Kafka连接器深度解读之JDBC源连接器 原 荐
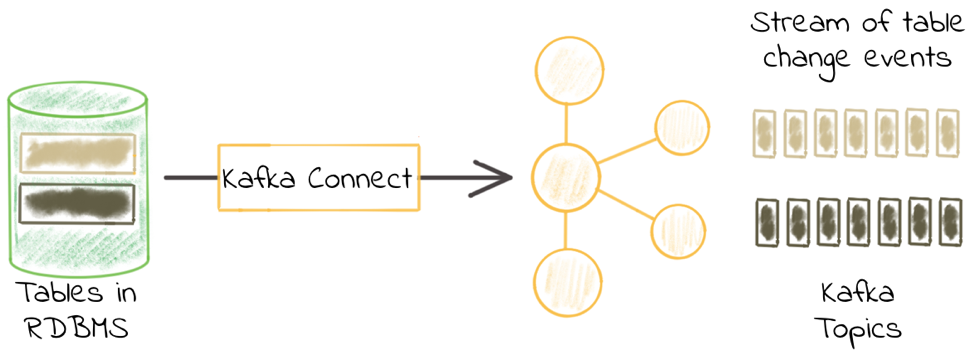
在现实业务中,Kafka经常会遇到的一个集成场景就是,从数据库获取数据,因为关系数据库是一个非常丰富的事件源。数据库中的现有数据以及对该数据的任何更改都可以流式传输到Kafka主题中,在这里这些事件可用于驱动应用,也可以流式传输到其它数据存储(比如搜索引擎或者缓存)用于分析等。
实现这个需求有很多种做法,但是在本文中,会聚焦其中的一个解决方案,即Kafka连接器中的JDBC连接器,讲述如何进行配置,以及一些问题排查的技巧,至于更多的细节,请参见Kafka的文档。
介绍
Kafka连接器中的JDBC连接器包含在Confluent Platform中,也可以与Confluent Hub分开安装。它可以作为源端从数据库提取数据到Kafka,也可以作为接收端从一个Kafka主题中将数据推送到数据库。几乎所有关系数据库都提供JDBC驱动,包括Oracle、Microsoft SQL Server、DB2、MySQL和Postgres。
下面将从最简单的Kafka连接器配置开始,然后进行构建。本文中的示例是从MySQL数据库中提取数据,该数据库有两个模式,每个模式都有几张表:
mysql> SELECT table_schema, table_name FROM INFORMATION_SCHEMA.tables WHERE TABLE_SCHEMA != 'information_schema'; +--------------+--------------+ | TABLE_SCHEMA | TABLE_NAME | +--------------+--------------+ | demo | accounts | | demo | customers | | demo | transactions | | security | firewall | | security | log_events | +--------------+--------------+
JDBC驱动
在进行配置之前,要确保Kafka连接器可以实际连接到数据库,即确保JDBC驱动可用。如果使用的是SQLite或Postgres,那么驱动已经包含在内,就可以跳过此步骤。对于所有其它数据库,需要将相关的JDBC驱动JAR文件放在和 kafka-connect-jdbc JAR相同的文件夹中。此文件夹的标准位置为:
- Confluent CLI:下载的Confluent Platform文件夹中的
share/java/kafka-connect-jdbc/; - Docker,DEB / RPM安装:
/usr/share/java/kafka-connect-jdbc/,关于如何将JDBC驱动添加到Kafka连接器的Docker容器,请参阅 此处 ; - 如果
kafka-connect-jdbcJAR位于其它位置,则可以使用plugin.path指向包含它的文件夹,并确保JDBC驱动位于同一文件夹中。
还可以在启动Kafka连接器时指定 CLASSPATH ,设置为可以找到JDBC驱动的位置。一定要将其设置为JAR本身,而不仅仅是包含它的文件夹,例如:
CLASSPATH=/u01/jdbc-drivers/mysql-connector-java-8.0.13.JAR ./bin/connect-distributed ./etc/kafka/connect-distributed.properties
两个事情要注意一下:
- 如果
kafka-connect-jdbcJAR位于其它位置,则Kafka连接器的plugin.path选项将无法直接指向JDBC驱动JAR文件 。根据文档,每个JDBC驱动JAR必须与kafka-connect-jdbcJAR位于同一目录; - 如果正在运行多节点Kafka连接器集群,则需要在集群中的每个连接器工作节点上都正确安装JDBC驱动JAR。
找不到合适的驱动
与JDBC连接器有关的常见错误是 No suitable driver found ,比如:
{"error_code":400,"message":"Connector configuration is invalid and contains the following 2 error(s):/nInvalid value java.sql.SQLException: No suitable driver found for jdbc:mysql://X.X.X.X:3306/test_db?user=root&password=pwd for configuration Couldn't open connection to jdbc:mysql://X.X.X.X:3306/test_db?user=root&password=pwd/nInvalid value java.sql.SQLException: No suitable driver found for jdbc:mysql://X.X.X.X:3306/test_db?user=root&password=admin for configuration Couldn't open connection to jdbc:mysql://X.X.X.X:3306/test_db?user=root&password=pwd/nYou can also find the above list of errors at the endpoint `/{connectorType}/config/validate`"}
这可能有2个原因:
- 未加载正确的JDBC驱动;
- JDBC URL不正确。
确认是否已加载JDBC驱动
Kafka连接器会加载与 kafka-connect-jdbc JAR文件在同一文件夹中的所有JDBC驱动,还有在 CLASSPATH 上找到的任何JDBC驱动。如果要验证一下,可以将连接器工作节点的 日志级别调整 为 DEBUG ,然后会看到如下信息:
1. DEBUG Loading plugin urls :包含 kafka-connect-jdbc-5.1.0.jar (或者对应当前正在运行的版本号)的一组JAR文件:
DEBUG Loading plugin urls: [file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/audience-annotations-0.5.0.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/common-utils-5.1.0.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/jline-0.9.94.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/jtds-1.3.1.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/kafka-connect-jdbc-5.1.0.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/mysql-connector-java-8.0.13.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/netty-3.10.6.Final.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/postgresql-9.4-1206-jdbc41.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/slf4j-api-1.7.25.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/sqlite-jdbc-3.25.2.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/zkclient-0.10.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/zookeeper-3.4.13.jar] (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader)
