“挑三拣四”地学一学Java I/O
古人云:“读书破万卷,下笔如有神”。也就是说,只有大量的阅读,写作的时候才能风生水起——写作意味着输出(我的知识传播给他人),而读书意味着输入(从他人的知识中汲取营养)。
对于Java I/O来说,I意味着Input(输入),O意味着Output(输出)。读书写作并非易事,而创建一个好的I/O系统更是一项艰难的任务。
01、数据流之字节与字符
Java所有的I/O机制都是基于 数据流 进行的输入输出。数据流可分为两种:
1)字节流,未经加工的原始二进制数据,最小的数据单元是 字节 。
2)字符流,经过一定编码处理后符合某种格式规定的数据,最小的数据单元是 字符 ——占用两个字节。
OutputStream 和 InputStream 用来处理字节流; Writer 和 Reader 用来处理字符流; OutputStreamWriter 可以把 OutputStream 转换为 Writer , InputStreamReader 可以把 InputStream 转换为 Reader 。
Java的设计者为此设计了众多的类,见下图。
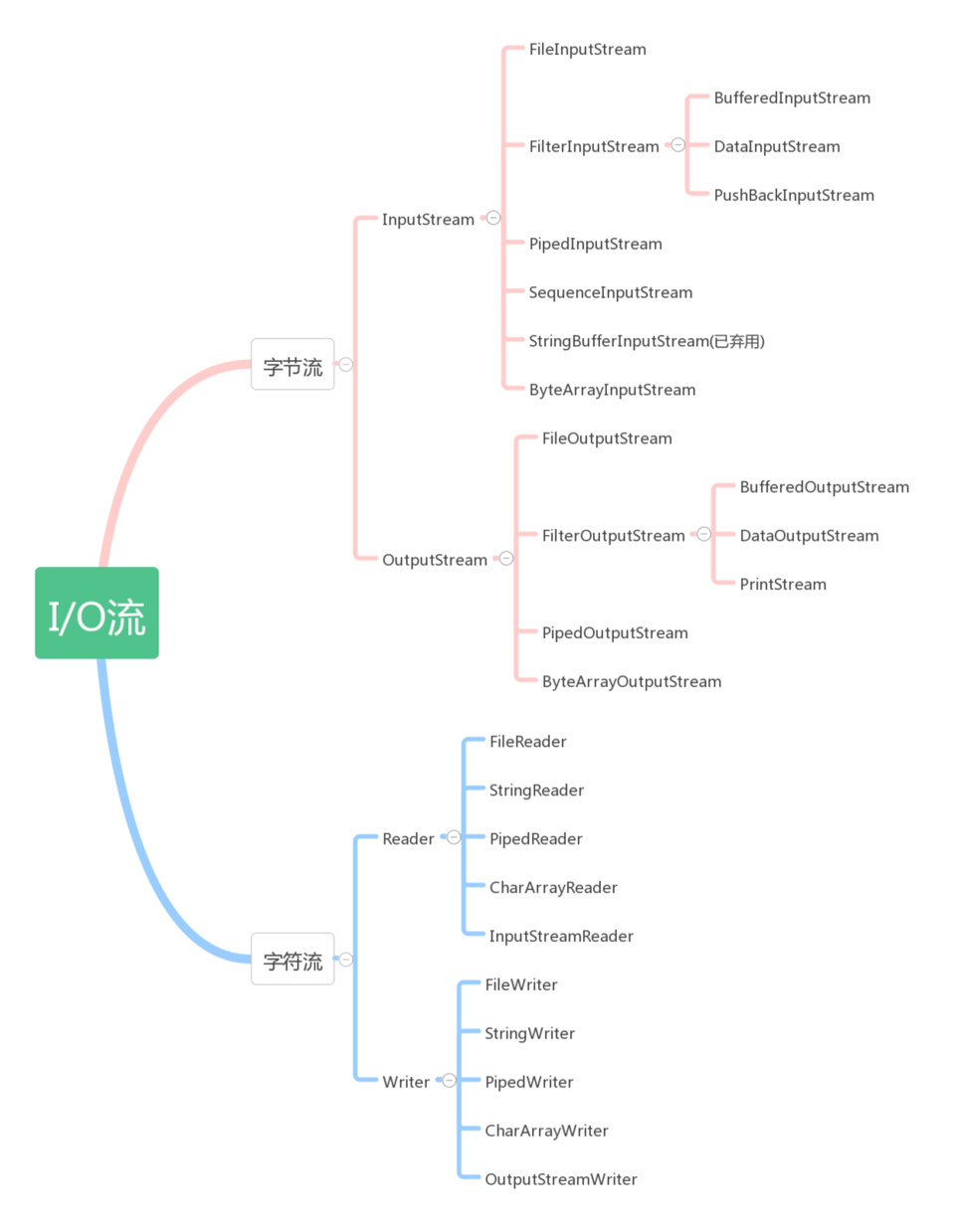
看到这么多类,你一定感觉头晕目眩。反正我已经看得不耐烦了。搞这么多类,看起来头真的大——这也从侧面说明实际的应用场景各有各的不同——你也完全不用担心,因为实际项目当中,根本就不可能全用到(我就没用过 SequenceOutputStream )。
我建议你在 学习的时候要掌握一种“挑三拣四”的能力 ——学习自己感兴趣的、必须掌握的、对能力有所提升的知识。切不可囫囵吞枣,强迫自己什么都学。什么都学,最后的结果可能是什么都不会。
字符流是基于字节流的,因此,我们先来学习一下字节流的两个最基础的类—— OutputStream 和 InputStream ,它们是必须要掌握的。
1)OutputStream
OutputStream 提供了4个非常有用的方法,如下。
public void write(byte b[]) public void write(byte b[], int off, int len) public void flush() public void close()
其子类 ByteArrayOutputStream 和 BufferedOuputStream 最为常用(File相关类放在下个小节)。
①、 ByteArrayOutputStream 通常用于在内存中创建一个字节数组缓冲区,数据被“临时”放在此缓冲区中,并不会输出到文件或者网络套接字中——就好像一个中转站,负责把输入流中的数据读入到内存缓冲区中,你可以调用它的 toByteArray() 方法来获取字节数组。
来看下例。
public static byte[] readBytes(InputStream in, long length) throws IOException {
ByteArrayOutputStream bo = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int read = 0;
while (read < length) {
int cur = in.read(buffer, 0, (int) Math.min(1024, length - read));
if (cur < 0) {
break;
}
read += cur;
bo.write(buffer, 0, cur);
}
return bo.toByteArray();
}
复制代码
ByteArrayOutputStream 的责任就是把 InputStream 中的字节流“一字不差”的读出来——这个工具方法很重要,很重要,很重要——可以解决粘包的问题。
