mybatis源码解读---一条sql的旅程
前言:本文从原始的mybatis源码开始分析一条sql语句的执行过程,我们常用的mybatis基本都是spring封装过的,本文不涉及spring封装部分。
一、mybatis使用步骤
我们先通过一个简单的实例回顾一下原生mybatis的使用步骤
场景:我们要通过用户id获取用户的详细信息,使用mybatis要经过如下四个步骤(sql如下)
select user_id as userId,user_name userName,age from op_user_info where user_id>#{userId}
复制代码
1.配置mybatis-config.xml文件
其中最重要的两个配置一个是dataSource(数据源)、mappers(mapper文件路径)
<configuration>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
<mappers>
<mapper class="classpath*:mybatis/UserMapper.xml"/>
</mappers>
....
</configuration>
复制代码
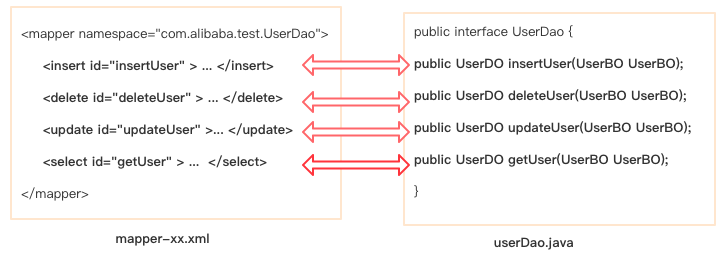
2.编写一个mappr-xx.xml文件
<mapper namespace="com.alibaba.test.UserDao">
<select id="getUser" parameterType="com.alibaba.test.UserBO"
resultType="com.alibaba.test.UserDO">
select user_id as userId,user_name userName,age from op_user_info where user_id>#{userId}
</select>
......
</mapper>
复制代码
3.编写一个接口Interface
public interface UserDao {
public UserDO getUser(UserBO UserBO)
.......
}
复制代码
<!--注意这里接口的方法名和mappr-xx.xml中的id一一对应-->
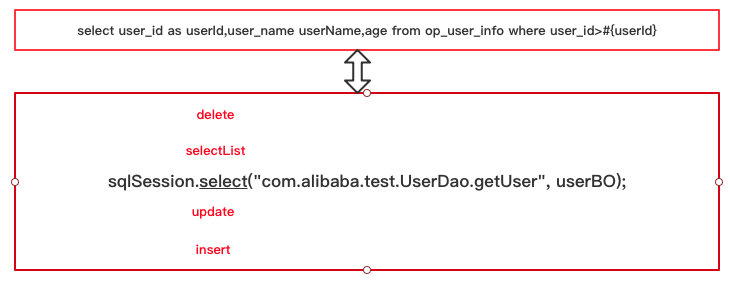
4.开始查询数据库
注意我们在查询数据的时候有两种选择
4.1 第一种方式,使用SqlSession的方法直接获取
SqlSession sqlSession = sqlSessionFactory.openSession();
try {
UserBO userBO= new UserBO();
userBO.setUserId(148736);
UserDO user = (UserDO) sqlSession.select("com.alibaba.test.UserDao.getUser", userBO);
} finally {
session.close();
}
复制代码
注意mybatis所有的操作增删改查都是从这句代码开始,后面我们分析sql的执行流程时也将从这句代码开始。

4.2 第二种方式,通过接口UserDao的实现类获取
SqlSession session = sqlSessionFactory.openSession();
try {
UserBO userBO= new UserBO();
userBO.setUserId(148736);
UserDao userDao = session.getMapper(UserDao.class);
UserDO user userDao.getUser(userBO);
} finally {
session.close();
}
复制代码
分析:第二种方式使用了动态代理的方式获取了Interface(UserDao)的实现类,最终还是通过第一种方式获取数据,一直跟踪代码在MapperProxy类中可以找到这段逻辑
public class MapperProxy<T> implements InvocationHandler, Serializable {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (Object.class.equals(method.getDeclaringClass())) {
try {
return method.invoke(this, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
final MapperMethod mapperMethod = cachedMapperMethod(method);
return mapperMethod.execute(sqlSession, args);
}
}
复制代码
所以我们得出结论mybatis所有的操作增删改查都是从这句代码开始
二、mybatis初始化
在此之前我们先了解下mybatis初始化阶段做了些什么事情,顺便找出我们的主角SqlSession是怎么产生的
1.mybatis初始化逻辑
1)String resource = "org/mybatis/example/mybatis-config.xml"; 2)InputStream inputStream = Resources.getResourceAsStream(resource); 3)SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream); 4)SqlSession session = sqlSessionFactory.openSession(); 复制代码
跟踪第二行代码可以看到mybatis将配置文件mybatis-config.xml中的所有信息都解析到了工厂类SqlSessionFactory中,SqlSessionFactory将所有的配置信息保存在了Configuration类中。SqlSession就是从SqlSessionFactory中创建的。
2.Configuration类
Configuration中存放了mybatis-config.xml中的所有配置信息