在这个JAR列表中,应该有JDBC驱动JAR。在上面的输出中,可以看到MySQL、Postgres和SQLite的JAR。如果期望的JDBC驱动JAR不在,可以将驱动放入 kafka-connect-jdbc JAR所在的文件夹中。
2. INFO Added plugin 'io.confluent.connect.jdbc.JdbcSourceConnector' :在此之后,在记录任何其它插件之前,可以看到JDBC驱动已注册:
INFO Added plugin 'io.confluent.connect.jdbc.JdbcSourceConnector' (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader) DEBUG Registered java.sql.Driver: jTDS 1.3.1 to java.sql.DriverManager (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader) DEBUG Registered java.sql.Driver: com.mysql.cj.jdbc.Driver@7bbbb6a8 to java.sql.DriverManager (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader) DEBUG Registered java.sql.Driver: org.postgresql.Driver@ea9e141 to java.sql.DriverManager (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader) DEBUG Registered java.sql.Driver: org.sqlite.JDBC@236134a1 to java.sql.DriverManager (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader)
确认JDBC驱动包含在已注册的列表中。如果没有,那么就是安装不正确。
注意,虽然可能会在日志的其它地方看到驱动的 Registered java.sql.Driver 信息,但如果要确认其对于JDBC连接器可用,那么它必须 直接 出现在 INFO Added plugin 'io.confluent.connect.jdbc 消息的后面。
JDBC URL
对于源数据库来说JDBC URL必须是正确的,如果搞错了,那么Kafka连接器即使驱动正确,也是不行。以下是一些常见的JDBC URL格式:
| 数据库 | 下载地址 | JDBC URL |
|---|---|---|
| IBM DB2 | 下载 | jdbc:db2://<host>:<port50000>/<database> |
| IBM Informix | jdbc:informix-sqli://:/:informixserver=<debservername> |
|
| MS SQL | 下载 | jdbc:sqlserver://<host>[:<port1433>];databaseName=<database> |
| MySQL | 下载 | jdbc:mysql://<host>:<port3306>/<database> |
| Oracle | 下载 | jdbc:oracle:thin://<host>:<port>/<service> or jdbc:oracle:thin:<host>:<port>:<SID> |
| Postgres | Kafka连接器自带 | jdbc:postgresql://<host>:<port5432>/<database> |
| Amazon Redshift | 下载 | jdbc:redshift://<server>:<port5439>/<database> |
| Snowflake | jdbc:snowflake://<account_name>.snowflakecomputing.com/?<connection_params> |
注意,虽然JDBC URL通常允许嵌入身份验证信息,但这些内容将以 明文形式 记录在Kafka连接器日志中。因此应该使用单独的 connection.user 和 connection.password 配置项,这样在记录时会被合理地处理。
指定要提取的表
JDBC驱动安装完成之后,就可以配置Kafka连接器从数据库中提取数据了。下面是最小的配置,不过它不一定是最有用的,因为它是数据的批量导入,在本文后面会讨论如何进行增量加载。
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_01",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-01-",
"mode":"bulk"
}
}'
使用此配置,每个表(用户有权访问)将完全复制到Kafka,通过使用KSQL列出Kafka集群上的主题,我们可以看到:
ksql> LIST TOPICS; Kafka Topic | Registered | Partitions | Partition Replicas | Consumers | ConsumerGroups ---------------------------------------------------------------------------------------------------- mysql-01-accounts | false | 1 | 1 | 0 | 0 mysql-01-customers | false | 1 | 1 | 0 | 0 mysql-01-firewall | false | 1 | 1 | 0 | 0 mysql-01-log_events | false | 1 | 1 | 0 | 0 mysql-01-transactions | false | 1 | 1 | 0 | 0
注意 mysql-01 前缀,表格内容的完整副本将每五秒刷新一次,可以通过修改 poll.interval.ms 进行调整,例如每小时刷新一次:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_02",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-02-",
"mode":"bulk",
"poll.interval.ms" : 3600000
}
}'
找个主题确认一下,显示完整的数据,看看是不是自己想要的:
ksql> PRINT 'mysql-02-accounts' FROM BEGINNING;
Format:AVRO
12/20/18 3:18:44 PM UTC, null, {"id": 1, "first_name": "Hamel", "last_name": "Bly", "username": "Hamel Bly", "company": "Erdman-Halvorson", "created_date": 17759}
