Java 类型系统从入门到放弃
作者 | 夏梓耀

杏仁后端工程师,励志成为计算机艺术家
总结
为什么文章的一开头会是总结?因为我怕你看不到最后 (¬_¬),本文不止是内容上过于偏重理论,信息量还非常大,但我不喜欢分篇,因为我觉得它是完整的。
虽然写了一万多字(写了半个月 _(:з」∠)_),但是还是有很多东西不是讲的很清楚,一是删减了一些理论背景(可能需要你额外去学习一下),精简后只保留了核心部分;二是本人水平的问题(逃
本文描述的是类型系统,一个只存在于编译阶段描述类型检查的形式系统(连个具体的程序都不是),是被广大程序员忽略的存在;并且还常常听到这样的言论:不要做编译器的奴隶(我经常在一些动态类型语言的广告里看到这样的话),是的,不要做编译器的奴隶,并不是应该抛掉编译器(的类型检查器),而是应该了解编译器,并且做编译器的主人,这才是正确的。
对程序员来说,编译器(的类型检查器)是一种财富,是你的武器,我们应该掌握语言的类型系统,并且让它更好的为我们服务,保证程序的安全性(正确性),在编译阶段就将犯错的可能性扼杀掉(即:将 BUG 杀死在摇篮中)
良好的类型定义也是一份良好的文档,会让我们的接口语义更加清晰,我们应该花时间思考类型定义,并且尽可能细化类型的定义。
本文是我学习的类型系统相关理论知识和 Java 类型系统的一篇总结,涉及到 Java 是希望将理论知识与实践结合(从而不无聊)。
Java 类型系统
众所周知,Java 在 Java 5.0 引入了泛型(Generics)aka 参数化多态 (parametric polymorphism),进一步的提高了类型安全性(type safe),对开发者来说最大的变化应该是:从一个集合里取出一个元素终于不需要强制类型转换(cast)了。
参数化多态 (Parametric Polymorphism)
为什么要引入参数化多态?因为它提高了语言的抽象能力,参数化多态意味着我们仅需写一个参数化的方法,比如:
<P, Q> Q f(Function<P, Q> f, P p) {
return f(p);
}
从而就有了:
Integer f(Function<String, Integer> f, String p) {...}
Boolean f(Function<String, Boolean> f, String p) {...}
String f(Function<Integer, String> f, Integer p) {...}
...
无数个方法,大大减少了重复性。
稍微理论一点的说法就是:具体类型,比如 List<Integer> 、 List<String> 都被一个类型参数 T 给索引了,当 T 为 Integer 时, List<T> 为 List<Integer> ,Integer 就是 T 的具体化/实例(instantiate)。
子类型化 (Subtyping)
除了参数化多态,Java 作为一门面向对象的语言,本身就有面向对象类型系统的核心特征:子类型多态(subtype polymorphism),也就是我们常说的 "继承、封装、多态" 的 "多态"。这个大家都比较熟了(平常用的最多的特性),不过 Java 在引入参数化多态的时候,其实是有对很多提案进行比较和权衡的,因为要做的不仅是单纯的引入参数化多态,还要考虑与现有的子类型结合起来。
边界/囿[yòu]量词 (Bounded Quantification)
首先是对参数化多态的扩展,支持给泛型变量添加边界,即: <T extends X> 等,这样可以表示更加精确的类型约束,而不仅仅是 forall;不仅如此,Java 还支持 F-bounded,即类型变量可以出现在自己的上边界中: <T extends F<T>> ,这有什么用呢?举个熟悉的例子:
interface Comparable<T> {
public int compareTo(T other);
}
class Integer implements Comparable<Integer> {
@Override
public int compareTo(Integer other) {
//...
}
}
class String implements Comparable<String> {
@Override
public int compareTo(String other) {
//...
