一张图看懂比特币、以太坊、联盟链等区块链系统架构
会当凌绝顶,一览众山小。进入区块链底层开发前,我们需要了解区块链底层的通用架构是如何设计的,从上而下地审视区块链底层的结构,做到了然于胸,才能胸有成竹。
他山之石,可以攻玉。在介绍区块链底层通用架构之前,我们不妨先从 比特币、以太坊、Hyperledger的架构解读开始。
比特币架构
根据中本聪的论文 《Bitcoin: A Peer-to-Peer Electronic Cash System》 中对比特币系统的描述,我们可以整理出如下图所示的比特币系统架构。
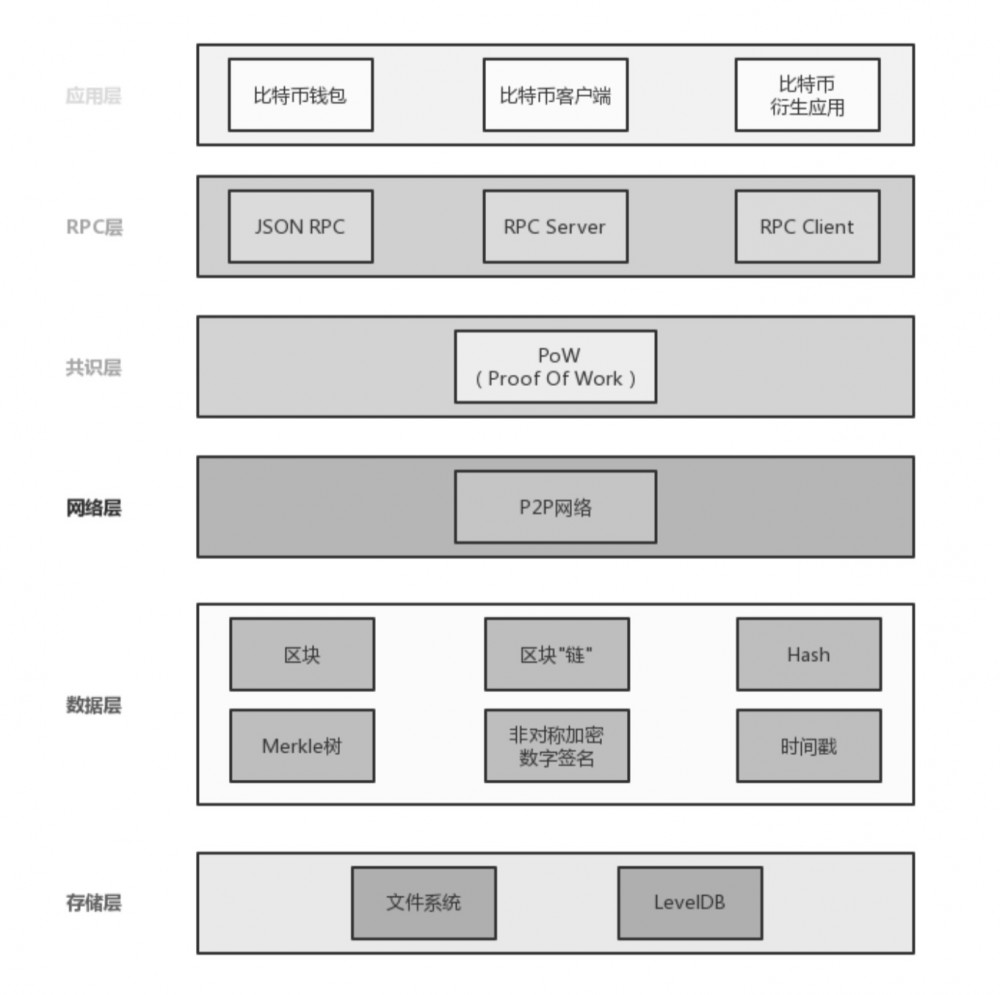
比特币系统架构
如图所示,比特币系统分为 6 层,由下至上依次是 存储层、数据层、网络层、共识层、RPC 层、应用层 。
其中, 存储层 主要用于存储比特币系统运行中的日志数据及区块链元数据,存储技术主要使用文件系统和 LevelDB。
数据层主要用于处理比特币交易中的各类数据,如将数据打包成区块,将区块维护成链式结构,区块中内容的加密与哈希计算,区块内容的数字签名及增加时间戳印记,将交易数据构建成 Merkle 树,并计算 Merkle 树根节点的哈希值等。
区块构成的链有可能分叉,在比特币系统中,节点始终都将最长的链条视为正确的链条,并持续在其后增加新的区块。
网络层用于构建比特币底层的 P2P 网络,支持多节点动态加入和离开,对网络连接进行有效管理,为比特币数据传输和共识达成提供基础网络支持服务。
共识层主要采用了 PoW(Proof Of Work)共识算法。在比特币系统中,每个节点都不断地计算一个随机数(Nonce),直到找到符合要求的随机数为止。在一定的时间段内,第一个找到符合条件的随机数将得到打包区块的权利,这构建了一个工作量证明机制。从 PoW 的角度,是不是发现 PoW 和分布式锁有异曲同工之妙呢?
