『互联网架构』软件架构-分布式架构(14)
分布式架构:原理,设计与实战,目前公司每个月都要出账,出账就是每个月有要把之前的一个月的账目盘算清楚,做到错误的0容忍,一笔都不能错,错一笔客户都会找你,偏准确性。4个9,5个9并不是说后面设计的,而是在开发之初就要考虑的。
分布式服务的发展历程
-
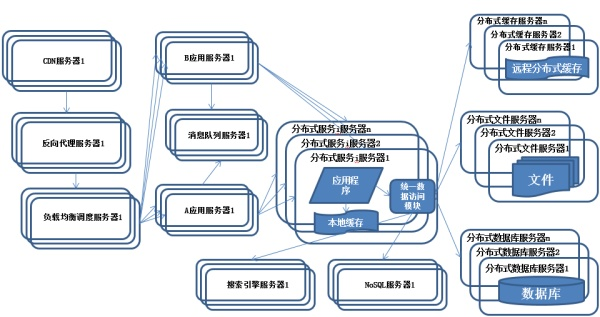
J2EE架构
>俗称JEE。对于大概有5年以上工作经验的老铁,应该都听过这个名词。基本分为3层。
- web容器
- EJB容器
- 数据库和数据存取的ORM
那时候的容器之间都没有进行物理的隔离,都是部署在同一个jvm上的。所以久而久之,它们之间互相的耦合互相的依赖,业务之前有千丝万缕的,添加和修改增加新的业务的时候,他们变的很复杂,经常导致服务不可用。这个时代就是有了层次,但是层次之前没有进行物理的隔离。带来了一些问题。
-
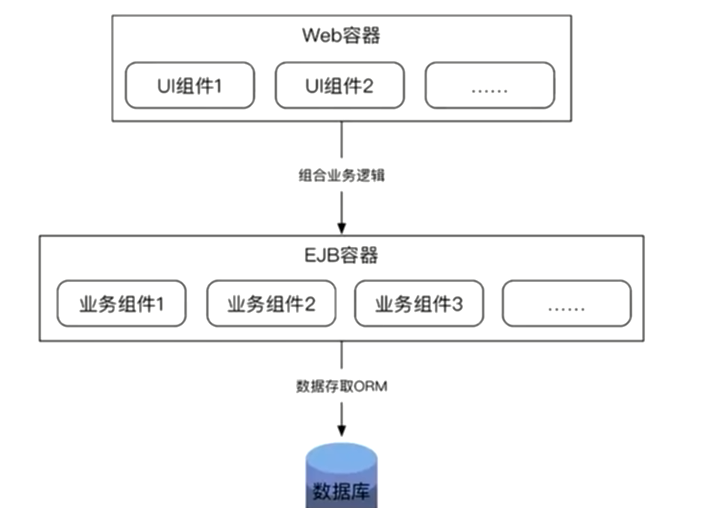
SSH架构
>开源框架SSH = struts + spring + hibernate,实际上它跟JEE的架构是基本相似的,也把组件分成了三层。
- struts MVC UI组件
- spring 业务组件,实现业务的逻辑
- ORM 对象管理映射层,连接数据库的
那时候的SSH非常流行,因为那个时期都是给传统的行业和制造行业来做的系统,在互联网行业里面ssh架构就不灵了。
-
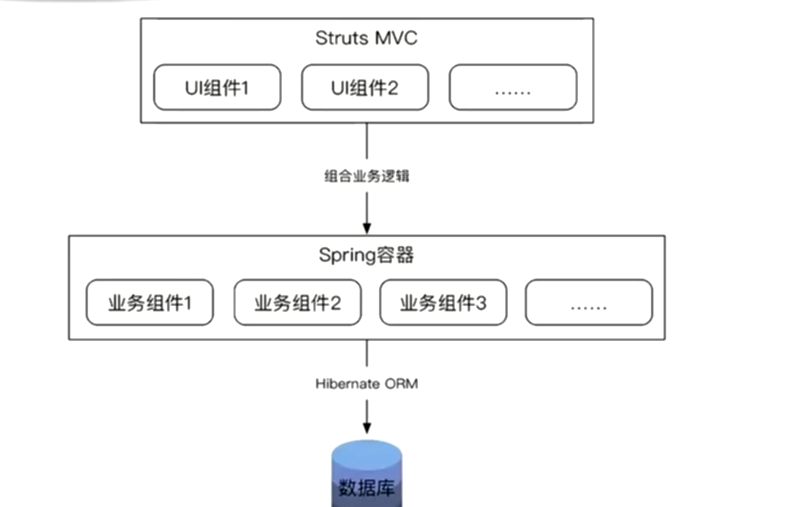
