前端工程化:围绕Jenkins打造工作流的过程
1年前入职时,公司前端部门的静态代码部署都是用ftp工具拖拽部署,没有记录,没有关联,经常造成许多困扰的问题,
比如:今天有没有其他人在我要部署的路径上工作?我的代码为啥被盖掉了?被谁盖掉的?啥时候盖掉的?
本地build,ftp拖拽部署这种方式,导致git版本与手动的构建、部署没啥关联,更有在本地写完代码部署上去后,压根没传git这种失误可能发生。
靠人去遵守规范来控制工作流,总会有失误、疏忽的发生。
想法
要靠机器和代码去规范工作流,提高效率、准确性,实现真正的前端工程化。
具体目标
不讨论通用模板(项目开发层面),只关心构建以后的事情,精确的说,就是从npm run build:xxx 这个脚本开始对接,npm run build:xxx之前的事情不在本文讨论范围内。 实现构建-部署-测试(多个环境)-沙箱-上线(可回滚)的全部半自动化流程把控。
为什么选择jenkins:优先选择强大的开源工具,避免重复造轮子,主要原因是插件特别丰富,基本可以满足所有实际需求
先把成果贴上来, 整体示意图
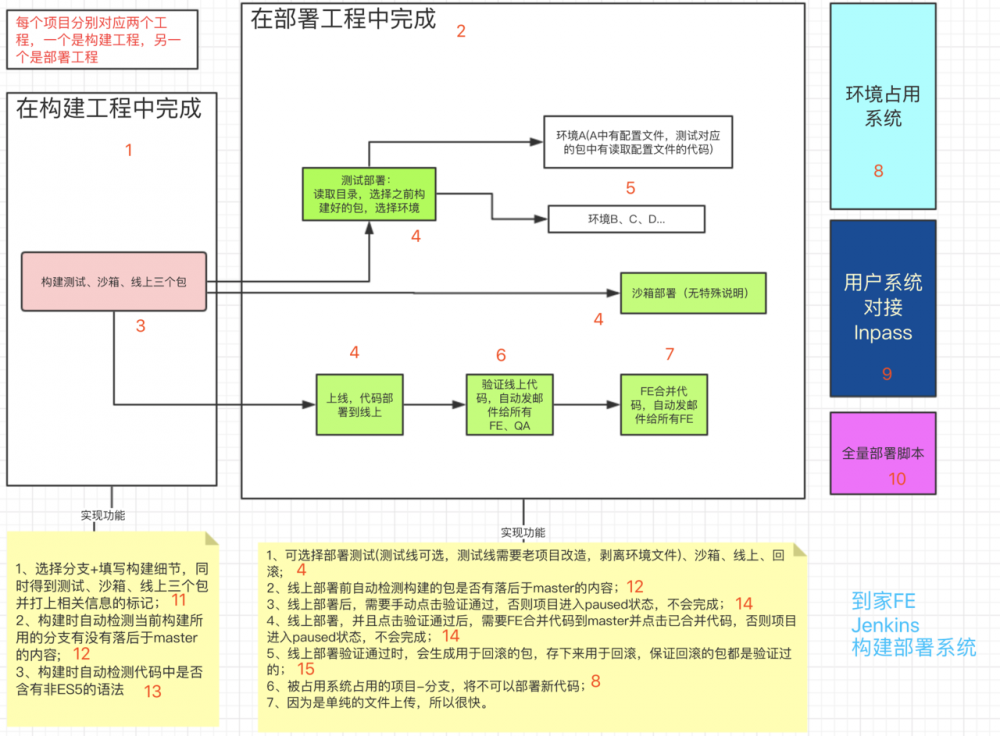
核心思想是分离构建、部署,所以每个项目,jenkins会建两个job。
jenkins服务部署在公司内网堡垒机上,使用tomcat管理jenkins的war包,占用系统服务、全量部署定时任务都跑在同一台堡垒机上(Linux)。