RPC 层实现了 RPC 服务,并提供 JSON API 供客户端访问区块链底层服务。
应用层主要承载各种比特币的应用,如比特币开源代码中提供了 bitcoin client。该层主要是作为 RPC 客户端,通过 JSON API 与 bitcoin 底层交互。除此之外,比特币钱包及衍生应用都架设在应用层上。
以太坊架构
根据以太坊白皮书 《A Next-Generation Smart Contract and Decentralized Application Platform》 的描述,以太坊架构如下图所示。
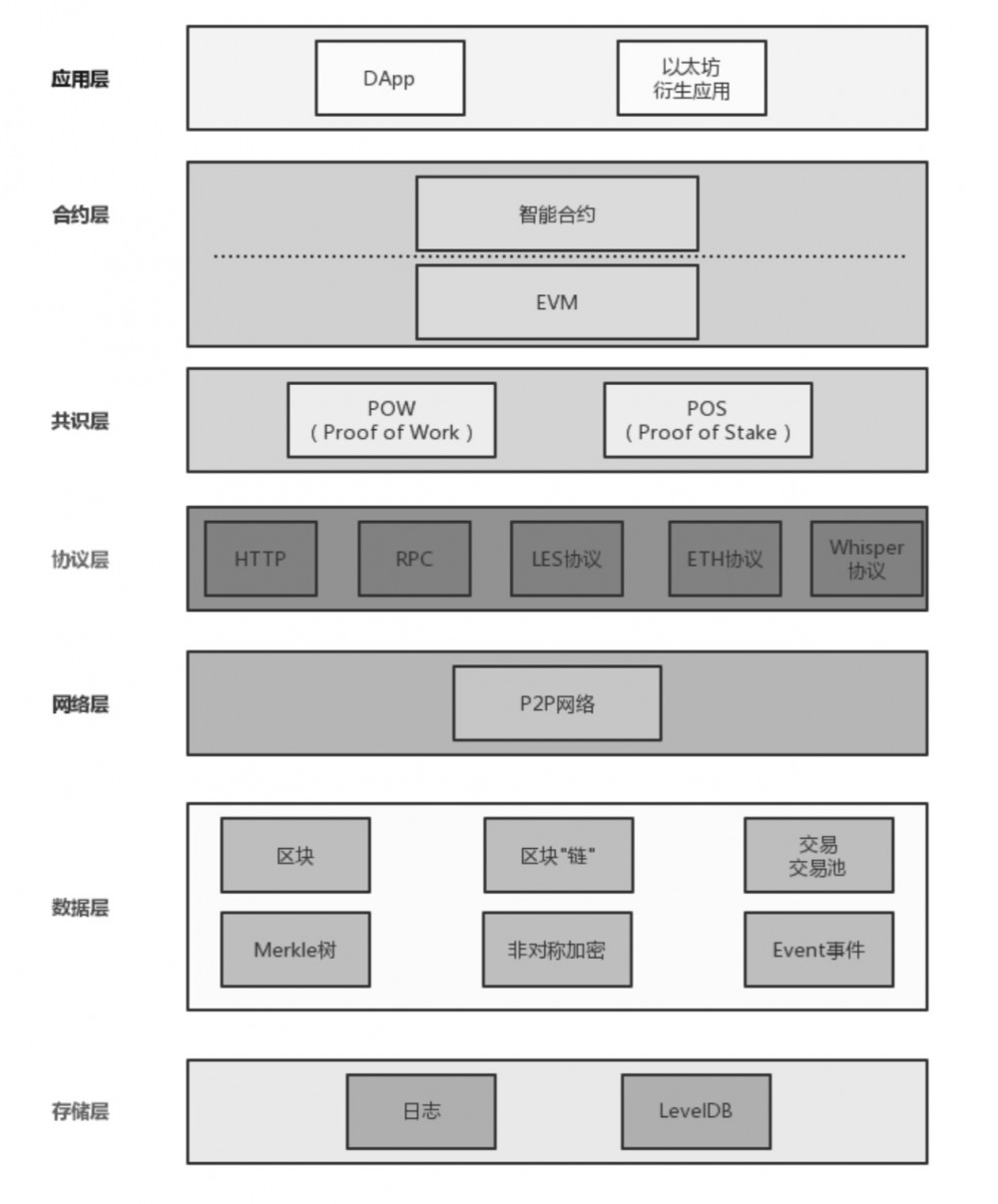
 以太坊架构
以太坊架构
如图所示,以太坊架构分为 7 层,由下至上依次是 存储层、数据层、网络层、协议层、共识层、合约层、应用层 。
其中 存储层 主要用于存储以太坊系统运行中的日志数据及区块链元数据,存储技术主要使用文件系统和 LevelDB。
数据层主要用于处理以太坊交易中的各类数据,如将数据打包成区块,将区块维护成链式结构,区块中内容的加密与哈希计算,区块内容的数字签名及增加时间戳印记,将交易数据构建成 Merkle 树,并计算 Merkle 树根节点的 hash 值等。
与比特币的不同之处在于以太坊引入了交易和交易池的概念。交易指的是一个账户向另一个账户发送被签名的数据包的过程。而交易池则存放通过节点验证的交易,这些交易会放在矿工挖出的新区块里。
以太坊的 Event(事件)指的是和以太坊虚拟机提供的日志接口,当事件被调用时,对应的日志信息被保存在日志文件中。
与比特币一样,以太坊的系统也是基于 P2P 网络的,在网络中每个节点既有客户端角色,又有服务端角色。
协议层是以太坊提供的供系统各模块相互调用的协议支持,主要有 HTTP、RPC协议、LES、ETH 协议、Whipser 协议等。
以太坊基于 HTTP Client 实现了对 HTTP 的支持,实现了 GET、POST 等 HTTP方法。外部程序通过 JSON RPC 调用以太坊的 API 时需通过 RPC (远程过程调用) 协议。
Whisper 协议用于 DApp 间通信。