其中
1)Environment environment封装了数据源信息

2) protected final Map mappedStatements 封装了mapepr-xx.xml中的信息。
其中Map的key为mapepr-xx.xml中中的namespace+id,MappedStatement封装了
….

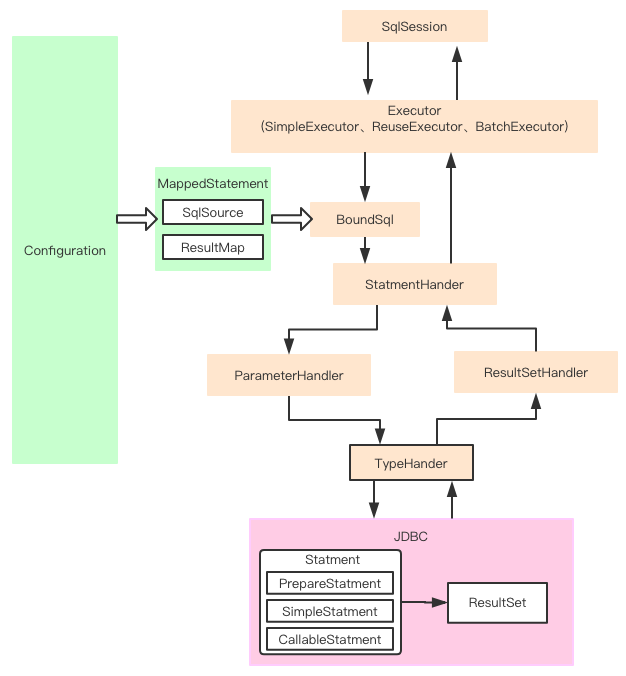
三、mybatis中几个重要的类
-
SqlSession 作为MyBatis工作的主要顶层API,表示和数据库交互的会话,完成必要数据库增删改查功能
-
Executor MyBatis执行器,是MyBatis 调度的核心,负责SQL语句的生成和查询缓存的维护
-
StatementHandler 封装了JDBC Statement操作,负责对JDBC statement 的操作,如设置参数、将Statement结果集转换成List集合。
-
ParameterHandler 负责对用户传递的参数转换成JDBC Statement 所需要的参数,
-
ResultSetHandler 负责将JDBC返回的ResultSet结果集对象转换成List类型的集合;
-
TypeHandler 负责java数据类型和jdbc数据类型之间的映射和转换
-
MappedStatement MappedStatement维护了一条节点的封装,
-
SqlSource 负责根据用户传递的parameterObject,动态地生成SQL语句,将信息封装到BoundSql对象中,并返回
-
BoundSql 表示动态生成的SQL语句以及相应的参数信息
-
Configuration MyBatis所有的配置信息都维持在Configuration对象之中。
四、数据查询的执行流程
1.通过第一篇文章的分析我们知道所有的执行流程从这句代码开始,其中"com.alibaba.test.UserDao.getUser"是
Configuration类中 Map mappedStatements的key值。
UserDO user = (UserDO) sqlSession.select("com.alibaba.test.UserDao.getUser", userBO);
复制代码
2.进入select方法发现首先根据statementId从 Map mappedStatements中获取到了封装的MappedStatement,然后将数据查询操作委托给了Executor executor。
public void select(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
executor.query(ms, wrapCollection(parameter), rowBounds, handler);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
复制代码
3.跟踪executor的query方法。说道Executor,mybatis有三种,他们的区别如下
SimpleExecutor :每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。(可以是Statement或PrepareStatement对象)
ReuseExecutor :执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map内,供下一次使用。(可以是Statement或PrepareStatement对象),代码如下
BatchExecutor :执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理的;
我们进入SimpleExecutor的query方法,在这个方法中通过ms.getBoundSql(parameter)生成了具体运行的sql。并将结果存在了BoundSql中。并为当前的查询创建一个缓存Key ,至此我们得到了一个可以正常运行的完整sql。
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 1.根据具体传入的参数,动态地生成需要执行的SQL语句,用BoundSql对象表示
BoundSql boundSql = ms.getBoundSql(parameter);
// 2.为当前的查询创建一个缓存Key
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
复制代码
4.继续跟踪query(ms, parameter, rowBounds, resultHandler, key, boundSql);
这段代码中根据上一步获取的CacheKey从缓存中获取结果,如果缓存结果为空则调用
queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
复制代码
5.我们继续跟踪queryFromDatabase。这个方法先执行查询返回list并将结果存入缓存中。
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//4. 执行查询,返回List 结果,然后 将查询的结果放入缓存之中
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
复制代码
6.根据 doQuery(ms, parameter, rowBounds, resultHandler, boundSql);方法。以上都是抽象类BaseExecutor中的方法。至此进入默认实现类SimpleExecutor。
