开始使用GraphQL Java和Spring Boot
这是一篇为想要用Java搭建GraphQL服务器的小伙伴们准备的教程。需要你有一定的Spring Boot和Java开发相关知识,虽然我们简要介绍了GraphQL,但是本教程的重点是用Java开发一个GraphQL服务器。
三分钟介绍GraphQL
GraphQL是一门从服务器检索数据的查询语言。在某些场景下可以替换REST、SOAP和gRPC。让我们假设我们想要从一个在线商城的后端获取某一个本书的详情。
你使用GraphQL往服务器发送如下查询去获取id为"123"的那本书的详情:
{
bookById(id: "book-1"){
id
name
pageCount
author {
firstName
lastName
}
}
}
复制代码
这不是一段JSON(尽管它看起来非常像),而是一条GraphQL查询。它基本上表示:
- 查询某个特定id的书
- 给我那本书的id、name、pageCount、author
- 对于author我想知道firstName和lastName
响应是一段普通JSON:
{
"bookById":
{
"id":"book-1",
"name":"Harry Potter and the Philosopher's Stone",
"pageCount":223,
"author": {
"firstName":"Joanne",
"lastName":"Rowling"
}
}
}
复制代码
静态类型是GraphQL最重要的特性之一:服务器明确地知道你想要查询的每个对象都是什么样子的并且任何client都可以"内省"于服务器并请求"schema"。schema描述的是查询可能是哪些情况并且你可以拿到哪些字段。(注意:当提及schema时,我们经常指的是"GraphQL Schema",而不是像"JSON Schema"或者"Database Schema")
上面提及的查询的schema是这样描述的:
type Query {
bookById(id: ID): Book
}
type Book {
id: ID
name: String
pageCount: Int
author: Author
}
type Author {
id: ID
firstName: String
lastName: String
}
复制代码
这篇教程将关注于如何用Java实现一个有着这种schema的GraphQL服务器。
我们仅仅触及了GraphQL的一些基本功能。更多内容可以去官网查看 graphql.github.io/learn/
GraphQL Java 预览
GraphQL Java是GraphQL的Java(服务器)实现。GraphQL Java Github org中有几个Git仓库。其中最重要的一个是 GraphQL Java 引擎 ,它是其他所有东西的基础。
GraphQL Java引擎本身只关心执行查询。它不处理任何HTTP或JSON相关主题。因此,我们将使用 GraphQL Java Spring Boot adapter,它通过Spring Boot在HTTP上暴露API。
创建GraphQL Java服务器的主要步骤如下:
- 定义GraphQL Schema。
- 决定如何获取需要查询的实际数据。
我们的示例API:获取图书详细信息
我们的示例应用程序将是一个简单的API,用于获取特定书籍的详细信息。这个API并不是很全面,但对于本教程来说已经足够了。
创建一个Spring Boot应用程序
创建Spring应用程序的最简单方法是使用start.spring.io/上的“Spring Initializr”。
选择:
- Gradle Project
- Java
- Spring Boot 2.1.x
对于我们使用的项目元数据:
com.graphql-java.tutorial book-details
至于dependency(依赖项),我们只选择Web。
点击 Generate Project ,你就可以使用Spring Boot app了。所有后面提到的文件和路径都是与这个Generate Project相关的。
我们在 build.gradle 的 dependencies 部分为我们的项目添加了三个依赖项:
前两个是GraphQL Java和GraphQL Java Spring,然后我们还添加了 Google Guava 。Guava并不是必须的,但它会让我们的生活更容易一点。
依赖项看起来是这样的:
dependencies {
implementation 'com.graphql-java:graphql-java:11.0' // NEW
implementation 'com.graphql-java:graphql-java-spring-boot-starter-webmvc:1.0' // NEW
implementation 'com.google.guava:guava:26.0-jre' // NEW
implementation 'org.springframework.boot:spring-boot-starter-web'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
