使用统一转换服务来处理不同数据展现的思路和实现
本文示例代码: https://github.com/flym/train-propertytranslate
本文描述了这样一个场景:
针对于一个功能场景,第三方过来的数据格式均不相同,但需要通过一个统一的功能接口来进行调用,然后根据不同来源数据格式进行不同的数据展现。在后端实现时,尽量不要通过if else进行硬编码,而是通过配置的方式来完成数据的处理和呈现。
场景中提到了几个概念,如下:
- 功能场景和数据来源 :分组信息,针对同一个来源,其格式是相同的。不同来源的数据格式不一样
- 统一功能接口 :调用入口是统一的,即方法名,参数定义,以及返回格式都是相同的,仅参数内容不相同
- 配置化 :场景是通用的,可以通过配置来实现,而不是在业务代码中硬编码
- 不同的数据展现 :可以针对不同的分组和场景通过模板来进行渲染,而模板本身是可以配置的,这样即隔离了数据封装这一层。
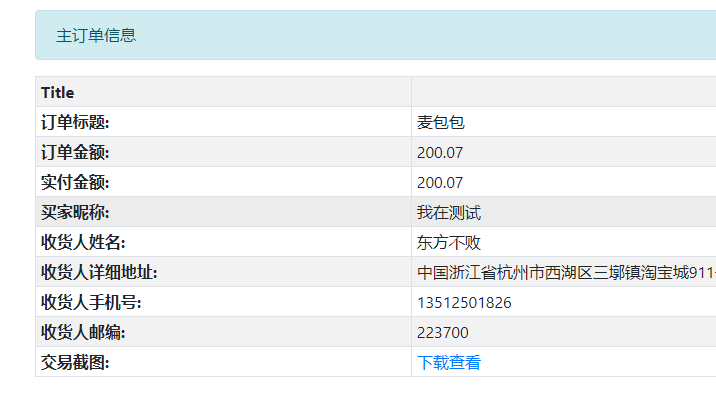
举例如下, 如下的一个数据内容:
{
"trade_fullinfo_get_response": {
"trade": {
"seller_nick": "我在测试",
"pic_name": "T1jVXXXePbXXaoPB6a_091917.jpg",
"receiver_name": "东方不败",
"buyer_message": "要送的礼物的,不要忘记的哦",
"receiver_city": "杭州市",
"receiver_district": "西湖区",
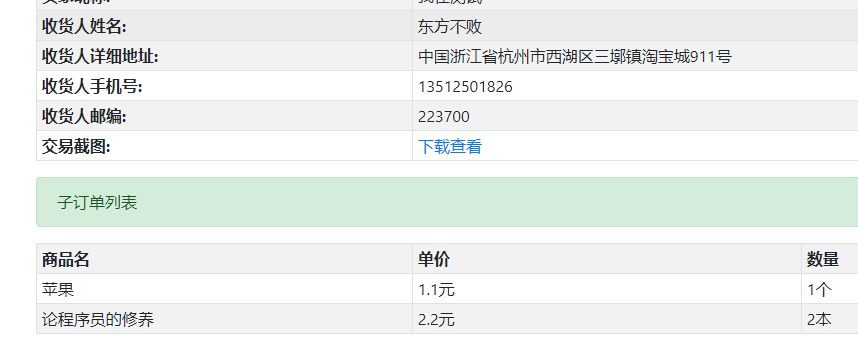
"orders": {
"order": [
{
"title": "苹果",
"unit": "个",
"oid": 1,
"price": 1.1,
"sum": 1
}
]
},
}
}
}
通过转换服务处理,可以展现为下面两种不同的数据内容(以html渲染为例)
本文从数据格式,转换器,转换过程,数据渲染几个方面来描述这一思路.