12/20/18 3:18:44 PM UTC, null, {"id": 2, "first_name": "Scottie", "last_name": "Geerdts", "username": "Scottie Geerdts", "company": "Mante Group", "created_date": 17692}
12/20/18 3:18:44 PM UTC, null, {"id": 3, "first_name": "Giana", "last_name": "Bryce", "username": "Giana Bryce", "company": "Wiza Inc", "created_date": 17627}
12/20/18 3:18:44 PM UTC, null, {"id": 4, "first_name": "Allen", "last_name": "Rengger", "username": "Allen Rengger", "company": "Terry, Jacobson and Daugherty", "created_date": 17746}
12/20/18 3:18:44 PM UTC, null, {"id": 5, "first_name": "Reagen", "last_name": "Volkes", "username": "Reagen Volkes", "company": "Feeney and Sons", "created_date": 17798}
…
目前会展示所有可用的表,这可能不是实际的需求,可能只希望包含特定模式的表,这个可以使用 catalog.pattern/schema.pattern (具体哪一个取决于数据库)配置项进行控制:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_03",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-03-",
"mode":"bulk",
"poll.interval.ms" : 3600000,
"catalog.pattern" : "demo"
}
}'
这样就只会从 demo 模式中取得3张表:
ksql> LIST TOPICS; Kafka Topic | Registered | Partitions | Partition Replicas | Consumers | ConsumerGroups ---------------------------------------------------------------------------------------------------- […] mysql-03-accounts | false | 1 | 1 | 0 | 0 mysql-03-customers | false | 1 | 1 | 0 | 0 mysql-03-transactions | false | 1 | 1 | 0 | 0 […]
也可以使用 table.whitelist (白名单)或 table.blacklist (黑名单)来控制连接器提取的表,下面的示例显式地列出了希望拉取到Kafka中的表清单:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_04",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-04-",
"mode":"bulk",
"poll.interval.ms" : 3600000,
"catalog.pattern" : "demo",
"table.whitelist" : "accounts"
}
}'
这时就只有一个表从数据库流式传输到Kafka:
ksql> LIST TOPICS; Kafka Topic | Registered | Partitions | Partition Replicas | Consumers | ConsumerGroups ---------------------------------------------------------------------------------------------------- mysql-04-accounts | false | 1 | 1 | 0 | 0
因为只有一个表,下面的配置:
"catalog.pattern" : "demo", "table.whitelist" : "accounts",
等同于:
"table.whitelist" : "demo.accounts",
也可以在一个模式中指定多个表,比如:
"catalog.pattern" : "demo", "table.whitelist" : "accounts, customers",
或者也可以跨越多个模式:
"table.whitelist" : "demo.accounts, security.firewall",
还可以使用其它的表过滤选项,比如 table.types 可以选择表之外的对象,例如视图。
过滤表时要注意,因为如果最终没有对象匹配该模式(或者连接到数据库的已认证用户没有权限访问),那么连接器将报错:
INFO After filtering the tables are: (io.confluent.connect.jdbc.source.TableMonitorThread) … ERROR Failed to reconfigure connector's tasks, retrying after backoff: (org.apache.kafka.connect.runtime.distributed.DistributedHerder) java.lang.IllegalArgumentException: Number of groups must be positive
在通过 table.whitelist/table.blacklist 进行过滤之前,可以将日志级别调整为 DEBUG ,查看用户可以访问的表清单:
DEBUG Got the following tables: ["demo"."accounts", "demo"."customers"] (io.confluent.connect.jdbc.source.TableMonitorThread)
然后,连接器会根据提供的白名单/黑名单过滤此列表,因此要确认指定的列表位于连接器可用的列表中,还要注意连接用户要有权限访问这些表,因此还要检查数据库端的 GRANT 语句。
增量提取
到目前为止,已经按计划将整张表都拉取到Kafka,这虽然对于转存数据非常有用,不过都是批量并且并不总是适合将源数据库集成到Kafka流系统中。
JDBC连接器还有一个 流式传输到Kafka 的选项,它只会传输上次拉取后的数据变更,具体可以基于自增列(例如自增主键)和/或时间戳(例如最后更新时间戳)来执行此操作。在模式设计中的常见做法是使用这些中的一个或两个,例如,事务表 ORDERS 可能有:
ORDER_ID UPDATE_TS
可以使用 mode 参数配置该选项,比如使用 timestamp :
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_08",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-08-",
"mode":"timestamp",
"table.whitelist" : "demo.accounts",
"timestamp.column.name": "UPDATE_TS",
"validate.non.null": false
}
}'
下面会获取表的全部数据,外加源数据后续的更新和插入:
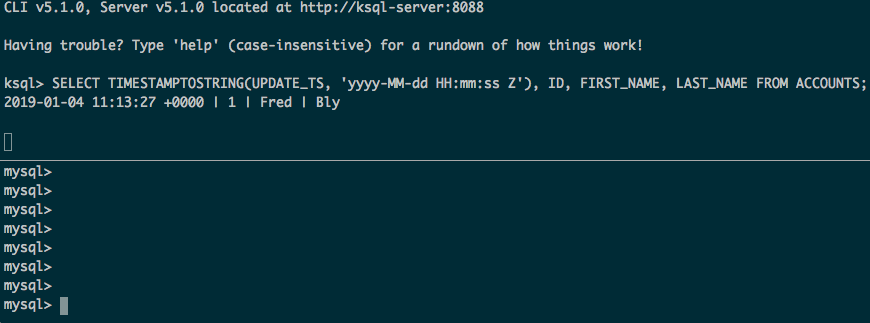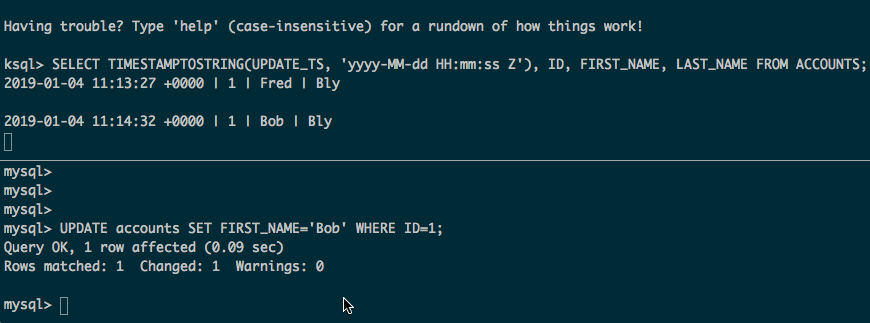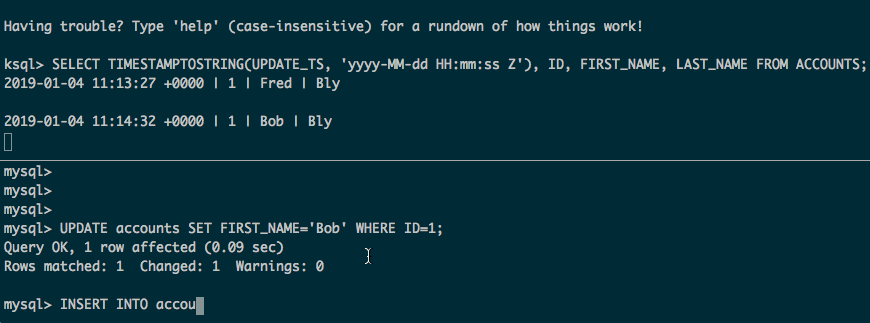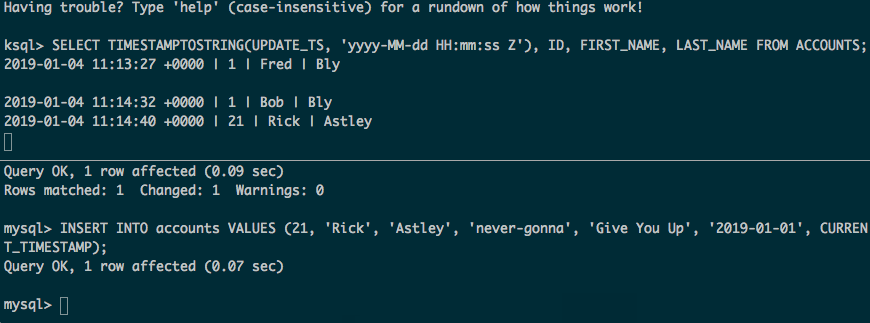
注意:
- 可以结合使用这些方法中的(时间戳/自增)或两者(时间戳+自增);
- 要使用的时间戳和/或自增列必须在连接器处理的所有表上。如果不同的表具有不同名称的时间戳/自增列,则需要创建单独的连接器配置;
- 如果只使用自增列,则不会捕获对数据的更新,除非每次更新时自增列也会增加(在主键的情况下几乎不可能);
- 某些表可能没有唯一的标识,或者有多个组合的列表示行的唯一标识(联合主键),不过JDBC连接器只支持单个标识列;
-
时间戳+自增列选项为识别新行和更新行提供了最大的覆盖范围; - 许多RDBMS支持声明更新时间戳列的DDL,该列会自动更新。例如:
- MySQL:
CREATE TABLE foo (
…
UPDATE_TS TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
- Postgres:
CREATE TABLE foo (
…
UPDATE_TS TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Courtesy of https://techblog.covermymeds.com/databases/on-update-timestamps-mysql-vs-postgres/
CREATE FUNCTION update_updated_at_column() RETURNS trigger
LANGUAGE plpgsql
AS $$
BEGIN
NEW.update_ts = NOW();
RETURN NEW;
END;
$$;
CREATE TRIGGER t1_updated_at_modtime BEFORE UPDATE ON foo FOR EACH ROW EXECUTE PROCEDURE update_updated_at_column();
- Oracle:
CREATE TABLE foo (
…
CREATE_TS TIMESTAMP DEFAULT CURRENT_TIMESTAMP ,
);
CREATE OR REPLACE TRIGGER TRG_foo_UPD
BEFORE INSERT OR UPDATE ON foo
REFERENCING NEW AS NEW_ROW
FOR EACH ROW
BEGIN
SELECT SYSDATE
INTO :NEW_ROW.UPDATE_TS
FROM DUAL;
END;
/
基于查询的提取
有时可能想从RDBMS中提取数据,但希望有比整个表更灵活的方式,原因可能包括:
- 一个有许多列的宽表,但是只希望有部分列被传输到Kafka主题上;
- 表中包含敏感信息,不希望这些信息传输到Kafka主题上(尽管也可以提取时在Kafka连接器中使用单消息转换进行处理);
- 多个表之间存在依赖关系,因此在传输到Kafka之前,可能希望将其解析为一个单一的一致性视图。
这可以使用JDBC连接器的 query 模式。在了解如何实现之前,需要注意以下几点:
- 谨防管道的“过早优化”,仅仅因为不需要源表中的某些列或行,而不是说在流式传输到Kafka时不应包含它们;
- 正如将在下面看到的,当涉及增量摄取时,
query模式可能不那么灵活,因此从源中简单地删除列的另一种方法(无论是简单地减少数量,还是因为敏感信息)都是在连接器本身中使用ReplaceField单消息转换; - 随着查询越来越复杂(例如解析关联),潜在的压力和对源数据库的影响会增加;
- 在RDBMS(作为源头)中关联数据是解决关联的一种方法,另一种方法是将源表流式传输到单独的Kafka主题,然后使用KSQL或Kafka Streams根据需求进行关联(过滤和标记数据也是如此),KSQL是在Kafka中对数据进行
后处理的绝佳方式,使管道尽可能简单。
下面将展示如何将 transactions 表,再加上 customers 表中的数据流式传输到Kafka:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_09",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-09",
"mode":"bulk",
"query":"SELECT t.txn_id, t.customer_id, t.amount, t.currency, t.txn_timestamp, c.first_name, c.last_name, c.email, c.gender, c.comments FROM demo.transactions t LEFT OUTER JOIN demo.customers c on t.customer_id = c.id;",
"poll.interval.ms" : 3600000
}
}'
可能注意到已切换回 bulk 模式,可以使用主键或者时间戳其中一个增量选项,但要确保在SELECT子句中包含相应的主键/时间戳列(例如 txn_id ):
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_10",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-10",
"mode":"incrementing",
"query":"SELECT txn_id, t.customer_id, t.amount, t.currency, t.txn_timestamp, c.first_name, c.last_name, c.email, c.gender, c.comments FROM demo.transactions t LEFT OUTER JOIN demo.customers c on t.customer_id = c.id",
"incrementing.column.name": "txn_id",
"validate.non.null": false
}
}'
如果不包括该列(即使它存在于源表中),那么连接器会报错并显示 org.apache.kafka.connect.errors.DataException 异常( #561 )或 java.lang.NullPointerException 异常( #560 ),这是因为连接器需要在返回的数据中获取值,以便可以存储相应偏移量的最新值。
如果使用 query 选项,除非使用 mode: bulk ( #566 ),否则无法指定自己的WHERE子句,也就是说,在查询中使用自己的谓词和使用Kafka进行增量提取之间是互斥的。
一个还是多个连接器?
如果需要不同的参数设定,可以创建新的连接器,例如,可能希望有不同的参数:
- 包含自增主键和/或时间戳的列的名称;
- 轮询表的频率;
- 连接数据库的用户不同。
简单来说,如果所有表参数都一样,则可以使用单个连接器。
为什么没有数据?
创建连接器之后,可能在目标Kafka主题中看不到任何数据。下面会一步步进行诊断:
1.查询 /connectors 端点,可确认连接器是否创建成功:
$ curl -s“http:// localhost:8083 / connectors” [ “jdbc_source_mysql_10”]
应该看到连接器列表,如果没有,则需要按照之前的步骤进行创建,然后关注Kafka连接器返回的任何错误。
2.检查连接器及其任务的状态:
$ curl -s "http://localhost:8083/connectors/jdbc_source_mysql_10/status"|jq '.'
