
为了30分钟配送,盒马工程师都有哪些“神操作”?
阿里妹导读:提到盒马鲜生,除了新鲜的大龙虾以外,大家印象最深的就是快速配送:门店附近3公里范围内,30分钟送货上门。
盒马是基于规模化和业务复杂度两个交织,从IT到DT,从原产地到消费者而形成的端到端的平台,而盒马配送更是集成IOT、智能化、自动化等到线下作业,同时受不可抗力因素雨雪冰雾、道路交通、小区设施等让配送系统的稳定性更加雪上加霜,如何保障线下配送作业的稳定性,让骑手快乐,更让用户开心是盒马配送永恒的话题。
三大规范
整个盒马技术部对线上/线下作业生产之关注,代码质量之高、故障处理之严,让我们工程师在反复反复地肯定自己的同时又不断地否定自己,在开发中设计重构系统,在生产之中检验系统。经过线上/线下冰与火的历练,我们淬炼出了一套稳定性的方法论,概括起来就12个字: 研发规范、架构规范、稳定性规范。
无规矩,无以成方圆
首先是研发规范,且看下图:

这个图管它叫做7层漏斗模型(努力画出漏斗,画图功夫不行,浅色的箭头表示漏斗),7层是指PRD评审、技术方案评审、TC评审、编码、测试&代码Review、灰度发布、运维。为什么是漏斗模型呢?因为我们通过这7层经过层层筛选,将阻碍线下流程的重大故障全部在这7层兜住。
PRD评审:我们有个需求池,所有的需求都先扔到这个池子里面,每两周有个运营双周会,从中筛选出优先级高、紧急程度高的需求开始进行PRD评审(倒排项目除外),所有的PRD评审都有PD组织,从项目或者需求的价值认识上达成一致,在评审的过程中研发同学从PRD中寻找名词进行领域建模和抽象。整个需求和项目需要识别到技术风险,遵循“不被别人搞死、不搞死别人”的原则,识别核心链路和非核心链路;测试同学从中识别风险点和测试功能点,为后面TC评审做好准备。
技术方案评审:PM组织研发、测试和PD总共参与,研发同学按照事先分配好的研发模块进行技术串讲,同时和PD、甚至电话业务同学共同达成产品兜底方案和业务兜底方案。人都会犯错,何况是人写出来的代码,我们要拥抱bug,但更要识别到潜在的风险进行兜底。
TC评审:一般在技术评审完成后的两天内会进行TC评审,主要功能的覆盖点、技术方案潜在的坑、非功能角度的业务降级方案、性能的QPS/RT、接口的可测性的评估、测试环境、测试数据等,最后给出可靠的上线时间。
编码:首先遵循集团的编码规则,然后就是防御性编程,业务系统可能80%的代码都在考虑异常情况下如何保证高可用。系统异常、业务异常的处理,上线时门店灰度方案(一个门店出问题,不影响整个盒马门店),缓存机制、柔性可用、重试机制、事务处理、串并行、打日志等等。
测试&代码Review:首先研发完成自测并冒烟通过,正式提测,当然在编码的过程中也会进行代码Review,那时的代码Review管它叫线上Review,通过Aone的功能提交给相关同学进行Review;整个测试结束后上线前我们会聚集到一起进行代码围观Review,这个阶段也会完成系统依赖顺序、发布顺序、回滚顺序,每个人的位置。
灰度发布:首先我们严格遵守盒马研发红线,按照发布窗口进行发布,同时为了将风险降到最低,针对不同的业务做不同的发布时间点,比如O2O场景下午2点准时发布,B2C场景晚上8点半准时点火;针对不同的门店进行灰度,发布完成后就立马通过SLS查看原始错误日志,A3查看错误统计日志,EagleEye查看QPS/RT,CloudDBA查看DB性能/慢SQL等全面盯屏30分钟以上。一般我们觉得风险比较大的,在发布时会只发2台机器,第二天观察没有任何问题再全部上线,如果有问题就直接上去Kill掉这两台机器。