Web Service 架构
>互联网行业偏向于服务化,最流行的微服务起源于服务化,服务化最早体现在web service,web service 以IBM为首的各大公司制定的标准,webservice特点服务开发完毕后,不在部署在同一台机器,同一个JVM上面,拆分成不同的服务,例如图中的web service1 ,web service2,web service3 它们3个各自有各自的角色,各自有各自的功能,服务和服务之前都是通过远程调用的方式来实现互相实现和交流的,远程调用是遵循已定的标准,当时标准是SOAP协议,这个协议是在http协议之上的,来传输xml来完成的。有了这些的服务。需要服务的发现机制,通过webservice的目录来实现的。所有的服务对外提供服务的功能,需要在webservice注册。发现服务UDDI,找到服务WSDL找到服务。这个时代服务主要的特点是:职责拆分,服务部署隔离,服务调用遵守协议。webservice定义的协议是非常重的,首先xml序列化,xml有冗余的标签,服务性能上不来的。webservice注册通信化的服务,通信化的注册服务一定要保证高可用。在互联网里面如果不是高可用的,服务也不是最优化的。
-
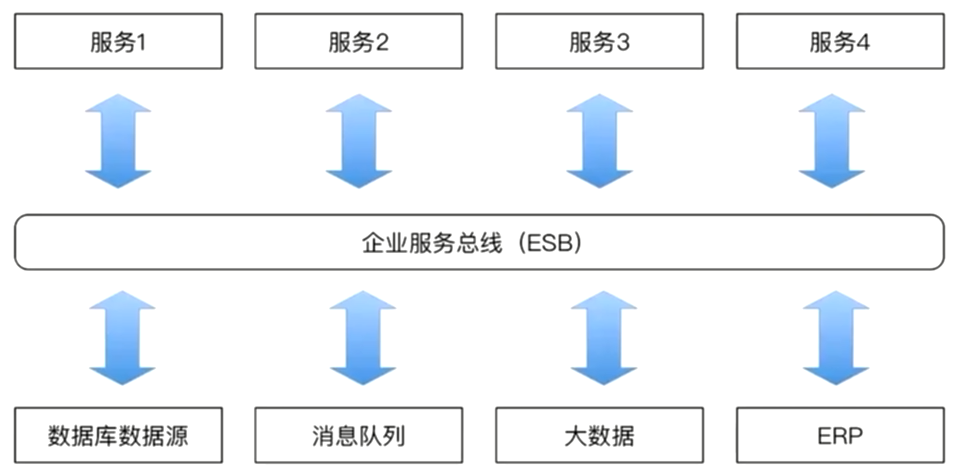
ESB架构
