容器监控实践—Prometheus的配置与服务发现
本文将分析Prometheus的常见配置与服务发现,分为概述、配置详解、服务发现、常见场景四个部分进行讲解。
一. 概述
Prometheus的配置可以用命令行参数、或者配置文件,如果是在k8s集群内,一般配置在configmap中(以下均为prometheus2.7版本)
查看可用的命令行参数,可以执行 ./prometheus -h
也可以指定对应的配置文件,参数:--config.file 一般为prometheus.yml
如果配置有修改,如增添采集job,Prometheus可以重新加载它的配置。只需要向其
进程发送SIGHUP或向/-/reload端点发送HTTP POST请求。如:
curl -X POST http://localhost:9090/-/reload
二. 配置详解
2.1 命令行参数
执行./prometheus -h 可以看到各个参数的含义,例如:
--web.listen-address="0.0.0.0:9090" 监听端口默认为9090,可以修改只允许本机访问,或者为了安全起见,可以改变其端口号(默认的web服务没有鉴权) --web.max-connections=512 默认最大连接数:512 --storage.tsdb.path="data/" 默认的存储路径:data目录下 --storage.tsdb.retention.time=15d 默认的数据保留时间:15天。原有的storage.tsdb.retention配置已经被废弃 --alertmanager.timeout=10s 把报警发送给alertmanager的超时限制 10s --query.timeout=2m 查询超时时间限制默认为2min,超过自动被kill掉。可以结合grafana的限时配置如60s --query.max-concurrency=20 并发查询数 prometheus的默认采集指标中有一项prometheus_engine_queries_concurrent_max可以拿到最大查询并发数及查询情况 --log.level=info 日志打印等级一共四种:[debug, info, warn, error],如果调试属性可以先改为debug等级 .....
在prometheus的页面上,status的Command-Line Flags中,可以看到当前配置,如promethues-operator的配置是:

2.2 prometheus.yml
从官方的 download页 下载的promethues二进制文件,会自带一份默认配置prometheus.yml
-rw-r--r--@ LICENSE -rw-r--r--@ NOTICE drwxr-xr-x@ console_libraries drwxr-xr-x@ consoles -rwxr-xr-x@ prometheus -rw-r--r--@ prometheus.yml -rwxr-xr-x@ promtool
prometheus.yml配置了很多属性,包括远程存储、报警配置等很多内容,下面将对主要属性进行解释:
# 默认的全局配置
global:
scrape_interval: 15s # 采集间隔15s,默认为1min一次
evaluation_interval: 15s # 计算规则的间隔15s默认为1min一次
scrape_timeout: 10s # 采集超时时间,默认为10s
external_labels: # 当和其他外部系统交互时的标签,如远程存储、联邦集群时
prometheus: monitoring/k8s # 如:prometheus-operator的配置
prometheus_replica: prometheus-k8s-1
# Alertmanager的配置
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093 # alertmanager的服务地址,如127.0.0.1:9093
alert_relabel_configs: # 在抓取之前对任何目标及其标签进行修改。
- separator: ;
regex: prometheus_replica
replacement: $1
action: labeldrop
# 一旦加载了报警规则文件,将按照evaluation_interval即15s一次进行计算,rule文件可以有多个
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# scrape_configs为采集配置,包含至少一个job
scrape_configs:
# Prometheus的自身监控 将在采集到的时间序列数据上打上标签job=xx
- job_name: 'prometheus'
# 采集指标的默认路径为:/metrics,如 localhost:9090/metric
# 协议默认为http
static_configs:
- targets: ['localhost:9090']
# 远程读,可选配置,如将监控数据远程读写到influxdb的地址,默认为本地读写
remote_write:
127.0.0.1:8090
# 远程写
remote_read:
127.0.0.1:8090
2.3 scrape_configs配置
prometheus的配置中,最常用的就是scrape_configs配置,比如添加新的监控项,修改原有监控项的地址频率等。
最简单配置为:
scrape_configs:
- job_name: prometheus
metrics_path: /metrics
scheme: http
static_configs:
- targets:
- localhost:9090
完整配置为(附prometheus-operator的推荐配置):
# job 将以标签形式出现在指标数据中,如node-exporter采集的数据,job=node-exporter
job_name: node-exporter
# 采集频率:30s
scrape_interval: 30s
# 采集超时:10s
scrape_timeout: 10s
# 采集对象的path路径
metrics_path: /metrics
# 采集协议:http或者https
scheme: https
# 可选的采集url的参数
params:
name: demo
# 当自定义label和采集到的自带label冲突时的处理方式,默认冲突时会重名为exported_xx
honor_labels: false
# 当采集对象需要鉴权才能获取时,配置账号密码等信息
basic_auth:
username: admin
password: admin
password_file: /etc/pwd
# bearer_token或者文件位置(OAuth 2.0鉴权)
bearer_token: kferkhjktdgjwkgkrwg
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
# https的配置,如跳过认证,或配置证书文件
tls_config:
# insecure_skip_verify: true
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
server_name: kubernetes
insecure_skip_verify: false
# 代理地址
proxy_url: 127.9.9.0:9999
# Azure的服务发现配置
azure_sd_configs:
# Consul的服务发现配置
consul_sd_configs:
# DNS的服务发现配置
dns_sd_configs:
