理解HashMap
HashMap源码分析
基于JDK7的HashMap源码分析
类的介绍
下面的类介绍是从源码的英文翻译来的
HashMap是基于哈希表实现的Map接口实现类。这个实现提供所有的map相关的操作,允许使用null的键和null的值。(HashMap与Hashtable大致是一样的,只是HashMap是不同步的,且它允许你null的键和值。);另外,HashMap内部元素排列是无序的。
假设哈希函数能将元素合理地分散在各个哈希桶中,那么HashMap的 put 、 get 等基础操作的效率会很高(时间复杂度是常数级别 O(n) )。HashMap的迭代所有元素的时间与它的实例的容量(哈希桶的数量)及大小(键值对的数量)之和成正比。因此,如果你很在意HashMap的迭代性能,就不应该初始容量设置得很高,或者把负载因子设置得很低。
一个HashMap的实例有两个参数会影响到它的性能:初始容量和负载因子。 容量 是指哈希表中桶的数量,初始容量就是哈希表创建时指定的初始大小。 负载因子 是一个度量,用来衡量当哈希表的容量满到什么程度时,哈希表就应该自动扩容。到哈希表中元素的数量超过 负载因子和当前容量的乘积 时,哈希表会重新计算哈希(rehashed)(即重建内部数据结构),哈希表桶的数量大约会变成原来的 两倍 。
一般来说,默认把负载因子值设置成0.75,在时间成本和空间成本之间是比较好的权衡。该值再高一点能减少空间开销,但会增加查找成本(表现在HashMap类的大多数操作中,包括get和put)。所以我们在设置初始化容量时,应该合理考虑预期装载的元素数量以及负载因子,从而减少rehash的操作次数。如果初始容量大于最大条目数除以加载因子(initial capacity > max entries / load factor),则不会发生重新加载操作。
如果HashMap的实例需要存储很多元素(键值对),创建HashMap时指定足够大的容量可以令它的存储效率比自动扩容高很多。
请注意如果很多的键使用的 hashCode() 方法结果都相同,那么哈希表的性能会很慢。为了改善影响,当键是 Comparable 时,HashMap会用这些键的排序来提升效率。
请注意,HashMap是不同步的。如果多条线程同时访问一个HashMap,且至少有一条线程发生了结构性改动,那么它必须在外部进行同步。(结构性改动是指任何增加或删除键值对的操作,在源码中具体体现是导致 modCount 属性改动的操作,仅仅修改一个键对应的值则不属于结构性改动)。外部同步通常通过同步一个封装了这个map的对象完成。
如果没有这样的对象,那么可以使用 Collections.synchronizedMap 把一个map转换成同步的map,这个动作最好在创建的时候完成,避免在转换前意外访问到不同步的map。
Map m = Collections.synchronizedMap(new HashMap(...));
HashMap的迭代器所有集合相关的方法都是快速失败的(fail-fast):如果创建迭代器后,除了迭代器自身的 remove 方法之外,map发生了结构性改动,迭代器会抛出 ConcurrentModificationException 。因此,面对并发的修改,迭代吗快速、干净利落地失败,而不会冒任何风险。
请注意,迭代器快速失败的特性在不同步的并发修改时,是不能作出硬性保证的。快速失败的迭代器会尽最大努力抛出 ConcurrentModificationException 。因此,编写依赖于此异常的程序以确保其正确性是错误的:迭代器的快速失败行为应该仅用于检测错误。
构造函数
HashMap的构造函数一共有四种:
- 无参构造,初始容量默认16,负载因子默认0.75
- 指定初始容量,负载因子默认0.75
- 指定初始容量和负载因子
- 通过传入的map构造
其中1、2、4都会调用第3种构造函数,第4种只是用已有的Map构造一个HashMap的便捷方法,所以这里 重点看3、4两种构造函数 的实现。
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
//......
// 空表
static final Entry<?,?>[] EMPTY_TABLE = {};
// 哈希表
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
// 容器扩容阈值,当容器大小(size)达到此值时,容器就会扩容。
// size = 容量 * 负载因子
// 如果table == EMPTY_TABLE,那么就会用这个值作为初始容量,创建新的哈希表
int threshold;
// 负载因子
final float loadFactor;
// 构造函数3:指定初始容量和负载因子
public HashMap(int initialCapacity, float loadFactor) {
// 检查参数
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
// 设置负载因子
this.loadFactor = loadFactor;
// 默认的阈值等于初始化容量
threshold = initialCapacity;
init();
}
// 构造函数4:用传入的map构造一个新的HashMap
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) ( m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
// 分配哈希表空间
inflateTable(threshold);
putAllForCreate(m);
}
//......