LES 的全称是轻量级以太坊子协议(Light Ethereum Sub-protocol),允许以太坊节点同步获取区块时仅下载区块的头部,在需要时再获取区块的其他部分。
共识层在以太坊系统中有 PoW(Proof of Work)和 PoS(Proof of Stake)两种共识算法。
合约层分为两层,底层是 EVM(Ethereum Virtual Machine,即以太坊虚拟机),上层的智能合约运行在 EVM 中。智能合约是运行在以太坊上的代码的统称,一个智能合约往往包含数据和代码两部分。智能合约系统将约定或合同代码化,由特定事件驱动触发执行。因此,在原理上适用于对安全性、信任性、长期性的约定或合同场景。在以太坊系统中,智能合约的默认编程语言是 Solidity,一般学过 JavaScript 语言的读者很容易上手 Solidity。
应用层有 DApp(Decentralized Application,分布式应用)、以太坊钱包等多种衍生应用,是目前开发者最活跃的一层。
Hyperledger 架构
超级账本(Hyperledger)是 Linux 基金会于 2015 年发起的推进区块链数字技术和交易验证的开源项目,该项目的目标是 推进区块链及分布式记账系统的跨行业发展与协作 。
目前该项目最著名的子项目是 Fabric,由 IBM 主导开发。按官方网站描述,Hyperledger Fabric 是分布式记账解决方案的平台,以模块化体系结构为基础,提供高度的弹性、灵活性和可扩展性。它旨在支持不同组件的可插拔实现,并适应整个经济生态系统中存在的复杂性。
Hyperledger Fabric 提供了一种独特的弹性和可扩展的体系结构,使其不同于其他区块链解决方案。我们必须在经过充分审查的开源架构之上对区块链企业的未来进行规划。超级账本是企业级应用快速构建的起点。
目前,Hyperledger Fabric 经历了两大版本架构的迭代,分别是 0.6 版和 1.0 版。其中,0.6 版的架构相对简单,Peer 节点集众多功能于一身,模块化和可拓展性较差。1.0 版对 0.6 版的 Peer 节点功能进行了模块化分解。目前最新的 1.1 版本处于 Alpha 阶段。