}
}
class Test {
public static void main(String[] args) {
Comparable<String> a = min("cat", "dog");
Comparable<Integer> b = min(new Integer(10), new Integer(3));
String str = Fmin("cat", "dog");
Integer i = Fmin(new Integer(10), new Integer(3));
}
public static <S extends Comparable> S min(S a, S b) {
if (a.compareTo(b) <= 0)
return a;
else
return b;
}
public static <T extends Comparable<T>> T Fmin(T a, T b) {
if (a.compareTo(b) <= 0)
return a;
else
return b;
}
}
注意 Fmin 方法的 <T extends Comparable<T>> ,如果 Comparable 不能包含 T,即像 min 方法那样,就会丢失接口 Comparable compareTo 方法的参数类型 (变成 Object),你会收到一个编译器的警告,说你绕过了编译检查直接使用了 raw type(参数化类型擦除后的类型);详情可参考 F-bounded quantification。
Wildcards
即便如此,子类型化和参数化多态依然存在分裂,试问 List<Integer> 和 List<Number> 是什么关系?答案是:没有关系;你 Integer 是 Number 的子类,和我 List<Integer> 与 List<Number> 又有什么关系 (づ ̄ 3 ̄)づ。
所以必须引入一个平滑过渡的桥梁,即:wildcards,也就是那个 <?> ,
为了让他们有关系(也就是所谓型变 variance),引入了 wildcards, List<? extends Integer> 就是 List<? extends Number> 的子类 (详情参考Wildcards and Subtyping)。
综上是 Java 类型系统的主要特性,可以说是相当的复杂,也相当的强大,因为它包含了面向对象语言独有的子类型多态和函数式语言的参数化多态,再加上 F-bounded 和 wildcards,已经够让人喝一壶的了。
更多内容可以参考官方教程:Lesson: Generics。
注: 本文不包含 Java8 引入 Lambda 表达式支持之后对类型系统扩展的相关内容。
类型系统(Type System)简史
什么是类型系统
类型系统简单的说就是语言的静态语义(static semantic),而 type-checking 就是静态语义分析的具体实现程序,即 type system 的实现;type system 本身就是一种模型,常常用数学语言描述,其作用就是保证程序的类型安全,拒绝非法类型的表达式/代码出现,因为类型不合法的程序往往会产生错误。注意不是 100% 产生错误,所以动态类型语言才会有市场,如果能做到非法类型即非法行为(类型系统足够强大)的话,动态类型的语言将毫无价值,ducking type 只不过是个静态检查的灰色地带而已(纯个人看法,误喷)。
注:就大部分语言来说,类型系统的安保能力都是有限的,且依赖于(编译期)静态检查;大部分语言的安全性,除了静态检查之外,还依靠(运行时)动态检查,比如数组越界等。
Modern software engineering recognizes a broad range of formal methods for helping ensure that a system behaves correctly with respect to some specification, implicit or explicit, of its desired behavior. But by far the most popular and best established lightweight formal methods are type systems —— Types and Programming Languages
类型检查器(Type-checking)
Type-checking 已经在前面说过了,是类型系统的实现,是一段可执行的程序,内嵌在编译器中。它的参数是一段表达式和当前上下文,返回值为表达式的类型,常常简化为一个函数表示:
typeof: (Γ, e) -> t
大写希腊字母 Γ 用于表示当前上下文(typing context, aka typing environment),它就是一个类型绑定关系的 Map,保存了项的类型(即:e 到 t),e 为表达式的 AST(抽象语法树),t 为类型(具体实现时也是一类特殊的 AST 节点),typeof 在数学上的写法为: Γ ├ e: t 读作:在类型上下文 Γ 下,e 的类型为 t;符号 '├' 在数学上是推导,推断的意思,它在这是一种三元关系即:HasType(Γ, e, t)。
所以只要在当前上下文下,语法项有具体类型,则类型检查就通过,如果无法返回其类型,那么就报错了,也就是我们常常看到的编译不过。
★注: 整个类型系统就是关系 ├ 对不同表达式结构(shape)的归纳定义,表现为若干条 typing rules (后面还会提到)。
Type
类型系统的核心是类型,类型是什么呢?有两种不同的角度,一种是计算的角度(程序员的角度)或者称 Church 的角度,另一种是逻辑的角度,或者叫 Curry 的角度;前者根据所计算的值的性质来对项(语法项)进行分类,你可以把类型比作集合,如类型 Integer,就是所有整型值的集合(当然实现层面有字长限制,并不是真正所有整型),它们有着共同的计算性质,即 Integer 类型支持的操作,比如:加减乘除;而 Boolean 类型,只有两个值 True 和 False,它们的计算性质就是布尔计算。
从 Curry 角度来说,就是对程序行为进行证明的推理工具,所以类型理论常常和证明理论扯上关系。
Untyped Lambda calculus
前面说过,类型系统是语言的静态语义,那么它必然是和所描述的编程语言(的语法构造)绑定的,没有语言谈何来的语义呢?但是,如果和某门特定的语言绑定的话,对类型系统的研究会很不方便,所以 Peter Landin 提出了用一个微小核心演算去形式化复杂语言的基本机制/特性的想法,而他选择的这个核心演算便是 Lambda calculus。
Lambda 演算可以看做是一门微小的函数式编程语言,它的语法构造非常简单,只有变量,函数(aka 抽象),和函数应用(调用):
<expr> ::= <name> | <function> | <application> <function> ::= λ<name>.<body> <body> ::= <expr> <application> ::= (<expr> <expr>)
举个例子,identity 函数(返回自身):
λx.x // 等价于 Java 的 lambda 表达式: x -> x
比如 const 函数(接收两个参数,永远返回第二参数):
λfrist.λsecond.second // 等价于 Java 的 lambda 表达式: (frist, second) -> second
你确实可以用它进行编程(计算),但是没数据怎么计算呢?(Lambda 演算中的值只有*函数*)这就涉及到一点点计算(数学)的本质了,在这里数据(data)也是函数(都是用函数 encode 出来的),比如 true 和 false:
true = λfrist.λsecond.first false = λfrist.λsecond.second
而我们的 if 语句本身也是个函数:
cond = λe1.λe2.λc.((c e1) e2) ((cond e1) e2) true 返回 e1 ((cond e1) e2) false 返回 e2
当然了,逻辑运算符,and、or、not 等都是函数;对于我们常见的自然数来说也是用函数 encode 出来的(明白为什么函数在函数式编程中是 first class 的了吧):
zero = λx.x succ = λn.λs.((s false) n) one = (succ zero) two = (succ one) = (succ (succ zero)) ... // 是否和古老语言 Lisp 有点像?