>企业服务总线,侧重于企业服务总线。 上边是提供的服务,下面是数据库数据源,消息队列,大数据,ERP。所有的服务和资源只要都进入ESB中,就会进行编排,完成特定的功能。这个时期,ESB功能进行了拆分,也有各自的职责,都进行了拆分,在不同的物理机,在不同JVM中。主要体现在可插拔,快速的添加删除服务,快速的加入资源。
-
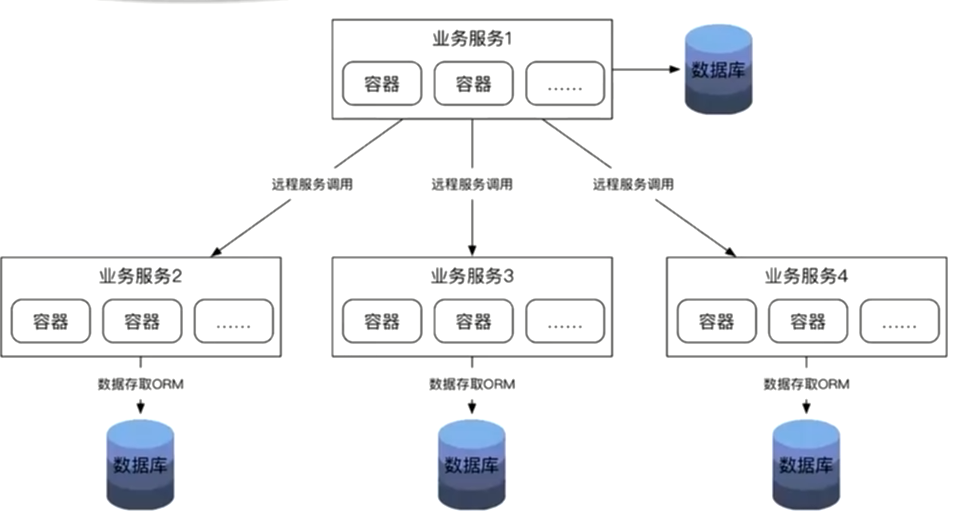
微服务架构
>最流行的架构,跟传统架构是一脉相承的,并不是矛盾的。采用的是分层的概念,上层的服务依赖下层的服务,基本两层,第一层:业务服务一;第二层:业务服务2,3,4。上一层跟下一层是依赖的,但是不是循环依赖的。每个服务之间自己是用数据库的,实际上数据库缓存和消息队列都是自治的,这就使微服务有自我管理的权限,微服务内可以快速的消化需求,敏捷上线,提高开发和运维的效率,微服务之前是通过远程的服务调用来先实现的。远程服务调用,并没有特定的要求是通过使用restful还是rpc,要求服务之间一定要有契约,契约可以服务生产者提出,也可以服务消费者提出的服务生产者契约,也可以是多个服务消费者一起找服务的生产者提要求,服务生产者提供一个公共的契约,保证通信没有问题的。例如:来了个需求,先进行服务的拆分,拆分到不同的微服务里面,微服务有了良好的通信契约,不在管对外的功能,就在服务内把需求消化掉了。上线和响应市场也是非常敏捷的。微服务每个节点他们的拆分都是比较单一的,都是比较细的,职责单一后,专业的人干专业的事情,这样很难犯错误,这样系统的可用性就提高起来了。
-
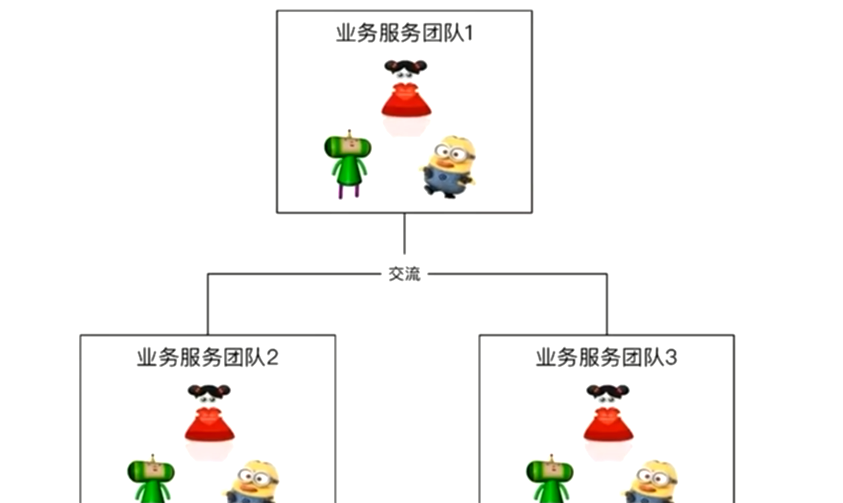
微服务的团队管理
