支撑日活百万用户的高并发系统,应该如何设计其数据库架构?【石杉的架构笔记】
1.用一个创业公司的发展作为背景引入 2.用多台服务器来分库支撑高并发读写 3.大量分表来保证海量数据下查询性能 4.读写分离来支撑按需扩容及性能提升 5.高并发下的数据库架构设计总结
“ 这篇文章,我们来聊一下对于一个支撑日活百万用户的高并系统,他的数据库架构应该如何设计?
看到这个题目,很多人第一反应就是:
分库分表啊!
但是实际上,数据库层面的分库分表到底是用来干什么的,他的不同的作用如何应对不同的场景,我觉得很多同学可能都没搞清楚。
(1)用一个创业公司的发展作为背景引入
假如我们现在是一个小创业公司,注册用户就20万,每天活跃用户就1万,每天单表数据量就1000,然后高峰期每秒钟并发请求最多就10。
天哪!就这种系统,随便找一个有几年工作经验的高级工程师,然后带几个年轻工程师,随便干干都可以做出来。
因为这样的系统,实际上主要就是在前期快速的进行业务功能的开发,搞一个单块系统部署在一台服务器上,然后连接一个数据库就可以了。
接着大家就是不停的在一个工程里填充进去各种业务代码,尽快把公司的业务支撑起来,如下图所示。

结果呢,没想到我们运气这么好,碰上个优秀的CEO带着我们走上了康庄大道!
公司业务发展迅猛,过了几个月,注册用户数达到了2000万!每天活跃用户数100万!每天单表新增数据量达到50万条!高峰期每秒请求量达到1万!
同时公司还顺带着融资了两轮,估值达到了惊人的几亿美金!一只朝气蓬勃的幼年独角兽的节奏!
好吧,现在大家感觉压力已经有点大了,为啥呢?
因为每天单表新增50万条数据,一个月就多1500万条数据,一年下来单表会达到上亿条数据。
经过一段时间的运行,现在咱们单表已经两三千万条数据了,勉强还能支撑着。
但是,眼见着系统访问数据库的性能怎么越来越差呢,单表数据量越来越大,拖垮了一些复杂查询SQL的性能啊!
然后高峰期请求现在是每秒1万,咱们的系统在线上部署了20台机器,平均每台机器每秒支撑500请求,这个还能抗住,没啥大问题。
但是数据库层面呢?
如果说此时你还是一台数据库服务器在支撑每秒上万的请求,负责任的告诉你,每次高峰期会出现下述问题:
你的数据库服务器的磁盘IO、网络带宽、CPU负载、内存消耗,都会达到非常高的情况,数据库所在服务器的整体负载会非常重,甚至都快不堪重负了
高峰期时,本来你单表数据量就很大,SQL性能就不太好,这时加上你的数据库服务器负载太高导致性能下降,就会发现你的SQL性能更差了
最明显的一个感觉,就是你的系统在高峰期各个功能都运行的很慢,用户体验很差,点一个按钮可能要几十秒才出来结果
如果你运气不太好,数据库服务器的配置不是特别的高的话,弄不好你还会经历数据库宕机的情况,因为负载太高对数据库压力太大了
(2)多台服务器分库支撑高并发读写
首先我们先考虑第一个问题,数据库每秒上万的并发请求应该如何来支撑呢?