即,我们定义了 0 和 +1 操作,那么自然就有了自然数集,现在觉得它就是一门编程语言了吧?
注:我们用函数去表示数据,用函数去表示操作,一切都是函数
(至于循环结构,大家可能听说过 Y 组合子或 Z 组合子之类的,在纯函数式语言中循环都是通过递归去替代,而递归交由函数不动点实现,这里不展开了)
其实 lambda 演算是和图灵机等价的计算模型,所以不用担心它的能力,更多关于lambda演算和编程的关系(以及其求值方式),可以参考书籍《An Introduction to Functional Programming Through Lambda Calculus》。
不过这么一门微内核的语言有点过于底层了(形象上离我们常见的语言有点遥远),故在研究类型系统时,为了方便,常常给它添加一些扩展,以及一些语法糖(即:导出形式),比如用 if-else 表达式而非 cond 函数;直接使用算术表达式(同时引入字面量),而非用函数去 encode;再比引入如局部变量的: let-in 表达式;还有最关键的是将非 ascii 符号 λ 改成关键字 fun 或 function 等。
有了这个核心语言后,其它的语言都可视为它的变种(及扩展)语言。
STLC (Simply Typed Lambda calculus)
前面介绍的 Lambda 演算是无类型的,它没有类型系统,也就是我定义一个函数 λx.λy.(x y) 你不知道 x,y 是什么类型,只能从语法结构上看出来,x 应该是个函数,但不知道具体是个怎样的函数,如果传入的 x 不符号期望,那么这个表达式就会得到错误的求值。
而 STLC 即:简单类型 Lambda 演算,就是在无类型的 Lambda 演算基础上添加了类型,其语法结构(BNF):
types:
τ ::= α base type
| τ → τ' function type
terms:
e ::= e : τ annotated term type τ
| x variable
| (e e') application
| λx.e lambda abstraction
我们看到在语法结构上,引入了类型(types),并且有两种,一种是基础类型 α,另一种是函数类型 τ → τ',这是一种复合类型,它由参数和返回值的类型 τ,τ' 组成。
这样我们就可以写出一个有类型的函数了:
λx: t1 -> t2.λy: t1.(x y) // 其类型为:(t1 -> t2) -> t1 -> t2
注:我们在表示函数类型的时候,使用的是 curry 化的形式,即上面函数类型等价于:((t1 -> t2), t1) -> t2,这样可以减少不必要的复杂性。
下图是 STLC 的 type system:
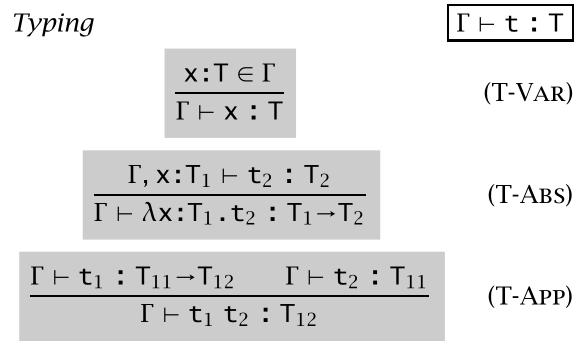
其中 T-VAR 是最基础的(归纳基底),中间的横线是指推出关系,横线上方是前提,下方是结论,规则 T-VAR 指:若上下文 Γ 中 x 的类型为 T,则可以得出结论:在上下文 Γ 中 x 的类型为 T,后面两条规则分别对应函数定义表达式的类型和函数应用(调用)表达式的类型。
我们来看一下其规则 T-APP 在 type-checking 里的实现:
def typeof(ctx: Γ, t: Term) = t match {
...
case TApp(name, t1, t2) => {
val tyT1 = typeof(ctx, t1)
val tyT2 = typeof(ctx, t2)
tyT1 match {
case TyArrow(tyT11, tyT12) =>
if (tyT2 == tyT11) {
tyT12
} else {
error(name, "parameter type mismatch")
}
}
...