>团队其实也是自治的。微服务团队里面可能是有产品,运营,测试,开发。如果系统分配到某个团队内,在团队内的开发可以非常敏捷的沟通,很快的开发上线,并不需要跨团队的沟通,跨团队的协调,回顾下当初的SSH,公司分为UI组,开发组,测试组,DB人团队沟通,都不是微服务的团队导致沟通效率很低。所以这就是微服务倡导的敏捷,专业的人干专业的事。
-
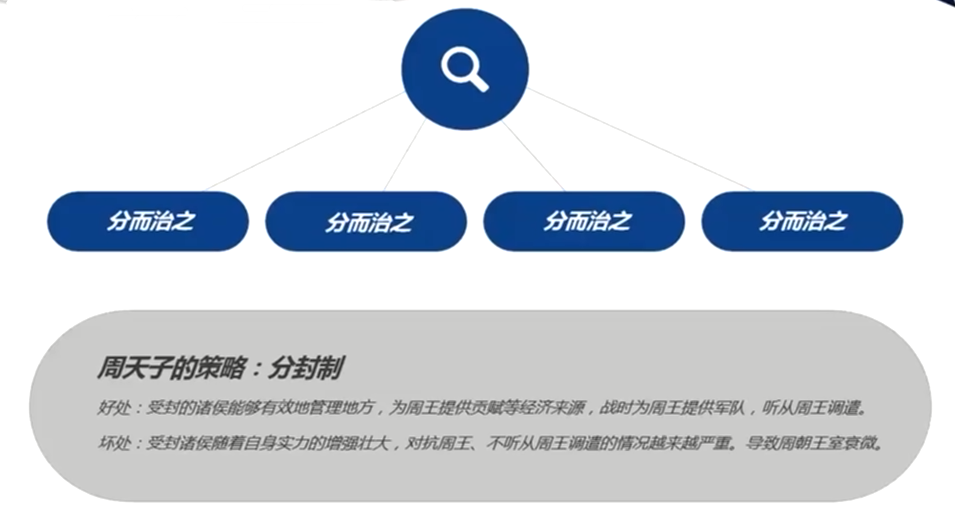
分布式服务架构的精髓
>敏捷上线,微服务下的自治,有效的减少不可用的因素。服务化和微服务都使用了分而治之的思想,分布式服务和分布式系统架构里面,无论是提高性能,提高吞吐量,提高敏捷性。
- 微服务架构的痛点
- 一致性
强一致性和弱一致性
- 高性能
容量评估和性能测试
- 高可用
4个9和5个9
- 可扩展
可修改,迭代新功能,可插拔
- 可伸缩
应用层和资源层,随着硬件投入的增加性能和能力相应的增长
- 安全性
防偷窥,防泄漏,防抵赖,防篡改,防中间人攻击
保证分布式一致性的最佳方案
周朝的时候,分而治之,后来都不听周王的话,导致不一致。不一致导致的痛点是很大的。如何去解决不一致的问题。线上趟过的坑和总结的经验分享。
-
一致性原理
>本质上需要理解下面的3种,本身是什么,应用的场景。

ACID,数据库理论的时候,我们都学过ACID就是强一致性。四个名词代表的是一个事务是不可以在进行拆分的,要么都成功,要么都失败。在传统的数据库里面都是单体的应用,单体的应用必须保持强一致性的,尤其是我们的关系型数据库。