在 1.0 版中,Peer 节点可分为 peers 节点和 orderers 节点。peers 节点用于维护状态(State)和账本(Ledger),orderers 节点负责对账本中的各条交易达成共识。
系统中还引入了认证节点(Endorsing Peers),认证节点是一类特殊的 peers 节点, 负责同时执行链码(Chaincode)和交易的认证(Endorsing Transactions)。
Hyperledger Fabric 的分层架构设计如图下所示。
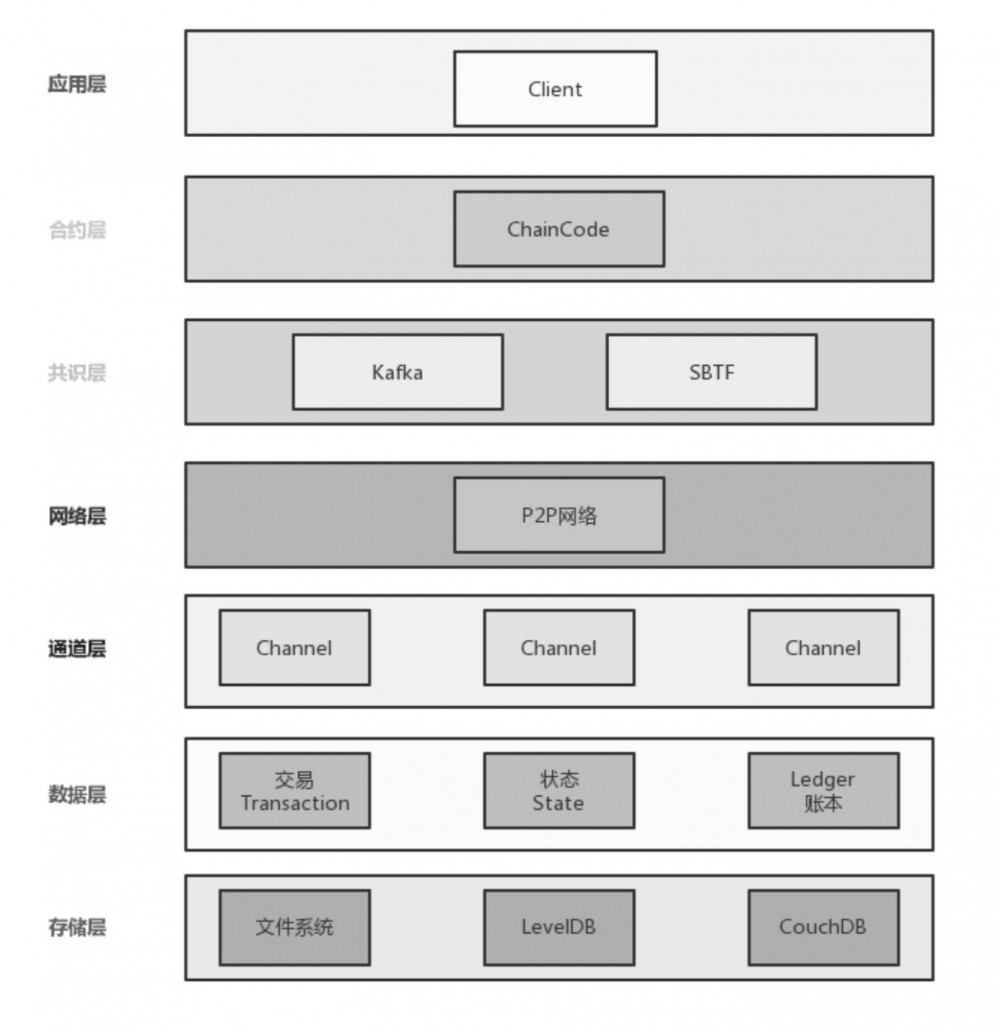
Hyperledger Fabric 的分层架构设计
Hyperledger Fabric 可以分为7层,分别是 存储层、数据层、通道层、网络层、共识层、合约层、应用层 。
其中 存储层 主要对账本和交易状态进行存储。账本状态存储在数据库中,存储的内容是所有交易过程中出现的键值对信息。比如,在交易处理过程中,调用链码执行交易可以改变状态数据。状态存储的数据库可以使用 LevelDB 或者 CouchDB。LevelDB 是系统默认的内置的数据库,CouchDB 是可选的第三方数据库。区块链的账本则在文件系统中保存。
数据层主要由交易(Transaction)、状态(State)和账本(Ledger)三部分组成。
其中,交易有两种类型:
- 部署交易:以程序作为参数来创建新的交易。部署交易成功执行后, 链码就被安装到区块链上。
- 调用交易:在上一步部署好的链码上执行操作。链码执行特定的函数,这个函数可能会修改状态数据,并返回结果。
状态对应了交易数据的变化。在 Hyperledger Fabric 中,区块链的状态是版本化的,用 key/value store(KVS) 表示。其中 key 是名字,value 是任意的文本内容,版本号标识这条记录的版本。这些数据内容由链码通过 PUT 和 GET 操作来管理。如存储层的描述,状态是持久化存储到数据库的,对状态的更新是被文件系统记录的。
账本提供了所有成功状态数据的改变及不成功的尝试改变的历史。