②、 BufferedOuputStream 实现了一个缓冲输出流,可以将很多小的数据缓存为一个大块的数据,然后一次性地输出到文件或者网络套接字中——这里的“缓冲”和 ByteArrayOutputStream 的“缓冲”有着很大的不同——前者是为了下一次的一次性输出,后者就是单纯的为了缓冲,不存在输出。
来看下例。
protected void write(byte[] data) throws IOException {
out.write(intToByte(data.length));
out.write(data);
out.flush();
out.close();
}
public static byte[] intToByte(int num)
{
byte[] data = new byte[4];
for (int i = 0; i < data.length; i++)
{
data[3-i] = (byte)(num % 256);
num = num / 256;
}
return data;
}
复制代码
使用 BufferedOuputStream 的时候,一定要记得调用 flush() 方法将数据从缓冲区中全部输出。使用完毕后,调用 close() 方法关闭输出流,释放与流相关的系统资源。
2)InputStream
InputStream 也提供了4个非常有用的方法,如下。
public int read(byte b[]) public int read(byte b[], int off, int len) public int available() public int close()
其子类 BufferedInputStream (缓冲输入流)最为常用,效率最高(当我们不确定读入的是大数据还是小数据)。
无缓冲流上的每个读取请求通常会导致对操作系统的调用以读取所请求的字节数——进行系统调用的开销非常大。但缓冲输入流就不一样了,它通过对内部缓冲区执行(例如)高达8k字节的大量读取,然后针对缓冲区的大小再分配字节来减少系统调用的开销——性能会提高很多。
使用示例如下。
先来看一个辅助方法 byteToInt ,把字节转换成int。
public static int byteToInt(byte[] b) {
int num = 0;
for (int i = 0; i < b.length; i++) {
num*=256;
num+=(b[i]+256)%256;
}
return num;
}
复制代码
再来看如何从输入流中,根据指定的长度contentLength来读取数据。 readBytes() 方法在之前已经提到过。
BufferedInputStream in = new BufferedInputStream(socket.getInputStream());
byte[] tmpByte = new byte[4];
// 读取四个字节判断消息长度
in.read(tmpByte, 0, 4);
// 将byte转为int
int contentLength = byteToInt(tmpByte);
byte[] buf = null;
if (contentLength > in.available()) {
// 之前提到的方法
buf = readBytes(in, contentLength);
} else {
buf = new byte[contentLength];
in.read(buf, 0, contentLength);
// 发生粘包了
if (in.available() > 0) {
}
}
复制代码
我敢保证,只要你搞懂了字节流,字符流也就不在话下——所以,我们在此略过字符流。
02、File类
前面我们了解到,数据有两种格式:字节与字符。那么这些数据从哪里来,又存往何处呢?
