互联网架构三板斧之并发
由于营销活动(创造营销节点、扩大影响力的需要),总有很多产品策划、运营乐此不疲的玩着一个game---在足够集中的时间内比如秒级处理足够多的用户请求,让世界为此狂欢,同时也是彰显技术实力的一次大考。
小米卖着抢号的手机、天猫发明了双11光棍节、微信和支付宝连续2年做着新春红包。 营销活动的时候要使用前2板斧,保证可用性和简单可扩展性,同时还要祭出第三板绝杀—拦河大坝、缓存为王、去热点资源的并发。
为啥要拦?很简单,用户很热情(感性),但系统必须得理性!就3个苹果手机,凭啥让几十万人都涌入柜台!在大秒系统一文中许同学就娓娓道来(省得少画个图)……
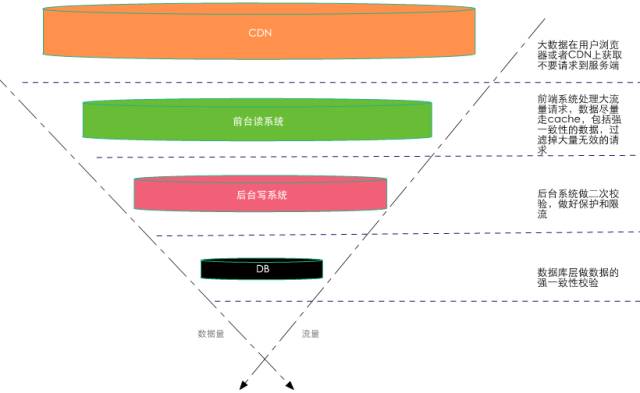
对大流量系统的数据做分层校验也是最重要的设计原则,所谓分层校验就是对大量的请求做成“漏斗”式设计,如上图所示:在不同层次尽可能把无效的请求过滤,“漏斗”的最末端才是有效的请求,要达到这个效果必须对数据做分层的校验,下面是一些原则:
1
先做数据的动静分离
2
将90%的数据缓存在客户端浏览器
3
将动态请求的读数据Cache在Web端
4
对读数据不做强一致性校验
5
对写数据进行基于时间的合理分片
6
对写请求做限流保护
7
对写数据进行强一致性校验
将90%的数据缓存在客户端浏览器,将动态请求的读数据cache在web端,还是不够的。在大秒的过程中,存在极端情况,就是请求超过单key所在server的QPS能力。
数据访问热点,比如Detail中对某些热点商品的访问度非常高,即使是Tair缓存这种Cache本身也有瓶颈问题,一旦请求量达到单机极限也会存在热点保护问题。有时看起来好像很容易解决,比如说做好限流就行,但你想想一旦某个热点触发了一台机器的限流阀值,那么这台机器Cache的数据都将无效,进而间接导致Cache被击穿,请求落地应用层数据库出现雪崩现象。这类问题需要与具体Cache产品结合才能有比较好的解决方案,这里提供一个通用的解决思路,就是在Cache的client端做本地Localcache,当发现热点数据时直接Cache在client里,而不要请求到Cache的Server。
数据更新热点,更新问题除了前面介绍的热点隔离和排队处理之外,还有些场景,如对商品的lastmodifytime字段更新会非常频繁,在某些场景下这些多条SQL是可以合并的,一定时间内只执行最后一条SQL就行了,可以减少对数据库的update操作。另外热点商品的自动迁移,理论上也可以在数据路由层来完成,利用前面介绍的热点实时发现自动将热点从普通库里迁移出来放到单独的热点库中。
心得体会
请允许笔者总结一下高并发方案的解决之道。
使用缓存,能越前端缓存的放在前端,
这样调用链路最短。
这里的缓存不仅仅是redis、或者memcached,而是local或者climatchent优先的思路,去除对并发资源的依赖。比如[ 揭秘微信摇一摇背后的技术细节 ]一文中提到:
按一般的系统实现,用户看到的红包在系统中是数据库中的数据记录,抢红包就是找出可用的红包记录,将该记录标识为match属于某个用户。在这种实现里,数据库是系统的瓶颈和主要成本开销。我们在这一过程完全不使用数据库,可以达到几个数量级的性能提升,同时可靠性有了更好的保障。
1
支付系统将所有需要下发的红包生成红包票据文件;
2
将红包票据文件拆分后放到每一个接入服务实例中;
3
接收到客户端发起摇一摇请求后,接入服务里的摇一摇逻辑拿出一个红包票据,在本地生成一个跟用户绑定的加密票据,下发给客户端;
4
客户端拿加密票据到后台拆红包,match后台的红包简化服务通过本地计算即可验证红包,完成抢红包过程。
分拆热点
上文提到,在极端情况下大秒使用了二级缓存,通过拆分key来达到避免超过cache server请求能力的问题。在facebook有一招,就是通过多个key_index(key:xxx#N) ,来获取热点key的数据,其实质也是把key分散。对于非高一致性要求的高并发读还是蛮有效的。 如图
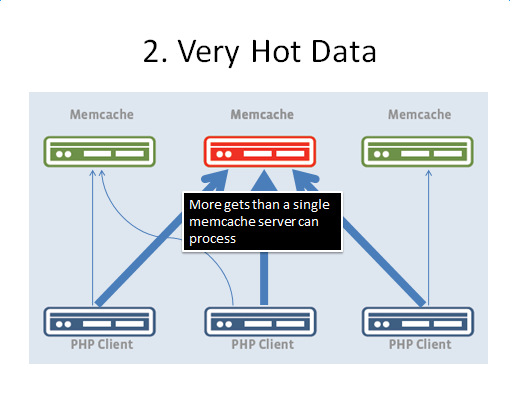
则解决之道是:
• Hot keys are published to all web-servers
• Each web-server picks an alias for gets
– get key:xxx => get key:xxx#N
• Each web-server deletes all aliases
微博团队披露:服务端本地缓存,使用nginx本身缓存和服务器的L0缓存,来提升模块的响应速度,做到了90%以上核心接口的响应时间在50ms以内,减少了进程等待时间,提升了服务器的处理速度。
解决并发有1种基本办法: 分拆!而分拆有两种拆法,
1
拆资源