要搞清楚这个问题,先得明白一般数据库部署在什么配置的服务器上。
通常来说,假如你用普通配置的服务器来部署数据库,那也起码是16核32G的机器配置。
这种非常普通的机器配置部署的数据库,一般线上的经验是:不要让其每秒请求支撑超过2000,一般控制在2000左右。
控制在这个程度,一般数据库负载相对合理,不会带来太大的压力,没有太大的宕机风险。
所以首先第一步,就是在上万并发请求的场景下,部署个5台服务器,每台服务器上都部署一个数据库实例。
然后每个数据库实例里,都创建一个一样的库,比如说订单库。
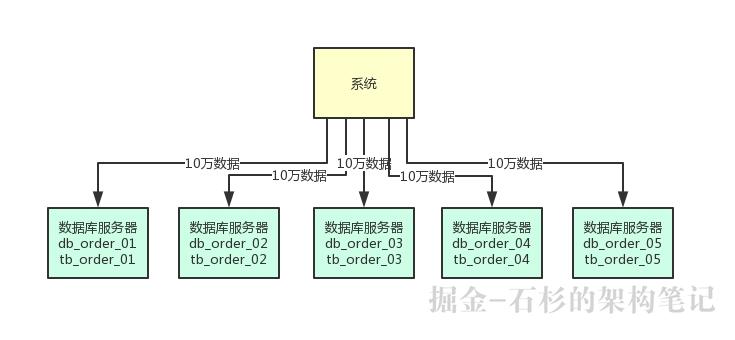
此时在5台服务器上都有一个订单库,名字可以类似为:db_order_01,db_order_02,等等。
然后每个订单库里,都有一个相同的表,比如说订单库里有订单信息表,那么此时5个订单库里都有一个订单信息表。
比如db_order_01库里就有一个tb_order_01表,db_order_02库里就有一个tb_order_02表。
这就实现了一个基本的分库分表的思路,原来的一台数据库服务器变成了5台数据库服务器,原来的一个库变成了5个库,原来的一张表变成了5个表。
然后你在写入数据的时候,需要借助数据库中间件,比如sharding-jdbc,或者是mycat,都可以。
你可以根据比如订单id来hash后按5取模,比如每天订单表新增50万数据,此时其中10万条数据会落入db_order_01库的tb_order_01表,另外10万条数据会落入db_order_02库的tb_order_02表,以此类推。
这样就可以把数据均匀分散在5台服务器上了,查询的时候,也可以通过订单id来hash取模,去对应的服务器上的数据库里,从对应的表里查询那条数据出来即可。
依据这个思路画出的图如下所示,大家可以看看。
做这一步有什么好处呢?
第一个好处,原来比如订单表就一张表,这个时候不就成了5张表了么,那么每个表的数据就变成1/5了。
假设订单表一年有1亿条数据,此时5张表里每张表一年就2000万数据了。
那么假设当前订单表里已经有2000万数据了,此时做了上述拆分,每个表里就只有400万数据了。
而且每天新增50万数据的话,那么每个表才新增10万数据,这样是不是初步缓解了单表数据量过大影响系统性能的问题?
另外就是每秒1万请求到5台数据库上,每台数据库就承载每秒2000的请求,是不是一下子把每台数据库服务器的并发请求降低到了安全范围内?
这样,降低了数据库的高峰期负载,同时还保证了高峰期的性能。
(3)大量分表来保证海量数据下的查询性能
但是上述的数据库架构还有一个问题,那就是单表数据量还是过大,现在订单表才分为了5张表,那么如果订单一年有1亿条,每个表就有2000万条,这也还是太大了。
