Twitter雪花算法SnowFlake算法的java实现
二进制是计算技术中广泛采用的一种数制。二进制数据是用0和1两个数码来表示的数。 它的基数为2,进位规则是“逢二进一”,借位规则是“借一当二”,由18世纪德国数理哲学大师莱布尼兹发现。 当前的计算机系统使用的基本上是二进制系统,数据在计算机中主要是以补码的形式存储的。 计算机中的二进制则是一个非常微小的开关,用“开”来表示1,“关”来表示0。 复制代码
1.2 运算法则
二进制的运算算术运算 二进制的加法:0+0=0,0+1=1 ,1+0=1, 1+1=10(向高位进位);例:7=111;10=1010;3=11 二进制的减法:0-0=0,0-1=1(向高位借位) 1-0=1,1-1=0 (模二加运算或异或运算) ; 二进制的乘法:0 * 0 = 0; 0 * 1 = 0; 1 * 0 = 0; 1 * 1 = 1; 二进制的除法:0÷0 = 0,0÷1 = 0,1÷0 = 0 (无意义),1÷1 = 1 ; 逻辑运算二进制的或运算:遇1得1 二进制的与运算:遇0得0 二进制的非运算:各位取反。 复制代码
1.3 位
数据存储的最小单位。每个二进制数字0或者1就是1个位; 复制代码
1.4 字节
8个位构成一个字节;即:1 byte (字节)= 8 bit(位);
1 KB = 1024 B(字节);
1 MB = 1024 KB; (2^10 B)
1 GB = 1024 MB; (2^20 B)
1 TB = 1024 GB; (2^30 B)
复制代码
1.5 字符
a、A、中、+、*、の......均表示一个字符;
一般 utf-8 编码下,一个汉字 字符 占用 3 个 字节;
一般 gbk 编码下,一个汉字 字符 占用 2 个 字节;
复制代码
1.6 字符集
即各种各个字符的集合,也就是说哪些汉字,字母(A、b、c)和符号(空格、引号..)会被收入标准中; 复制代码
1.7 java语言的8大基本数据类型
| 数据类型 | 字节长度(单位:byte) | 位长度(单位:bit)| |------- |--------------------|-----------------| | int | 4 | 32 | | byte | 1 | 8 | | short | 2 | 16 | | long | 8 | 64 | | float | 4 | 32 | | double | 8 | 64 | | boolean| 1 | 8 | | char | 2 | 16 | 复制代码
1.8 二进制原码、反码、补码
| 正数 | 负数 | |
|---|---|---|
| 原码 | 原码 | 原码 |
| 反码 | 原码 | 原码符号位外按位取反 |
| 补码 | 原码 | 反码+1 |
1.9 有符号数和无符号数
无符号数中,所有的位都用于直接表示该值的大小。 有符号数中最高位用于表示正负。 例: 8位2进制表示的: 无符号数的范围为0(00000000B) ~ 255 (11111111B); 有符号数的范围为-128(10000000B) ~ 127 (01111111B); 255 = 1*2^7 + 1*2^6 + 1*2^5 +1*2^4 +1*2^3 +1*2^2 +1*2^1 +1*2^0; 127 = 1*2^6 + 1*2^5 +1*2^4 +1*2^3 +1*2^2 +1*2^1 +1*2^0; 复制代码
疑问:为什么不是-127 ~ 127 ?