账本是由 Ordering Service 构建的一个完全有序的交易块组成的区块哈希链 (Hash Chain)。
账本既可以存储在所有的 peers 节点上,又可以选择存储在几个 orderers 节点上。 此外,账本允许重做所有交易的历史记录,并且重建状态数据。
通道层指的是通道 (Channel),通道是一种 Hyperledger Fabric 数据隔离机制,用于保证交易信息只有交易参与方可见。每个通道都是一个独立的区块链,因此多个用户可以共用同一个区块链系统,而不用担心信息泄漏问题。
网络层用于给区块链网络中各个通信节点提供 P2P 网络支持,是保障区块链账本一致性的基础服务之一。
在 Hyperledger Fabric 中,Node 是区块链的通信实体。Node 仅仅是一个逻辑上的功能,多个不同类型的 Node 可以运行在同一个物理服务器中。Node 有三种类型,分别是客户端、peers 节点和 Ordering Service。
其中,客户端用于把用户的交易请求发送到区块链网络中。
peers 节点负责维护区块链账本,peers 节点可以分为 endoring peers 和 committing peers 两种。endoring peers 为交易作认证,认证的逻辑包含验证交易的有效性,并对交易进行签名;committing peers 接收打包好的区块,并写入区块链中。与 Node 类似,peers节点也是逻辑概念,endoring peers 和 committing peers 可以同时部署在一台物理机上。
Ordering Service 会接收交易信息,并将其排序后打包成区块,然后,写入区块链中,最后将结果返回给 committing peers。
共识层基于 Kafka、SBTF 等共识算法实现。Hyperledger Fabric 利用 Kafka 对交易信息进行排序处理,提供高吞吐、低延时的处理能力,并且在集群内部支持节点故障容错。相比于 Kafka,SBFT(简单拜占庭算法)能提供更加可靠的排序算法,包括容忍节点故障以及一定数量的恶意节点。