数据格式
一般来说,在对象层面就两种数据 List 和 Map,而List又是Map格式的一种集合,因此最终的对象格式均是 Map。而 Map的格式即是K,V,并且针对数据来说,K 的数据格式均为 String, V是可变的,但总结下来即为下面几种:
- LONG(“整数”),
- DOUBLE(“浮点数”),
- STRING(“字符串”),
- BOOL(“布尔”),
- DATE(“日期”),
- TIME(“时间”),
- DATETIME(“日期时间”),
- OBJECT(“对象”)
以及相应的集合格式. 通过这些信息,定义出表示一个对象的schema以及相应的属性信息
对象Schema:
class DataSchemaVO {
/**
* 当前这一层的惟一名,一般以相应的property name来表示
* 如果是顶级,则为 ROOT
*/
var name: String? = null
/**
* 中文标题
* 如果为顶级,则为 ROOT
*/
var title: String? = null
/** 子类的分类集 */
private var schemaSet: MutableSet<DataSchemaVO>? = null
/** 当前层的属性集(不包括引用类型) */
private var propertySet: MutableSet<DataPropertyVO>? = null
}
其中,子属性被拆分为两个分类,主要是为了后面转换服务方便。当属性是一个对象类型时,其被认为是一个 DataSchema,即一个递归的数据格式。如果是一个原生数据,即表示 DataProperty, 即可以当作基本数据格式进行各项操作和处理。
属性Property:
class DataPropertyVO : Cloneable, Comparable<DataPropertyVO> {
/** 当前层的惟一名 */
var name: String? = null
/** 当前标题 */
var title: String? = null
/** 数据类型 */
var dataType: DataPropertyDataType? = null
}
属性很简单,在java层面可以理解为除了name,其它的都是可选的。 dataType主要是为了后续在进行运算和处理时能够根据格式进行相应的convert和format,比如 +-*/ 和 format 。
通过以上的定义,那么一个对象即通过以下的xml进行描述出来(json也是可以的,这里仅给参考):
<schema name="ROOT" title="ROOT">
<schema name="trade_fullinfo_get_response" title="订单全信息响应">
<schema name="trade" title="主订单">
<property name="seller_nick" title="卖家昵称" dataType="STRING"/>
<property name="pic_name" title="交易截图" dataType="STRING" order="80"/>
<property name="payment" title="实付金额" dataType="DOUBLE" order="30"/>
<!-- ... 省略 --->
<schema name="orders" title="子订单">
<schema name="order" title="子订单信息">
<property name="title" title="商品名称" dataType="STRING"/>
<property name="unit" title="商品单位" dataType="STRING"/>
</schema>
</schema>
</schema>
</schema>
</schema>
此xml即可描述出本文开始的订单数据格式.
转换器
转换即Converter,在spring体系中,到处可见。对于一个converter,其将单个input转换为单个output,但对于input从哪儿拿到,以及output后面如何来处理,并没有描述。因此在本文中,将 整个过程描述为以下三步
- 拿到入参
- 执行转换
- 出参处理
即将整个生命周期全部进行了描述。整个定义,称之为Transformer.
同时,在转换过程中,转换本身并不是通过类型来进行区别,而是通过转换的场景来描述的。即需要有相应的上下文来描述转换过程中具体拿到哪些数据,以及过程中的逻辑怎么进行。这里引入了概念 context, 其主要作用即告诉转换器,相应的入参从哪儿拿,旧值如何处理,出参后续怎么处理这种。转换器本身按照一定的逻辑和相应的 if 判断逻辑来完成相应的过程。
因此,整个转换器的方法定义为如下格式:
fun transform(input: I, inputSchema: DataSchemaVO, context: C, globalContext: GlobalTransformContext): Tuple2<Any, DataSchemaVO>
参数除入参,上下文之后,还引入了 参数对象格式信息,全局上下文,以进行一些额外的判断和处理
转换器的实现即是根据不同的操作进行处理咯,如参考代码中,即包括toString, script, split,rollup,remove,copy,case等操作。根据实现情况还可以加入如format等处理,具体可参考接口Transformer的实现.