算机中数据用补码表示,利用补码统一了符号位与数值位的运算,同时解决了+0、-0问题,将空出来的二进制原码1000 0000表示为-128,这也符合自身逻辑意义的完整性。因此八位二进制数表示范围为-128~+127。
对于n位二进制数原、反、补码范围:

你会发现,补码比其它码多一位,这是为什么呢?问题出在0上。
[+0]原码=0000 0000, [-0]原码=1000 0000 [+0]反码=0000 0000, [-0]反码=1111 1111 [+0]补码=0000 0000, [-0]补码=0000 0000 反码表示法规定:正数的反码与其原码相同。负数的反码是对其原码逐位取反,但符号位除外。 在规定中,8位二进制码能表示的反码范围是-127~127。 -128没有反码。 那么,为什么规定-128没有反码呢?下面解释。 首先看-0,[-0]原码=1000 000,其中1是符号位,根据反码规定,算出[-0]反码=1111 1111, 再看-128,[-128]原码=1000 000,假如让-128也有反码,根据反码规定,则[-128]反码=1111 1111, 你会发现,-128的反码和-0的反码相同,所以为了避免面混淆,有了-0,便不能有-128,这是反码规则决定的。 复制代码
因此八位二进制表示的范围为:-128~0~127。此处的0为正0,负0表示了-128。
注意:
-128的8位补码是:1000 0000B,换算成十进制就是 128。 负数的补码,是用“模”计算出来的, 即: [X]补 = 256 - |X| = 256- |-128| = 128 复制代码
2 理解分布式id生成算法SnowFlake
2.1 概述
SnowFlake算法生成id的结果是一个64bit大小的整数,它的结构如下图:
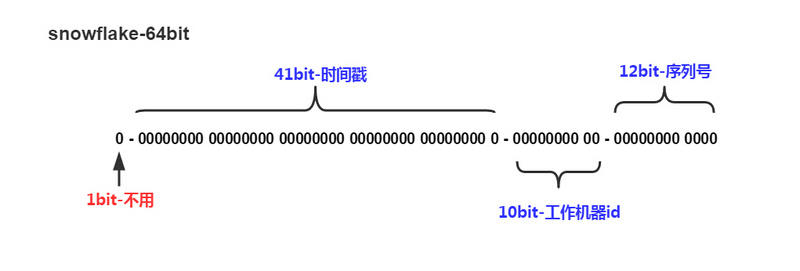
1) 1位,不用。二进制中最高位为1的都是负数,但是我们生成的id一般都使用整数,所以这个最高位固定是0 2) 41位,用来记录时间戳(毫秒)。 3) 41位可以表示2^41−1个数字,如果只用来表示正整数(计算机中正数包含0),可以表示的数值范围是:0 至 2^41−1,减1是因为可表示的数值范围是从0开始算的,而不是1。 也就是说41位可以表示2^41−1个毫秒的值,转化成单位年则是(2^41−1)/(1000∗60∗60∗24∗365)=69年 4) 10位,用来记录工作机器id。 可以部署在2^10=1024个节点,包括5位datacenterId和5位workerId 5) 5位(bit)可以表示的最大正整数是2^5−1=31,即可以用0、1、2、3、....31这32个数字,来表示不同的datecenterId或workerId 6) 12位,序列号,用来记录同毫秒内产生的不同id。 12位(bit)可以表示的最大正整数是2^12−1=4095,即可以用0、1、2、3、....4094这4095个数字,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号 由于在Java中64bit的整数是long类型,所以在Java中SnowFlake算法生成的id就是long来存储的。 复制代码
2.2 雪花算法的作用
SnowFlake可以保证:
所有生成的id按时间趋势递增 整个分布式系统内不会产生重复id(因为有datacenterId和workerId来做区分) 复制代码
2.3 雪花算法java代码展示
下面解读一下java版的雪花算法:
public class SnowFlake {
/**
* 起始的时间戳:这个时间戳自己随意获取,比如自己代码的时间戳
*/
private final static long START_STMP = 1543903501000L;
/**
* 每一部分占用的位数
*/
private final static long SEQUENCE_BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 5; //机器标识占用的位数
private final static long DATACENTER_BIT = 5;//数据中心占用的位数
/**
* 每一部分的最大值:先进行左移运算,再同-1进行异或运算;异或:相同位置相同结果为0,不同结果为1
*/
/** 用位运算计算出最大支持的数据中心数量:31 */
private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
/** 用位运算计算出最大支持的机器数量:31 */
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
/** 用位运算计算出12位能存储的最大正整数:4095 */
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
/**
* 每一部分向左的位移
*/
/** 机器标志较序列号的偏移量 */
private final static long MACHINE_LEFT = SEQUENCE_BIT;
/** 数据中心较机器标志的偏移量 */
private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
/** 时间戳较数据中心的偏移量 */
private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
private static long datacenterId; //数据中心