所以还应该继续分表,大量分表。
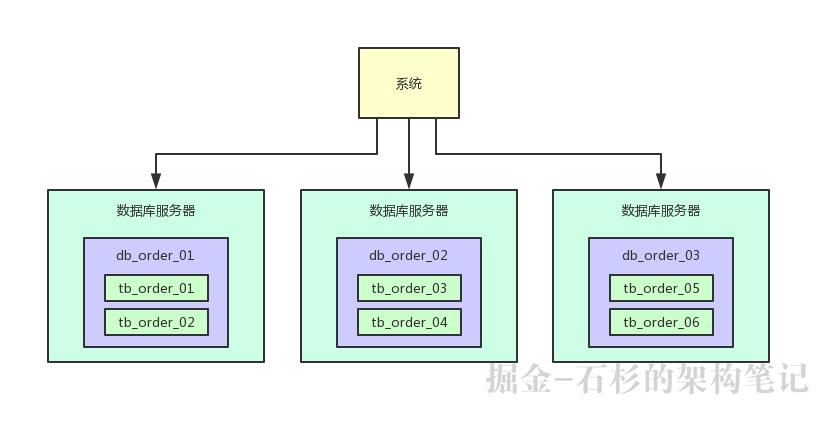
比如可以把订单表一共拆分为1024张表,这样1亿数据量的话,分散到每个表里也就才10万量级的数据量,然后这上千张表分散在5台数据库里就可以了。
在写入数据的时候,需要做两次路由,先对订单id hash后对数据库的数量取模,可以路由到一台数据库上,然后再对那台数据库上的表数量取模,就可以路由到数据库上的一个表里了。
通过这个步骤,就可以让每个表里的数据量非常小,每年1亿数据增长,但是到每个表里才10万条数据增长,这个系统运行10年,每个表里可能才百万级的数据量。
这样可以一次性为系统未来的运行做好充足的准备,看下面的图,一起来感受一下:
(4)读写分离来支撑按需扩容以及性能提升
这个时候整体效果已经挺不错了,大量分表的策略保证可能未来10年,每个表的数据量都不会太大,这可以保证单表内的SQL执行效率和性能。
然后多台数据库的拆分方式,可以保证每台数据库服务器承载一部分的读写请求,降低每台服务器的负载。
但是此时还有一个问题,假如说每台数据库服务器承载每秒2000的请求,然后其中400请求是写入,1600请求是查询。
也就是说,增删改的SQL才占到了20%的比例,80%的请求是查询。
此时假如说随着用户量越来越大,假如说又变成每台服务器承载4000请求了。
那么其中800请求是写入,3200请求是查询,如果说你按照目前的情况来扩容,就需要增加一台数据库服务器.
但是此时可能就会涉及到表的迁移,因为需要迁移一部分表到新的数据库服务器上去,是不是很麻烦?
其实完全没必要,数据库一般都支持读写分离,也就是做主从架构。
写入的时候写入主数据库服务器,查询的时候读取从数据库服务器,就可以让一个表的读写请求分开落地到不同的数据库上去执行。
这样的话,假如写入主库的请求是每秒400,查询从库的请求是每秒1600,那么图大概如下所示。
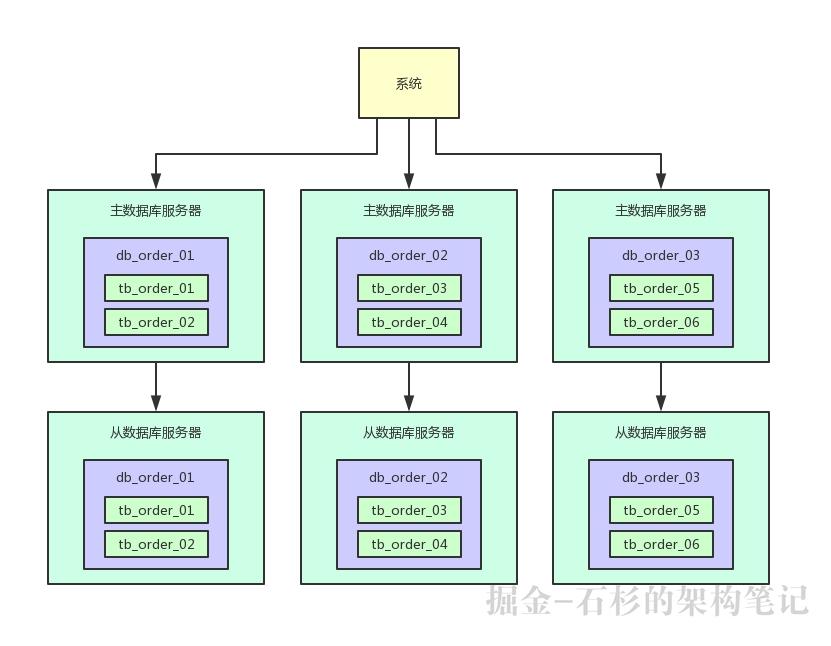
写入主库的时候,会自动同步数据到从库上去,保证主库和从库数据一致。
然后查询的时候都是走从库去查询的,这就通过数据库的主从架构实现了读写分离的效果了。
现在的好处就是,假如说现在主库写请求增加到800,这个无所谓,不需要扩容。然后从库的读请求增加到了3200,需要扩容了。
这时,你直接给主库再挂载一个新的从库就可以了,两个从库,每个从库支撑1600的读请求,不需要因为读请求增长来扩容主库。
实际上线上生产你会发现,读请求的增长速度远远高于写请求,所以读写分离之后,大部分时候就是扩容从库支撑更高的读请求就可以了。
