Guava -- Bloom Filter原理
去重在软件开发中经常需要用到,在Java当中一般使用Set集合,面对大量数据则可以利用取MD5签名等值后再进行去重,然而Set集合的实现原理决定了如果有大量的key需要判断,必然会需要大量的内存来支撑,且随着数据量增大效率也变得不那么尽人意。另外业务中存在着很多对精确性不需要那么高的场景,此时使用Set集合则是一种资源浪费,因此就可以利用 布隆过滤器 等算法手段进行去重。
业务场景
笔者实习面试的时候,面试官问了个关于怎么判断爬虫URL是否已经爬过的问题,笔者先回答了使用Set集合,然后升级为内存很小,数据量很大怎么办?笔者想了想往数据库插,取签名值后,可以分库分表,利用数据库唯一键来约束。面试官没再追问。。。后来见识到了 布隆过滤器 ,才想起来面试官真正的用意。
布隆过滤器的原理
布隆过滤器原理很简单,用一个很大的bit位数组与多个无偏hash函数(即计算出来的hash值呈均匀分布),当存入一个元素时,使用每一个hash函数进行hash,再与bit数组取模,得出的位置置为1。判断一个元素是否存在时,同样也是利用这样的方法判断对应的数组位是不是否为1。
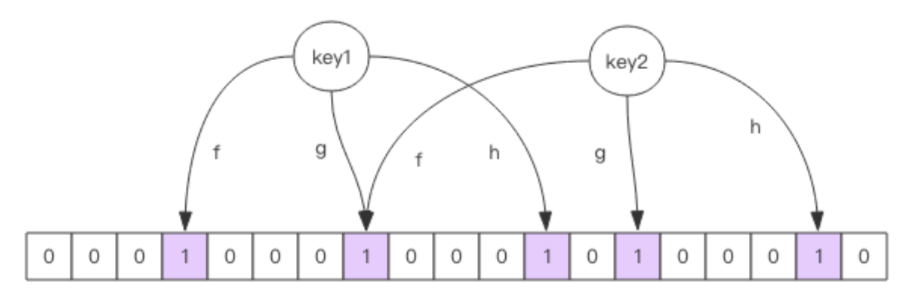
从原理上可以得出布隆过滤器的特性:
- 存在不一定真的存在:存在则可能对应的数组位与其他key产生了碰撞。
- 不存在则一定不存在:不存在则 一定 不存在,那么这个特性则可以很好的实现去重。
那么问题又来了,布隆过滤器既然有一定误判率,怎么使这个误判率降低?
具体有相关公式,不过一般使用直接计算工具,比如 bloom-calculator ,100w的数据判断,万分之一的误判率才需要2M内存,优势巨大。

常见实现方案
guava
在Guava中提供了 com.google.common.hash.BloomFilter 类,如下所示,可以很方便的实现布隆过滤器。其实现原理中有很多值得学习的点。
@Test
public void test() {
// 100w bit长度 ,0.01%误判率
// bf对象则会生成 299534 个long数组,使用13次hash计算.
BloomFilter<String> bf = BloomFilter
.create(Funnels.stringFunnel(Charset.defaultCharset()), 100 * 10000, 0.0001d);
System.out.println(bf.test("quding")); // false
bf.put("quding"); // bitCount=13
System.out.println(bf.test("quding")); // true
bf.put("quding1"); // bitCount=26
}
如何表示超长的bit数组?
