Java编程方法论-Spring WebFlux篇 01 为什么需要Spring WebFlux 下
本系列为本人Java编程方法论 响应式解读系列的 Webflux 部分,现分享出来,前置知识Rxjava2 ,Reactor的相关解读已经录制分享视频,并发布在b站,地址如下:
Rxjava源码解读与分享: www.bilibili.com/video/av345…
Reactor源码解读与分享: www.bilibili.com/video/av353…
NIO源码解读相关视频分享: www.bilibili.com/video/av432…
NIO源码解读视频相关配套文章:
BIO到NIO源码的一些事儿之BIO
BIO到NIO源码的一些事儿之NIO 上
BIO到NIO源码的一些事儿之NIO 中
BIO到NIO源码的一些事儿之NIO 下 之 Selector BIO到NIO源码的一些事儿之NIO 下 Buffer解读 上 BIO到NIO源码的一些事儿之NIO 下 Buffer解读 下
Java编程方法论-Spring WebFlux篇 01 为什么需要Spring WebFlux 上
其中,Rxjava与Reactor作为本人书中内容将不对外开放,大家感兴趣可以花点时间来观看视频,本人对着两个库进行了全面彻底细致的解读,包括其中的设计理念和相关的方法论,也希望大家可以留言纠正我其中的错误。
Servlet 3.1与Spring MVC
随着 Servlet 3.1 的引入,通过 Spring MVC 即可以实现非阻塞行为。 但是,由于 Servlet API 依然包含几个阻塞的接口。同样,我们在应用程序设计的API中也可能会使用到阻塞,而该API本来是被设定为非阻塞。 在这种情况下,相关阻塞API的使用肯定会降低应用程序性能。 我们来看下面这段代码:
@GetMapping
void onResponse(){
try{
//some logic here
}catch(Exception e){
//sendError() is a blocking API
response.sendError(500);
}
}
复制代码
这段代码使用在Spring MVC中,Spring容器针对这个错误而对相应页面的渲染则是阻塞的。如下:
@Controller
public class MyCustomErrorController implements ErrorController {
@RequestMapping(path = "/error")
public String greeting() {
return "myerror";
}
@Override
public String getErrorPath() {
return "/error";
}
}
复制代码
此处渲染的页面为 myerror.jsp ,具体代码就不贴了。当然,我们肯定有办法来异步解决这个错误处理问题,但我们出错的可能性就会变大,要知道,我们最终还是要经过 Servlet 对象的,而 Servlet 相关api有阻塞的也有非阻塞的,我们来通过一张图来方便理解。
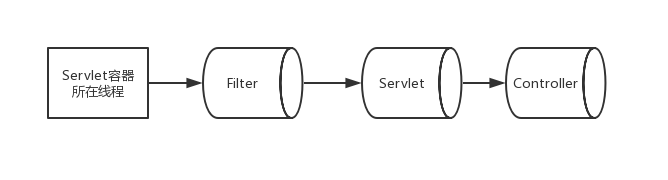
当产生请求访问时事件时,则该事件处理流向如上图所示(我们只关注进入到Servlet容器的处理阶段),可以知道,这个过程尤其是Filter链这里,都是可以发生IO阻塞的,再根据上一节所讲内容,我们可以使用一张图来展示我们可以确定的非阻塞IO。
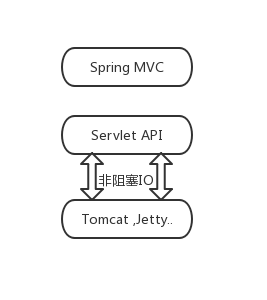
Spring MVC 中在所写代码逻辑中做到完美的无阻塞,我们依然无法改变与避免
Servlet 3.1+ 中那些架构设计层面的缺陷,
Servlet 的相关阻塞API我们依然会用到。那么我们是不是可以使用netty来避免这样的情形?于是我们就可以将目光放到
Spring WebFlux
之上。
业务层面异步处理难易分析