而且另外一点,对同一个表,如果你既写入数据(涉及加锁),还从该表查询数据,可能会牵扯到锁冲突等问题,无论是写性能还是读性能,都会有影响。
所以一旦读写分离之后,对主库的表就仅仅是写入,没任何查询会影响他,对从库的表就仅仅是查询。
(5)高并发下的数据库架构设计总结
其实从大的一个简化的角度来说,高并发的场景下,数据库层面的架构肯定是需要经过精心的设计的。
尤其是涉及到分库来支撑高并发的请求,大量分表保证每个表的数据量别太大,读写分离实现主库和从库按需扩容以及性能保证。
这篇文章就是从一个大的角度来梳理了一下思路,各位同学可以结合自己公司的业务和项目来考虑自己的系统如何做分库分表应该怎么做。
另外就是,具体的分库分表落地的时候,需要借助数据库中间件来实现分库分表和读写分离,大家可以自己参考 sharding-jdbc 或者 mycat 的官网即可,里面的文档都有详细的使用描述。
(封面图源网络,侵权删除)
END
扫描下方二维码,备注:“ 资料 ”,获取更多“ 秘制 ” 精品学习资料

如有收获,请帮忙转发,您的鼓励是作者最大的动力,谢谢!
一大波微服务、分布式、高并发、高可用的原创系列文章正在路上
欢迎扫描下方二维码,持续关注:

石杉的架构笔记(id:shishan100)
十余年BAT架构经验倾囊相授
推荐阅读:
1、 拜托!面试请不要再问我Spring Cloud底层原理
2、 【双11狂欢的背后】微服务注册中心如何承载大型系统的千万级访问?
3、 【性能优化之道】每秒上万并发下的Spring Cloud参数优化实战
4、 微服务架构如何保障双11狂欢下的99.99%高可用
5、 兄弟,用大白话告诉你小白都能听懂的Hadoop架构原理
6、 大规模集群下Hadoop NameNode如何承载每秒上千次的高并发访问
7、 【性能优化的秘密】Hadoop如何将TB级大文件的上传性能优化上百倍
8、 拜托,面试请不要再问我TCC分布式事务的实现原理!
9、 【坑爹呀!】最终一致性分布式事务如何保障实际生产中99.99%高可用?
10、 拜托,面试请不要再问我Redis分布式锁的实现原理!
11、 【眼前一亮!】看Hadoop底层算法如何优雅的将大规模集群性能提升10倍以上?
12、 亿级流量系统架构之如何支撑百亿级数据的存储与计算
13、 亿级流量系统架构之如何设计高容错分布式计算系统
14、 亿级流量系统架构之如何设计承载百亿流量的高性能架构
15、 亿级流量系统架构之如何设计每秒十万查询的高并发架构
16、 亿级流量系统架构之如何设计全链路99.99%高可用架构
17、 七张图彻底讲清楚ZooKeeper分布式锁的实现原理
18、 大白话聊聊Java并发面试问题之volatile到底是什么?