在Java中提供的基本类型最小的位Byte,占8bits,最大的为Long,占64bits,因此常见方案是使用Long数组作为bits数组使用,举个例子 128bits可以用long[2]标识,146bits可以用long[3]表示,在Guava中对应的实现为 com.google.common.hash.BloomFilterStrategies.LockFreeBitArray 。
清单1:
static final class LockFreeBitArray {
private static final int LONG_ADDRESSABLE_BITS = 6;
// long数组,表示超长bit位,使用Atomic提供原子操作能力,保证线程安全
final AtomicLongArray data;
// 当前数组中为1的bit位数量,其实现可以看错JDK8中的LongAdder
private final LongAddable bitCount;
LockFreeBitArray(long bits) {
// 初始化时传入bit位,然后按照64位进行拆分计算,比如传入146bits,则会拆分位long[3]数组
this(new long[Ints.checkedCast(LongMath.divide(bits, 64, RoundingMode.CEILING))]);
}
}
那么可以想象更新bits位的操作需要先定位到long数组的下标,然后使用将对应bits位置为1,具体做法如清单2所示。
清单2: bit位更新操作
boolean set(long bitIndex) {
if (get(bitIndex)) {
return false;
}
// 定位到long数组对应的下标
int longIndex = (int) (bitIndex >>> LONG_ADDRESSABLE_BITS);
// 左移,将对应位置的bit位置为1,其他全是0
long mask = 1L << bitIndex; // only cares about low 6 bits of bitIndex
long oldValue;
long newValue;
do {
oldValue = data.get(longIndex);
// 或操作将对应bit位变成1
newValue = oldValue | mask;
if (oldValue == newValue) {
return false;
}
// CAS保证原子性
} while (!data.compareAndSet(longIndex, oldValue, newValue));
// We turned the bit on, so increment bitCount.
bitCount.increment();
return true;
}
扩展一下,这种拆分思想的应用很多,DB上有分库分表,应用上有各种锁拆分,比如 ConcurrentHashMap , LongAdder ,那么业务上可以怎么利用呢?想到一种在业务中一个账户的金额如果频繁变动,那么就需要对这个账户不停的做更新操作,到DB那一层则是高并发,那么此时将一个账户拆分为多个呢?比如收入是一个账户,支出是另一个账户,或者按照币种维护,按照业务维度等方法,那么就将一个账户的锁拆分为账户的锁,有效的降低了高并发带来的锁竞争问题。当然一致性上还需要应用层使用事务等机制来解决。
如何多次hash计算?
如上图计算,100w元素,0.0001误判率下需要13次hash计算,hash在快次数一多也必然会成为性能瓶颈,在Guava中并没有引入多个Hash函数,而是计算出一个hash值后,其他的使用位移,乘除等方法快速计算出来,其实本身是均匀分布的随机值,也没必要使用多个hash函数。
清单3: hash计算
MURMUR128_MITZ_32() {
@Override
public <T> boolean put(
T object, Funnel<? super T> funnel, int numHashFunctions, LockFreeBitArray bits) {
long bitSize = bits.bitSize();
// 计算出一个hash值
long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong();
// 取低32位
int hash1 = (int) hash64;
// 取高32位
int hash2 = (int) (hash64 >>> 32);
boolean bitsChanged = false;
// 根据hash次数分别计算出hash值,然后设置到bits数组中
for (int i = 1; i <= numHashFunctions; i++) {
int combinedHash = hash1 + (i * hash2);
// Flip all the bits if it's negative (guaranteed positive number)
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
// 填充bits位
bitsChanged |= bits.set(combinedHash % bitSize);
}
return bitsChanged;
}
}
另外 com.google.common.hash.BloomFilterStrategies 也是枚举策略模式的典型应用场景,值得学习,关于策略模式可以参考
Redis
Guava只能本地使用,面对分布式场景时则可以选择一些缓存类组件实现,在Redis4.0版本之后,提供了module支持了布隆过滤器 RedisBloom ,主要命令如下所示,具体实现原理不是很了解了,在此也不多讨论。
清单1: redis bloom filter命令
BF.RESERVE {key} {error_rate} {size} 初始化一个布隆过滤器
BF.ADD {key} {item} 添加单个元素
BF.EXISTS {key} {item} 是否存在
bf.madd {key} {item} [item...] 添加多个元素
BF.MEXISTS {key} {item} [item...] 判断多个元素是否存在
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