# EC2的服务发现配置
ec2_sd_configs:
# OpenStack的服务发现配置
openstack_sd_configs:
# file的服务发现配置
file_sd_configs:
# GCE的服务发现配置
gce_sd_configs:
# Marathon的服务发现配置
marathon_sd_configs:
# AirBnB的服务发现配置
nerve_sd_configs:
# Zookeeper的服务发现配置
serverset_sd_configs:
# Triton的服务发现配置
triton_sd_configs:
# Kubernetes的服务发现配置
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- monitoring
# 对采集对象进行一些静态配置,如打特定的标签
static_configs:
- targets: ['localhost:9090', 'localhost:9191']
labels:
my: label
your: label
# 在Prometheus采集数据之前,通过Target实例的Metadata信息,动态重新写入Label的值。
如将原始的__meta_kubernetes_namespace直接写成namespace,简洁明了
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: (.*)
target_label: namespace
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_name]
separator: ;
regex: (.*)
target_label: service
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_pod_name]
separator: ;
regex: (.*)
target_label: pod
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_name]
separator: ;
regex: (.*)
target_label: job
replacement: ${1}
action: replace
- separator: ;
regex: (.*)
target_label: endpoint
replacement: web
action: replace
# 指标relabel的配置,如丢掉某些无用的指标
metric_relabel_configs:
- source_labels: [__name__]
separator: ;
regex: etcd_(debugging|disk|request|server).*
replacement: $1
action: drop
# 限制最大采集样本数,超过了采集将会失败,默认为0不限制
sample_limit: 0
三. 服务发现
上边的配置文件中,有很多 * _sd_configs的配置,如kubernetes_sd_configs,就是用于服务发现的采集配置。
支持的服务发现类型:
// prometheus/discovery/config/config.go
type ServiceDiscoveryConfig struct {
StaticConfigs []*targetgroup.Group `yaml:"static_configs,omitempty"`
DNSSDConfigs []*dns.SDConfig `yaml:"dns_sd_configs,omitempty"`
FileSDConfigs []*file.SDConfig `yaml:"file_sd_configs,omitempty"`
ConsulSDConfigs []*consul.SDConfig `yaml:"consul_sd_configs,omitempty"`
ServersetSDConfigs []*zookeeper.ServersetSDConfig `yaml:"serverset_sd_configs,omitempty"`
NerveSDConfigs []*zookeeper.NerveSDConfig `yaml:"nerve_sd_configs,omitempty"`
MarathonSDConfigs []*marathon.SDConfig `yaml:"marathon_sd_configs,omitempty"`
KubernetesSDConfigs []*kubernetes.SDConfig `yaml:"kubernetes_sd_configs,omitempty"`
GCESDConfigs []*gce.SDConfig `yaml:"gce_sd_configs,omitempty"`
EC2SDConfigs []*ec2.SDConfig `yaml:"ec2_sd_configs,omitempty"`
OpenstackSDConfigs []*openstack.SDConfig `yaml:"openstack_sd_configs,omitempty"`
AzureSDConfigs []*azure.SDConfig `yaml:"azure_sd_configs,omitempty"`
TritonSDConfigs []*triton.SDConfig `yaml:"triton_sd_configs,omitempty"`
}
因为prometheus采用的是pull方式来拉取监控数据,这种方式需要由server侧决定采集的目标有哪些,即配置在scrape_configs中的各种job,pull方式的主要缺点就是无法动态感知新服务的加入,因此大多数监控都默认支持服务发现机制,自动发现集群中的新端点,并加入到配置中。
Prometheus支持多种服务发现机制:文件,DNS,Consul,Kubernetes,OpenStack,EC2等等。基于服务发现的过程并不复杂,通过第三方提供的接口,Prometheus查询到需要监控的Target列表,然后轮询这些Target获取监控数据。
对于kubernetes而言,Promethues通过与Kubernetes API交互,然后轮询资源端点。目前主要支持5种服务发现模式,分别是:Node、Service、Pod、Endpoints、Ingress。对应配置文件中的role: node/role:service
如:动态获取所有节点node的信息,可以添加如下配置:
- job_name: kubernetes-nodes
scrape_interval: 1m
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: null
role: node
namespaces:
names: []
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
relabel_configs:
- separator: ;
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
action: labelmap
- separator: ;
regex: (.*)
target_label: __address__
replacement: kubernetes.default.svc:443
action: replace
- source_labels: [__meta_kubernetes_node_name]
separator: ;
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