}
上面的源码中,需要注意几点:
- 扩容阈值默认等于初始容量,16。
当哈希表为空表时,HashMap会在内部以该阈值作为初始容量建哈希表,哈希表实质是一个数组 -
inflateTable方法就是建立哈希表,分配表内存空间的操作(inflate翻译为“膨胀”的意思,后面会详述)。但是指定初始容量和负载因子的构造方法并没有马上调用inflateTable。查找源码中全部调用inflateTable的地方有:
graph LR HashMap构造函数-Map为参数 --> inflateTable put --> inflateTable putAll --> inflateTable clone --> inflateTable readObject --> inflateTable
初步看上去,只有参数列表是Map的构造函数调用了 inflateTable ,但 HashMap(Map map) 构造函数内部的逻辑是先调用一下 HashMap(int initialCapacity, float loadFactor) 构造函数初始化完了容量和负载因子后,再调用 inflateTable 的。所以 小结一点:HashMap在初始化阶段不会马上创建哈希表 。
调用逻辑
为了更好理解代码的调用,下图列出一些方法之间的调用关系:
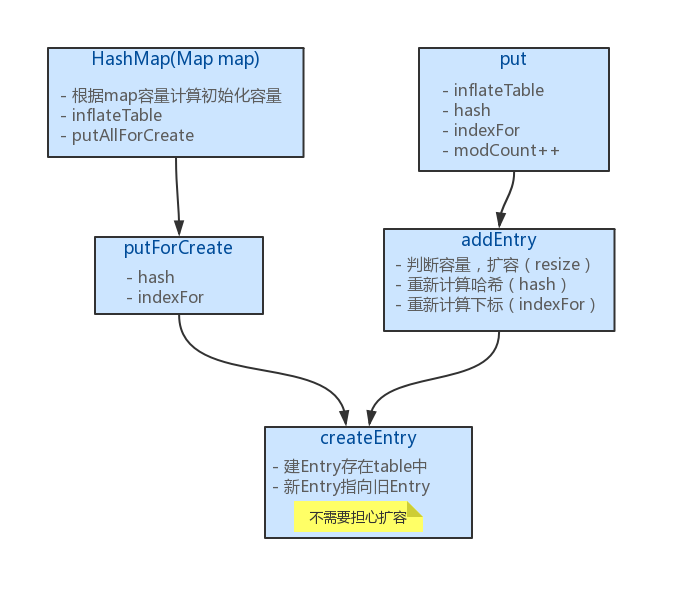
内部数据结构
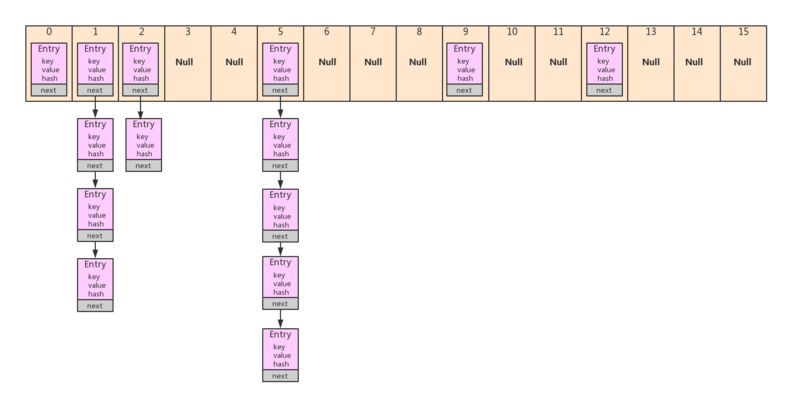
HashMap内部维护的数据结构是 数组+链表 ,每个键值对都存储在HashMap的静态内部类 Entry 中,结构如下图:
put的实现
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
// 如果容器大小大于等于阈值,且目标桶的entry不等于null
if ((size >= threshold) && (null != table[bucketIndex])) {
// 容器扩容: 哈希表原长度 * 2
resize(2 * table.length);
// 重新计算键的哈希值
hash = (null != key) ? hash(key) : 0;
// 重新计算哈希值对应存储的哈希表的位置
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
- 在put方法内部,会先判断哈希表是不是空表,如果是空表就建立哈希表(上面提到的内部数据结构中的
数组),建好表后,就有空间可以存放键值对了。 - 要存放键值对,需要先根据key计算哈希码(hash),哈希码返回是一个int类型的数值,再根据哈希码计算出在固定长度的数组中存放的位置(下标)
- 得到下标后,就要在哈希表中找到存储的位置。HashMap会先加载指定下标中存放的
Entry对象,如果Entry不为空,就比较该Entry的hash和key(比较key的时候,用==和equals来比较)。如果跟put进来的hash、key匹配,就覆盖该Entry上的value,然后直接返回旧的value;否则,就找该Entry指向的下一个Entry,直到最后一个Entry为止。 - 如果HashMap加载指定下标中存放的
Entry对象是null,又或者是找完整条Entry链表都没有匹配的hash和key。那么就调用addEntry新增一个Entry -
addEntry方法中会做一些前置处理。HashMap会判断容器当前存放的键值对数量是否达到了设定的扩容阈值,如果达到了就扩容2倍。扩容后重新计算哈希码,并根据新哈希码和新数组长度重新计算存储位置。做好潜质处理后,就调用createEntry新增一个Entry。 - 由于上面已经做了前置的处理,
createEntry方法就不用担心扩容的问题,放心存Entry即可。该方法会在给定的下标为止存放put进来的key,value,当然这个key,value是包装在Entry中的,让后将Entry指向旧的Entry。
建哈希表的逻辑(inflateTable)
建哈希表是在 inflateTable 方法中实现的:
/**
* 将一个数换算成2的n次幂
* @param number