因为内容很多,所以我直接采用一张图 + 注释 来零碎的讲解每个功能的实现,因为每个公司的前端业务环境都不一样,所以我也不打算花太大的笔墨去描述所有的实现。写这篇文章的目的就是可能某个思想、某一段对jenkins插件的使用等等会帮助到有类似需求的人。 注释会是截图,或者是关键代码,对应图中的数字 。
先放几张实际使用的图
jenkins项目界面部分截图
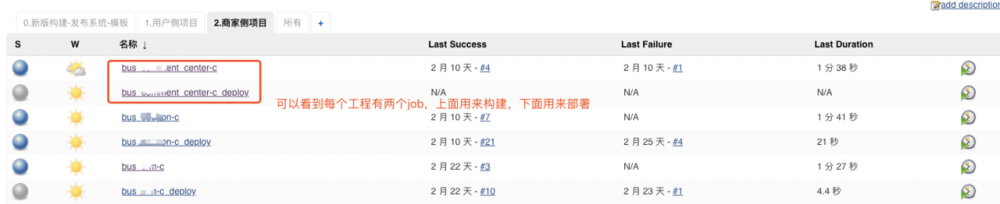
构建job部分截图

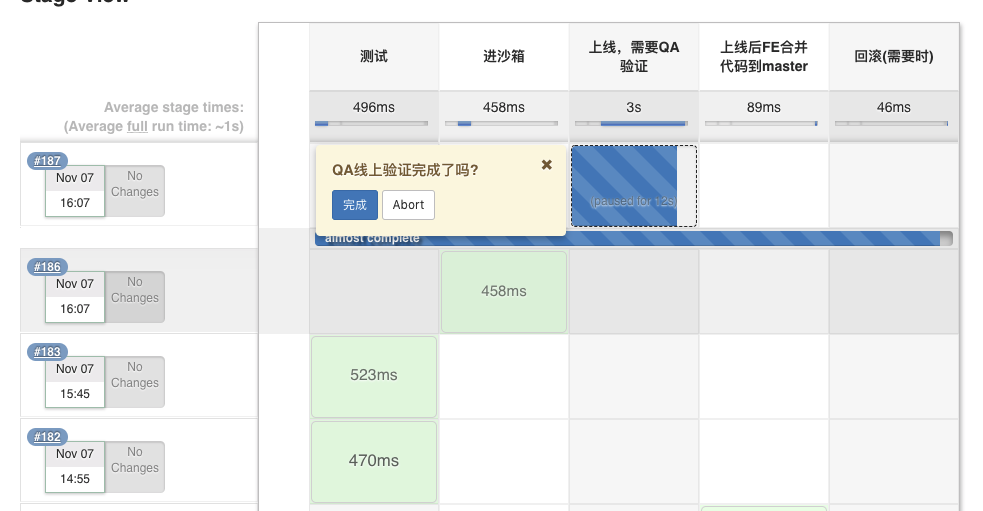
部署job部分截图(使用jenkins-pipeline实现流程图)
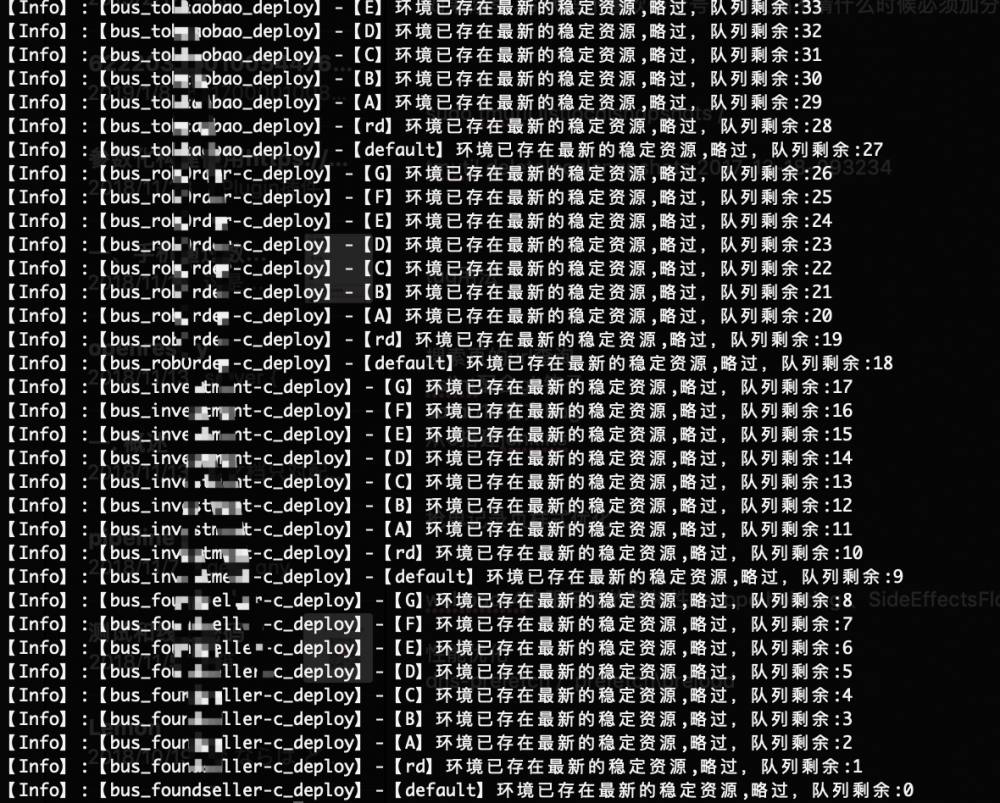
多套测试环境占用系统部分截图(占用环境后别人无法部署,全量脚本也不会覆盖)

全量部署脚本日志展示部分截图
整体示意图的注释(每一条都对应示意图中的红色阿拉伯数字):
- 构建和部署分离开来,便于后续的各种操作,比如全量部署、分环境部署、回滚代码等都是不需要构建操作的,耦合在一起会做很多无用功。
- 同上
- 一次构建三个包,保证了测试环境和沙箱、线上的构建环境/副作用参数的一致性(用shell脚本实现,具体如何实现不细说,就是循环变量执行npm脚本,shell脚本由git仓库管理,jenkins配置时统一拉取代码,这样所有的项目配置可以同步。示例如下)
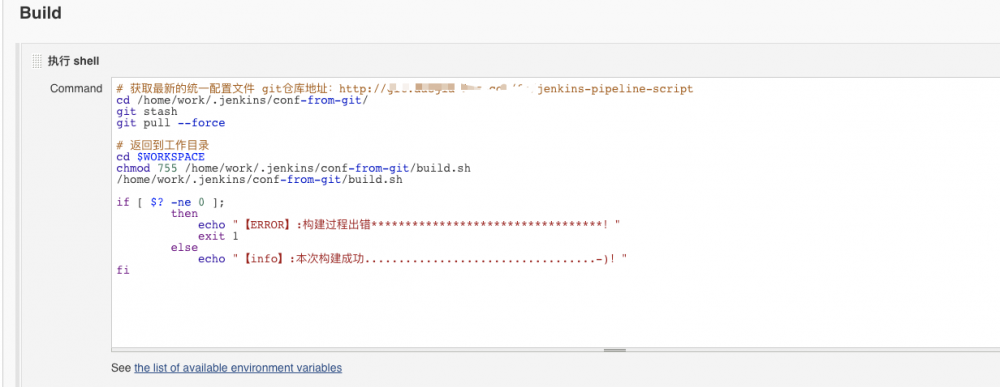
4. 下图展示了部署job可操作的选项

- 上图中有说明
- 贴一段jenkinsfile代码,语法为pipeline script
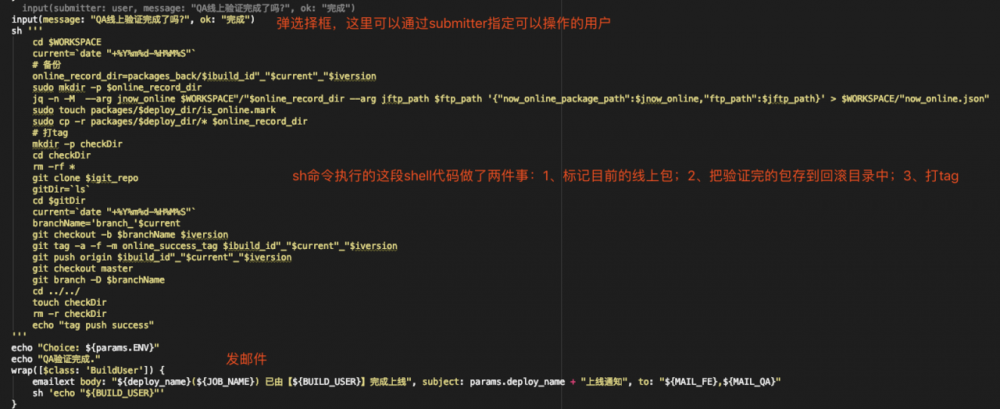