action: replace
就可以在target中看到具体内容
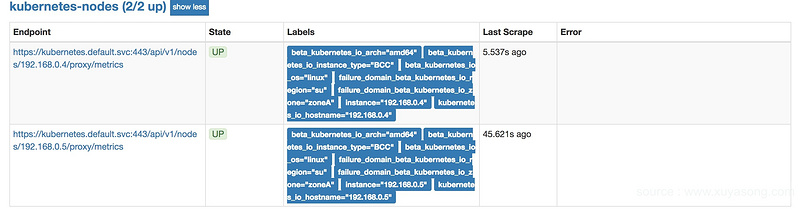
对应的service、pod也是同样的方式。
需要注意的是,为了能够让Prometheus能够访问收到Kubernetes API,我们要对Prometheus进行访问授权,即serviceaccount。否则就算配置了,也没有权限获取。
prometheus的权限配置是一组ClusterRole+ClusterRoleBinding+ServiceAccount,然后在deployment或statefulset中指定serviceaccount。
ClusterRole.yaml
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: namespace: kube-system name: prometheus rules: - apiGroups: [""] resources: - configmaps - secrets - nodes - pods - nodes/proxy - services - resourcequotas - replicationcontrollers - limitranges - persistentvolumeclaims - persistentvolumes - namespaces - endpoints verbs: ["get", "list", "watch"] - apiGroups: ["extensions"] resources: - daemonsets - deployments - replicasets - ingresses verbs: ["get", "list", "watch"] - apiGroups: ["apps"] resources: - daemonsets - deployments - replicasets - statefulsets verbs: ["get", "list", "watch"] - apiGroups: ["batch"] resources: - cronjobs - jobs verbs: ["get", "list", "watch"] - apiGroups: ["autoscaling"] resources: - horizontalpodautoscalers verbs: ["get", "list", "watch"] - apiGroups: ["policy"] resources: - poddisruptionbudgets verbs: ["get", list", "watch"] - nonResourceURLs: ["/metrics"] verbs: ["get"]
ClusterRoleBinding.yaml
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: namespace: kube-system name: prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: prometheus subjects: - kind: ServiceAccount name: prometheus namespace: kube-system
ServiceAccount.yaml
apiVersion: v1 kind: ServiceAccount metadata: namespace: kube-system name: prometheus
prometheus.yaml
.... spec: serviceAccountName: prometheus ....
完整的kubernete的配置如下:
- job_name: kubernetes-apiservers
scrape_interval: 1m
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: null
role: endpoints
namespaces:
names: []
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
separator: ;
regex: default;kubernetes;https
replacement: $1
action: keep
- job_name: kubernetes-nodes
scrape_interval: 1m
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: null
role: node
namespaces:
names: []
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
relabel_configs:
- separator: ;
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
action: labelmap
- separator: ;
regex: (.*)
target_label: __address__
replacement: kubernetes.default.svc:443
action: replace
- source_labels: [__meta_kubernetes_node_name]
separator: ;
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
action: replace
- job_name: kubernetes-cadvisor
scrape_interval: 1m
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: null
role: node
namespaces:
names: []
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: false
relabel_configs:
- separator: ;
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
action: labelmap
- separator: ;
regex: (.*)
target_label: __address__
replacement: kubernetes.default.svc:443
action: replace
- source_labels: [__meta_kubernetes_node_name]
separator: ;
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
action: replace
- job_name: kubernetes-service-endpoints
scrape_interval: 1m
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- api_server: null
role: endpoints
namespaces:
names: []
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
separator: ;
regex: "true"
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
separator: ;
regex: (https?)
