京东 JDK 的探索与研究(一)
来这里找志同道合的小伙伴!
前 言
本文旨在概述京东在JDK方向上的尝试与探索,以及京东JDK项目背景,基本特性以及未来的工作方向。
对于JDK特性的技术讨论,实现细节及效果,将在后续系列文章中深入讨论。
背景
HDFS简介
HDFS是作为最底层的分布式存储服务而存在的,是Hadoop的分布式文件系统组件。HDFS是高容错的,被设计成在低成本硬件上部署。HDFS为应用数据提供高吞吐量的访问,适用于具有大规模数据集的应用程序。HDFS采用了基于Master/Slave主从架构的分布式文件系统, 一个HDFS集群包含的Master节点(NameNode)和多个Slave节点(DataNode)服务器,文件以block的形式存储在DataNode节点。NameNode主要负责响应客户端请求,进行文件的打开、关闭、重命名文件和目录,同时决定block到具体Datanode节点的映射。Datanode在Namenode的指挥下进行block的创建、删除和复制。
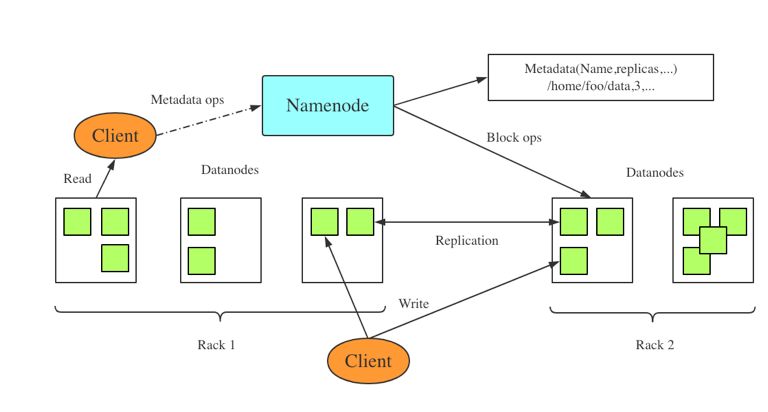
JVM对HDFS的作用
由于HDFS采用Java开发,并运行于JVM上,因此如何从JVM角度提高HDFS的能力是主要研究的方向之一。 从JVM角度看,NameNode节点的特点是进程生命周期长,对象创建频繁,资源利用率高,对于内存的资源要求较高,NameNode的性能是HDFS性能的关键。DataNode节点的特点是进程生命周期短,多数进程创建后进行对文件块的操作后即退出。如何对JVM进行优化,才能使其更加适用于HDFS NameNode和DataNode的工作特点是京东JDK研发的主要方向。
京东在JDK方面的尝试与经验
京东对通用JDK的尝试
01
使用Oracle JDK 1.8的经验
在京东,曾经尝试使用Oracle的JDK1.8做为HDFS的JDK解决方案。经过不断的工作与参数调优,已经使HDFS稳定的运行在OracleJDK1.8环境中。但是,随着京东业务的不断增长,对于HDFS的要求也在不断提高,OracleJDK1.8在以下问题上并不能提供更多的帮助:
性能优化 :虽然OracleJDK1.8 的JVM中具备很多先进的优化功能,比如tiered compiler, 高效的CMS垃圾收集器等,但其主要针对通用Java程序的性能进行优化,缺少针对分布式工作环境的特定优化。由于无法对oracle JDK1.8的源代码进行修改,通过参数调整并不能从根本上解决问题。
不可控的GC : 虽然OracleJDK1.8提供的相当优秀的CMS垃圾收集器,可以有效的提高GC暂停时间带来的性能损失,但在实际使用过程中,发现GC停顿时间仍然不能满足要求,比如YoungGC的时间仍在1秒左右,而OldGC消耗在60秒左右,如果一旦发生FullGC,则经常会导致NameNode暂停时间过长从而导致系统假死,结果往往是灾难性的。
内存利用率低 :对于NameNode节点,能够使用的物理内存在512GB,而为了避免JVM中老年代GC和Full GC时间过长而导致的灾难性后果,NameNode节点只能配置Java堆在200GB左右。通常NameNode节点的机器上只运行NameNode进程和一个轻量级的ZKFC进程,所以物理内存不能得到有效利用。另一方面,NameNode的承载能力受到Java堆大小的制约,导致HDFS的总体承载能力受限。
JDK版本更新 :随着以上问题的不断显现,同时JDK1.8将在2019年停止更新,同时需要尝试新的JDK以及OpenJDK能否帮助解决问题。
02
尝试openJDK11
随着openJDK的不断演进,为了缓解上面提到的问题,也尝试了OpenJDK11, 相对于openJDK1.8,发现openJDK11在以下方面可能具备优势:
G1GC : open JDK11采用G1作为默认的GC算法,相对于CMS,G1具备以下优点:
△ 更小的内存碎片:
由于CMS老年代采用Mark-sweep算法,并不是每次做OldGC都进行Compact,所以CMS老年代空间常常会引入碎片问题。而G1采用分块Copy算法,使得内存碎片问题仅仅在G1的分块中存在,相对于CMS,其内存的利用率更高,发生FullGC和OOM的可能性更低。
△ 可控的GC暂停时间:
G1算法最大的特点就是它可以让用户提供期望的GC最大暂停时间,在其内部通过统计预测的方法对下一次即将发生的GC算法进行有效的暂停时间的控制,从而优化GC对于性能的损耗。
更丰富的性能分析工具: OpenJDK11引入了JavaFrameRecorder(JFS),这是原来oracle JDK1.8商业版才具备的特性,JFR可以在不损耗,或轻微损耗性能的情况下,对Java程序进行sampling,从而帮助分析性能、功能瓶颈和指导优化。
HDFS更高的负载能力: OpenJDK11由于采用G1作为默认的GC算法,其可以更高效的利用堆内存,同时由于G1算法的设计及优化,其发生FullGC的几率非常低,并且FullGC的暂停时间也得到了优化,所以相对于oracle JDK1.8的CMS,对于HDFS NameNode来说,其负载能力受到堆大小的限制更加宽松。
虽然OpenJDK11能够帮助缓解一系列问题,但对于京东大数据来说,仅使用原生的OpenJDK11仍然缺少针对性的优化,目前主要存在以下问题:
△ 针对大堆的优化:
由于openJDK上G1内部的一些限制,其针对大堆,如360GB的堆的性能并没有达到最优。
△ 针对大堆的工具开发:
以JMap为例,当堆内存很大的时候,一次JMap操作便利整个堆内存耗时巨大,我们经常遇到JMap导致假死的情况。
△ 针对HDFS的定制化工作:
另外,目前仍然希望JDK具备一些可利用的特性帮助我们对HDFS在问题分析,危机处理以及线上分析方面的能力进行增强。
京东定制化JDK
经过以上尝试,结合HDFS业务特点及优化需求。最终决定在OpenJDK11的基础上,对openjdk进行有针对性的开发和优化,打造京东的定制化JDK。
01
京东JDK特性介绍
除openJDK11具备的特性外,目前京东JDK主要具备以下能力:
JDK8 兼容性支持 javah: 由于JDK8具备Javah工具能供根据Java的类定义文件生成相应JNI实现所需的C/C++头文件。在大型项目中,如Hadoop,Yarn都会利用Javah进行JNI头文件的生成。
从JDK10开始,javah工具在JDK中被移除,取而代之的是javac –h功能,但由于javac –h在使用上不同于javah,并且在复杂的项目中,要想用javac –h 代替javah, 必须要修改编译系统,工作量和难度都比较大。为了在京东内部流畅的进行JDK升级,重写了javah,使其能成功的利用javac –h进行JNI头文件的生成。
扩大G1 region size: 由于openJDK的限制,针对G1GC的region大小最大只能达到32MB, 并且JVM内部推荐的region个数为2048, 即G1GC最为适用的堆大小在64GB (2048*32MB),而业务量要求NameNode堆至少要在180GB,因此JDJDK确定了优化G1GC对于大堆的支持的目标,以期望提高管理结点的性能。
经过调查研究,针对G1GC的region调整,实际上有两种方向,一种是保持region大小不变,增大region的个数以适应大堆,比如针对180GB的堆,region大小保持在32MB不变,那么就需要创建5760个region。此方案的好处是保持region大小不变,可以将分配的影响降到最小,但同时由于G1算法需要对每个region之间的引用关系做同步,如果堆数量过多,则同步的开销增大,从而影响GC的效率。