一个主要的方式就是从物理磁盘上进行读取和存储,磁盘的唯一最小描述就是文件。也就是说上层应用程序只能通过文件来操作磁盘上的数据,文件也是操作系统和磁盘驱动器交互的一个最小单元。
在Java中,通常用 File 类来操作文件。当然了,File不止是文件,它也是文件夹(目录)。File类保存了文件或目录的各种元数据信息(文件名、文件长度、最后修改时间、是否可读、当前文件的路径名等等)。
通过File类以及文件输入输出流( FileInputStream 、 FileOutputStream ),可以轻松地创建、删除、复制文件或者目录。
这里,我提供给你一个实用的文件工具类——FileUtils。
package com.cmower.common.util;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.util.Enumeration;
import java.util.List;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.google.common.collect.Lists;
/**
* 文件操作工具类
* 实现文件的创建、删除、复制、压缩、解压以及目录的创建、删除、复制、压缩解压等功能
*/
public class FileUtils extends org.apache.commons.io.FileUtils {
private static Logger logger = LoggerFactory.getLogger(FileUtils.class);
/**
* 复制单个文件,如果目标文件存在,则不覆盖
* @param srcFileName 待复制的文件名
* @param descFileName 目标文件名
* @return 如果复制成功,则返回true,否则返回false
*/
public static boolean copyFile(String srcFileName, String descFileName) {
return FileUtils.copyFileCover(srcFileName, descFileName, false);
}
/**
* 复制单个文件
* @param srcFileName 待复制的文件名
* @param descFileName 目标文件名
* @param coverlay 如果目标文件已存在,是否覆盖
* @return 如果复制成功,则返回true,否则返回false
*/
public static boolean copyFileCover(String srcFileName,
String descFileName, boolean coverlay) {
File srcFile = new File(srcFileName);
// 判断源文件是否存在
if (!srcFile.exists()) {
logger.debug("复制文件失败,源文件 " + srcFileName + " 不存在!");
return false;
}
// 判断源文件是否是合法的文件
else if (!srcFile.isFile()) {
logger.debug("复制文件失败," + srcFileName + " 不是一个文件!");
return false;
}
File descFile = new File(descFileName);
// 判断目标文件是否存在
if (descFile.exists()) {
// 如果目标文件存在,并且允许覆盖
if (coverlay) {
logger.debug("目标文件已存在,准备删除!");
if (!FileUtils.delFile(descFileName)) {
logger.debug("删除目标文件 " + descFileName + " 失败!");
return false;
}
} else {
logger.debug("复制文件失败,目标文件 " + descFileName + " 已存在!");
return false;
}
} else {
if (!descFile.getParentFile().exists()) {
// 如果目标文件所在的目录不存在,则创建目录
logger.debug("目标文件所在的目录不存在,创建目录!");
// 创建目标文件所在的目录
if (!descFile.getParentFile().mkdirs()) {
logger.debug("创建目标文件所在的目录失败!");
return false;
}
}
}
// 准备复制文件
// 读取的位数
int readByte = 0;
InputStream ins = null;
OutputStream outs = null;
try {
// 打开源文件
ins = new FileInputStream(srcFile);
// 打开目标文件的输出流
outs = new FileOutputStream(descFile);
byte[] buf = new byte[1024];
// 一次读取1024个字节,当readByte为-1时表示文件已经读取完毕
while ((readByte = ins.read(buf)) != -1) {
// 将读取的字节流写入到输出流
outs.write(buf, 0, readByte);
}
logger.debug("复制单个文件 " + srcFileName + " 到" + descFileName
+ "成功!");
return true;
} catch (Exception e) {
logger.debug("复制文件失败:" + e.getMessage());
return false;
} finally {
// 关闭输入输出流,首先关闭输出流,然后再关闭输入流
if (outs != null) {
try {
outs.close();
} catch (IOException oute) {
oute.printStackTrace();
}
}
if (ins != null) {
try {
ins.close();
} catch (IOException ine) {
ine.printStackTrace();
}
}
}
}
/**
* 复制整个目录的内容,如果目标目录存在,则不覆盖
* @param srcDirName 源目录名
* @param descDirName 目标目录名
* @return 如果复制成功返回true,否则返回false
*/