复制代码
Schema
我们正在 src/main/resources 下创建一个新的文件 schema.graphqls ,它包含以下内容:
type Query {
bookById(id: ID): Book
}
type Book {
id: ID
name: String
pageCount: Int
author: Author
}
type Author {
id: ID
firstName: String
lastName: String
}
复制代码
此schema定义了一个顶层字段(在 Query 类型中): bookById ,它返回特定图书的详细信息。
它还定义了类型 Book ,它包含了: id 、 name 、 pageCount 和 author 。 author 属于 Author 类型,在 Book 之后定义。
上面显示的用于描述模式的特定于域的语言称为模式定义语言或SDL。更多细节可以在这里找到。
一旦我们有了这个文件,我们就需要通过读取文件并解析它,然后添加代码来为它获取数据,从而“让它活起来”。
我们在 com.graphqljava.tutorial.bookdetails 包中创建了一个新的 GraphQLProvider 类。 init 方法将创建一个GraphQL实例:
@Component
public class GraphQLProvider {
private GraphQL graphQL;
@Bean
public GraphQL graphQL() {
return graphQL;
}
@PostConstruct
public void init() throws IOException {
URL url = Resources.getResource("schema.graphqls");
String sdl = Resources.toString(url, Charsets.UTF_8);
GraphQLSchema graphQLSchema = buildSchema(sdl);
this.graphQL = GraphQL.newGraphQL(graphQLSchema).build();
}
private GraphQLSchema buildSchema(String sdl) {
// TODO: we will create the schema here later
}
}
复制代码
我们使用 Guava 资源从类路径读取文件,然后创 GraphQLSchema 和 GraphQL 实例。这个 GraphQL 实例通过使用 @Bean 注解的 GraphQL() 方法作为Spring Bean暴露出去。GraphQL Java Spring适配器将使用该 GraphQL 实例,使我们的schema可以通过默认url /GraphQL 进行HTTP访问。
我们还需要做的是实现 buildSchema 方法,它创建 GraphQLSchema 实例,并连接代码来获取数据:
@Autowired
GraphQLDataFetchers graphQLDataFetchers;
private GraphQLSchema buildSchema(String sdl) {
TypeDefinitionRegistry typeRegistry = new SchemaParser().parse(sdl);
RuntimeWiring runtimeWiring = buildWiring();
SchemaGenerator schemaGenerator = new SchemaGenerator();
return schemaGenerator.makeExecutableSchema(typeRegistry, runtimeWiring);
}
private RuntimeWiring buildWiring() {
return RuntimeWiring.newRuntimeWiring()
.type(newTypeWiring("Query")
.dataFetcher("bookById", graphQLDataFetchers.getBookByIdDataFetcher()))
.type(newTypeWiring("Book")
.dataFetcher("author", graphQLDataFetchers.getAuthorDataFetcher()))
.build();
}
复制代码
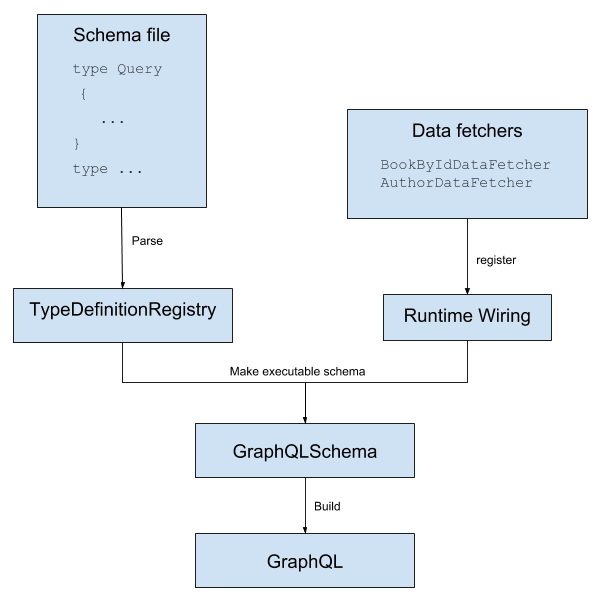
TypeDefinitionRegistry 是schema文件的解析版本。SchemaGenerator将 TypeDefinitionRegistry 与 RuntimeWiring 结合起来,实际生成 GraphQLSchema 。
buildRuntimeWiring 使用 graphQLDataFetchers bean来注册两个 Datafetcher s:
- 一个是检索具有特定ID的图书。
- 一个是为特定的书找到作者。