犹豫在互联网高并发的线上。用户量非常大,上千,上万,上亿的,单体的服务架构和单体数据库很难撑起来这么大的量,所以就需要它们之前进行分而治之,在网上进行分开,进行分开,分片。带来的问题,当网络出现问题的时候,这些应用是否可以正常的工作。这就引入了CAP原则。 CAP,之间肯定是网络通信,一定要有分区容错性,也就是某个节点网络不能正常的通信时。网络断了,或者闪断的话,各自之间还要继续的工作。P肯定是要有的。这个原则是如果三者只能选择其中的二个,P已经必须要了,那就需要在C和A之间选择一个。例如:网络上有一份数据,数据是通过复制来完成的。一份是主数据,一份是从数据,当你存一份数据的时候到主数据的时候,同时也需要往从数据中存一份,如果从出现问题,是继续还是返回给主,这就是一致性和可用性的解读。如果主从必须保持一致,主从都存起来后才可以返回的话,那就保证一致性,可用性就不好,如果网络出问题,就一致等待都一致才返回。不会在有限的时间内返回给客户端的请求,可用性就很差,所以一致性和可用性就是互斥的。如果是很快的返回客户端,那就可能牺牲了一致性保持了可用性。总结就是在容错性的基础之上,可用性和一致性是互斥的。不可兼得。 BASE,基本可用,中间有软状态,最终保持了一致。基本可用是条件,最终保持一致是目标。软状态就是事先的BASE的方法,就是我们要做一个事,达到目的中间的过程需要2,3个阶段,做完一个阶段记录状态信息,然后做第二个阶段,我们可以从出问题的那个位置恢复到出问题的地方。互联网上很多的高并发项目,都使用了分布式事务都进行打折了,完成了最终一致性。使用了BASE原理,CAP限制了它不可能三者同时存在。