SimpleExecutor.doQuery源码
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
// 根据既有的参数,创建StatementHandler对象来执行查询操作
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
//创建java.Sql.Statement对象,传递给StatementHandler对象
stmt = prepareStatement(handler, ms.getStatementLog());
//调用StatementHandler.query()方法,返回List结果集
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
复制代码
该函数的作用如下:
6.1 根据既有的参数,创建StatementHandler对象来执行查询操作,在这段代码中我们发现了 interceptorChain.pluginAll(statementHandler) ,我们经常见到的mybatis拦截器就是在这个地方开始生效的。
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
复制代码
6.2 调用prepareStatement方法创建java.Sql.Statement对象,并对创建的Statement对象设置参数,即设置SQL 语句中 ? 设置为指定的参数 ,最后传递给StatementHandler对象
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}
复制代码
6.3 调用StatementHandler.query()方法
StatementHandler对象负责设置Statement对象中的查询参数、处理JDBC返回的resultSet,将resultSet加工为List
6.3.1进入PreparedStatementHandler的query方法,该函数中终于看到了我们熟悉的代码。进行了最终的数据库查询操作。并将结果交给了ResultSetHandler处理
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
return resultSetHandler.<E> handleResultSets(ps);
复制代码
6.3.2 跟踪ResultSetHandler的实现类DefaultResultSetHandler。找到了handleResultSets方法。
ResultSetHandler的handleResultSets(Statement) 方法会将Statement语句执行后生成的resultSet 结果集转换成List 结果集
@Override
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0;
ResultSetWrapper rsw = getFirstResultSet(stmt);
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
ResultMap resultMap = resultMaps.get(resultSetCount);
handleResultSet(rsw, resultMap, multipleResults, null);
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
return collapseSingleResultList(multipleResults);
}
复制代码
五、总结
sql执行流程总结如下:
1.调用SqlSession的select方法,传入StatementId(Mappr-xx.xml的namespace+id)和查询条件参数
2.调用Configuration的getMappedStatement方法获取StatementId对应的MappedStatement,并调用Executor的query方法
3.调用Executor的query方法,根据入参获取具体的sql,封装到BoundSql中
4.创建StatementHandler对象执行查询操作
5.ResultSetHandler将查询结果转化为需要的格式

正文到此结束
- 本文标签: executor Statement ip UI 解析 mybatis lib SqlSessionFactoryBuilder cache JDBC db 配置 App REST build Action StatementHandler equals tab map CTO list example Property ArrayList stream 源码 sql 代码 value Connection 文章 plugin session zab classpath cat API key dataSource ACE sqlsession id 缓存 update 数据库 NSA XML 总结 Word SQL执行 Collection Proxy java IDE 实例 final http mapper IO ResultSet spring https 数据 Select 参数 src SqlSessionFactory
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