一是把资源(resource)拆了,著名的比如ConcurrentHashMap,拆成了16个桶,并发能力大大提高。
2
拆基础数据
在红包应用中,如果还依赖一个共同的基础数据,也可以把这个基础数据拆成多个cell。
预处理
[ 互动1808亿次,16倍的超越!谈支付宝红包的高并发挑战 ]一文中如此说:
“
在这次春晚活动中,涉及到大量的资源,包括图片、拜年视频等。图片和视频都比较大,十几b到几百kb不等。当在高峰期时,如果瞬间有海量的请求到CDN上,这么大的请求带宽根本扛不住。我们当时预估了大约有几T的带宽需求。
为了能有效地扛住瞬间峰值对CDN的压力,我们对资源进行了有效的管理和控制。首先在客户端预埋了几个缺省资源,万一真不行了,这几个资源可以用。其次尽量提前打开入口,当用户浏览过后,就将资源下载到本地。再次浏览时不再需要远程访问CDN。最后,做了应急预案,高峰期一旦发现流量告警,紧急从视频切换到图片,降低带宽压力,确保不出现带宽不够而发生限流导致的黑屏等体验不好的问题。
最后的结果可以用完美来形容,由于预热充分,带宽虽然很高,但没达到我们的告警值,应急预案也没有使用。
”
微信团队也提到:
“
在除夕,用户通过摇一摇参与活动,可以摇到红包或其他活动页,这些页面需要用到很多图片、视频或 H5 页面等资源。在活动期间,参与用户多,对资源的请求量很大,如果都通过实时在线访问,服务器的网络带宽会面临巨大压力,基本无法支撑;另外,资源的尺寸比较大,下载到手机需要较长时间,用户体验也会很差。因此, 我们采用预先下载的方式,在活动开始前几天把资源推送给客户端,客户端在需要使用时直接从本地加载。
”
异步化
江湖传说中有一句话,叫能异步的尽量异步。做活动的时候,资源多宝贵啊,对C端无感但可以容忍的,就让它慢慢做,而此种一般放入到队列当中。
杭州的蘑菇街七公又名小白,是一个热情的朋友。他提及交易服务依赖过多的解决之道。服务依赖过多,会带来管理复杂性增加和稳定性风险增大的问题。试想如果我们强依赖10个服务,9个都执行成功了,最后一个执行失败了,那么是不是前面9个都要回滚掉?这个成本还是非常高的。所以在拆分大的流程为多个小的本地事务的前提下,对于非实时、非强一致性的关联业务写入,在本地事务执行成功后,我们选择发消息通知、关联事务异步化执行的方案。(看看下图,那些可以异步化?)
使用队列
拦、拦、拦;之后缓存抗;缓存扛不住的并发分拆;但是还有一个问题,就是极端热点资源在db里,如果并发高还是会出问题。大秒一文中有较好的处理方案,就是排队。Web服务器排队,在db层还做了一个patch排队,真心是业务是最好的老师,不得已何必祭大招!
应用层做排队。按照商品维度设置队列顺序执行,这样能减少同一台机器对数据库同一行记录操作的并发度,同时也能控制单个商品占用数据库连接的数量,防止热点商品占用太多数据库连接。 关于详情,可以阅读大秒一文。
引用
引用内容 from:
《互动1808亿次,16倍的超越!谈支付宝红包的高并发挑战》- QCon公众号
《10亿红包从天而降,揭秘微信摇一摇背后的技术细节》 - InfoQ网站
《淘宝大秒系统设计详解》- CSDN
《解密微博红包:架构、防刷、监控和资源调度》 - InfoQ网站
http://www.slideshare.net/jboner/scalability-availability-stability-patterns
LiveJournal's Backend - A history of scaling
本公众号编辑部维护读者群之架构群,邀请了坐馆老司机曲健、伟山、安晓辉、史海峰嘉宾等参与交流。加群请在公众号回复:架构群。
往期推荐:
-
面试总被问高并发,你真的会么?
-
研发职位到底应该怎么设置?
-
如何打造有战斗力的团队
-
什么样的 TL 是好的 TL ?
-
再好的技术,再完美的规章,也无法取代人自身的素质和责任心
技术琐话
以分布式设计、架构、体系思想为基础,兼论研发相关的点点滴滴,不限于代码、质量体系和研发管理。

正文到此结束
- 本文标签: Nginx 数据库 map SDN 总结 ACE 二级缓存 ConcurrentHashMap web sql 管理 滴滴 http 数据缓存 HashMap update CDN 双11 Facebook 小米 运营 cache 一致性 远程访问 https 网站 IDE key src scala 高并发 加密 质量 产品 redis 实例 client 营销 分布式 并发 db 互联网 数据 时间 微博 支付系统 id 限流 tab 压力 UI 需求 下载 服务端 QPS 服务器 进程 支付宝 代码 苹果 红包 图片 缓存
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