下一节将解释 DataFetcher 以及如何实现 GraphQLDataFetchers bean。
总的来说,创建 GraphQL 和 GraphQLSchema 实例的过程是这样的:
DataFetchers
GraphQL Java服务器最重要的概念可能是 Datafetcher :在执行查询时, Datafetcher 获取一个字段的数据。
当GraphQL Java执行查询时,它为查询中遇到的每个字段调用适当的 Datafetcher 。 DataFetcher 是一个只有一个方法的接口,带有一个类型的参数 DataFetcherEnvironment :
public interface DataFetcher<T> {
T get(DataFetchingEnvironment dataFetchingEnvironment) throws Exception;
}
复制代码
重要提示:模式中的每个字段都有一个与之关联的 DataFetcher 。如果没有为特定字段指定任何 DataFetcher ,则使用默认的 PropertyDataFetcher 。我们稍后将更详细地讨论这个问题。
我们正在创建一个新的类 GraphQLDataFetchers ,其中包含图书和作者的示例列表。
完整的实现是这样的,我们将很快详细研究它:
@Component
public class GraphQLDataFetchers {
private static List<Map<String, String>> books = Arrays.asList(
ImmutableMap.of("id", "book-1",
"name", "Harry Potter and the Philosopher's Stone",
"pageCount", "223",
"authorId", "author-1"),
ImmutableMap.of("id", "book-2",
"name", "Moby Dick",
"pageCount", "635",
"authorId", "author-2"),
ImmutableMap.of("id", "book-3",
"name", "Interview with the vampire",
"pageCount", "371",
"authorId", "author-3")
);
private static List<Map<String, String>> authors = Arrays.asList(
ImmutableMap.of("id", "author-1",
"firstName", "Joanne",
"lastName", "Rowling"),
ImmutableMap.of("id", "author-2",
"firstName", "Herman",
"lastName", "Melville"),
ImmutableMap.of("id", "author-3",
"firstName", "Anne",
"lastName", "Rice")
);
public DataFetcher getBookByIdDataFetcher() {
return dataFetchingEnvironment -> {
String bookId = dataFetchingEnvironment.getArgument("id");
return books
.stream()
.filter(book -> book.get("id").equals(bookId))
.findFirst()
.orElse(null);
};
}
public DataFetcher getAuthorDataFetcher() {
return dataFetchingEnvironment -> {
Map<String,String> book = dataFetchingEnvironment.getSource();
String authorId = book.get("authorId");
return authors
.stream()
.filter(author -> author.get("id").equals(authorId))
.findFirst()
.orElse(null);
};
}
}
复制代码
数据源
我们从类中的静态列表中获取图书和作者。这只是为了本教程而做的。理解GraphQL并不指定数据来自何处是非常重要的。这就是GraphQL的强大之处:它可以来自内存中的静态列表、数据库或外部服务。
Book DataFetcher
我们的第一个方法 getBookByIdDataFetcher 返回一个 DataFetcher 实现,该实现接受一个 DataFetcherEnvironment 并返回一本书。在本例中,这意味着我们需要从 bookById 字段获取id参数,并找到具有此特定id的图书。
String bookId = dataFetchingEnvironment.getArgument("id"); 中的"id"为schema中 bookById 查询字段中的“id”:
type Query {
bookById(id: ID): Book
}
...