* @return
*/
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
// 理解 Integer.highestOneBit((number - 1) << 1)
// 比如 number = 23,23 - 1 = 22,二进制是:10110
// 22 左移一位(右边补1个0),结果是:101100
// Integer.highestOneBit() 函数的作用是取左边最高一位,其余位取0,
// 即:101100 -> 100000,换成十进制就是 32
}
/**
* inflate有“膨胀”、“充气”的意思。
* 理解为初始化哈希表,分配哈希表内存空间
*/
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
// 找出大于等于toSize的2的n次幂,作为哈希表的容量
int capacity = roundUpToPowerOf2(toSize);
// 计算新的扩容阈值: 容量 * 负载因子
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
// 指定容量建哈希表
table = new Entry[capacity];
// 根据容量判断是否需要初始化hashSeed
initHashSeedAsNeeded(capacity);
}
理解一下roundUpToPowerOf2方法:
roundUpToPowerOf2部分计算结果:
roundUpToPowerOf2(0) = 1
roundUpToPowerOf2(1) = 1
roundUpToPowerOf2(2) = 2
roundUpToPowerOf2(3) = 4
roundUpToPowerOf2(4) = 4
roundUpToPowerOf2(5) = 8
roundUpToPowerOf2(6) = 8
roundUpToPowerOf2(7) = 8
roundUpToPowerOf2(8) = 8
roundUpToPowerOf2(9) = 16
roundUpToPowerOf2(10) = 16
roundUpToPowerOf2(11) = 16
roundUpToPowerOf2(12) = 16
roundUpToPowerOf2(13) = 16
roundUpToPowerOf2(14) = 16
roundUpToPowerOf2(15) = 16
roundUpToPowerOf2(16) = 16
roundUpToPowerOf2(17) = 32
roundUpToPowerOf2(6)计算示例:
计算公式:Integer.highestOneBit((5 - 1) << 1)
计算5<<1:
00000101
<<1
-------------
00001010
1010的十进制是10,然后计算Integer.highestOneBit(10),
该函数的作用是取传入数值的最高位然后其余低位取0,
所以Integer.highestOneBit(10)应该等于二进制的1000,即8
值得注意的是, inflateTable 中最后还调用了一个 initHashSeedAsNeeded(capacity) 方法,该方法是用来依据容量决定是否需要初始化 hashSeed , hashSeed 默认是0,如果初始化 hashSeed ,它的值将会是一个随机值。
Alternative hashing与hashSeed
在源码中有一个常量 ALTERNATIVE_HASHING_THRESHOLD_DEFAULT ,它的注释提供了一些值得注意的信息:
/**
* The default threshold of map capacity above which alternative hashing is
* used for String keys. Alternative hashing reduces the incidence of
* collisions due to weak hash code calculation for String keys.