public static boolean copyDirectory(String srcDirName, String descDirName) {
return FileUtils.copyDirectoryCover(srcDirName, descDirName,
false);
}
/**
* 复制整个目录的内容
* @param srcDirName 源目录名
* @param descDirName 目标目录名
* @param coverlay 如果目标目录存在,是否覆盖
* @return 如果复制成功返回true,否则返回false
*/
public static boolean copyDirectoryCover(String srcDirName,
String descDirName, boolean coverlay) {
File srcDir = new File(srcDirName);
// 判断源目录是否存在
if (!srcDir.exists()) {
logger.debug("复制目录失败,源目录 " + srcDirName + " 不存在!");
return false;
}
// 判断源目录是否是目录
else if (!srcDir.isDirectory()) {
logger.debug("复制目录失败," + srcDirName + " 不是一个目录!");
return false;
}
// 如果目标文件夹名不以文件分隔符结尾,自动添加文件分隔符
String descDirNames = descDirName;
if (!descDirNames.endsWith(File.separator)) {
descDirNames = descDirNames + File.separator;
}
File descDir = new File(descDirNames);
// 如果目标文件夹存在
if (descDir.exists()) {
if (coverlay) {
// 允许覆盖目标目录
logger.debug("目标目录已存在,准备删除!");
if (!FileUtils.delFile(descDirNames)) {
logger.debug("删除目录 " + descDirNames + " 失败!");
return false;
}
} else {
logger.debug("目标目录复制失败,目标目录 " + descDirNames + " 已存在!");
return false;
}
} else {
// 创建目标目录
logger.debug("目标目录不存在,准备创建!");
if (!descDir.mkdirs()) {
logger.debug("创建目标目录失败!");
return false;
}
}
boolean flag = true;
// 列出源目录下的所有文件名和子目录名
File[] files = srcDir.listFiles();
for (int i = 0; i < files.length; i++) {
// 如果是一个单个文件,则直接复制
if (files[i].isFile()) {
flag = FileUtils.copyFile(files[i].getAbsolutePath(),
descDirName + files[i].getName());
// 如果拷贝文件失败,则退出循环
if (!flag) {
break;
}
}
// 如果是子目录,则继续复制目录
if (files[i].isDirectory()) {
flag = FileUtils.copyDirectory(files[i]
.getAbsolutePath(), descDirName + files[i].getName());
// 如果拷贝目录失败,则退出循环
if (!flag) {
break;
}
}
}
if (!flag) {
logger.debug("复制目录 " + srcDirName + " 到 " + descDirName + " 失败!");
return false;
}
logger.debug("复制目录 " + srcDirName + " 到 " + descDirName + " 成功!");
return true;
}
/**
*
* 删除文件,可以删除单个文件或文件夹
*
* @param fileName 被删除的文件名
* @return 如果删除成功,则返回true,否是返回false
*/
public static boolean delFile(String fileName) {
File file = new File(fileName);
if (!file.exists()) {
logger.debug(fileName + " 文件不存在!");
return true;
} else {
if (file.isFile()) {
return FileUtils.deleteFile(fileName);
} else {
return FileUtils.deleteDirectory(fileName);
}
}
}
/**
*
* 删除单个文件
*
* @param fileName 被删除的文件名
* @return 如果删除成功,则返回true,否则返回false
*/
public static boolean deleteFile(String fileName) {
File file = new File(fileName);
if (file.exists() && file.isFile()) {
if (file.delete()) {
logger.debug("删除文件 " + fileName + " 成功!");
return true;
} else {
logger.debug("删除文件 " + fileName + " 失败!");
return false;
}
} else {
logger.debug(fileName + " 文件不存在!");
return true;
}
}
/**
*
* 删除目录及目录下的文件
*
* @param dirName 被删除的目录所在的文件路径
* @return 如果目录删除成功,则返回true,否则返回false
*/
public static boolean deleteDirectory(String dirName) {
String dirNames = dirName;
if (!dirNames.endsWith(File.separator)) {
dirNames = dirNames + File.separator;