target_label: __scheme__
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
separator: ;
regex: (.+)
target_label: __metrics_path__
replacement: $1
action: replace
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
separator: ;
regex: ([^:]+)(?::/d+)?;(/d+)
target_label: __address__
replacement: $1:$2
action: replace
- separator: ;
regex: __meta_kubernetes_service_label_(.+)
replacement: $1
action: labelmap
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: (.*)
target_label: kubernetes_namespace
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_name]
separator: ;
regex: (.*)
target_label: kubernetes_name
replacement: $1
action: replace
配置成功后,对应的target是:

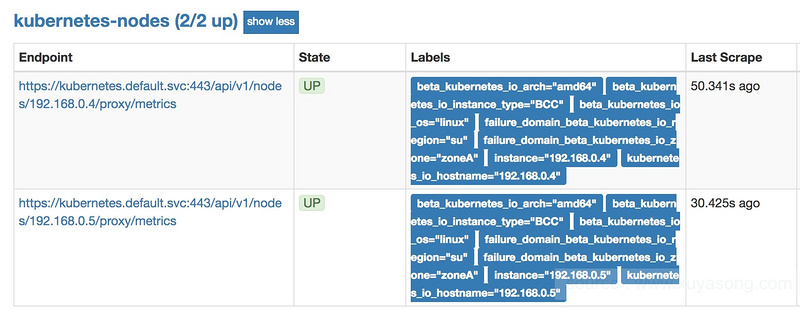
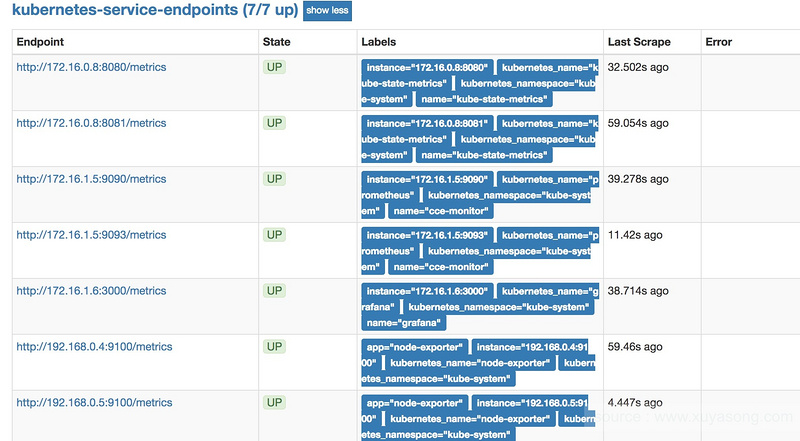
四. 常见场景
- 1.获取集群中各节点信息,并按可用区或地域分类
如使用k8s的role:node采集集群中node的数据,可以通过"meta_domain_beta_kubernetes_io_zone"标签来获取到该节点的地域,该label为集群创建时为node打上的标记,kubectl decribe node可以看到。
然后可以通过relabel_configs定义新的值
relabel_configs: - source_labels: ["meta_domain_beta_kubernetes_io_zone"] regex: "(.*)" replacement: $1 action: replace target_label: "zone"
后面可以直接通过node{zone="XX"}来进行地域筛选
- 2.过滤信息,或者按照职能(RD、运维)进行监控管理
对于不同职能(开发、测试、运维)的人员可能只关心其中一部分的监控数据,他们可能各自部署的自己的Prometheus Server用于监控自己关心的指标数据,不必要的数据需要过滤掉,以免浪费资源,可以最类似配置;
metric_relabel_configs:
- source_labels: [__name__]
separator: ;
regex: etcd_(debugging|disk|request|server).*
replacement: $1
action: drop
action: drop代表丢弃掉符合条件的指标,不进行采集。
-
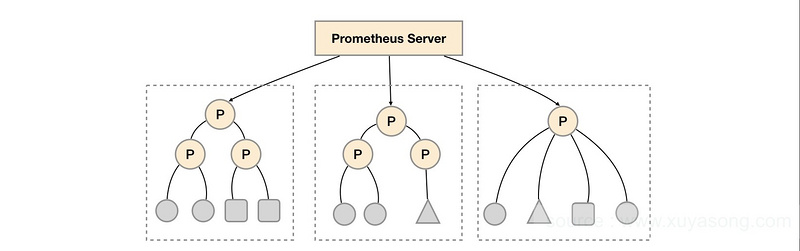
3.搭建prometheus联邦集群,管理各IDC(地域)监控实例
如果存在多个地域,每个地域又有很多节点或者集群,可以采用默认的联邦集群部署,每个地域部署自己的prometheus server实例,采集自己地域的数据。然后由统一的server采集所有地域数据,进行统一展示,并按照地域归类
配置:
scrape_configs:
- job_name: 'federate'
scrape_interval: 15s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="prometheus"}'
- '{__name__=~"job:.*"}'
- '{__name__=~"node.*"}'
static_configs:
- targets:
- '192.168.77.11:9090'
- '192.168.77.12:9090'
本文为容器监控实践系列文章,完整内容见: container-monitor-book
正文到此结束
- 本文标签: 协议 struct 安全 API list http Action consul web ip 集群 管理 实例 src Authorization token 目录 db cat 数据 URLs lib Jobs Lua node 进程 调试 DOM Connection Job OAuth 2.0 remote tar UI Kubernetes Uber 下载 bug 部署 端口 配置 App 文章 id 并发 认证 DNS map 时间 开发 ACE IO Proxy 测试 https zookeeper OpenStack 参数 Word Service Pods
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

