折腾Java设计模式之迭代器模式
Provide a way to access the elements of an aggregate object sequentially without exposing its underlying representation.
提供一种不公示其底层细节(结构)的情况下能顺序访问聚合对象元素的方法。
其实在java体系中,jdk已经引入了迭代器接口以及对于的容器接口等。就拿迭代器中的角色,在java中找出其对应的类。
具体角色
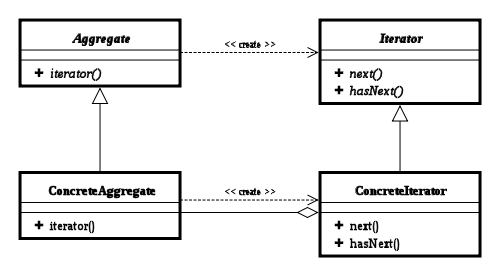
(1)迭代器角色(Iterator):定义遍历元素所需要的方法,一般来说会有这么三个方法:取得下一个元素的方法next(),判断是否遍历结束的方法hasNext()),移出当前对象的方法remove(), (2)具体迭代器角色(Concrete Iterator):实现迭代器接口中定义的方法,完成集合的迭代。 (3)容器角色(Aggregate): 一般是一个接口,提供一个iterator()方法,例如java中的Collection接口,List接口,Set接口等 (4)具体容器角色(ConcreteAggregate):就是抽象容器的具体实现类,比如List接口的有序列表实现ArrayList,List接口的链表实现LinkList,Set接口的哈希列表的实现HashSet等。
单独举出ArrayList的角色,
迭代器角色对应java中的java.lang.Iterator,这个迭代器是java容器公用的。
容器角色对应java.lang.Iterable,其还有Iterator iterator()方法获取迭代器。
具体迭代器角色对应java.lang.ArrayList.Itr,实现了对应的hasNext、next、remove方法。
具体容器角色那就是java.lang.ArrayList了,实现iterator方法返回Itr具体迭代器,用游标形式实现。
再看看UML类
项目实例
源码在Github
项目中很简单的实现了一个容器和迭代器。大致参考了ArrayList实现,但是是简洁版本,去除很多无关以及性能上的东西,只保留最基本的迭代器元素。
@Slf4j
public class Application {
public static void main(String[] args) {
Aggregate<Integer> aggregate = new ConcreteAggregate<>();
aggregate.add(1);
aggregate.add(2);
aggregate.add(3);
aggregate.add(4);
Iterator<Integer> iterator = aggregate.iterator();
while (iterator.hasNext()) {
log.info("循环数据{}", iterator.next());
}
}
}
复制代码
执行结果如下

简单的迭代器定义
public interface Iterator<E> {
boolean hasNext();
E next();
}
复制代码
简单容器定义
public interface Aggregate<T> {
Iterator<T> iterator();
void add(T t);
}
复制代码
具体容器和具体的迭代器定义
public class ConcreteAggregate<E> implements Aggregate<E> {
private Object[] elements;
private int size = 0;
public ConcreteAggregate() {
elements = new Object[16];
}
public int getSize() {
return size;
}
public void add(E e) {
elements[size++] = e;
}
@Override
public Iterator<E> iterator() {
return new ConcreteIterator<E>();
}
private class ConcreteIterator<E> implements Iterator<E> {
int cursor;
@Override
public boolean hasNext() {
return cursor != size;
}
@Override
public E next() {
if (cursor >= size) {
return null;
}
return (E) elements[cursor++];
}
}
}
复制代码
具体容器中用数组来作为容器来存储元素,而且最简单的容器,固定了大小,并没有实现扩容的算法等等,只是一个简单的样例,但是大部分上,都是直接使用java带有的迭代器。
优点
- 简化了遍历方式,对于对象集合的遍历,还是比较麻烦的,对于数组或者有序列表,我们尚可以通过游标来取得,但用户需要在对集合了解很清楚的前提下,自行遍历对象,但是对于hash表来说,用户遍历起来就比较麻烦了。而引入了迭代器方法后,用户用起来就简单的多了。
- 可以提供多种遍历方式,比如说对有序列表,我们可以根据需要提供正序遍历,倒序遍历两种迭代器,用户用起来只需要得到我们实现好的迭代器,就可以方便的对集合进行遍历了。
- 封装性良好,用户只需要得到迭代器就可以遍历,而对于遍历算法则不用去关心。
缺点
由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加,这在一定程度上增加了系统的复杂性。
对于比较简单的遍历(像数组或者有序列表),使用迭代器方式遍历较为繁琐,大家可能都有感觉,像ArrayList,我们宁可愿意使用for循环和get方法来遍历集合。
总结
迭代器模式是与集合共生共死的,一般来说,我们只要实现一个集合,就需要同时提供这个集合的迭代器,就像java中的Collection,List、Set、Map等,这些集合都有自己的迭代器。假如我们要实现一个这样的新的容器,当然也需要引入迭代器模式,给我们的容器实现一个迭代器。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