}
File dirFile = new File(dirNames);
if (!dirFile.exists() || !dirFile.isDirectory()) {
logger.debug(dirNames + " 目录不存在!");
return true;
}
boolean flag = true;
// 列出全部文件及子目录
File[] files = dirFile.listFiles();
for (int i = 0; i < files.length; i++) {
// 删除子文件
if (files[i].isFile()) {
flag = FileUtils.deleteFile(files[i].getAbsolutePath());
// 如果删除文件失败,则退出循环
if (!flag) {
break;
}
}
// 删除子目录
else if (files[i].isDirectory()) {
flag = FileUtils.deleteDirectory(files[i]
.getAbsolutePath());
// 如果删除子目录失败,则退出循环
if (!flag) {
break;
}
}
}
if (!flag) {
logger.debug("删除目录失败!");
return false;
}
// 删除当前目录
if (dirFile.delete()) {
logger.debug("删除目录 " + dirName + " 成功!");
return true;
} else {
logger.debug("删除目录 " + dirName + " 失败!");
return false;
}
}
/**
* 创建单个文件
* @param descFileName 文件名,包含路径
* @return 如果创建成功,则返回true,否则返回false
*/
public static boolean createFile(String descFileName) {
File file = new File(descFileName);
if (file.exists()) {
logger.debug("文件 " + descFileName + " 已存在!");
return false;
}
if (descFileName.endsWith(File.separator)) {
logger.debug(descFileName + " 为目录,不能创建目录!");
return false;
}
if (!file.getParentFile().exists()) {
// 如果文件所在的目录不存在,则创建目录
if (!file.getParentFile().mkdirs()) {
logger.debug("创建文件所在的目录失败!");
return false;
}
}
// 创建文件
try {
if (file.createNewFile()) {
logger.debug(descFileName + " 文件创建成功!");
return true;
} else {
logger.debug(descFileName + " 文件创建失败!");
return false;
}
} catch (Exception e) {
e.printStackTrace();
logger.debug(descFileName + " 文件创建失败!");
return false;
}
}
/**
* 创建目录
* @param descDirName 目录名,包含路径
* @return 如果创建成功,则返回true,否则返回false
*/
public static boolean createDirectory(String descDirName) {
String descDirNames = descDirName;
if (!descDirNames.endsWith(File.separator)) {
descDirNames = descDirNames + File.separator;
}
File descDir = new File(descDirNames);
if (descDir.exists()) {
logger.debug("目录 " + descDirNames + " 已存在!");
return false;
}
// 创建目录
if (descDir.mkdirs()) {
logger.debug("目录 " + descDirNames + " 创建成功!");
return true;
} else {
logger.debug("目录 " + descDirNames + " 创建失败!");
return false;
}
}
/**
* 写入文件
* @param file 要写入的文件
*/
public static void writeToFile(String fileName, String content, boolean append) {
try {
FileUtils.write(new File(fileName), content, "utf-8", append);
logger.debug("文件 " + fileName + " 写入成功!");
} catch (IOException e) {
logger.debug("文件 " + fileName + " 写入失败! " + e.getMessage());
}
}
/**
* 写入文件
* @param file 要写入的文件
*/
public static void writeToFile(String fileName, String content, String encoding, boolean append) {
try {
FileUtils.write(new File(fileName), content, encoding, append);
logger.debug("文件 " + fileName + " 写入成功!");
} catch (IOException e) {
logger.debug("文件 " + fileName + " 写入失败! " + e.getMessage());
}
}
/**
* 获目录下的文件列表
* @param dir 搜索目录
* @param searchDirs 是否是搜索目录
* @return 文件列表
*/
public static List<String> findChildrenList(File dir, boolean searchDirs) {