private static long machineId; //机器标识
private static long sequence = 0L; //序列号
private static long lastStmp = -1L;//上一次时间戳
/** 此处无参构造私有,同时没有给出有参构造,在于避免以下两点问题:
1、私有化避免了通过new的方式进行调用,主要是解决了在for循环中通过new的方式调用产生的id不一定唯一问题问题,因为用于 记录上一次时间戳的lastStmp永远无法得到比对;
2、没有给出有参构造在第一点的基础上考虑了一套分布式系统产生的唯一序列号应该是基于相同的参数
*/
private SnowFlake(){}
/**
* 产生下一个ID
*
* @return
*/
public static synchronized long nextId() {
/** 获取当前时间戳 */
long currStmp = getNewstmp();
/** 如果当前时间戳小于上次时间戳则抛出异常 */
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
/** 相同毫秒内 */
if (currStmp == lastStmp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
/** 获取下一时间的时间戳并赋值给当前时间戳 */
currStmp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
/** 当前时间戳存档记录,用于下次产生id时对比是否为相同时间戳 */
lastStmp = currStmp;
return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分
| datacenterId << DATACENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
private static long getNextMill() {
long mill = getNewstmp();
while (mill <= lastStmp) {
mill = getNewstmp();
}
return mill;
}
private static long getNewstmp() {
return System.currentTimeMillis();
}
}
复制代码
2.4 雪花算法demo展示
下面就上述代码给出案例进行相关位运算 所有参数展示:
当前生成的id :1143315521077248 currStmp:1544176088662 START_STMP:1543903501000 SEQUENCE_BIT:12 MACHINE_BIT:5 DATACENTER_BIT:5 MAX_DATACENTER_NUM:31 MAX_MACHINE_NUM:31 MAX_SEQUENCE:4095 MACHINE_LEFT:12 DATACENTER_LEFT:17 TIMESTMP_LEFT:22 datacenterId:0 machineId:0 sequence:0 lastStmp:1544176088662 currStmp - START_STMP:272587662 (currStmp - START_STMP) << TIMESTMP_LEFT:1143315521077248 datacenterId << DATACENTER_LEFT:0 machineId << MACHINE_LEFT:0 sequence:0 (currStmp - START_STMP) << TIMESTMP_LEFT | datacenterId << DATACENTER_LEFT:1143315521077248 (currStmp - START_STMP) << TIMESTMP_LEFT | datacenterId << DATACENTER_LEFT| machineId << MACHINE_LEFT:1143315521077248 (currStmp - START_STMP) << TIMESTMP_LEFT | datacenterId << DATACENTER_LEFT| machineId << MACHINE_LEFT | sequence:1143315521077248 复制代码
2.5 雪花算法中的实际运算
1) MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT):数据中心最大数量; 先进行-1的左移5位,得到的结果再同-1进行异或运算: 由于我们知道1的补码+(-1)的补码=0; 8位2进制1的表示表示为:00000001; 由此得出xxxxxxxx(代表-1的补码): 00000001 + xxxxxxxx ----------- = 00000000 从而得出:xxxxxxxx = 11111111;(溢出的最高位舍弃) -1L << DATACENTER_BIT:-1左移5位:高位舍弃,低位用0补齐, 则:为11100000; -1L ^ 11100000:-1异或11100000 则: 11111111 ^ 11100000 ---------- = 00011111 最高位为0,代表正数,即:2^4 +2^3 +2^2 +2^1 +2^0 = 31; 2) MAX_MACHINE_NUM 同理; 3)MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT):最大序列号,计算12位能耐存储的最大正整数: -1L << SEQUENCE_BIT:-1向左偏移12位:1111000000000000; -1 ^ 1111000000000000: 1111111111111111 ^ 1111000000000000 ------------------ = 0000111111111111 最高位为0,代表正数,同上计算出为:4095; 4) (currStmp - START_STMP) << TIMESTMP_LEFT:272587662向左偏移22位: 即:0001 0000 0011 1111 0101 1011 1000 1110左移:22位,左移可能造成高位数据丢失,故先把0001 0000 0011 1111 0101 1011 1000 1110用64位进行表示,则为: 0000 0000 0000 0000 0000 0000 0000 0000 0001 0000 0011 1111 0101 1011 1000 1110;再进行左移22位为: 0000 0000 0000 0100 0000 1111 1101 0110 1110 0011 1000 0000 0000 0000 0000 0000; 经如下计算换算成10进制:1*2^41 + 0*2^40 +0*2^39+ …… +0*2^2 +0*2^1 +0*2^0 = 1143315521077248; 其他较长的位运算同4)进行即可得出正确验证。 5)(currStmp - START_STMP) << TIMESTMP_LEFT | datacenterId << DATACENTER_LEFT| machineId << MACHINE_LEFT:1143315521077248同0偏移12位的结果做或运算,因为0的偏移结果还是0,再进行或运算的结果即为1143315521077248本身; 6)(currStmp - START_STMP) << TIMESTMP_LEFT | datacenterId << DATACENTER_LEFT| machineId << MACHINE_LEFT | sequence同5)即得证结果为1143315521077248; 注:至于最后返回(return)的的表达式中的或运算(|),我们只要知道二进制中1的位置,相同位置有一个为1即为1,其余部分补0即可。 复制代码
3 雪花算法中值得考虑的问题
雪花算法中的溢出问题
先来看一段代码:sequence = (sequence + 1) & MAX_SEQUENCE;
替换一下参数为:sequence = (sequence + 1) & (-1L ^ (-1L << SEQUENCE_BIT))
带入常量为:sequence = (sequence + 1) & (-1L ^ (-1L << 12))
化简得:sequence = (sequence + 1) & 4095;
用控制台打印结果展示这段代码解决的问题:
//计算12位能耐存储的最大正整数,相当于:2^12-1 = 4095
long seqMask = -1L ^ (-1L << 12L);
System.out.println("seqMask: "+seqMask);
System.out.println(1L & seqMask);
System.out.println(2L & seqMask);
System.out.println(3L & seqMask);
System.out.println(4L & seqMask);
System.out.println(4095L & seqMask);
System.out.println(4096L & seqMask);
System.out.println(4097L & seqMask);
System.out.println(4098L & seqMask);
/**
seqMask: 4095
1
2
3
4
4095
0
1
2
*/
复制代码
带入雪花算法中去看,问题就是:当同一毫秒产生的序列号已经最大了,该怎么办?
上述内容已经给出了明确的解决方案,接下来我们去看另外一个很实际的问题;
雪花算法中的夏令时问题
我们所说的夏令时实际上包括两类:夏令时和冬令时
夏令时(1:00 -> 3:00 AM) 往后拨一个小时,直接从1点变到3点,也就是说我们要比原来提前一个小时和美国人开会。 冬令时(1:00 -> 1:00 -> 2:00 AM) 往前拨一个小时,要过两个1点,这时比平常晚一个小时。 复制代码
由此可见夏令时从1点跳到3点在雪花算法中没有什么影响,但是在冬令时要经历两个相同的时间段并使用相同的时间戳和算法参数进行运算就要出问题了。 忽略掉具体的实现逻辑,单单看返回结果的构造:
return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分
| datacenterId << DATACENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
复制代码
主要问题在于currStmp - START_STMP会重复,借此入手是否有可行的解决方案?
猜想1、在不影响后续时间戳差值及以前数据的情况下能否再产生一个新的时间戳差值?比如上述参数可食用的年限为69年,这里能不能使用69年以后的数据? 猜想2、在冬令时改变序列号的计算算法,使用4095以后未使用的数据; 复制代码
至此本次关于雪花算法的分享到此就结束了,欢迎大家在下方积极评论与交流,下期我们再会。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