合约层是 Hyperledger Fabric 的智能合约层 Blockchain,Blockchain 默认由 Go 语言实现。Blockchain 运行的程序叫作链码,持有状态和账本数据,并负责执行交易。在Hyperledger Fabric 中,只有被认可的交易才能被提交。而交易是对链码上的操作的调用,因此链码是核心内容。同时还有一类称之为系统链码的特殊链码,用于管理函数和参数。
应用层是 Hyperledger Fabric 的各个应用程序。
此外,既然是联盟链,在 Hyperledger Fabric中 还有一个模块专门用于对联盟内的成员进行管理,即 Membership Service Provider(MSP),MSP 用于管理成员认证信息,为客户端和 peers 节点提供成员授权服务。
区块链通用架构
至此,我们已经了解了比特币、以太坊和 Hyperledger 的架构设计, 三者根据使用场景的不同而有不同的设计 ,但还是能抽象出一些共同点,我们可以基于这些共同点设计企业级联盟链的底层架构。
本文提供的联盟链底层架构如下图所示。
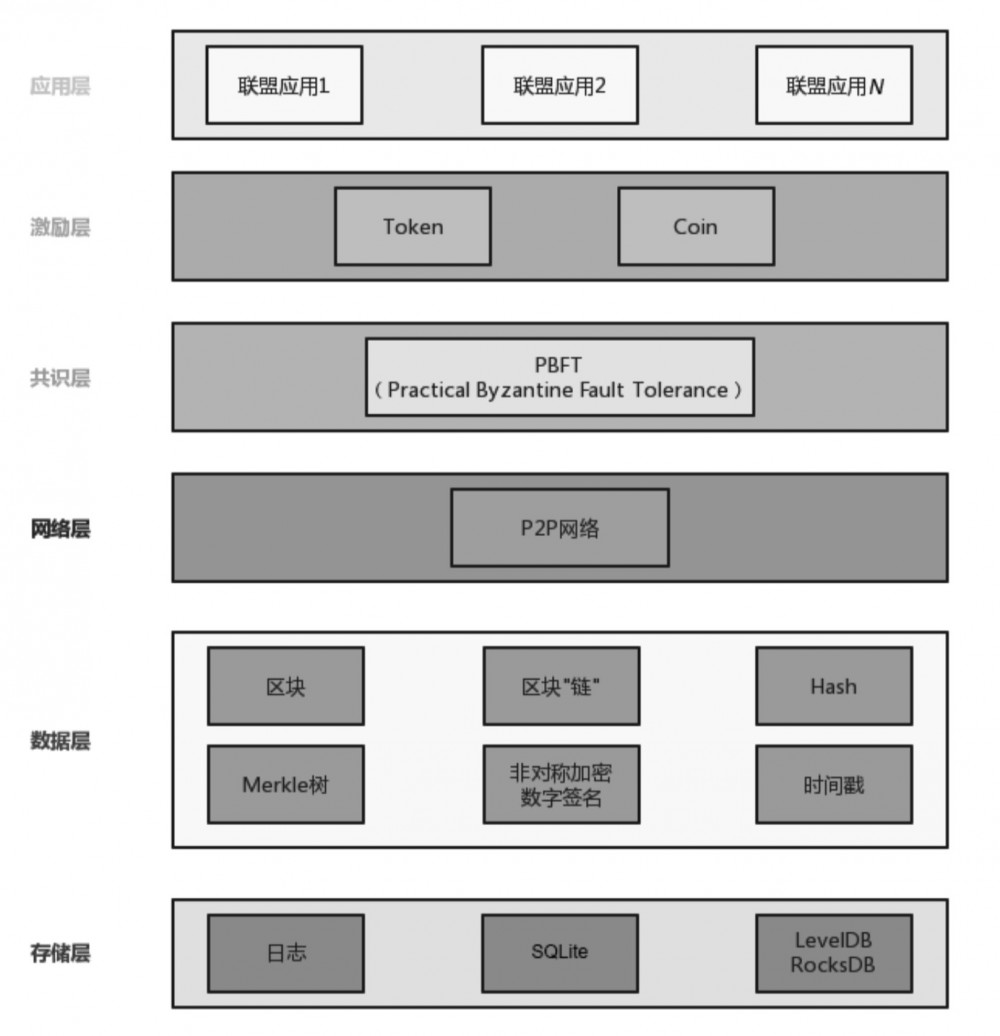
联盟链底层架构
我们将区块链底层分为 6 层,从下至上分别是 存储层、数据层、网络层、共识层、激励层和应用层 。
存储层主要存储交易日志和交易相关的内容。其中,交易日志基于 LogBack 实现。交易的内容由内置的 SQLite 数据库存储,读写 SQLite 数据库可以基于 JPA 实现;交易的上链元数据信息由 RocksDB 或 LevelDB 存储。
数据层由区块和区块“链”(区块的链式结构)组成。其中,区块中还会涉及交易列表在 Merkle 树中的存储及根节点哈希值的计算。交易的内容也需要加密处理。由于在联盟链中有多个节点,为有效管理节点数据及保障数据安全,建议为不同节点分配不同的公、私钥,以便加密使用。
网络层主要提供共识达成及数据通信的底层支持。在区块链中,每个节点既是数据的发送方,又是数据的接收方。可以说每个节点既是客户端,又是服务端,因此需要基于长连接来实现。我们可以基于 WebSocket 用原生方式建立长连接,也可以基于长连接第三方工具包实现。