List<String> files = Lists.newArrayList();
for (String subFiles : dir.list()) {
File file = new File(dir + "/" + subFiles);
if (((searchDirs) && (file.isDirectory())) || ((!searchDirs) && (!file.isDirectory()))) {
files.add(file.getName());
}
}
return files;
}
}
复制代码
public static boolean createFile(String descFileName) public static boolean createDirectory(String descDirName) public static boolean copyFile(String srcFileName, String descFileName) public static boolean copyDirectory(String srcDirName, String descDirName) public static boolean deleteFile(String fileName) public static boolean deleteDirectory(String dirName) public static void writeToFile(String fileName, String content, boolean append)
03、网络套接字——Socket
虽然网络套接字( Socket )并不在java.io包下,但它和输入输出流密切相关。 File 和 Socket 是两组主要的数据传输方式。
Socket 是描述计算机之间完成相互通信的一种抽象。可以把 Socket 比作为两个城市之间的交通工具,有了交通工具(高铁、汽车),就可以在城市之间来回穿梭了。交通工具有多种,每种交通工具也有相应的交通规则。 Socket 也一样,也有多种。大部分情况下,我们使用的都是基于 TCP/IP 的套接字——一种稳定的通信协议。
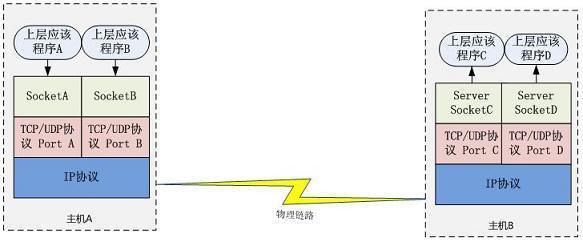
假设主机A是客户端,主机B是服务器端。客户端要与服务器端通信,客户端首先要创建一个 Socket 实例,操作系统将为这个 Socket 实例分配一个没有被使用的本地端口号,并创建一个套接字数据结构,直到这个连接关闭。
示例如下。
Socket socket = new Socket(serverIp, serverPort); BufferedInputStream in = new BufferedInputStream(socket.getInputStream()); BufferedOutputStream out = new BufferedOutputStream(socket.getOutputStream()); 复制代码
与之对应的,服务端需要创建一个 ServerSocket 实例,之后调用 accept() 方法进入阻塞状态,等待客户端的请求。当一个新的请求到来时,将为这个连接创建一个新的套接字数据结构。
示例如下。
ServerSocket server = new ServerSocket(port); Socket socket = server.accept(); InputStream in = new BufferedInputStream(socket.getInputStream()); OutputStream out = new BufferedOutputStream(socket.getOutputStream()); 复制代码
Socket 一旦打通,就可以通过 InputStream 和 OutputStream 进行数据传输了。
04、压缩
Java I/O 支持压缩格式的数据流。在 Socket 通信中,我常用 GZIPOutputStream 和 GZIPInputStream 来对数据流进行简单地压缩和解压。
压缩的好处就在于能够减小网络传输中数据的体积。代码如下。
package com.cmower.common.util;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.util.zip.GZIPInputStream;
import java.util.zip.GZIPOutputStream;
/**
* 压缩解压
*/
public class CompressionUtil {
public static byte[] compress(byte[] data) throws IOException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
byte[] result = null;
GZIPOutputStream zos = new GZIPOutputStream(bos);
zos.write(data);
zos.finish();
zos.flush();
result = bos.toByteArray();
zos.close();
bos.close();
return result;
}
public static byte[] deCompress(byte[] in) throws IOException {
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
GZIPInputStream inStream = new GZIPInputStream(new ByteArrayInputStream(in));
byte[] buf = new byte[1024];
while (true) {
try {
int size = inStream.read(buf);
if (size <= 0)
break;
outStream.write(buf, 0, size);
} catch (Exception e) {
e.printStackTrace();
break;
}
}
inStream.close();
outStream.close();
return outStream.toByteArray();
}
}
复制代码
偷偷地告诉你:作者「沉默王二」的微信ID是:qing_gee,趁他没有小号之前先加一波好友,占个坑位再说!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

