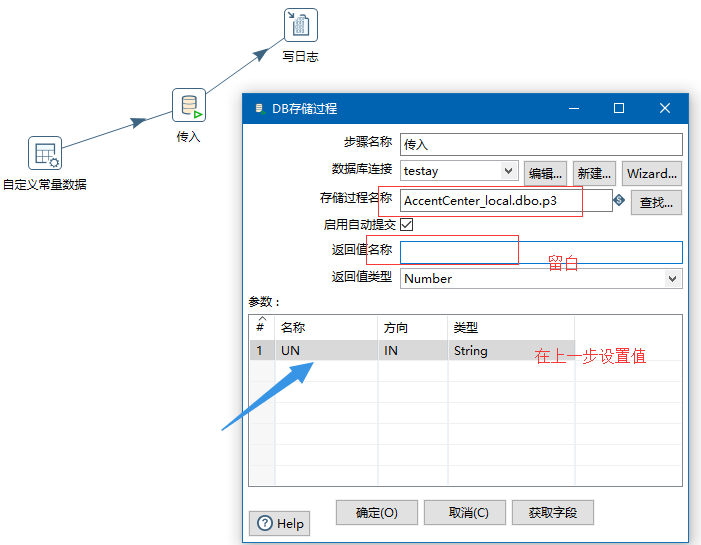
上图参数错了,修改自定义常量为id,这里名称不要太重要,为了好读,才和存储过程参数名一致的。
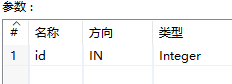
执行前
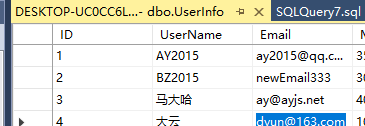
执行后,id为2的email被改了
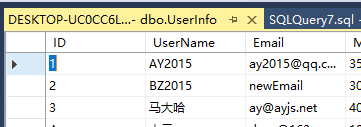
如果存储过程具有返回值
创建一个p5的存储过程
create procedure p5 @id int, @un varchar(255) output as select @un=UserName from userinfo where id=@id go
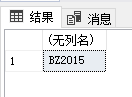
sql中执行
declare @un varchar(255) exec p5 '2',@un output select @un
那么在kettle中执行
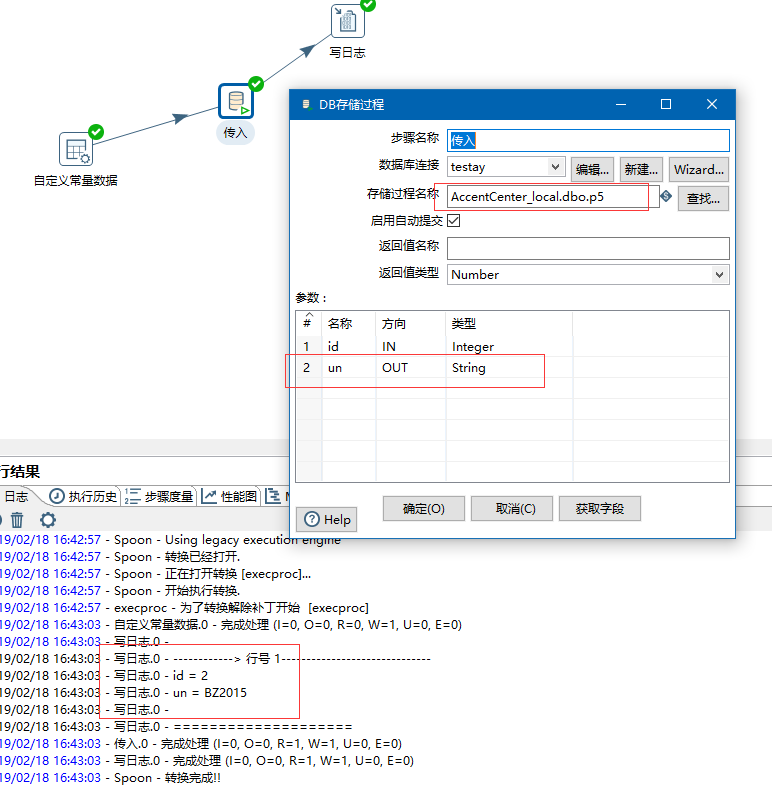