复制代码
Author DataFetcher
第二个方法 getAuthorDataFetcher 返回一个 Datafetcher ,用于获取特定书籍的作者。与前面描述的book DataFetcher 相比,我们没有参数,但是有一个book实例。来自父字段的 DataFetcher 的结果可以通过 getSource 获得。这是一个需要理解的重要概念:GraphQL中每个字段的 Datafetcher 都是以自顶向下的方式调用的,父字段的结果是子 Datafetcherenvironment 的 source 属性。
然后,我们使用先前获取的图书获取authorId,并以查找特定图书的相同方式查找特定的作者。
Default DataFetchers
我们只实现了两个 Datafetcher 。如上所述,如果不指定一个,则使用默认的 PropertyDataFetcher 。在我们的例子中,它指的是 Book.id 、 Book.name 、 Book.pageCount 、 Author.id 、 Author.firstName 和 Author.lastName 都有一个默认的 PropertyDataFetcher 与之关联。
PropertyDataFetcher 尝试以多种方式查找Java对象上的属性。以 java.util.Map 为例, 它只是按键查找属性。这对我们来说非常好,因为book和author映射的键与schema中指定的字段相同。例如,在我们为图书类型定义的schema中,字段 pageCount 和book DataFetcher 返回一个带有键 pageCount 的 Map 。因为字段名与 Map 中的键相同(“pageCount”), PropertyDateFetcher 正常工作。
让我们假设我们有一个不匹配,book Map 有一个键是 totalPages 而不是 pageCount 。这将导致每本书的 pageCount 值为 null ,因为 PropertyDataFetcher 无法获取正确的值。为了解决这个问题,你必须为 Book.pageCount 注册一个新的 DataFetcher 。它看起来像这样:
// In the GraphQLProvider class
private RuntimeWiring buildWiring() {
return RuntimeWiring.newRuntimeWiring()
.type(newTypeWiring("Query")
.dataFetcher("bookById", graphQLDataFetchers.getBookByIdDataFetcher()))
.type(newTypeWiring("Book")
.dataFetcher("author", graphQLDataFetchers.getAuthorDataFetcher())
// This line is new: we need to register the additional DataFetcher
.dataFetcher("pageCount", graphQLDataFetchers.getPageCountDataFetcher()))
.build();
}
// In the GraphQLDataFetchers class
// Implement the DataFetcher
public DataFetcher getPageCountDataFetcher() {
return dataFetchingEnvironment -> {
Map<String,String> book = dataFetchingEnvironment.getSource();
return book.get("totalPages");
};
}
...
复制代码
这个 DataFetcher 将通过在book Map 中查找正确的键来解决这个问题。(同样:在我们的示例中不需要这个,因为我们没有命名不匹配)
试用API
这就是构建一个可工作的GraphQL API所需的全部内容。在启动Spring Boot应用程序之后,可以在 http://localhost:8080/graphql 上使用API。
尝试和探索GraphQL API的最简单方法是使用 GraphQL Playground 的工具。下载并运行它。
启动之后,你将被要求输入一个URL,输入 http://localhost:8080/graphql 。
之后,你可以查询我们的示例API,您应该会得到我们在开始时提到的结果。它应该是这样的:
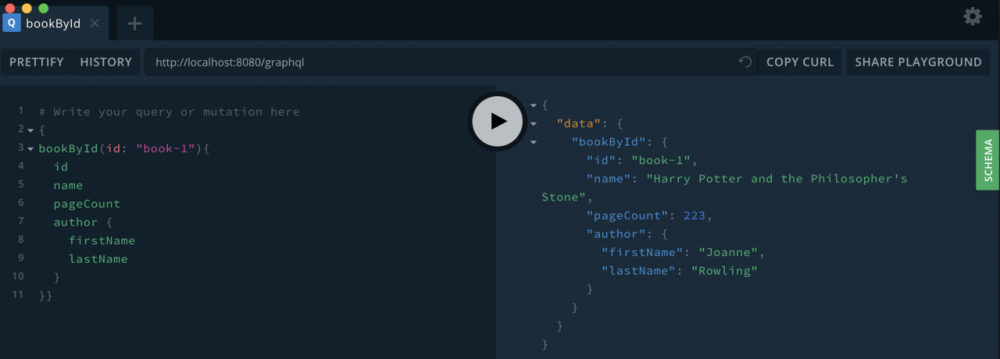
正文到此结束
- 本文标签: Google REST struct http UI 适配器 解析 spring provider bean API list tab src map equals App 开发 js Property SOA json 服务器 client 数据库 Spring Boot 代码 dependencies https 下载 IDE 实例 web build find id GitHub 参数 git ACE 数据 stream parse java schema tar IO
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