* <p/>
* This value may be overridden by defining the system property
* {@code jdk.map.althashing.threshold}. A property value of {@code 1}
* forces alternative hashing to be used at all times whereas
* {@code -1} value ensures that alternative hashing is never used.
*/
static final int ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE;
大意是说, ALTERNATIVE_HASHING_THRESHOLD_DEFAULT 是一个默认的阈值,当一个键值对的键是String类型时,且map的容量达到了这个阈值,就启用备用哈希(alternative hashing)。备用哈希可以减少String类型的key计算哈希码(更容易)发生哈希碰撞的发生率。该值可以通过定义系统属性 jdk.map.althashing.threshold 来指定。如果该值是1,表示强制总是使用备用哈希;如果是-1则表示禁用。
HashMap有一个静态内部类 Holder ,它的作用是在虚拟机启动后根据 jdk.map.althashing.threshold 和 ALTERNATIVE_HASHING_THRESHOLD_DEFAULT 初始化 ALTERNATIVE_HASHING_THRESHOLD ,相关代码如下:
/**
* Holder维护着一些只有在虚拟机启动后才能初始化的值
*/
private static class Holder {
/**
* 触发启用备用哈希的哈希表容量阈值
*/
static final int ALTERNATIVE_HASHING_THRESHOLD;
static {
// 读取JVM参数 -Djdk.map.althashing.threshold
String altThreshold = java.security.AccessController.doPrivileged(
new sun.security.action.GetPropertyAction(
"jdk.map.althashing.threshold"));
int threshold;
try {
// 如果该参数没有值,采用默认值
threshold = (null != altThreshold)
? Integer.parseInt(altThreshold)
: ALTERNATIVE_HASHING_THRESHOLD_DEFAULT;
// 如果参数值为-1,禁用备用哈希
// ALTERNATIVE_HASHING_THRESHOLD_DEFAULT也是等于Integer.MAX_VALUE
// 所以jdk默认是禁用备用哈希的
if (threshold == -1) {
threshold = Integer.MAX_VALUE;
}
// 参数为其它负数,则视为非法参数
if (threshold < 0) {
throw new IllegalArgumentException("value must be positive integer.");
}
} catch(IllegalArgumentException failed) {
throw new Error("Illegal value for 'jdk.map.althashing.threshold'", failed);
}
ALTERNATIVE_HASHING_THRESHOLD = threshold;
}
}
之前提到过, inflateTable 中最后还调用了一个 initHashSeedAsNeeded(capacity) 方法,该方法是用来依据容量决定是否需要初始化 hashSeed , hashSeed 默认是0,如果初始化 hashSeed 。所以下面来看看这个方法:
/**
* A randomizing value associated with this instance that is applied to
* hash code of keys to make hash collisions harder to find. If 0 then
* alternative hashing is disabled.
*/
transient int hashSeed = 0;
/**
* 按需初始化哈希种子
*/
final boolean initHashSeedAsNeeded(int capacity) {
// 如果hashSeed != 0,表示当前正在使用备用哈希
boolean currentAltHashing = hashSeed != 0;
// 如果vm启动了且map的容量大于阈值,使用备用哈希
boolean useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
// 异或操作,如果两值同时为false,或同时为true,都算是false。
boolean switching = currentAltHashing ^ useAltHashing;
if (switching) {
// 把hashSeed设置成随机值
hashSeed = useAltHashing
? sun.misc.Hashing.randomHashSeed(this)
: 0;
}
return switching;
}
从 hashSeed 变量的注释可以看出,哈希种子一个随机值,在计算key的哈希码时会用到这个种子,目的是为了进一步减少哈希碰撞。如果 hashSeed=0 表示禁用备用哈希。
而 Holder 中维护的 ALTERNATIVE_HASHING_THRESHOLD 是触发启用备用哈希的阈值,该值表示,如果容器的 容量 (注意是容量,不是实际大小) 达到了该值,容器应该启用备用哈希。
Holder 会尝试读取JVM启动时传入的参数 -Djdk.map.althashing.threshold 并赋值给 ALTERNATIVE_HASHING_THRESHOLD 。它的值有如下含义:
- ALTERNATIVE_HASHING_THRESHOLD = 1,总是使用备用哈希
- ALTERNATIVE_HASHING_THRESHOLD = -1,禁用备用哈希
在 initHashSeedAsNeeded(int capacity) 方法中,会判断如果容器的 容量>=ALTERNATIVE_HASHING_THRESHOLD ,就会生成一个随机的哈希种子 hashSeed ,该种子会在 put 方法调用过程中的 hash 方法中使用到:
/**
* 获取key的哈希码,并应用一个补充的哈希函数,构成最终的哈希码。
* This is critical because HashMap uses power-of-two length hash tables, that
* otherwise encounter collisions for hashCodes that do not differ
* in lower bits. Note: Null keys always map to hash 0, thus index 0.