我们业务端来讲,绝大多数程序员对于并发的操作并不在行的,也就很难写出性能很好而且符合规范的代码,这也造成了在 Spring web MVC 下,我们很难针对自己的业务进行合理的异步化操作。比如,我们往往会将 I/O 操作与当前执行线程进行绑定到一起,也就是生产和消费两种业务绑定在一起,这样,即便我们异步,两者也是在同一个线程中进行,这样,假如并发量很大的情况下,异步化会产生大量的线程, CPU 会在切换线程上消耗更多的性能,这是我们所不愿看到的,而 RxJava 和 Reactor 给我们提供了很好的调度 API ,如 Reactor中的publishOn , RxJava中的observeOn ,可以保证我们将生产和消费分离,同时,作为生产或消费线程所在的线程池,其往往是针对于使用了这个线程池的多个订阅服务,这样,每一个线程都可能同时为多个订阅关系服务,一个单独的订阅关系并不会一直占有这个线程,当有元素下发时,将会根据订阅者请求数量和元素产生的速度以及是否有多个线程在处理此订阅关系的下发元素,使用调度器的话,这里拿 Reactor中的publishOn 来讲,当上游只支持同步的话( FluxPublishOn.PublishOnSubscriber#onSubscribe 内调用源的 requestFusion 方法判断),那就始终在同一个线程内消费( FluxPublishOn.PublishOnSubscriber#trySchedule 内进行判断,通过 WIP 控制),当我们定义好 publishOn 中队列大小后,每当队列内元素消耗完毕,然后上游元素产生太慢,就会跳出当前消费线程,直到有新元素下发时,就再次从线程池中拿到一个线程消费。读者假如此处有疑问,请回顾本书之前内容(因书并未出版,可回顾本人相关分享视频)。 这样服务器的性能就可以得到最大程度的利用。这个我们在 Spring MVC 中确实很难自行实现,比较复杂。 另外,通过 Reactor 对于背压的实现,我们可以做到类似消息中间件对于消息的积压,不至于数据在网络传输的过程中丢失,这样就可以更好的应对高并发场景下的访问需求。 接下来,我们就来对 Webflux 下的背压使用进行一波大致的说明。
Webflux中的背压的使用
为了帮助理解 Backpressure 在 WebFlux 使用时底层的工作原理,我们有必要回顾一下默认使用的 TCP/IP 传输层。我们知道,浏览器和服务器之间的正常通信(服务器到服务器之间的通信通常也是一样)是通过 TCP 连接完成的(同样包括 WebFlux 中的 WebClient 和服务器之间的通信)。同时,我们会从 Reactive Streams 规范的角度来回顾一下背压的含义,以便更好的针对背压进行控制。
在 Reactive Streams 中,背压包括两部分,一部分是接收端的消息积压,另一部分是消费者可以通过发出通知来表达该消费者可以消耗多少元素,以此来进行需求调节。整个过程是操作的元素对象,那么,在这里,我们就碰到一个棘手的问题: TCP 是针对字节抽象而不是逻辑元素抽象。 我们通常所说的背压控制是指制向或者从网络发送或接收的逻辑元素的数量。而TCP自己的流程控制是基于字节而不是逻辑元素。
由上,可知道,在 WebFlux 的实现中,背压通过数据传输流程控制来调节,但它不会暴露接收方的实际需求。 我们可以通过下图来观察其中的交互流程:
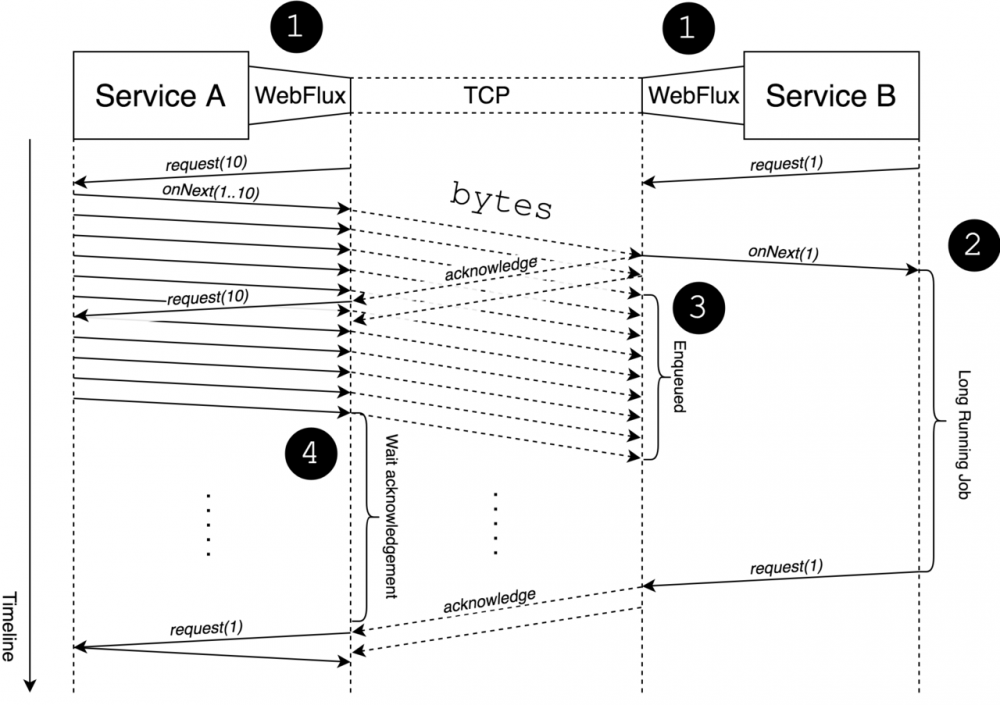
上图显示了两个微服务之间的通信,其中左侧发送数据流,右侧对该流进行消费。接下来对上图整个过程进行简要说明:
WebFlux
正如我们从上图中可以看到的那样,接收者的需求与发送者的需求不同(这里指图中的 request 请求的逻辑元素)。这也就意味着两者的需求是相互独立的,也就是说,在WebFlux中,我们可以通过业务逻辑(服务)交互来展现需求,但很少会暴露服务A与服务B交互的相关背压细节。 也就是说, webflux 中的背压设计并没有对数据发送服务端进行按需设计,这点可能与我们所期望的有所出入,不是那么完美,显得有失公平。
自定义背压控制