}
这个代码片段就是规则 T-APP的实现,它检查了参数的类型 tyT1 是否为函数类型 tyT11 -> tyT12,如果是的话,返回 tyT12,即函数应用的类型为返回值类型
有了 STLC,我们就可以添加基本的类型进去来扩展它,使它成为更实用的语言(可以探讨某些具体问题,而非那么的抽象),比如:Nat (自然数类型),Bool,Unit(类似 Java 的 void) 等,常见的一些语法结构也将被类型化,比如:
分号: e1;e2 等价于 (λx: Unit.e2) e1 let-in:let x = e1 in e2 等价于 (λx: T1.e2) e1
我们还可以扩展类型系统,添加积类型(T1 x T2)和 和类型(T1 + T2)(和函数一样都是复合类型),这样就可以表达 Pair,元组,Record(类似 C 语言结构体),枚举等结构。
子类型化(subtyping)
到此为止我们已经了解了一门简单类型系统的语言了,但是如果将类型比作集合的话,你会发现集合并不是孤立的,它们还可以有包含关系,即像子集和父集那样。在我们为 STLC 添加 Record 结构后,我们有时候往往只用到 Record 的某个字段,比如下面的例子:
record: {x: Nat, y: Nat} = {x=0, y=1}
(λr: {x: Nat}.r.x record)
我定义了函数 λr: {x: Nat}.r.x 它的类型为:Record 类型 {x: Nat} 到 Nat,只是单纯的返回它的 x 字段值,但是我们传入的参数为 {x=0, y=1},它的类型为 {x: Nat, y: Nat},不等于 {x: Nat},故类型检查通不过。
(注:这里的 Record 你可以看成是个 Json 对象,只不过冒号用了等号替换,而它的类型都是用每个字段的类型集合来表示,如 r = {x = 1, y = 2, z = 3} 则 r 的类型为: {x: Nat, y: Nat, z: Nat} )
所以我们需要改进类型规则,让更加具体的类型 {x: Nat, y: Nat} 成为 {x: Nat} 的子类型,更加形式化的说法是:令 S 是 T 的子类型,记:S <: T, 那么所有类型为 T 的项,替换为类型为 S 的项也是安全的 。
这也引出了子类型多态,即:我们可以通过声明为父类型,来选择性的忘记一些(子类型的)具体信息,有点里面向对象中氏替换原则的感觉哈
注: 子类型是类型间的一种关系,并不是面向对象语言中的子类(subclass)类型,子类类型和父类类型之间的 关系 是子类型
子类型的具体定义为:它是一种类型之间的自反传递关系,如下图:
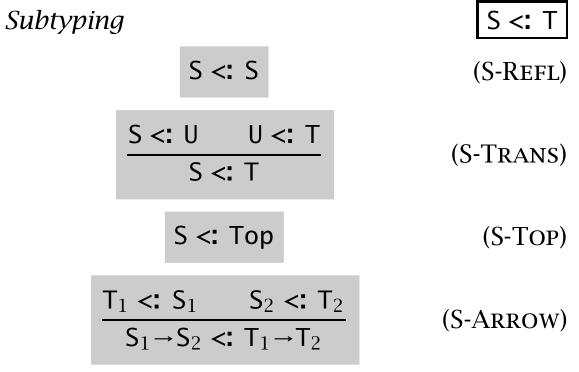
S-REFL 和 S-TRANS 规则规定了其自反和传递性,而 S-TOP 规则规定了类型的上边界,这个 Top 就类似于 Java 的 Object,是所有类型的父类型(其实还有个 Bottom 写为 ⊥ 它是所有类型的子类型,在 Java 中 null 的类型就是 Bottom 类型)
需要注意的是关于函数类型的子类型关系定义规则 S-ARROW,我们看到在参数类型 S1 和 T1 上,它们是 T1 <: S1,也就是逆变的,也就是子类型函数可以接收更广泛的内容(参数类型),而返回值必须是更具体的内容,这也是为什么 Java8 的 Function 接口方法要这么定义:
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
// Function<? super V, ? extends T> , 第一个 ? 为 S1,第二个? 为 S2, V = T1,T = T2
关于协变和逆变可以搜索‘生产消费原则’了解更多(简单的说:逆变表达的是 write-only,协变是 ready-only,more)。
有了子类型化关系之后,我们其实已经可以表达 Java 5.0 之前的类型系统了,不得不说那时的类型系统确实简单,类型由 class 和 interface 定义产生,而子类型化也只是遵照 class/interface 继承体系去推导就行了(可惜 Java 5.0 之后全变了 ╮(﹀_﹀”)╭)
我们看一下引入子类型后 type-checking 有什么变化:
def typeof(ctx: Γ, t: Term) = t match {
...
case TApp(name, t1, t2) => {
val tyT1 = typeof(ctx, t1)
val tyT2 = typeof(ctx, t2)
tyT1 match {
case TyArrow(tyT11, tyT12) =>
if (isSubtype(tyT2, tyT11)) {
tyT12
} else {
error(name, "parameter type mismatch")
}
}
...