*/
final int hash(Object k) {
// 如果哈希种子是随机值,使用备用哈希
// (方法调用链:inflateTable()-->initHashSeedAsNeeded()-->hash(),
// 在initHashSeedAsNeeded()中已判断了是否需要初始化哈希种子)
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
计算存储下标(indexFor)
/**
* 根据哈希码计算返回哈希表的下标
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
这段代码和简单,却有几个有意思的地方。
为什么容量要设计成2的n次幂
注意, 容量 实质就是内部 数组的length ,还要注意是 2的n次幂 ,不是 2的倍数 。先看下面的测试代码:
public class Main {
static final int hash(Object k) {
int hashSeed = 0;
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
public static void main(String[] args) {
String key = "14587";
int h = hash(key);
int capacity = 16;
for (int i = 0; i < 10; i++) {
System.out.println(String.format("哈希码: %d, 容量: %d, 下标: %d",
h, // 同一个哈希码
(capacity<<i), // 不同的容量
indexFor(h,capacity<<i))); //计算出来的下标
}
}
// key: hello
// 哈希码: 96207088, 容量: 16, 下标: 0
// 哈希码: 96207088, 容量: 32, 下标: 16
// 哈希码: 96207088, 容量: 64, 下标: 48
// 哈希码: 96207088, 容量: 128, 下标: 112
// 哈希码: 96207088, 容量: 256, 下标: 240
// 哈希码: 96207088, 容量: 512, 下标: 240
// 哈希码: 96207088, 容量: 1024, 下标: 240
// 哈希码: 96207088, 容量: 2048, 下标: 240
// 哈希码: 96207088, 容量: 4096, 下标: 240
// 哈希码: 96207088, 容量: 8192, 下标: 240
// key: 4
// 哈希码: 55, 容量: 16, 下标: 7
// 哈希码: 55, 容量: 32, 下标: 23
// 哈希码: 55, 容量: 64, 下标: 55
// 哈希码: 55, 容量: 128, 下标: 55
// 哈希码: 55, 容量: 256, 下标: 55
// 哈希码: 55, 容量: 512, 下标: 55
// 哈希码: 55, 容量: 1024, 下标: 55
// 哈希码: 55, 容量: 2048, 下标: 55
// 哈希码: 55, 容量: 4096, 下标: 55
// 哈希码: 55, 容量: 8192, 下标: 55
// key: 14587
// 哈希码: 48489485, 容量: 16, 下标: 13
// 哈希码: 48489485, 容量: 32, 下标: 13
// 哈希码: 48489485, 容量: 64, 下标: 13
// 哈希码: 48489485, 容量: 128, 下标: 13
// 哈希码: 48489485, 容量: 256, 下标: 13
// 哈希码: 48489485, 容量: 512, 下标: 13
// 哈希码: 48489485, 容量: 1024, 下标: 13
// 哈希码: 48489485, 容量: 2048, 下标: 1037
// 哈希码: 48489485, 容量: 4096, 下标: 1037