如果我们想很简单的对背压进行控制,我们可以通过 Reactor 的相关操作来控制请求数量,也可以在自定义订阅者的时候进行限定,这里我们通过 Flux 下的 limitRate(n) 来实现。首先我们先来看下其实现思路,其实就是一个调度操作,只不过我们之前有讲, publishOn 自己是一个中间存储站,它将上下游进行分离下游的请求数量在这里进行管理, publishOn 自己有一个每次向上游请求的数量限制,关于 publishOn 操作源码细节,可以回顾之前相关章节内容(因书并未出版,可回顾本人相关分享视频)。也就是说,我们只需要在 publishOn 之上封装一个 API 来实现即可:
//reactor.core.publisher.Flux#limitRate(int)
public final Flux<T> limitRate(int prefetchRate) {
return onAssembly(this.publishOn(Schedulers.immediate(), prefetchRate));
}
复制代码
假如我们有一个包含 questions 的源,因为解决问题的能力有限,想要对其进行限流,于是我们就可以进行如下操作:
@PostMapping("/questions")
public Mono<Void> postAllQuestions(Flux<Question> questionsFlux) {
return questionService.process(questionsFlux.limitRate(10))
.then();
}
复制代码
我们熟悉 publishOn 后,可以知道 limitRate() 操作会首先从上游获取10个元素存到其内定义的队列中。这意味着即使我们定义的订阅者所设定的请求元素数量为 Long.MAX_VALUE , limitRate 操作也会将此需求拆分为一块一块去请求下发。此处涉及的源码如下,大家可对照理解:
//reactor.core.publisher.FluxPublishOn.PublishOnSubscriber#runAsync
if (e == limit) {
if (r != Long.MAX_VALUE) {
r = REQUESTED.addAndGet(this, -e);
}
s.request(e);
e = 0L;
}
复制代码
上面是提交的数据的分块处理,我们有时候会涉及到数据库请求数据的处理,比如查询,同时将所发送数据进行限流逐步发送,可以进行如下操作:
@GetMapping("/questions")
public Flux<Question> getAllQuestions() {
return questionService.retreiveAll()
.limitRate(10);
}
复制代码
由此,我们也能理解背压在 webflux 中的作用机制了。对于这些特性, Spring MVC 也就很难提供了。
小结
相信大家也明确感受到了使用 Spring WebFlux 的好处了,也知道为何会要求使用 Servlet 3.1+ ,同时对于 webflux 中背压的作用有了更清晰的认知。不过,我们需要注意的是,通过官方文档可知, Spring Webflux 可以在 Servlet Container 或 Netty 上运行,而本书更关心 Spring Webflux 基于 Netty 服务器的运行。那么,接下来,我们将接触 Reactor-netty 的内在细节。
正文到此结束
- 本文标签: https 数据 响应式 同步 线程池 id 并发 ip UI 时间 final 调度器 服务端 stream servlet map 需求 value 文章 希望 微服务 源码 cat 代码 Select http 工作原理 限流 服务器 线程 Netty 程序员 core IO Reactor web 数据库 API App src NIO BIO java 管理 CTO lib 业务层 架构设计 spring js IDE TCP client Service 高并发
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