}
仅仅将 tyT2 == tyT11 改为了 isSubtype(tyT2, tyT11) ,而 isSubtype 函数就是上面四条规则的实现而已(当然如果是 Java 的话就会复杂一些,需要检查类型的继承关系)
System F (polymorphic lambda calculus)
在编写函数时,往往会有逻辑(实现)一样,但是仅仅类型不一样的情况比如下面的 double 函数:
doubleNat = λf:Nat→Nat. λx:Nat. f (f x)
doubleRcd = λf:{l:Bool}→{l:Bool}. λx:{l:Bool}. f (f x)
doubleFun = λf:(Nat→Nat)→(Nat→Nat). λx:Nat→Nat. f (f x)
我们需要将这个不同部分的类型抽象出来,这样这些重复的函数就只有一个了,这就是参数化多态,而这样的类型系统称为 System F,System F 是对 STLC 的推广,推广后的语言称为多态 Lambda 演算,记为:λ->。
它允许我们引入类型变量(即:将类型参数化):
double = λX. λf: X -> X.λa: X.f(f a) double的类型为:∀X. (X -> X) -> X -> X doubleNat = (double [Nat])
在语法上我们将类型变量 X 直接作为参数引入,并且在调用时赋予具体类型如 Nat;在类型上,我们用全称量词 ∀ 引入类型变量 X,顾名思义指:对所有的类型 X 有 (X -> X) -> X -> X。
引入参数化多态带来了进一步的抽象能力的同时,也给类型系统带来了复杂性,因为类型需要求值了(注意:是类型层面的上的求值),如某个类型变量赋予具体的类型,那么其它用到该类型变量的类型都要替换为该具体类型;
比如上面的 (double [Nat]) 就是发生了类型层面的代换,所有 X 都换为了 Nat。
注:在逻辑视角上,多态 Lambda 演算还被称为二阶 Lambda 演算,因为它通过柯里霍华德同构于二阶直觉逻辑,这种逻辑不仅对个体(项)进行量化,还对谓词(类型)进行量化
类型推导(type-infernece)
你是否对需要写类型声明感到厌烦?明明是个字符串却偏偏要在前面加个 String,这种脱裤子放屁的感觉很不爽,所以 Java 10 终于加入了 var 关键字。
是的,类型系统是有能力推测出你要写的类型是什么的,这就是类型推导。
类型推导首先建立在基础类型的基础上,即需要有最基本类型的集合(如:Nat,Bool,String 等),并且提供这些基础类型判断的方法(如:isNat,isString),然后扩展类型上下文 Γ,这样 Γ 在一开始就不是空的。
代换 (substitution)
其次需要引入代换的概念,其实也是个 Map,将类型变量映射为具体类型,常常记为 θ,假设有两个语法项:t1 和 t2,令 S 为一个代换,记 S(t1) 为 t1 应用代换 S,如果 S(t1) = S(t2) 则称代换 S 为合一子(unifier)。
合一 (unification)
为两个项寻找一个代换(合一子),使它们在语法上等价,这样的过程称为合一,比如有两个项:
t1 = f x (g y) t2 = f (g z) w
它们有代换 S:
S = [x <- (g z), w <- (g y)]
使得 S(t1) = S(t2),这里 S 就是一个 unifier,而且代换常常不止一个,比如: T = [x <- g (f a b), y <- f b a, z <- f a b, w <- g (f b a)] 也是一个 unifier,也就是说合一的解不一定只有一种,但是 T 可以通过 S 进一步代换得到;
如果其它所有的 unifier 都可以由某个 unifier 进一步代换得到,那么该 unifier 称为: most general unifier 简称:mgu。
合一算法可以参考下图(参数c 为待合一的项对的集合):

unify 函数的参数项序对的集合,如:{(t1, t2), (t3, t4) ... (tn, tn+1)},这个集合被称之为约束集(Contraint Collection),返回类型为一个 unifier,如果约束集有 unifier 返回,则推导成功,否则失败。
具体到类型推导中,约束集就是类型变量的约束,而返回的 unifier 就是最终推导出来的类型。
约束类型的构造方式不同系统略有不同,这里不得不说一个被反复发明了很多次的类型系统 HM 类型系统(是ML系语言的类型系统,包括 Haskell),它构造约束集的方式是给所有定义的变量(函数参数,局部变量等)添加不重名的推导变量(或者叫预备类型),然后给所有表达式的子表达式添加不同的类型推导变量,根据表达式的 shape (语法结构)构造约束(如函数返回类型要等于函数体表达式求值的类型),比如:
let g = fun x -> ((+) 5) x // 这里加法用了前缀写法
这个表达式的约束集合构造过程如下:
Subexpression Preliminary type
------------------ --------------------
fun x -> ((+) 5) x R
x U
((+) 5) x S
((+) 5) T
(+) int -> (int -> int)
5 int
x V
可以得到约束集:
U = V
R = U -> S
T = V -> S
int -> (int -> int) = int -> T
然后把约束集丢给 unfiy 函数,去返回一个 gmu ,而应用 gmu (这个 gmu 对应的类型称为:主类型) 后得到 g 的类型为 int -> int。
总结一下类型推导过程:首先要有最基本的类型上下文,其次是分配推导变量(推断变量,预备类型等,各处叫法不一样),根据语法构造构建约束集,然后交给合一算法去求解。
也就是说它是 type-checking 的前置步骤,不过它们常常被何在一起,即在做类型检查的时候顺便做了类型推导(你可以理解为在一次遍历里把两件事都做了),合在一起的过程称为:type reconstruction
注:将类型推导和其他语言特性结合起来还是一件难事,尤其是和子类型结合,是件非常困难的事情(所以 Scala 没有实现全局的类型推导,你还是必须写一些类型标注),故类型推导在 System F 上应用广泛,在基于它的语言上,你是不需要写任何类型标注的。