{
"name": "jdbc_source_mysql_10",
"connector": {
"state": "RUNNING",
"worker_id": "kafka-connect:8083"
},
"tasks": [
{
"state": "RUNNING",
"id": 0,
"worker_id": "kafka-connect:8083"
}
],
"type": "source"
}
正常应该看到所有的连接器和任务的 state 都是 RUNNING ,不过 RUNNING 不总是意味着正常。
3.如果连接器或任务的状态是 FAILED ,或者即使状态是 RUNNING 但是没有按照预期行为运行,那么可以转到Kafka连接器工作节点的输出( 这里 有相关的说明),这里会显示是否存在任何实际的问题。以上面的连接器为例,其状态为 RUNNING ,但是连接器工作节点日志中实际上全是重复的错误:
ERROR Failed to run query for table TimestampIncrementingTableQuerier{table=null, query='SELECT t.id, t.customer_id, t.amount, t.currency, t.txn_timestamp, c.first_name, c.last_name, c.email, c.gender, c.comments FROM demo.transactions t LEFT OUTER JOIN demo.customers c on t.customer_id = c.id;', topicPrefix='mysql-10', incrementingColumn='t.id', timestampColumns=[]}: {} (io.confluent.connect.jdbc.source.JdbcSourceTask)
java.sql.SQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'WHERE `t.id` > -1 ORDER BY `t.id` ASC' at line 1
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:120)
4.在这里,问题是什么并不明确,需要调出连接器的配置来检查指定的查询是否正确:
$ curl -s "http://localhost:8083/connectors/jdbc_source_mysql_10/config"|jq '.'
{
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"mode": "incrementing",
"incrementing.column.name": "t.id",
"topic.prefix": "mysql-10",
"connection.password": "asgard",
"validate.non.null": "false",
"connection.user": "connect_user",
"query": "SELECT t.id, t.customer_id, t.amount, t.currency, t.txn_timestamp, c.first_name, c.last_name, c.email, c.gender, c.comments FROM demo.transactions t LEFT OUTER JOIN demo.customers c on t.customer_id = c.id;",
"name": "jdbc_source_mysql_10",
"connection.url": "jdbc:mysql://mysql:3306/demo"
}
5.在MySQL中运行此查询发现能正常执行:
mysql> SELECT t.id, t.customer_id, t.amount, t.currency, t.txn_timestamp, c.first_name, c.last_name, c.email, c.gender, c.comments FROM demo.transactions t LEFT OUTER JOIN demo.customers c on t.customer_id = c.id; +------+-------------+--------+----------+----------------------+------------+-----------+----------------------------+--------+------------------------------------------------------+ | id | customer_id | amount | currency | txn_timestamp | first_name | last_name | email | gender | comments | +------+-------------+--------+----------+----------------------+------------+-----------+----------------------------+--------+------------------------------------------------------+ | 1 | 5 | -72.97 | RUB | 2018-12-12T13:58:37Z | Modestia | Coltart | mcoltart4@scribd.com | Female | Reverse-engineered non-volatile success
6.所以肯定是Kafka连接器在执行时做了什么。鉴于错误消息引用 t.id ,这是在 incrementing.column.name 参数中指定的,可能问题与此有关。通过将Kafka连接器的日志级别调整为 DEBUG ,可以看到执行的完整SQL语句:
DEBUG TimestampIncrementingTableQuerier{table=null, query='SELECT t.id, t.customer_id, t.amount, t.currency, t.txn_timestamp, c.first_name, c.last_name, c.email, c.gender, c.comments FROM demo.transactions t LEFT OUTER JOIN demo.customers c on t.customer_id = c.id;', topicPrefix='mysql-10', incrementingColumn='t.id', timestampColumns=[]} prepared SQL query: SELECT t.id, t.customer_id, t.amount, t.currency, t.txn_timestamp, c.first_name, c.last_name, c.email, c.gender, c.comments FROM demo.transactions t LEFT OUTER JOIN demo.customers c on t.customer_id = c.id; WHERE `t.id` > ? ORDER BY `t.id` ASC (io.confluent.connect.jdbc.source.TimestampIncrementingTableQuerier)
7.看一下该 prepared SQL query 部分,可能会发现:
[…] FROM demo.transactions t LEFT OUTER JOIN demo.customers c on t.customer_id = c.id; WHERE `t.id` > ? ORDER BY `t.id` ASC
8.注意在 JOIN 子句的 c.id 后面有语句终止符(;),后面有WHERE子句。该 WHERE 子句由Kafka连接器附加,用于实现所要求的 incrementing 模式,但创建了一个无效的SQL语句; 9.然后在GitHub中查找与看到的错误相关的问题,因为有时它实际上是一个已知的问题,例如这个问题; 10.如果连接器存在并且是 RUNNING ,并且Kafka连接器工作节点日志中也没有错误,还应该检查:
- 连接器的提取间隔是多少?也许它完全按照配置运行,并且源表中的数据已经更改,但就是没有拉取到新数据。要检查这一点,可以在Kafka连接器工作节点的输出中查找`JdbcSourceTaskConfig`的值和`poll.interval.ms`的值; - 如果正在使用的是增量摄取,Kafka连接器关于偏移量是如何存储的?如果删除并重建相同名称的连接器,则将保留前一个实例的偏移量。考虑这样的场景,创建完连接器之后,成功地将所有数据提取到源表中的给定主键或时间戳值,然后删除并重新创建了它,新版本的连接器将获得之前版本的偏移量,因此仅提取比先前处理的数据更新的数据,具体可以通过查看保存在其中的`offset.storage.topic`值和相关表来验证这一点。
重置JDBC源连接器读取数据的点
当Kafka连接器以分布式模式运行时,它会在Kafka主题(通过 offset.storage.topic 配置)中存储有关它在源系统中读取的位置(称为偏移量)的信息,当连接器任务重启时,它可以从之前的位置继续进行处理,具体可以在连接器工作节点日志中看到:
INFO Found offset {{protocol=1, table=demo.accounts}={timestamp_nanos=0, timestamp=1547030056000}, {table=accounts}=null} for partition {protocol=1, table=demo.accounts} (io.confluent.connect.jdbc.source.JdbcSourceTask)
每次连接器轮询时,都会使用这个偏移量,它会使用预编译的SQL语句,并且使用Kafka连接器任务传递的值替换 ? 占位符:
DEBUG TimestampIncrementingTableQuerier{table="demo"."accounts", query='null', topicPrefix='mysql-08-', incrementingColumn='', timestampColumns=[UPDATE_TS]} prepared SQL query: SELECT * FROM `demo`.`accounts` WHERE `demo`.`accounts`.`UPDATE_TS` > ? AND `demo`.`accounts`.`UPDATE_TS` < ? ORDER BY `demo`.`accounts`.`UPDATE_TS` ASC (io.confluent.connect.jdbc.source.TimestampIncrementingTableQuerier)
DEBUG Executing prepared statement with timestamp value = 2019-01-09 10:34:16.000 end time = 2019-01-09 13:23:40.000 (io.confluent.connect.jdbc.source.TimestampIncrementingCriteria)
这里,第一个时间戳值就是存储的偏移量,第二个时间戳值是当前时间戳。
虽然没有文档记载,但可以手动更改连接器使用的偏移量,因为是在JDBC源连接器的上下文中,所以可以跨多个源连接器类型,这意味着更改时间戳或主键,连接器会将后续记录视为未处理的状态。
首先要做的是确保Kafka连接器已经刷新了周期性的偏移量,可以在工作节点日志中看到何时执行此操作:
INFO WorkerSourceTask{id=jdbc_source_mysql_08-0} Committing offsets (org.apache.kafka.connect.runtime.WorkerSourceTask)
看下Kafka的主题,可以看到Kafka连接器创建的内部主题,并且负责偏移量的主题也是其中之一,名字可能有所不同:
ksql> LIST TOPICS;
Kafka Topic | Registered | Partitions | Partition Replicas | Consumers | ConsumerGroups
----------------------------------------------------------------------------------------------------
docker-connect-configs | false | 1 | 1 | 0 | 0
docker-connect-offsets | false | 1 | 1 | 0 | 0
docker-connect-status | false | 5 | 1 | 0 | 0
ksql> PRINT 'docker-connect-offsets' FROM BEGINNING;
Format:JSON
{"ROWTIME":1547038346644,"ROWKEY":"[/"jdbc_source_mysql_08/",{/"protocol/":/"1/",/"table/":/"demo.customers/"}]","timestamp_nanos":0,"timestamp":1547030057000}
当Kafka连接器任务启动时,它会读取此主题并使用适当主键的最新值。要更改偏移量,只需插入一个新值即可。最简单的方法是转存当前主题内容,修改内容并重新执行,因为一致性和简单,可以考虑使用 kafkacat :
- 转存当前的内容:
$ kafkacat -b kafka:29092 -t docker-connect-offsets -C -K# -o-1
% Reached end of topic docker-connect-offsets [0] at offset 0
["jdbc_source_mysql_08",{"protocol":"1","table":"demo.accounts"}]#{"timestamp_nanos":0,"timestamp":1547030056000}
);
如果是多个连接器,可能复杂些,但是这里只有一个,所以使用了 -o-1 标志,它定义了返回的偏移量。
- 根据需要修改偏移量。在这里使用了
mode=timestamp来监测表中的变化。时间戳值是1547030056000,使用相关的 时间戳转换 之类的工具,可以很容易地转换和操作,比如将其提前一小时(1547026456000)。接下来,使用更新后的timestamp值准备新消息:
["jdbc_source_mysql_08",{"protocol":"1","table":"demo.accounts"}]#{"timestamp_nanos":0,"timestamp":1547026456000}
- 将新消息发给主题:
echo '["jdbc_source_mysql_08",{"protocol":"1","table":"demo.accounts"}]#{"timestamp_nanos":0,"timestamp":1547026456000}' | /
kafkacat -b kafka:29092 -t docker-connect-offsets -P -Z -K#
- 如果要从头开始重启连接器,可以发送
NULL消息值:
echo'[“jdbc_source_mysql_08”,{“protocol”:“1”,“table”:“demo.accounts”}]#'| /
kafkacat -b kafka:29092 -t docker-connect-offsets -P -Z -K#
- 重启连接器任务:
curl -i -X POST -H "Accept:application/json" /
-H "Content-Type:application/json" http://localhost:8083/connectors/jdbc_source_mysql_08/tasks/0/restart
- 也可以只重启Kafka连接器工作节点,重启之后,数据源中所有比新设置的偏移量更新的记录,都会被重新提取到Kafka主题中。
从指定的时间戳或者主键处开启表的捕获
当使用时间戳或自增主键模式创建JDBC源连接器时,它会从主键为 -1 和/或时间戳为 1970-01-01 00:00:00.00 开始,这意味着会获得表的全部内容,然后在后续的轮询中获取任何插入/更新的数据。
但是如果不想要表的完整副本,只是希望连接器从现在开始,该怎么办呢?这在目前的Kafka连接器中还不支持,但可以使用前述的方法。不需要获取现有的偏移量消息并对其进行定制,而是自己创建。消息的格式依赖于正在使用的连接器和表的名称,一种做法是先创建连接器,确定格式,然后删除连接器,另一种做法是使用具有相同源表名和结构的环境,除非在该环境中没有可供连接器提取的数据,否则同样也能得到所需的消息格式。
在创建连接器之前,使用适当的值配置偏移量主题。在这里,希望从 demo.transactions 表中提取自增主键大于42的所有行:
echo '["jdbc_source_mysql_20",{"protocol":"1","table":"demo.transactions"}]#{"incrementing":42}' | /
kafkacat -b kafka:29092 -t docker-connect-offsets -P -Z -K#
下面创建连接器:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_20",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-20-",
"mode":"incrementing",
"table.whitelist" : "demo.transactions",
"incrementing.column.name": "txn_id",
"validate.non.null": false
}
}'
在生成的Kafka连接器工作日志中,可以看到:
INFO Found offset {{protocol=1, table=demo.transactions}={incrementing=42}, {table=transactions}=null} for partition {protocol=1, table=demo.transactions} (io.confluent.connect.jdbc.source.JdbcSourceTask)
…
DEBUG Executing prepared statement with incrementing value = 42 (io.confluent.connect.jdbc.source.TimestampIncrementingCriteria)
和预期一样,Kafka主题中只注入了 txn_id 大于42的行:
ksql> PRINT 'mysql-20x-transactions' FROM BEGINNING;
Format:AVRO