- 一致性协议
两个阶段的协调者
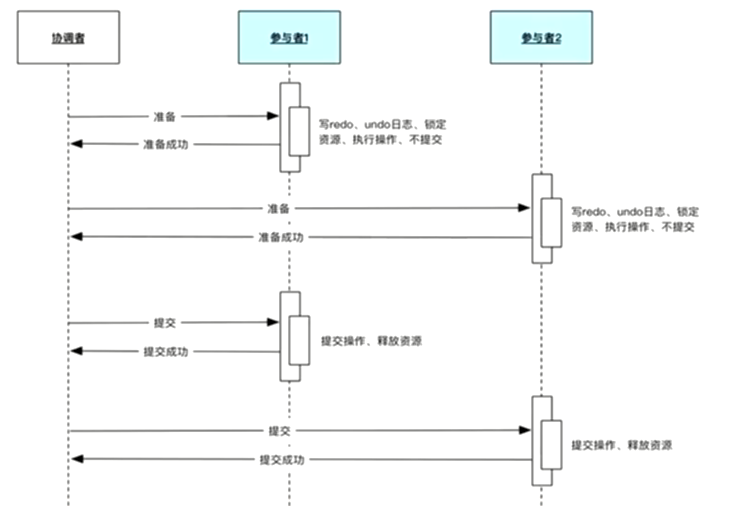
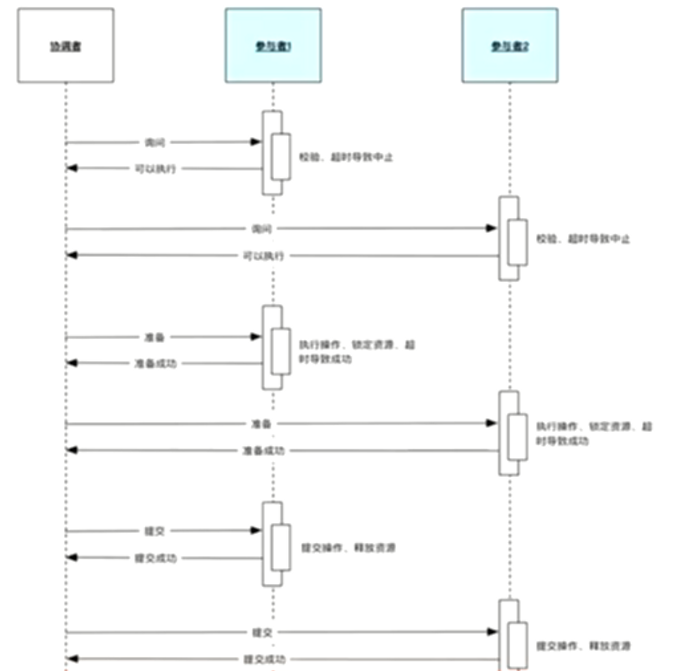
三阶段的协调者
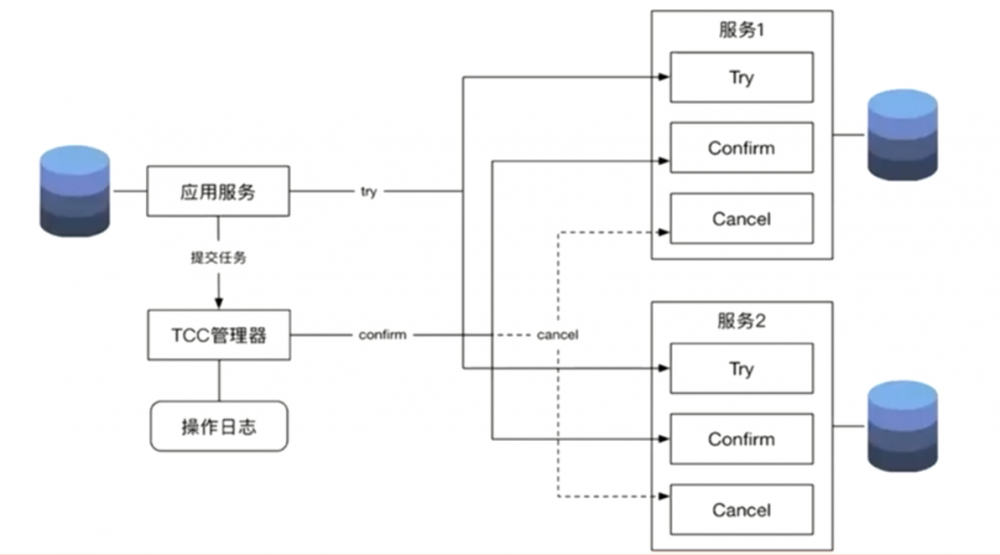
TCC(Try)
- 最终一致性
查询模式
补偿模式
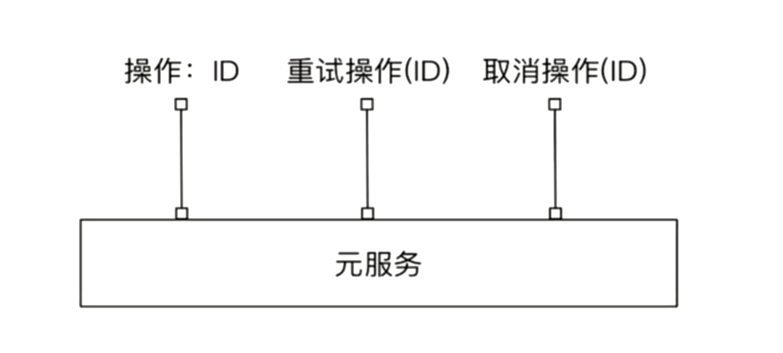
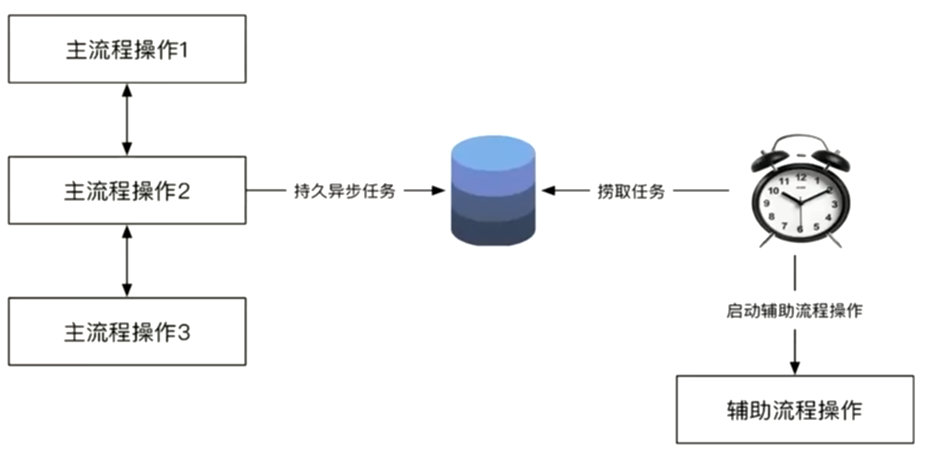
异步确保模式
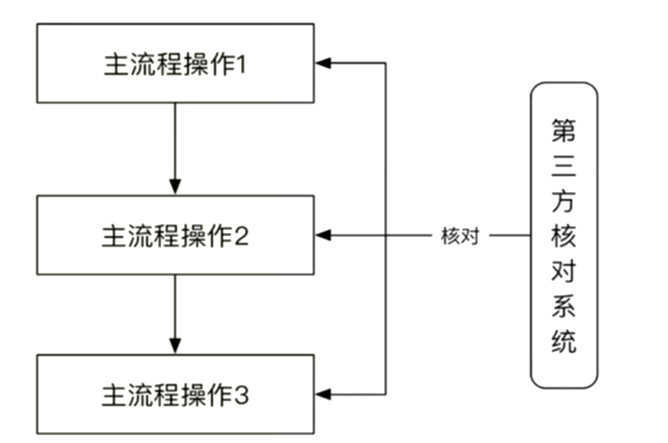
定期校对模式
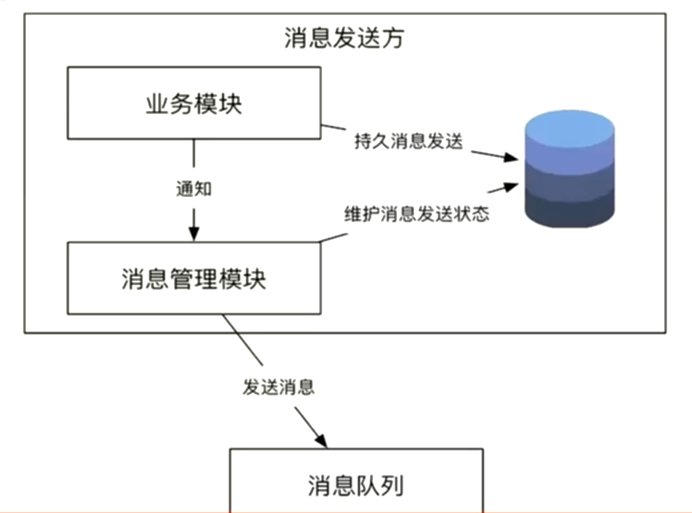
可靠消息模式
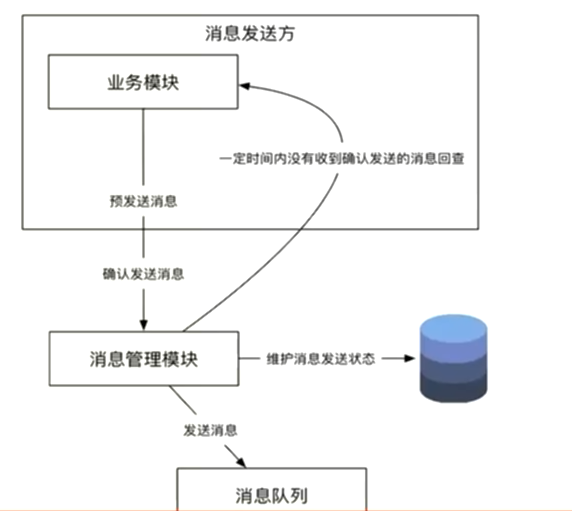
- 服务交互的模式
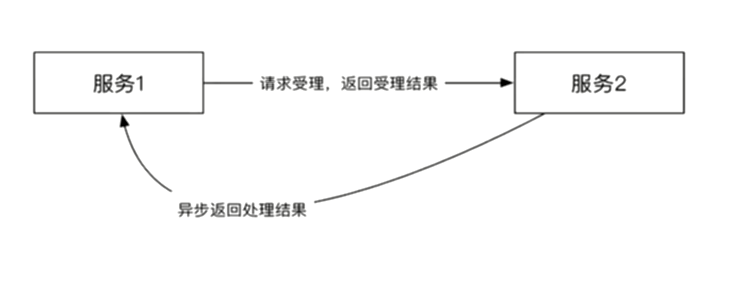
同步模式

异步模式
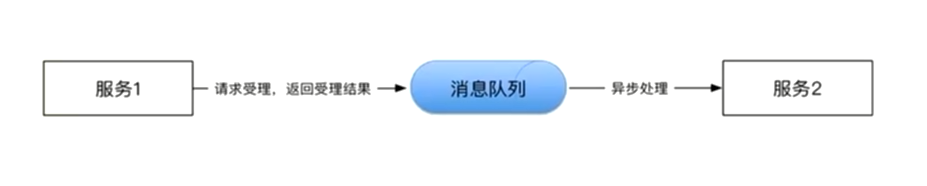
消息模式
- 同步与异步的抉择
尽量使用异步来替换同步操作
能用同步解决的问题,不要引入异步
- 超时模式
同步两个状态的接口超时
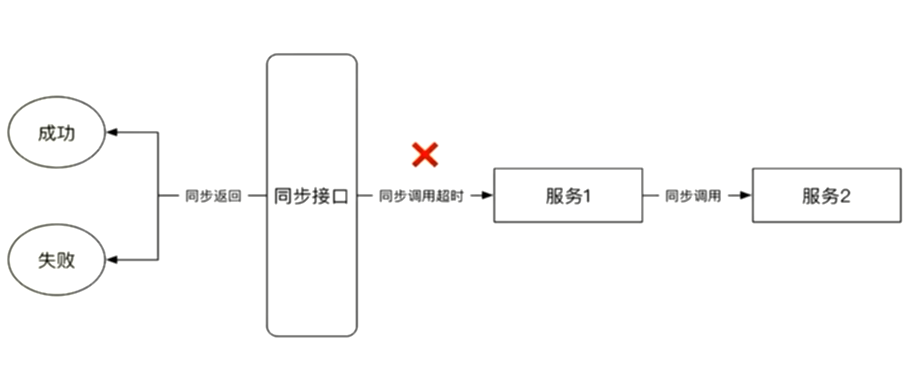