System F<:
也有人将不同类型系统结合作为研究方向,所以将子类型和参数化多态结合后得到的类型系统就是 System F<: 或叫 System F-Sub,也就是 Bounded Quantification,即:在全称量词的类型参数上添加子类型约束,就像 Java 的 <T extends Number> ;
将原来 ∀X 扩展为 ∀X <: T,不加约束则默认等于:∀X <: Top
存在类型(Existential type)
既然全称量词 ∀ 已经出现,它们它的好基友存在量词 ∃ 还会远吗?存在类型,但却是没有存在感的类型,可以用来创建 ADT (抽象数据类型),如:Stack,Queue,Map 等。而 ADT 呢,则可以认为是 OO 语言 class 的基础(ADT 并非语言的实际特性,而是个抽象概念,但其很多特点与编程语言的特性相关联)。
与 ∀X.T 类似,存在类型可以记为:∃X.T ,但常常写成二元组的形式:{∃X, T},X是类型分量,T是值分量,它的实例 {*S, t},S 被称为隐藏表示类型,而 t 则是数据类型,听着有点抽象,看个具体的例子,比如下面的计数器:
{∃X, {init: X, get: X -> Nat,inc: X -> X}}
它的值分量为 Record,里面提供了一个数据 init,两个函数 get 和 inc,接下来为其添加实现:
counterADT = {*Nat, {init = 1, get = λi: Nat.i,inc = λi: Nat. i + 1}}
counterADT 的类型为:{∃X, {init: X, get: X -> Nat,inc: X -> X}}
然后可以通过模式匹配取出分量部分并进行计算:
let {datatype, counter} = counterADT in
counter.get(counter.inc(counter.init))
整个 counterADT 称之为 package 或 module(它包含数据类型,数据以及数据的操作),我们可以使用包里的操作返回计算结果,就像上面计算的例子,这个操作称为 package 的消去,或者我们更熟悉的 import,又或者叫 open。
有一点非常重要的注意点(敲黑板),在于类型 X,是不对外暴露的,外部也不需要知道具体 X 是什么的,它只需要调用 counter的 get,inc 和 init 函数,知道最终会返回个 Nat,也就是说类型 X 存在,但是你不知道它到底是个啥(你不用关心具体实现,只使用接口就行了);也就是说 X 是包范围可见,你需要定义 close 操作去消除这个 X,就如上面的 get 函数。
正如逻辑上(直觉逻辑)那样,存在量词可以和全称量词互相转换: (∃X.Q(X)) => P ≡ ∀X.(Q(X) => P) (有兴趣的可以看一下 Skolemization 算法);也就是说你可以将上面的 counterADT 用 Java 泛型实现:
interface Counter<X> {
X init();
Nat get(X x);
X inc(X x);
}
class CounterADT implements Counter<Nat> {...}
<X> Nat calc (Counter<X> counter) {
return counter.get(counter.inc(counter.init));
}
// 调用方得给我一个 X,比如 Nat,calc 表达的是:∀X.(Counter<X> => Nat)
// 而存在类型则是: (∃X.{init: X, get: X -> Nat,inc: X -> X}) => Nat
反之,将 ∀ 转化为 ∃ 则可以消除类型参数(type parameters)的引入。而满足转换的条件就是,存在的类型需要的条件,即:封闭(不对外暴露,如上面的 calc 方法,类型参数 X 是可以不对外暴露的,外部只在乎结果 Nat)
Java 类型系统
类型系统简史还没有说完,还有 System Fω,Dependent type 等没有说(我想你也没有兴趣了),不过没关系,因为关系 Java 类型系统的基本概念前面已经全部涵盖了(言外之意,后面这些也是 Java 所没有的),其实在本文的第一节就已经剧透了 Java 类型系统的主要特性了,唯一还没有说的就是 wildcards 了。
简单总结一下 Java 类型系统,就是 System-F<: + Existential type,有一定的类型推导能力,有非常复杂的子类型化关系( <: 和 子关系 <= 两种,具体参考 JLS 4.10 节),这里的复杂是类型的多样性带来的。
深入理解 Wildcards
虽然前面说了存在类型,但是为什么 Java 有用到存在类型呢?在哪里呢?就是 wildcards,在论文 Wild FJ 中,将 wildcards 即: T<?> ,视为存在类型的 受限形式 ,即: ∃⊥ <: X <: Object.T<X> ,与 ∃X.T<X> 的差别在于 X 有上下边界,在 Java 中 wildcards 也可以指定边界如: T<? extends Number> ,它等同于: ∃⊥ <: X <: Number.T<X> 。
前面说过泛型方法的类型参数可以转换为存在类型(即:将 ∀ 转化为 ∃),这也是为什么 Java 中常常可以用 <?> 取代类型变量 <T> 的缘故。比如上面的例子中可以将: <X> Nat calc (Counter<X> counter) 写为 Nat calc (Counter<?> counter) ,转换原则已经在上面说过了,对应官方教程的话来说就是:
When the code is using methods in the generic class that don't depend on the type parameter
捕获转换(Capture Conversion)
下面来聊聊 Java 对 wildcards 的处理,对存在类型的使用,即:open 操作,对应到 JLS (The Java® Language Specification)中,称为:捕获转换。