另一种方案是增加region大小,以保持region个数保持在2048或少量增长,其特点是增大region可能会导致应用程序对象分配的行为改变,但对于region间引用关系的同步影响比较小。
为了能够达到优化性能的目标,对NameNode做了如下分析:通过采集GCdebug的日志信息,可以看到NameNode的对象分配速率非常频繁,old space allocation rate 达到1MB/s,即有大量的object被频繁提升到老年代,同时存在大量的TLAB refile以及出现TLAB fill的频率在每分钟3万次左右,TLAB fill 即allocation进入slow path,需要进行TLAB的替换或者在非TLAB中分配。因此对象的分配性能是NameNode 性能的关键点之一。

结合以上分析,对JDK的region大小上限进行了优化,同时针对region大小,对G1进行了相应的修改。以下为优化后的实验得到的数据。
可以看到,TLAB fill次数从每分钟30000降到了20000,即对象分配在slow path的机率减少了33%。
针对多线程下锁的性能优化:
在JDJDK版本升级后, 运维与研发人员在大数据平台运行过程中,发现G1在运行过程中会出现2s左右的超长YoungGC,而相同规模的YGC大部分只有200ms左右. 如下图中绿线所示。
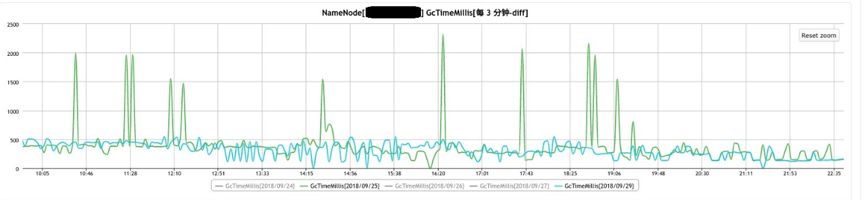
经过分析, G1出现2s GC的主要原因在于偏向锁功能的revoke过于频繁。利用JFR可以看到如下现象。
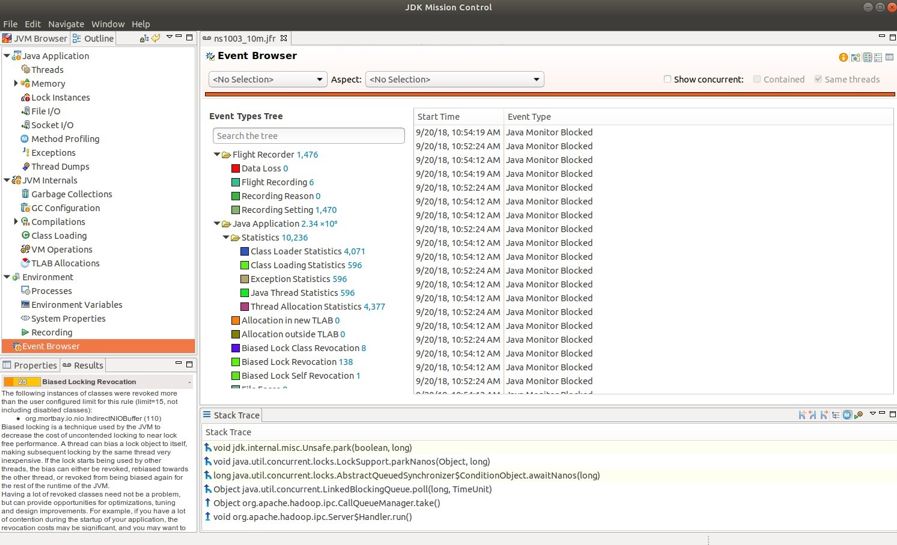
综合以上分析, 在管理节点采用-XX:-UseBiasedLocking后, 2s的GC 消失, 上图蓝色线条所示。
Java堆的动态拓展: Java程序在启动时要求程序员为JVM预设堆内存上限,即指定-Xmx的大小(或采用默认JVM参数)。但在实际使用过程中,很难清晰的计算出究竟应该采用多大的Java堆上限,尤其是对于线上系统中的管理进程,很有可能在发生大量的业务请求时出现OOM(Out-Of-Memory)异常而导致管理进程退出,出现灾难性后果。另一方面,考虑到系统资源占用,Java程序往往要求JVM不要占用大量的系统内存,即使-Xmx的值小于RAM的大小,所以在程序运行时,经常会出现Java进程因为OOM退出,而系统RAM却还有很多剩余可以利用。
为了缓解OOM的问题,京东JDK研发了基于G1GC的动态拓展堆大小的功能。 该功能在JVM堆内存使用率正常的情况下,维持java堆在-Xmx之下,而当JVM发现当前进程Java堆被大量占用时,将发出警报,从而运维人员可以根据当前业务情况即系统RAM使用情况,动态的打开Java堆拓展功能,JVM将Java堆进行一定比例的拓展,以保证JVM顺利度过业务繁忙的时段。 当业务量降低,并且heap使用率低于一定阈值时,JVM将利用G1GC回收拓展的堆区域,从而保证在正常情况下JVM进程不会给系统内存造成额外的压力。
定期、定时触发GC: 经过调研,发现京东的业务呈现明显的时间周期性,比如某个集群在某一时段基本处于空闲状态。而在繁忙状态时,堆内存以及CPU资源都集中于业务的处理,如果此时发生OldGC或者FullGC,或者YoungGC发生过于频繁,都会导致系统的业务处理能力下降。
为了降低GC对于业务处理能力的影响,京东JDK基于G1GC开发了周期性GC的功能。运维人员可以在每天系统不繁忙的时间段定时触发多次YoungGC以及必要的MixedGC/FullGC来清里Java堆中的垃圾,从而降低高峰时段GC触发的频率及时间。