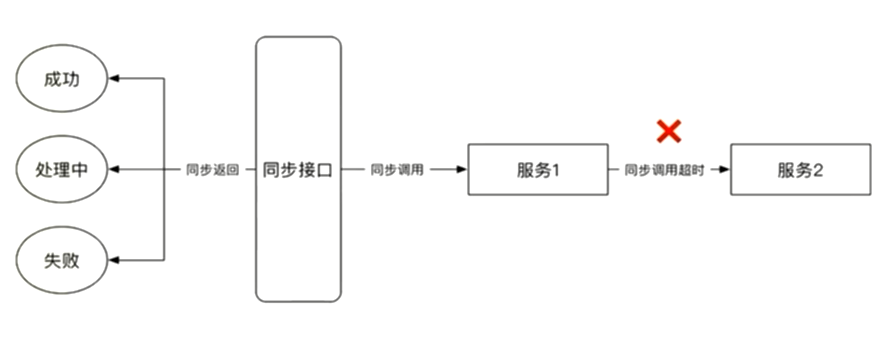
同步两个状态的内部超时
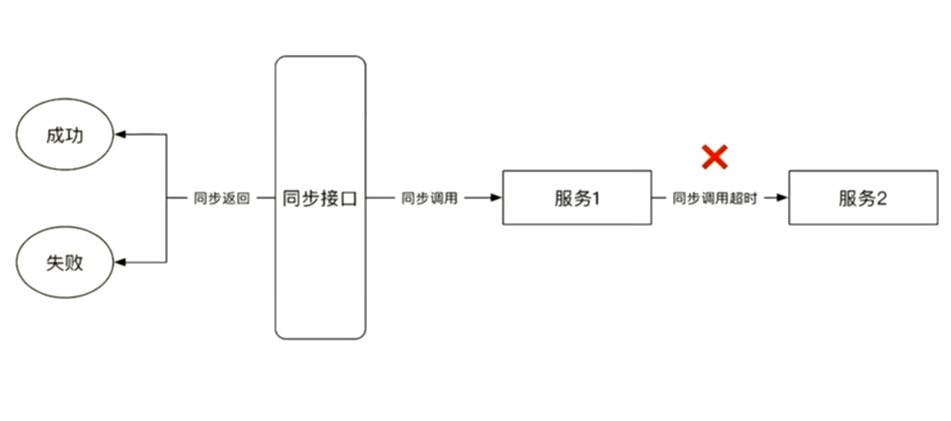
同步三状态的内部超时
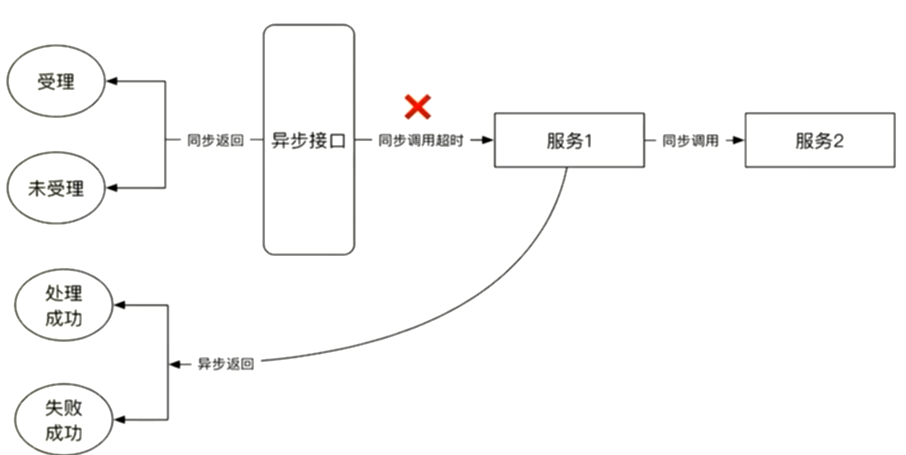
异步受理超时
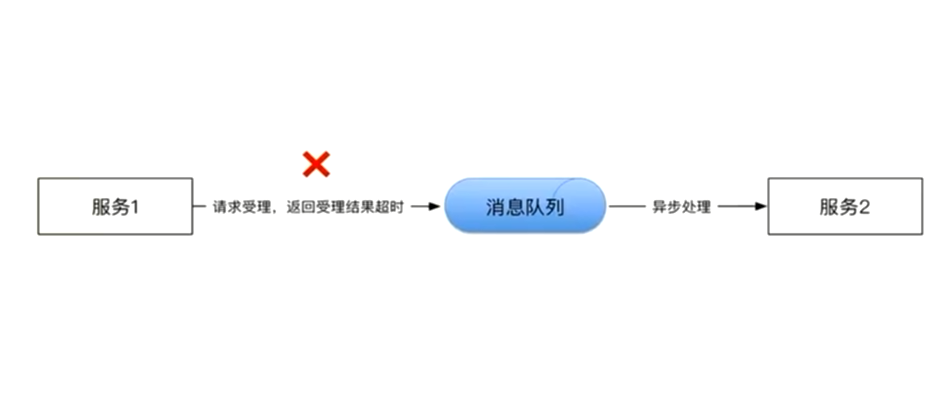
消息队列发送超时
消息对垒接收超时
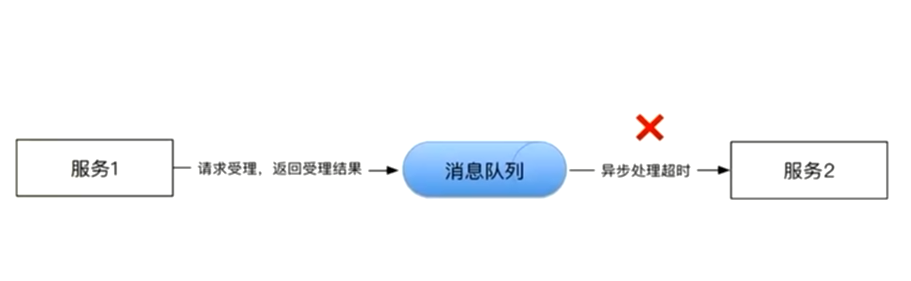
- 补偿的博弈

服务1调用服务2,如果服务2响应服务1,并且告诉服务1消息我接收了,那么服务1的任务就结束了,如果服务2处理失败,服务2应该负责重试或者补偿。在这种情况下,服务2通常先持久化消息后再告诉服务1接收成功,随后服务2才开始处理持久的消息,避免服务进程被傻吊丢失消息的情况。

服务1调用服务2,如果服务2没有给出明确的接收响应,那么服务1应该持久尝试重试,知道服务2明确表达已经接收消息,这种情况下,容易出现消息重复,因此在服务2中通常要保证滤重或者幂等性。
-
缓存使用的一致性模式
> 缓存是用来加速的,牺牲了一致性,获得高性能,只适合特殊场景。
保持数据库和缓存的强一致性是个伪命题
如果性能要求不是非常的高,尽量使用分布式缓存,而不是使用本地缓存,本地缓存可能你现在读的时候本地是开,其实另一个时间其他人读的是关,你想想多可怕。
种缓存的时候一定种完全,如果缓存数据的一部分有效,一部分无效,宁可放弃种缓存,也不要把部分数据中入缓存