// 哈希码: 48489485, 容量: 8192, 下标: 1037
}
上面的 hash 、 indexFor 都是从HashMap源码中拷过来的, hashSeed=0 也是HashMap默认的值, main 方法中按key计算哈希码再按哈希码和数组长度计算下标也是 put 方法中的执行逻辑。从测试结果可以看出, 相同的哈希码,在多次扩容时,使用indexFor的算法,下标变动较少 ,这样能减少扩容引起的移动 Entry 的操作次数。
可以看看key为4,容量为16、32、64......时indexFor计算下标的过程。
字符串“4”的哈希码是:55(二进制110111) 当length = 16时: h & (length-1) = 55 & (16-1) = 110111 & 1111 当length = 32时: h & (32-1) = 55 & (16-1) = 110111 & 11111 当length = 64时: h & (length-1) = 55 & (64-1) = 110111 & 111111
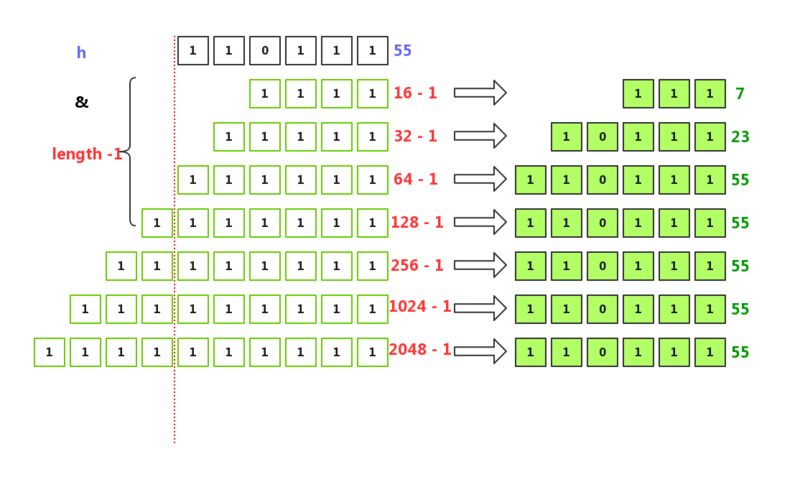
由于容量每次扩容都会翻倍(容量 x 2),翻到特定次数后(红色虚线往左),跟 h 做与运算的位肯定是全部都是1,所以算出来的下标都会是一样的。这样子,虽然扩容会引起下标变动,但相对稳定。
试想想,如果容量是17、33、65.....那么 lenght-1 的二进制除了高位(最左一位)是1,其余是0, 不同hash 和 length-1 做与运算算出来的下标就更容易有重复的下标。使 lenght-1 的全部位为1,能使计算出来的下标分布更均匀,减少哈希碰撞。
小结一下,容量设计成2的n次幂是为了:
- 在put方法中,有调用indexFor计算下标,容量设计成2的n次幂能使下标相对均匀,减少哈希碰撞
- 在扩容相关的transfer方法中,也有调用indexFor重新计算下标。容量设计成2的n次幂能使扩容时重新计算的下标相对稳定,减少移动元素
扩容与线程安全问题
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
// 缓存就哈希表数据
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 用扩容容量创建一个新的哈希表
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**
* 把所有条目从当前哈希表转移到新哈希表
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
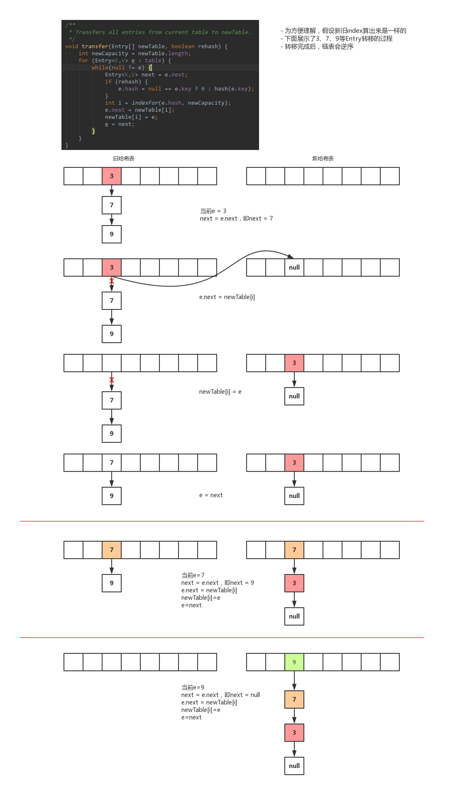
从上图显示的转移过程可以看出,链表在转移后会逆序。3-->7-->9 变成 9-->7-->3。在单线程环境下,是不会出现闭合的回路的。
但是在多线程环境下,有可能多条线程都调用 transfer ,而 transfer 方法中访问了一个全局变量 table ,并修改下标中指向的Entry。由于转移过程会导致 链表逆序 ,就有可能出现闭环的引用:3-->7-->9-->3,然后,在调用 get 方法的时候,就出现死循环。
正文到此结束
- 本文标签: Collection 安全 zab 空间 value Property https equals IDE parse 翻译 src IO cat 缓存 注释 key Security ip HashTable 数据 App java 同步 ORM 线程 synchronized 时间 Collections 1111 tab HashMap UI rand CTO final constant find 构造方法 代码 实例 源码 删除 id map 并发 CEO 参数 Action JVM 多线程 DOM 测试 http
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