19、 大白话聊聊Java并发面试问题之Java 8如何优化CAS性能?
20、 大白话聊聊Java并发面试问题之谈谈你对AQS的理解?
21、 大白话聊聊Java并发面试问题之公平锁与非公平锁是啥?
22、 大白话聊聊Java并发面试问题之微服务注册中心的读写锁优化
23、 互联网公司的面试官是如何360°无死角考察候选人的?(上篇)
24、 互联网公司面试官是如何360°无死角考察候选人的?(下篇)
25、 Java进阶面试系列之一:哥们,你们的系统架构中为什么要引入消息中间件?
26、 【Java进阶面试系列之二】:哥们,那你说说系统架构引入消息中间件有什么缺点?
27、 【行走的Offer收割机】记一位朋友斩获BAT技术专家Offer的面试经历
28、 【Java进阶面试系列之三】哥们,消息中间件在你们项目里是如何落地的?
29、 【Java进阶面试系列之四】扎心!线上服务宕机时,如何保证数据100%不丢失?
30、 一次JVM FullGC的背后,竟隐藏着惊心动魄的线上生产事故!
31、 【高并发优化实践】10倍请求压力来袭,你的系统会被击垮吗?
32、 【Java进阶面试系列之五】消息中间件集群崩溃,如何保证百万生产数据不丢失?
33、 亿级流量系统架构之如何在上万并发场景下设计可扩展架构(上)?
34、 亿级流量系统架构之如何在上万并发场景下设计可扩展架构(中)?
35、 亿级流量系统架构之如何在上万并发场景下设计可扩展架构(下)?
36、 亿级流量架构第二弹:你的系统真的无懈可击吗?
37、 亿级流量系统架构之如何保证百亿流量下的数据一致性(上)
38、 亿级流量系统架构之如何保证百亿流量下的数据一致性(中)?
39、 亿级流量系统架构之如何保证百亿流量下的数据一致性(下)?
40、 互联网面试必杀:如何保证消息中间件全链路数据100%不丢失(1)
41、 互联网面试必杀:如何保证消息中间件全链路数据100%不丢失(2 )
42、 面试大杀器:消息中间件如何实现消费吞吐量的百倍优化?
43、 高并发场景下,如何保证生产者投递到消息中间件的消息不丢失?
44、 兄弟,用大白话给你讲小白都能看懂的分布式系统容错架构
45、 从团队自研的百万并发中间件系统的内核设计看Java并发性能优化
46、 【非广告,纯干货】英语差的程序员如何才能无障碍阅读官方文档?
47、 如果20万用户同时访问一个热点缓存,如何优化你的缓存架构?
48、 【非广告,纯干货】中小公司的Java工程师应该如何逆袭冲进BAT?
49、 拜托,面试请不要再问我分布式搜索引擎的架构原理!
50、 【金三银四跳槽季】Java工程师如何在1个月内做好面试准备?
51、 【offer收割机必备】我简历上的Java项目都好low,怎么办?
52、 【offer去哪了】我一连面试了十个Java岗,统统石沉大海!
作者:石杉的架构笔记 链接: juejin.im/post/5c263a… 来源:掘金 著作权归作者所有,转载请联系作者获得授权!
正文到此结束
- 本文标签: 高并发 架构设计 微服务 node 广告 安全 代码 参数 http 分布式 sharding 缓存 Hadoop 数据库 双11 redis 二维码 src 分布式锁 JDBC 服务器 事故 Namenode 数据 分布式事务 同步 id 性能优化 JVM java 创业 集群 UI 实例 主从架构 工程师 索引 spring 搜索引擎 系统架构 程序员 总结 IO 一致性 服务注册 https cat 配置 CEO 锁 SQL执行 分布式系统 注册中心 部署 cpu负载 互联网 sql 创业公司 volatile 文章 高可用 Spring cloud 并发 db 压力 zookeeper 时间 开发 删除
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