通常情况下读的顺序要先缓存,后数据库,写的顺序要先数据库,后缓存
-
迁移开关的设计模式
>新旧系统的迁移。
不要用统一配置开关,开关是定义在某个业务上。在一个系统做滤重,比在多个系统做滤重简单。
不要用节点独立的开关
迁移开关必须使用订单开关
开关要用权限控制。开关的重要,特定经验的人来操作。
开关要能开能关
迁移开关要大小力度都有
PS:了解分布式架构,是对自己从心智上的一种提升,敲代码只是往下看,建议多往前方看看。架构这条路不好走,需要多接触,多趟多走,才能前方一路小平破。

百度未收录
>>原创文章,欢迎转载。转载请注明:转载自IT人故事会,谢谢!
>>原文链接地址:上一篇:下一篇:
正文到此结束
- 本文标签: 2019 测试 产品 RESTful 分布式事务 百度 删除 id 权限控制 部署 协议 互联网 管理 消息队列 总结 http MQ 本质 并发 web 进程 大数据 设计模式 开发 运营 HTTP协议 一致性 微服务 ssh 数据库 数据 时间 快的 src WebService 分布式系统 幂等 spring UI 需求 REST 企业 ORM 高可用 缓存 目录 https 系统架构 代码 软件 同步 Service 高并发 JVM db 配置 IT人 敏捷 文章 分布式 IBM 安全 SOA XML 开源 服务团队 幂等性 bus
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