JVM及时归还未使用的内存(Uncommitted Memory)给系统:
JDK12特性,京东JDK目前已经支持。此功能主要为节省物理内存空间。JDK11版本中的G1并不会及时的将空的region交还给OS,只有在FullGC或Old GC的concurrent 阶段才会交还已经回收的region给OS。但由于G1的设计目标就是避免FullGC以及尽量少的触发OldGC,所以实际运行过程中,G1 堆占用的物理内存会迟迟不能释放给系统,导致JVM进程占用内存远高于实际使用量。在多进程多任务环境中,会整体导致系统内存资源不能有效分配及使用,同时提高内存硬件的需求量,增加企业的成本投入。
京东JDK在JDK11的基础上,从JDK12引入了JEP346特性 --“及时回收未使用的Uncommitted Memory给系统“这个特性,其在JVM内部引入了监测机制,当发现系统空闲以及JVMGC触发不频繁时,JVM会自动触发concurrentGC 或FullGC来回收uncommitted region给系统。
可撤销的G1 Mixed GC以保证GC停顿时间:
JDK12特性,有效减少及控制G1停顿时间。G1GC的主要设计目标是保证G1的停顿时间在可控的范围内,用户可以通过-XX:MaxGCPauseMills参数来指定G1的最大停顿时间,G1GC会尽量尝试保证每次GC的时间不会超过-XX:MaxGCPauseMills。在JVM内部,G1GC在Concurrent 阶段会根据最大停顿时间来选择需要回收的集合(Collect Set),然后在暂停阶段回收这些集合中的对象。
在JDK11版本中,Collection Set一旦确定就无法改变,但由于Collection Set是JVM根据历史GC信息推断出的,因此如果推断与真实情况的误差过大,会导致MixGC(oldGC)的暂停时间过长,远超过-XX:MaxGCPauseMills设定的目标。
京东JDK从JDK12引入了JEP344特性—Abortable Mixed Collections for G1,该特性可以将Collection Set分解为“必须回收”和“可选择回收”的两部分,在发生MixedGC时,GC在回收完“必须回收”的部分后,会根据目标暂停时间的剩余量循环的从“可选择回收”部分中选取回收集合进行回收,以保证GC整体暂停时间可控。
默认的类型信息共享文件(Class Data Sharing - CDS Archive):
Class Data Sharing (CDS)有助于加快Java程序启动时间,同时允许多JVM实例复用SharedArchive以减少memory footprint.
JDK10对CDS进一步拓展,SharedArchive中保存应用程序数据:Application Class-data sharing (参见JEP 310)
对于CDS,JEP中的介绍如下:
· We can save about 340MB of RAM for a Java EE app server that includes 6 JVM processes consuming a total of 13GB of RAM (~2GB of that is for class meta data).
· We can improve the startup time of the JEdit benchmark by 20-30%.
· We can reduce the RAM usage of the embedded Felix benchmark by 18% across 4 JVM processes.