共识层采用 PBFT(Practical Byzantine Fault Tolerance)共识算法。不同于公链的挖矿机制,联盟链中更注重各节点信息的统一,因此可以省去挖矿,直奔共识达成的目标。
激励层主要是币(Coin)和 Token 的颁发和流通。在公链中,激励是公链的灵魂;但在联盟链中不是必需的。
应用层主要是联盟链中各个产品的落地。一般联盟链的应用层都是面向行业的,解决行业内的问题。
Java 版联盟链的部署架构如下图所示。
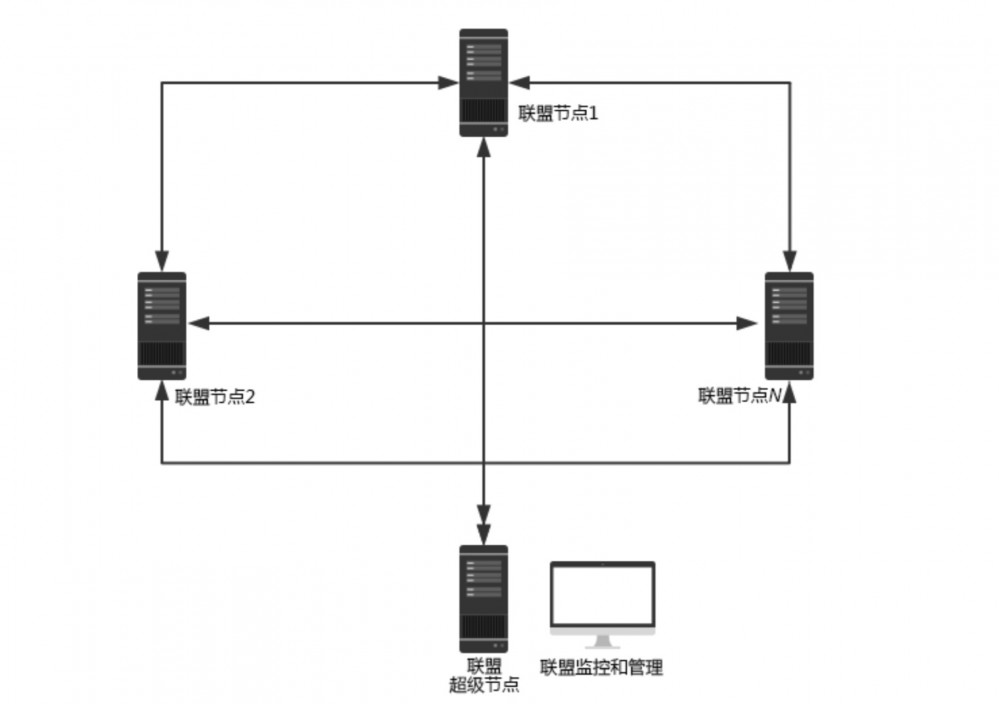
Java 版联盟链的部署架构
联盟链由 1 个超级节点和若干个普通节点组成,超级节点除具备普通节点的功能外,还具备在联盟中实施成员管理、权限管理、数据监控等工作。因此相较于完全去中心化的公链,联盟链是部分去中心化的,或者说 联盟的“链”是去中心化的,但是联盟链的管理是中心化的。
整个开发环境建议基于 Spring Boot 2.0 实现。基于 Spring Boot 开发,可以省去大量的 xml 配置文件的编写,能极大简化工程中在 POM 文件配置的复杂依赖。Spring Boot 还提供了各种 starter,可以实现自动化配置,提高开发效率。
来源:区块链大本营
作者:乔治
正文到此结束
- 本文标签: 开源 tar 配置 2015 管理 文件系统 java key 架构设计 pom 网站 企业 开发者 Action 灵魂 分布式 认证 锁 部署 安装 下载 开源项目 长连接 spring XML token 自动化 cat 同步 UI JavaScript 时间 Spring Boot 协议 开发 加密 js sql http NSA IO linux json 分布式锁 db provider 产品 基金 JPA 代码 id 服务器 参数 Logback https 安全 src IDE ORM App Go 语言 node 数据库 系统架构 SQLite API 服务端 web value 对账 ip 集群 client 数据 Service 智能 一致性 IBM
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