- 原理同6
- 占用系统是另外开发的,配套使用,上面有占用系统的示意图,是用node做后台,vue+element做前台快速开发的,这里不展开说;
- 这个利用jenkins的Url Auth Plugin,再开发一下对接公司统一登录系统的api,就可以直接用了,本质上是围绕cookie来进行的,每个公司都有自己的统一登录(也可能没有,那就使用jenkins自带的用户系统),这里不展开说。
- 全量部署脚本用corntab,用node脚本实现,核心思想在于读取说明6中的"now_online.json"来得知是哪一个包是线上的,取到这个包,同步到所有测试环境。同时检测是否有改动,没改动则跳过;同时检测说明8中的标记,查明环境是否有人占用,占用也跳过。上面我有贴日志的截图。
- 这里的意思就是,构建任务还没执行完的时候,打开了部署任务进行部署,此时要检查一下构建任务是否插入了构建完成的标记,不然不能部署。
- 这里是我自认为最大的亮点,“如何保证当前分支上的代码绝对不落后于master”?我们都知道master上的代码即是线上最新代码,当多人协作开发的时候,有人先上线,此时master代码更新,而后上线的人还在用老的代码测试、上线,这样就会造成问题, 除了人为保证主动去pull代码,有没有更可靠的方式? 这里就是工程化的一大亮点,我们设想, 如果后上线的人的分支上有落后于master的代码,那么我们就不让jenkins的构建/部署成功! 如何通过代码实现并整合进jenkins?我研究了一下git的命令,如果执行 git log [你的当前分支]..origin/master 打印了空值,那么说明当前分支没有落后,如果打印了内容,那么就说明分支落后与master!具体用shell实现示例:
check_results=`git log $branchName..origin/master` if [[ ! $check_results = "" ]] then echo "【Error】:当前代码比master落后,需要合并master或更新代码重新打包之后才能进行构建!" exit 1 else echo "【info】:当前代码正常,可以部署!" fi 复制代码
- 没太多好说的,打包出来的dist文件夹额外用eslint检测一下就好,shell脚本实现。
- 通过说明6中的pipeline script 中的 input 语法实现
- 回滚的关键代码也在说明6中有。
整篇文章比较零散,主要讲了一下我对前端工程化探索的思想和实践,因为手头的需求也很多(18年一起工作的好几个小伙伴被裁了,你猜他们剩下的工作谁来做),断断续续搞了两三个月,目前这套系统已经稳定运行几个月了,不断的完善使它现在很好用;这套系统的优点就是,基于开源jenkins+核心思想,就可以很快的通过node/shell/pipelinescript搭建起一套完整的系统,成本极低!超级实用的功能却实现很多!
如果你觉得读完没啥收获或我写的实在不知所云,那就好好看看说明12,我觉得把这一个小技巧分享出去,并且让你有所收获,那也值了,毕竟写作能力有限~
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