1/9/19 1:44:07 PM UTC, null, {"txn_id": 43, "customer_id": 3, "amount": {"bytes": "ús"}, "currency": "CNY", "txn_timestamp": "2018-12-15T08:23:24Z"}
1/9/19 1:44:07 PM UTC, null, {"txn_id": 44, "customer_id": 5, "amount": {"bytes": "/f!"}, "currency": "CZK", "txn_timestamp": "2018-10-04T13:10:17Z"}
1/9/19 1:44:07 PM UTC, null, {"txn_id": 45, "customer_id": 3, "amount": {"bytes": "çò"}, "currency": "USD", "txn_timestamp": "2018-04-03T03:40:49Z"}
配置Kafka消息键
Kafka消息是键/值对,其中值是 有效内容 。在JDBC连接器的上下文中,值是要被提取的表行的内容。Kafka消息中的键对于分区和下游处理非常重要,其中任何关联(比如KSQL)都将在数据中完成。
JDBC连接器默认不设置消息键,但是使用Kafka连接器的 单消息转换 (SMT)机制可以轻松实现。假设想要提取 accounts 表并将其 ID 列用作消息键。只需简单地将其添加到下面的配置中即可:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_06",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-06-",
"poll.interval.ms" : 3600000,
"table.whitelist" : "demo.accounts",
"mode":"bulk",
"transforms":"createKey,extractInt",
"transforms.createKey.type":"org.apache.kafka.connect.transforms.ValueToKey",
"transforms.createKey.fields":"id",
"transforms.extractInt.type":"org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.extractInt.field":"id"
}
}'
这时如果使用诸如 kafka-avro-console-consumer 之类的工具检查数据,就会看到键(JSON内容之前的最左列)与 id 值匹配:
kafka-avro-console-consumer /
--bootstrap-server kafka:29092 /
--property schema.registry.url=http://schema-registry:8081 /
--topic mysql-06-accounts --from-beginning --property print.key=true
1 {"id":{"int":1},"first_name":{"string":"Hamel"},"last_name":{"string":"Bly"},"username":{"string":"Hamel Bly"},"company":{"string":"Erdman-Halvorson"},"created_date":{"int":17759}}
2 {"id":{"int":2},"first_name":{"string":"Scottie"},"last_name":{"string":"Geerdts"},"username":{"string":"Scottie Geerdts"},"company":{"string":"Mante Group"},"created_date":{"int":17692}}
如果要在数据中设置键以便与KSQL一起使用,则需要将其创建为字符串类型,因为KSQL目前不支持其它键类型,具体可以在连接器配置中添加如下内容:
"key.converter": "org.apache.kafka.connect.storage.StringConverter"
然后就可以在KSQL中使用了:
ksql> CREATE STREAM ACCOUNTS WITH (KAFKA_TOPIC='mysql-06X-accounts', VALUE_FORMAT='AVRO'); ksql> SELECT ROWKEY, ID, FIRST_NAME + ' ' + LAST_NAME FROM ACCOUNTS; 1 | 1 | Hamel Bly 2 | 2 | Scottie Geerdts 3 | 3 | Giana Bryce
更改主题名称
JDBC连接器要求指定 topic.prefix ,但如果不想要,或者想将主题名更改为其它模式,SMT可以实现。
假设要删除 mysql-07- 前缀,那么需要一点 正则表达式 的技巧:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_07",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-07-",
"poll.interval.ms" : 3600000,
"catalog.pattern" : "demo",
"table.whitelist" : "accounts",
"mode":"bulk",
"transforms":"dropTopicPrefix",
"transforms.dropTopicPrefix.type":"org.apache.kafka.connect.transforms.RegexRouter",
"transforms.dropTopicPrefix.regex":"mysql-07-(.*)",
"transforms.dropTopicPrefix.replacement":"$1"
}
}'
这样主题名就和表名一致了:
ksql> LIST TOPICS; Kafka Topic | Registered | Partitions | Partition Replicas | Consumers | ConsumerGroups ---------------------------------------------------------------------------------------------------- accounts | false | 1 | 1 | 0 | 0
Bytes, Decimals, Numerics和自定义类型
这是话题比较深入。
-
numeric.mapping:best_fit如果源中包含NUMERIC/NUMBER类型的数据,则可能需要这个配置项; - 如果需要,可以在JDBC连接器中使用
query选项,用于对源表中的数据进行转换; - 如果字段以JDBC
DECIMAL类型暴露,则numeric.mapping无法处理:- MySQL将所有数值存储为
DECIMAL; - SQL Server将
DECIMAL和NUMERIC原生存储,因此必须将DECIMAL字段转换为NUMERIC;
- MySQL将所有数值存储为
- 在Oracle中,要在
NUMBER字段中指定长度和标度,例如NUMBER(5,0),不能是NUMBER; -
NUMERIC和DECIMAL都被视为NUMBER,INT也是;
完成之后,下面会做一个解释:
Kafka连接器是一个可以将数据注入Kafka、与特定源技术无关的框架。无论是来自SQL Server、DB2、MQTT、文本文件、REST还是Kafka连接器支持的任何其它数十种来源,它发送给Kafka的数据格式都为 Avro 或 JSON ,这通常是一个透明的过程,只是在处理数值数据类型时有些特别,比如 DECIMAL , NUMBER 等等,以下面的MySQL查询为例:
mysql> SELECT * FROM transactions LIMIT 1; +--------+-------------+--------+----------+----------------------+ | txn_id | customer_id | amount | currency | txn_timestamp | +--------+-------------+--------+----------+----------------------+ | 1 | 5 | -72.97 | RUB | 2018-12-12T13:58:37Z | +--------+-------------+--------+----------+----------------------+
挺正常是吧?其实, amount 列是 DECIMAL(5,2) :
mysql> describe transactions; +---------------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+-------+ | txn_id | int(11) | YES | | NULL | | | customer_id | int(11) | YES | | NULL | | | amount | decimal(5,2) | YES | | NULL | | | currency | varchar(50) | YES | | NULL | | | txn_timestamp | varchar(50) | YES | | NULL | | +---------------+--------------+------+-----+---------+-------+ 5 rows in set (0.00 sec)
