Foxdisk09-工具篇
题外话,大概是2017年底,开始开发DTU,用来采集光伏逆变器的数据,通过GPRS发送给后端服务器。一个不大的物联网设备,针对客户的需求做了三种不同的形态。采用的是STM32F103C8T6+SIM800C的硬件架构,软件则用FreeRTOS,方便后续的扩展。2018年4月份,国家政策一变,原计划的50K的产品计划也逐渐泡汤。我写博客前,刚好看到文件夹中满满的资料,不禁有些惆怅。先定个小计划,Foxdisk的博客写完后,也针对这个项目写写历程吧,从前期找客户、定方案、打样到量产,甚至包括采购物料、包材、后期的款项等等,可以吐槽的地方太多了。
回到正题。发现之前提供的Foxdisk的下载链接没法用了,同时也发现小工具的代码没有放上去。什么时候有人需要,我再整整吧,这段时间有点忙,有点顾不上。
Foxdisk的编译过程中,有两个小工具需要使用,EHZ24.exe和ETRHZ.exe,名字有点怪,我随便取的。EHZ24.exe是用来提取汉字字模的工具,即将需要的汉字的点阵图提取出来,方便程序去打印到屏幕上。其主要功能如下:
- 可以针对多个源文件进行处理,提取C语言源代码中需要显示的汉字;
- 可指定提取的字模为楷体、黑体或者仿宋,字模为24×24点阵字;
- 提取出来的字模,自动生成一个.h的头文件,并在头文件中定义了字模的结构体。
源代码中HZK24K.h就是由这个工具自动生成的。 ETRHZ.exe提取的是16×16的点阵字,其功能与EHZ24.exe差不多,HZTABLE.H由其提取。理论上可以把这两个程序合成一个,只是因为这两个程序是我以前开发隔离卡产品时写的,当时就这么分开的,稍微改改就拿来用了,也没兴趣去合一了。如图,两个工具简陋的命令行帮助文档。
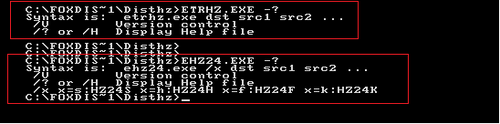
这两个工具其实没什么可以说的,主要就是分析源文件,将程序中需要显示的汉字取出来,然后在相应的汉字库中,将对应的汉字字模提取,最后写入到生成的文件中。如图2,从生成的文件中,也能了解到其大致功能。
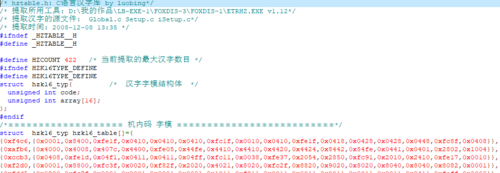
这两个工具的源代码比较简单,有兴趣的可以看看,过段时间我上传到博客上。源代码不难看懂,主要是要了解汉字提取的原理。
为什么要提取汉字?那是因为汉字库比较大(一般200K左右,大的400多K,Foxdisk才100多K,没法放下),我们是在无操作系统的情况下工作,程序越小越好。具体的汉字显示原理,我在接下来的几篇中记录。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