即:将 T<?> 转换为 T<X> 且 ⊥ <: X <: Object ,引入新的类型变量 X (我们称之为存在类型的 witness),并且伴随其边界信息;这样在泛型方法调用遇到通配符时,则可以给类型变量赋值为捕获转换后的类型变量 X,比如:
void reverse(List<?> list) { rev(list); }
<T> void rev(List<T> list) {...}
在调用 rev 方法时,list 的类型为 List<X>
我们知道存在类型的类型变量 X 是包可见的(仅对应用 open 的表达式可见),外部必须 close 掉;但是 Java 的做法要激进很多,它是对所有表达式应用 open 操作,也就是在全局的作用域内都能看到类型变量,这样就不用 close 了。
原因是在 Java 中,如果去做 close,一是不好做,二是代价太大,比如 F-bound: class PandoraBox<X extends Box<X>> ,写成 PandoraBox<?> pbox 捕获转换后: PandoraBox<Z> 且 Z <: Box<Z>
,此时这个 Z 不好 close,无法给与它一个合适的具体类型。
这是 Java 捕获转换相较于存在类型的最大区别,这么做的好处是简化了类型系统,不需要做额外的处理。
Java 的类型推导
JLS 中关于 Java 类型系统的描述是分散在各个章节中的(同理意味着类型检查也是分散的),但是关于类型推导则用了第 18 章,一整章来描述,相信在看过本文前面的内容后对 18 章的内容应该比较容易看懂了,先来看一下 Java 类型推导的几个过程:
-
归纳(Reduction)
-
合并(Incorporation)
-
解析(Resolution)
这几个过程(你可以认为是函数)是互相递归调用的,并不是按照顺序执行,比如归纳会触发合并,合并又可能导致进一步归纳,解析也可能引发进一步合并。
这几个函数的参数是约束公式(constraint formulas)和边界集(bound set):
-
约束公式:有关兼容性(compatibility)和子类型化的断言,并且可能包含推导变量
-
推导变量:正如前面讲类型推断时所说的等待合一的类型变量(区别 Java 泛型中引入的类型变量),用小写希腊字母表示
-
边界集:类似前面提到的约束集合,不同的是形式上更丰富,Java 的边界集包含:α = T,α <: T 或 T <: α,false(不存在可选的推断变量),G<α1...αn> = capture(G
) (capture(...) 表示应用捕获转换)以及 throws α 形式,其中最主要的是 α = T,α <: T 两种形式 -
兼容性:方法调用时,实参赋值给形参,需要判断兼容性,这是 Java 比较复杂的地方,因为 Java 有 8 种基本类型,会有隐转,装箱,拆箱,这也是现实与理论的差别;
<S -> T>表示类型 S 与类型 T兼容
其它关于约束公式的具体形式可以参考 JSL 第18.1.2 节
约束公式和边界集的关系:边界集是约束公式的产出(化简),约束公式经过归纳操作,可转换为边界集,边界集是最终拿去合一(JLS 里称为解析)的,可以认为边界集是约束公式的初略形式,需要进一步简化,边界集的合并操作中可能产生新的约束公式需要继续归纳。
约束公式举例:
比如对于调用 Collections.singleton("hi") 可得出约束公式: <"hi" -> α> 进一步归纳得: < String <: α> ,而 String <: α 则会被添加到边界集中。
JLS 中对归纳合并过程都描述的非常详细,这里只简单的总结一下:
-
归纳:针对不同约束公式的 shape,比如
<S -> T>,<S = T>等,去构造边界集,最终遍历完约束公式后产生一个边界集,无法化简则返回 false。 -
合并:合并是遍历归纳产生的初始边界集后,根据边界的 shape,产生新的边界集,并调用归纳获得新的边界集,与初始边界集合并。主要针对两类边界的 shape 会产生新的边界集,分别是:互补边界树和涉及捕获转换的边界,即 G<α1...αn> = capture(G
) 这样的边界出现时,尤其是在 A1...An 中出现 wildcards 时。 -
互补边界对:比如 α = S,α = T 可推导出:
<S = T>;如 α = S,α <: T 可推导出<S <: T> -
涉及捕获转换:边界如 G<α1...αn> = capture(G
) ,会根据 Ai 的形式,推导 αi 的边界,如:Ai 为 ? super T,则 R <: αi 可推导出:<R <: T>
解析:即合一过程,给定不包含 false 的边界集 C,C 中包含推断变量的子集 C‘ 可以被解析,指全部推断变量都有对应的实例化版本。
解析的推断变量,有一定的依赖顺序,比如 α <: T,T 包含推断变量 β,则 α 依赖 β,所以解析的每一个子过程都是:选择要实例化的边界集(一组推断变量的边界集),加上至少一个(需要解析的)推断变量依赖的推断变量的边界集,这样的并集去解析。
解析的主要过程就是对边界的处理,对形如 α <: T1,α <: T2 的边界,会选择最低上边界(lub),而对于多个下边界则选择最大下边界 (glb),最后 α = T1(作为 α 的实例化/代换) 会与当前边界集合并;而对于包含捕获转换而来的边界, G<α1...αn> = capture(G
应用
下面分析两个需要用到类型推导的主要场景:Invocation Applicability Inference 和 Invocation Type Inference
调用可应用性推断(Invocation Applicability Inference):
调用可应用性推断比较简单,先是根据所调用的方法的类型声明(泛型参数的边界声明),产生初始边界集;然后根据实参和形参的类型产生兼容性断言即:
比如: List<Number> ln = Arrays.asList(1, 2.0); ,会先根据方法标识符找到方法:
public static <T> List<T> asList(T... a)
因为只有这个方法,接下来就会检查其可用性:
-
初始化边界集 B:{ α <: Object }
-
初始约束公式集:{ ‹ 1 → α›, ‹ 2.0 → α› }
-