京东JDK引入了最新的JDK12中关于CDS的新特性 - Default CDS Archives。该功能在编译阶段生成默认的Archive,并且无需用户指定JVM选项-Xshare:auto即可享受到CDS带来的优点。
并行的高效JMap Java堆分析工具: JMap作为Java开发人员常用工具,一般在调查OOM,查看堆对象分布时都能发挥重要作用。但是在日常工作中,发现对于大堆,例如堆内存配置为-Xmx200g时,在线上系统运行JMap histo时间非常长,并且影响整个JVM进程的响应速度,一旦JVM进程被KILL,运行中JMap histo也无法提供有效信息。 经过调研,JMap 工具在扫描Java堆时是单线程工作,并且只有在整个堆扫描完成时才会统计信息并输出。
针对JMap的问题,京东JDK团队对JMap进行了拓展,实现了其并行,增量式对扫描方案。对JMap histo在大堆上的扫描并行化,同时在运行中统计中间结果。使得JMap在200GB堆扫描性能提升2倍,同时能够使JMap在运行过程中不断输出中间结果,这样即使JVM进程退出,JMap仍能提供有效的信息用于分析内存使用情况。
02
京东JDK优化效果
经过一系列的工作,目前京东JDK已经顺利应用于京东大数据平台HDFS的NameNode节点上,其对于管理结点优化达到50%, 见下图:
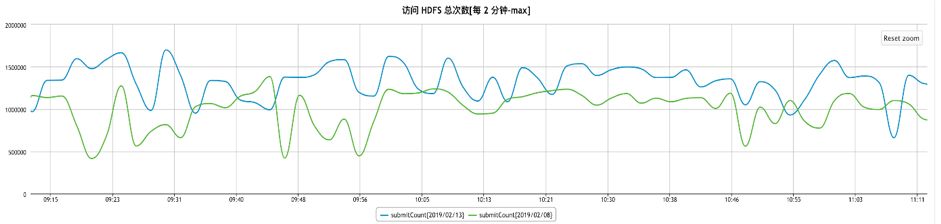
另一方面,JDJDK对于管理结点文件数承载能力从4亿上升到10亿,承载能力提升1.5倍。缓解了业务方的需求,节省了人力。
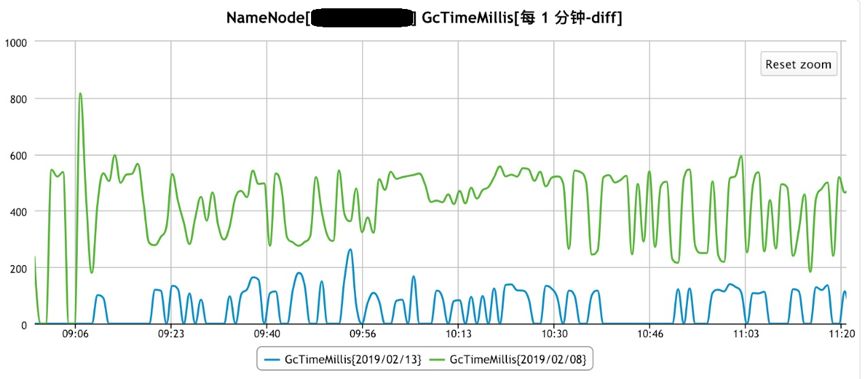
针对G1GC 也做了相关优化, 优化后的G1GC 对比之前JDK8的CMS的YoungGC暂停时间如下图:
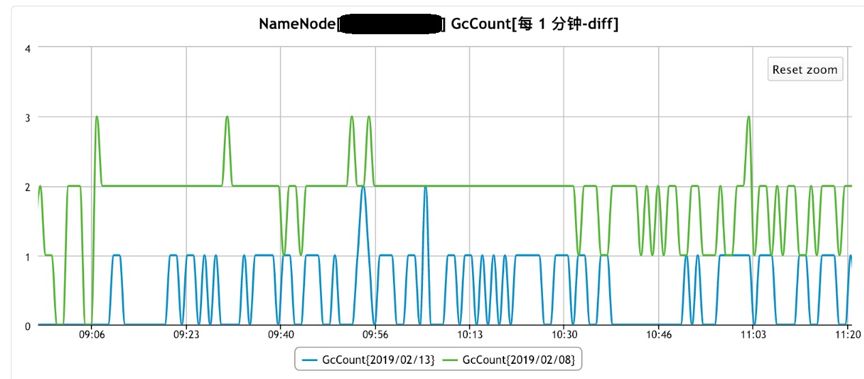
GC发生的次数对于如下:
在加/解锁及线程同步方面,京东JDK团队也进行了深入的研究及优化,除了上文提到的偏向锁以外,还利用JVM 的instrumentation等工具,对锁相关的bytecode进行线上优化,针对不同的HDFS访问,优化效果如下:
Mkdir:
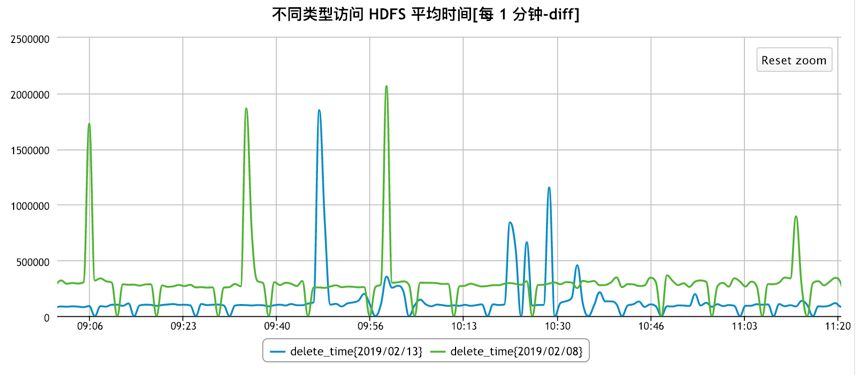
Delete:
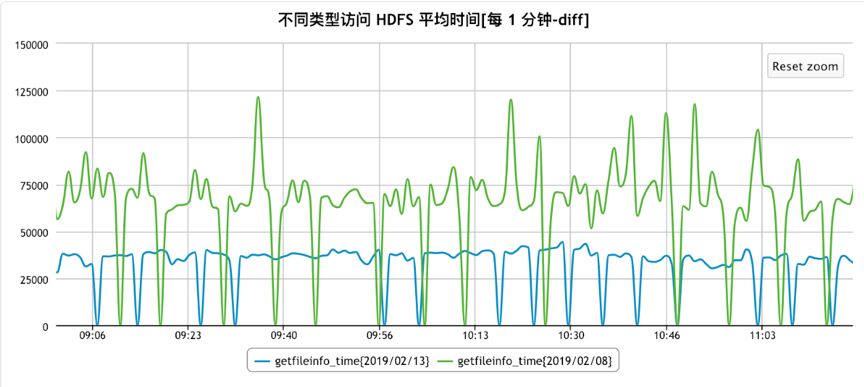
Getfileinfo:
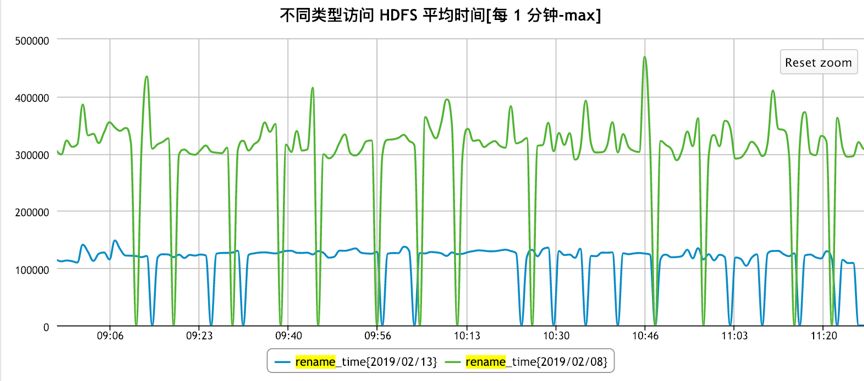
Rename:
京东JDK的发展方向
在未来,京东JDK团队将更加注重于降本增效方面的工作,我们计划进行更多的尝试及创新,例如:
△ 用于特定使用场景的,独立的heap区域
△ 半自动式GC
△ 基于大数据应用场景的GC算法开发及优化
△ 基于Graal的AOT功能的开发及优化
同时,京东JDK团队也将积极参与openJDK社区的开发及研究工作,尽可能将京东JDK的特性贡献到社区,让更多人能够使用到。
作者简介
臧琳,京东JVM专家,主要负责京东JDK针对京东大数据业务的定制化开发及优化工作。专注于JVM中内存管理,runtime运行时以及JIT编译器的性能分析及优化等领域。 欢迎对文章或JVM感兴趣的小伙伴邮件联系zanglin5@jd.com
RECOMMEND
正文到此结束
- 本文标签: Oracle Datanode 管理 实例 统计 主从架构 bug 编译 tar Namenode 大数据 程序员 src Collection 专注 2019 服务器 HDFS 数据 App 企业 IO 分布式 部署 java https 集群 UI 空间 同步 文章 id 分布式文件系统 rmi cat Region 时间 锁 ACE Master Full GC 目录 node 压力 配置 需求 开发 生命 希望 JVM tab 进程 map 代码 参数 删除 物理内存 线程同步 Hadoop 线程 京东 多线程 Collections http 文件系统 性能优化 定制
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