增加一个OUT的参数,这个参数是返回赋值的,不用在上一步定义。
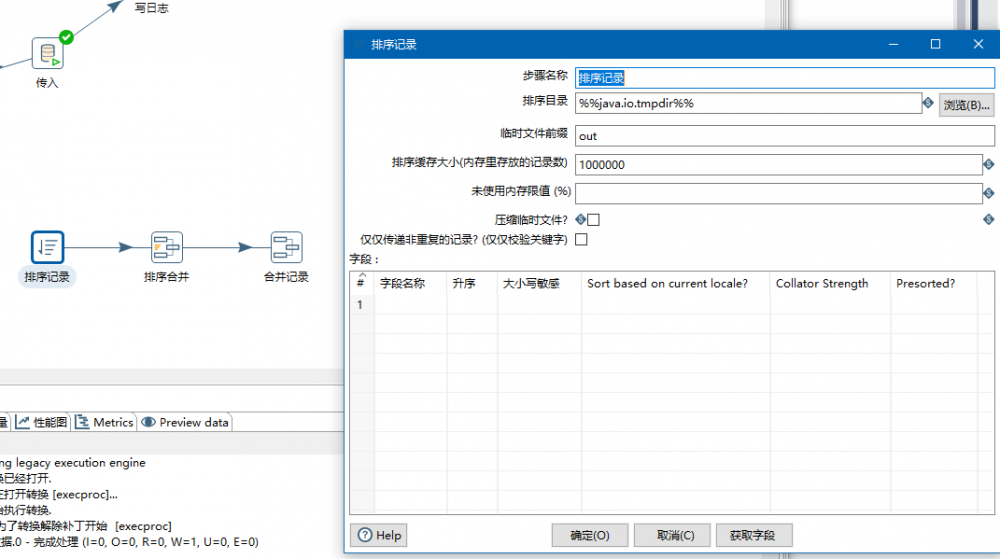
例30 连接-排序记录和排序合并(自己实践下)
数据合并记录前必须排序,否则每次同步完数据是变化的
排序后面一般跟排序合并,用于集群状态下好像
按照中文字段排序可能会有问题,所以尽量避免中文字段排序
“仅仅传递非重复的记录”就是去掉这个字段的重复的记录
(只要是这个字段的重复记录就去掉,同行的不是重复的也去掉)
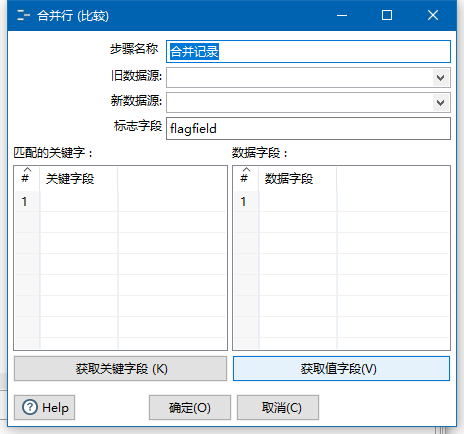
合并记录
功能描述:
用于比较两组输入数据,其中一组是引用流,一组是比较流,每次比较后只有最新版本的行数据被输出到下一步。
比较结果包括:
idectical一致:两组流的主键一致,值一致
changed有变化:两组流的主键一致,值有一个或多个不同
new新行:引用流中有而比较流中没有某一主键
deleted被删除的行:比较流中有而引用流中没有某一主键
例31
下篇博客讲解
推荐您阅读更多有关于“kettle,etl,”的文章
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