但是当使用JDBC连接器的默认设置提取到Kafka中时,最终会是这样:
ksql> PRINT 'mysql-02-transactions' FROM BEGINNING;
Format:AVRO
1/4/19 5:38:45 PM UTC, null, {"txn_id": 1, "customer_id": 5, "amount": {"bytes": "ã/u007F"}, "currency": "RUB", "txn_timestamp": "2018-12-12T13:58:37Z"}
DECIMAL 变成了一个看似乱码的 bytes 值,连接器默认会使用自己的 DECIMAL 逻辑类型,该类型在Avro中被序列化为字节,可以通过查看Confluent Schema Registry中的相关条目来看到这一点:
$ curl -s "http://localhost:8081/subjects/mysql-02-transactions-value/versions/1"|jq '.schema|fromjson.fields[] | select (.name == "amount")'
{
"name": "amount",
"type": [
"null",
{
"type": "bytes",
"scale": 2,
"precision": 64,
"connect.version": 1,
"connect.parameters": {
"scale": "2"
},
"connect.name": "org.apache.kafka.connect.data.Decimal",
"logicalType": "decimal"
}
],
"default": null
}
当连接器使用 AvroConverter 消费时,这会正常处理并保存为 DECIMAL (并且在Java中也可以反序列化为 BigDecimal ),但对于反序列化Avro的其它消费者,它们只会得到字节。在使用启用了模式的JSON时,也会看到这一点, amount 值会是Base64编码的字节字符串:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "bytes",
"optional": true,
"name": "org.apache.kafka.connect.data.Decimal",
"version": 1,
"parameters": {
"scale": "2"
},
"field": "amount"
},
},
"payload": {
"txn_id": 1000,
"customer_id": 5,
"amount": "Cv8="
}
}
因此,不管使用的是JSON还是Avro,这都是 numeric.mapping 配置项的来源。它默认设置为 none (即使用连接器的 DECIMAL 类型),但通常希望连接器将类型实际转换为更兼容的类型,以适合数字的精度,更具体的说明,可以参见相关的 文档 。
此选项目前不支持 DECIMAL 类型 ,因此这里是在Postgres中具有 NUMERIC 类型的相同原理的示例:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_postgres_12",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:postgresql://postgres:5432/postgres",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "postgres-12-",
"numeric.mapping": "best_fit",
"table.whitelist" : "demo.transactions",
"mode":"bulk",
"poll.interval.ms" : 3600000
}
}'
结果如下所示:
ksql> PRINT 'postgres-12-transactions' FROM BEGINNING;
Format:AVRO
1/7/19 6:27:16 PM UTC, null, {"txn_id": 1, "customer_id": 5, "amount": -72.97, "currency": "RUB", "txn_timestamp": "2018-12-12T13:58:37Z"}
可以在 这里 看到有关此内容的更多详细信息,以及Postgres、Oracle和MS SQL Server中的示例。
处理多个表
如果需要从多个表中提取数据,则可以通过并行处理来减少总提取时间,这在Kafka的JDBC连接器有两种方法:
- 定义多个连接器,每个连接器都处理单独的表;
- 定义单个连接器,但增加任务数。每个Kafka连接器的工作由一个或多个 任务 来执行,每个连接器默认只有一个任务,这意味着从数据库中提取数据是单进程处理的。
前者具有更高的管理开销,但确实提供了每个表自定义设置的灵活性。如果可以使用相同的连接器配置提取所有表,则增加单个连接器中的任务数是一种好方法。
当增加从数据库中提取数据的并发性时,要从整体上考虑。因为运行一百个并发任务虽然可能会更快,但数百个与数据库的连接可能会对数据库产生负面影响。
以下是同一连接器的两个示例。两者都将从数据库中提取所有表,总共6个。在第一个连接器中,未指定最大任务数,因此为默认值1。在第二个中,指定了最多运行三个任务( "tasks.max":3 ):
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_01",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-01-",
"mode":"bulk"
}
}'
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_11",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-11-",
"mode":"bulk",
"tasks.max":3
}
}'
当查询连接器的 Kafka连接器REST API时,可以看到每个连接器正在运行的任务数以及它们已分配的表。第一个连接器有一个任务负责所有6张表:
$ curl -s "http://localhost:8083/connectors/jdbc_source_mysql_01/tasks"|jq '.'
[
{
"id": {
"connector": "jdbc_source_mysql_01",
"task": 0
},
"config": {
"tables": "`demo`.`NUM_TEST`,`demo`.`accounts`,`demo`.`customers`,`demo`.`transactions`,`security`.`firewall`,`security`.`log_events`",
…
}
}
]
第二个连接器有3个任务,每个任务分配2张表:
$ curl -s“http:// localhost:8083 / connectors / jdbc_source_mysql_11 / tasks”| jq'。'
[
{
“ID”: {
“connector”:“jdbc_source_mysql_11”,“任务”:0
},
“config”:{
“tables”:“`demo` .NUM_TEST`,`demo` .accounts`”,
...
}
},
{
“ID”: {
“connector”:“jdbc_source_mysql_11”,“任务”:1
},
“config”:{
“tables”:“`demo``customers`,`demo` .transactions`”,
...
}
},
{
“ID”: {
“connector”:“jdbc_source_mysql_11”,“任务”:2
},
“config”:{
“tables”:“`security``firewall`,`security``log_events`”,
...
}
}
]
正文到此结束
- 本文标签: sql 管理 App value consumer DDL trigger IO 目录 乱码 定制 UTC mail Oracle zookeeper NSA CTO key final src SQLite plugin mysql Mysql数据库 编译 并发 db find 集群 Bootstrap 时间 Docker volatile dist 下载 ORM 正则表达式 bug ssl stream db2 tar 搜索引擎 数据 需求 json 参数 client ACE Service 一致性 root retry IBM cat UI GitHub 实例 REST schema Word Action 分布式 apache 缓存 tab js 压力 配置 Netty URLs 插件 Connection 删除 Property id update Statement 认证 https 进程 安装 FIT Select SyntaxError SQL Server http Security 希望 java JDBC rpm git map API 解析 list Amazon ask message MQ rmi 索引 classpath 2019 struct 数据库
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