归纳后产生边界集 B1:{ α <: Object , Integer <: α, Double <: α }
-
B1 与 B 合并,解析后得到:
α = Number & Comparable<? extends Number & Comparable<?>>
调用类型推断(Invocation Type Inference):
调用类型推断相对复杂些,因为它会得到更具体的类型,你可以认为它是对调用可应用性推断的扩展,会得到更多的约束公式,更具体的初始边界集,最重要的是对目标类型的处理:另 R 为函数返回类型(R 可能是参数化的类型如 G<A> ),T 为目标类型(赋值的变量类型),会产生约束:
对与上面的例子: List<Number> ln = Arrays.asList(1, 2.0); 会多出约束: ‹ List<α> → List<Number> › 从而得到约束集:{ α <: Object , Integer <: α, Double <: α, α = Number },最后解析得:α = Number
Soundness
最后以 Java 类型系统是 Unsound 的证明来结束本文。Soundness 在逻辑上是指推导系统的一致性,即:不能推导出错误的定理;对应到类型系统上,就是指类型系统的 type rules 不能推导出错误的结果,比如我不能将 Integer 的值赋值给 String 的变量,但是在 Java8 里你可以,在论文《Java and Scala’s Type Systems are Unsound》的例子中:
class Unsound {
static class Constrain<A, B extends A> {}
static class Bind<A> {
<B extends A>
A upcast(Constrain<A,B> constrain, B b) {
return b;
}
}
static <T,U> U coerce(T t) {
Constrain<U,? super T> constrain = null;
Bind<U> bind = new Bind<U>();
return bind.upcast(constrain, t);
}
public static void main(String[] args) {
String zero = Unsound.<Integer,String>coerce(0);
}
}
main 方法中,我们将 0 赋值给了 String 类型的 zero,编译没问题,因为类型检查通过了,运行时会报错。这段代码的关键在于coerce 方法中的: bind.upcast(constrain, t) ,constrain 类型是 Constrain<U,? super T> 当传参给 upcast 时,发生了通配符的捕获转换, ? 被赋予了新的类型变量 Z,并且 T <: Z,且因为 Constrain 的声明,隐含 Z <: U,在做 upcast 方法的类型检查时,我们发现约束:
B ≡ Z T <: B B <: U
因为 T <: Z <: U,故 B = Z,检查没问题。
类型系统的一致性是很重要的性质,它确保我们不能写出非良定的类型,如果类型系统是 Unsound 的,那么就像一段程序有漏洞一般,我们可以通过漏洞去做一些破坏程序行为的事情(但往往会被运行时检查拦下来)。
出现这个问题也是因为 Java 结合了参数化多态和子类型化两个子系统的缘故,即 wildcards 作为桥梁引入的捕获转换机制导致的,两个子系统本身都是一致的,但是结合的时候不能确保一定是一致的。
参考文献
-
《Types and Programming Languages》
-
The Java® Language Specification SE 8 Edition:
-
Lesson: Generics
-
Wild FJ
-
Type unification in Generic–Java
-
Type Inference for Java 5 Wildcards, F-Bounds, and Undecidability
-
Lecture 26: Type Inference and Unification
-
Functional Programming in OCaml
-
Java and Scala’s Type Systems are Unsound
-
Going wild with generics
全文完
以下文章您可能也会感兴趣:
-
零基础玩转 Serverless
-
基于 Apollo 的 配置中心 Matrix 2.0 实践总结
-
ZooKeeper 分布式锁实践(下篇)读写锁
-
ZooKeeper 分布式锁实践(上篇)排它锁
-
浅析 InnoDB 存储引擎的工作流程
-
使用 RabbitMQ 实现 RPC
-
原来你是这样的 Stream —— 浅析 Java Stream 实现原理
-
分布式锁实践之一:基于 Redis 的实现
-
数据介绍一个 MySQL 自动化运维利器 - Inception
-
JVM 揭秘: 一个 class 文件的前世今生
我们正在招聘 Java 工程师,欢迎有兴趣的同学投递简历到 rd-hr@xingren.com 。

杏仁技术站
长按左侧二维码关注我们,这里有一群热血青年期待着与您相会。
正文到此结束
- 本文标签: js sql 漏洞 json 总结 招聘 Collection bug lambda java https zookeeper IDE 实例 锁 文章 IO 一致性 存储引擎 mysql struct 安全 redis 遍历 开发 ACE ORM 模型 JVM cat 数据 解析 返回值类型 http Action rabbitmq 索引 mina 广告 开发者 程序员 参数 ask 函数式编程 分布式 配置中心 自动化 财富 UI App 二维码 推广 scala id 分布式锁 tk db 配置 时间 list entity Wildcards 希望 本质 递归 tab 励志 map 代码 Collections src queue MQ 工程师 stream 编译
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