转换过程
整个过程理解为一系列的转换操作,即上一步的出参即是下一步的入参,直到最后结尾为止。这种典型的链式调用,参考的例子即是servlet体系的过滤器链,spring体系的拦截器链。整个过程通常是由一个执行对象来描述,且都叫做Invocation,这里我们也直接套用这个概念,并且通过特定的手法形成链式调用。
invocation对象中封装了当前的执行过程,步骤以及相应的当前参数,结果。其本身作为执行起点,不断地将信息进行绑定,调用,直到步骤结束。其过程简单用代码描述如下:
//执行对象
@Suppress("UNCHECKED_CAST")
override fun proceed() {
if(currentStep >= maxStep) {
return
}
val transformerVO = transformerInstanceList!![currentStep++]
val transformer = transformerVO.createTransformer() as Transformer<TransformContext, Any>
val context = transformerVO.createContext()
transformer.transformChained(currentOutput, currentOutputSchema, context, this, this.globalContext)
}
//转换器的自身处理和链式下一步调用
fun transformChained(input: I, inputSchema: DataSchemaVO, context: C, invocation: DefaultTransformerInvocation, globalTransformContext: GlobalTransformContext) {
val tuple2 = transform(input, inputSchema, context, globalTransformContext)
invocation.bindCurrentOutput(tuple2.t1)
invocation.bindCurrentOutputSchema(tuple2.t2)
invocation.proceed()
}
可以看出,最终当 currentStep 完成时,整个过程即可以结束.
在整个过程中,为了更加精细地描述对象格式,以方便后续的渲染对最终的结果的格式有所了解,相应的参数的schema信息是一直在传递的,同时过程中也根据转换过程进行调整和处理。这样的目的,即让后续数据渲染可以通过一种更通用的方式来使用结果数据.
此过程也可以通过一个xml来描述,如下参考
<root>
<dp key="receiverFullAddress" name="receiverFullAddress" title="收货人详细地址" dataType="STRING" order="55"/>
<!-- 提取里面的内容 -->
<t class="nestRollupKeyMapTransformer" key="trade_fullinfo_get_response.trade"/>
<!-- 下划线转驼峰 -->
<t class="allCaseLowerUnderscore2CamelKeyMapTransformer"/>
<!-- 下载链接转换 -->
<t class="docMapTransformer" key="picName"/>
<!-- 地址拼接 -->
<t class="scriptMapTransformer" key="receiverFullAddress" script="receiverCountry+receiverState+receiverCity+receiverDistrict+receiverTown+receiverAddress"
keyProperty:ref="receiverFullAddress"/>
<t class="allToStringMapTransformer" />
</root>
数据渲染
渲染过程即已经拿到结果信息以及相应的schema格式,按照实际的业务需要来展现即可。实际操作中,可以将其渲染为json(直接调用对象.toJson), 或者渲染为html或其它字符串格式。示例中使用了freemarker来进行数据渲染,同时为了让渲染过程更加了解结果信息,最终结果将对象和schema封装在一个统一的map中,以让ftl中可以直接使用这一对象信息。
同时,考虑到同一份来源过程,可能存在多种不同的渲染场景,因此在功能上,引入了key的概念,即同一个组内,可以通过多个不同的key来描述渲染过程。甚至将多个过程的数据一起进行组装,形成一个大的group渲染过程。例子参考示例中的两个不同的单元测试。
//指定场景进行转换并渲染 propertyTransformService.transformAndPrint(groupKey, orderDefineKey, inputData()) 将整个组的多个场景一起进行转换并组合,最终以group的格式进行数据渲染 //propertyTransformService.transformGroupAndPrint(groupKey, inputData())
总结
过程描述起来很简单,但实际在一些细节实现上也存在一些处理。如参数格式如何不停的调整和处理,内部集合属性如何从单个对象输出为一个集合,以及转换器如何转换,参数如何解析处理等. 示例工程作为一个非常通用的数据转换服务,很有参考意义。
注:工作使用kotlin语言进行翻译描述(从java通过idea转换的), 单元验证类为:PropertyTransformServiceTest. 本文使用到的第三方框架包括:spring, iflym体系,json处理,mvel,freemarker,testng .
正文到此结束
- 本文标签: java git 配置 解析 schema Freemarker 单元测试 spring ip map HTML 苹果 message ELK servlet apr 时间 总结 下载 id tab 标题 代码 参数 生命 AOP 测试 cat GitHub list http IO 翻译 IDE key core ORM root js 数据 XML src Service 2019 PHP https UI json dist Property 递归
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