运维:每次发布后第二天早起盯屏是非常关键,尤其是配送涉及不同运力商、运力类型等作业的校验方式不同,在早上运力类型丰富是最容易出问题,也最容易发现问题。一旦有问题,谁先第一个发现先问题就会立马在群里钉钉电话所有人,若是跨团队的会单独拉小群电话所有人,对于问题的定位我们设置专门的同学,有人看SLS,有人看EagleEye,有人看A3,有人看Xflush,有人看CloudDBA,有人对外发声安抚骑手,一个人统一指挥,大家分工明确,整个问题处理起来就像一个人。
不把鸡蛋放在一个篮子
盒马配送目前有50+系统,其中核心应用有20+,那么这么多系统如何既保稳定又能协作?且看下图:
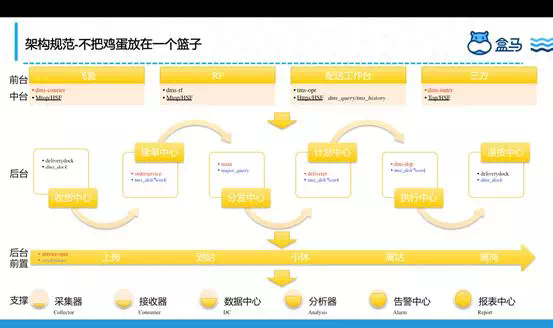
项目化:盒马配送从刚开始按照项目维度构建整个系统,能够满足盒马用户的个性化需求,这种在人少的情况下开发起来很快,也能快速的迭代。
产品化:随着业务需求越来越多,这种开发方式越来越拖慢整个项目节奏,尤其是需求的灵活多变,这个时候产品化的方式随之而来,我们在去年5月份的引入了NBF的规则中心、各种Setup,将运营逻辑和业务逻辑区别开来等各种配置化,快速支持需求的变化。
服务化:去年8月份的时候和点我达、邻趣、蜂鸟等三方进行对接,对接的过程比较痛苦,我们发现业务逻辑主要是在盒马场景下,三方的场景需要做一些定制,这个时候我们开始考虑整个线下作业不变业务规则和基于场景的业务规则,将不变业务规则下沉作为我们的后台,基于场景的业务规则放到我们的中台,形成后台解释业务概念、业务状态和业务规则,中台做统一权限校验、场景化的业务逻辑、数据网关、整个降级限流可以上浮到中台来,完成对各运力商的流控,慢慢孵化出上面的架构规范。这一过程比较痛苦,我们既要追赶业务,又把34个核心的L0服务梳理业务逻辑、接口参数的合理性、外部依赖等重新升级一遍,新老服务平滑迁移对业务无感,最后注册到NBF上,通过NBF链接起所需的各域能力去表达业务。
数字化:最底下一层是我们的用工管理平台,新零售从企业角度看有两个核心层面,其一是技术层面“人货场”的数字化;其二是零售层面的“人货场”的变革或者革命;用技术驱动零售变革,让我们真正能看到整个线下作业流程的好与坏,哪些门店好,哪些门店差,原因到底在哪里,如何去优化提供技术依据和支撑,整个数据模型如下图:
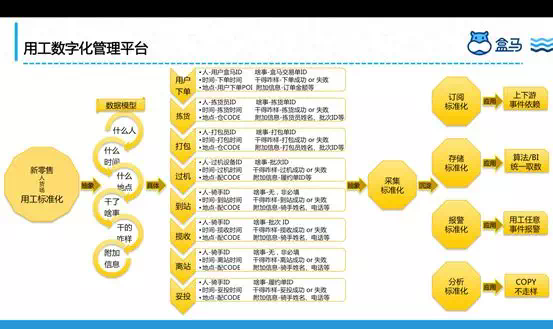
纸上得来终觉浅
任何理论、架构都要不断接受实践的检验,在错误中学习,在错误中成长,提出了一套适合线下配送的7路23招打法,如下图:
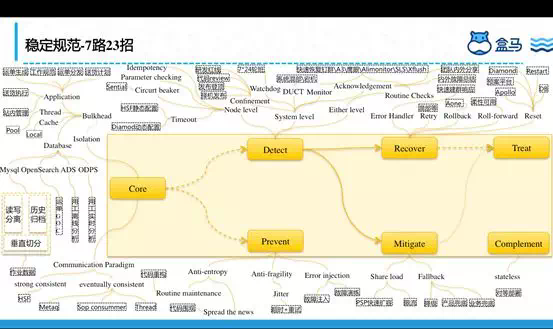
第一路:核心和非核心隔离
首先我们从应用维度进行核心和非核心隔离,核心服务和非核心服务隔离,从数据库层面我们做了核心库和非核心库隔离,读写分离、充分发挥各存储层的优势,比如核心作业场景我们采用Mysql,实时聚合分析场景我们采用ADS,非核心多维度组合查询场景我们引入OpenSearch、和离线场景的ODPS,这样既起到分流的作用,又保护了核心作业场景。如此架构升级,可以让我们的上嘉同学进来在一些非核心场景上独挡一面,充分发挥他们的潜力。
系统交互上我们采用基于Request/Response模式的HSF水平调用;另外一种基于Event-driven模式的消息垂直调用。
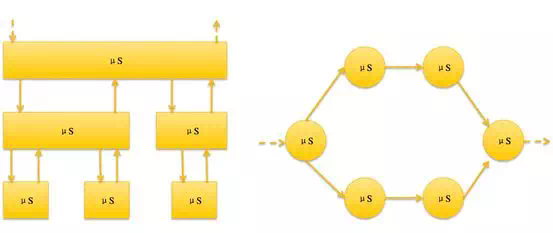
对核心服务的依赖上,我们本着不信任任何外部服务的原则,即使外部服务出问题,我们依然能够继续作业,形成如下图的调用方式:
链路开销大且网络抖动很容易引起问题,我们会将其做成一个“航母级”的服务来调用,如下调用:
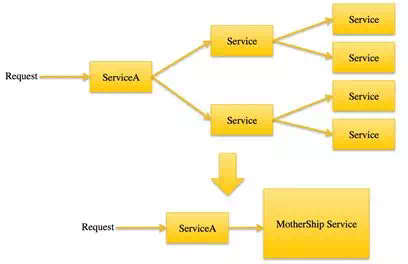
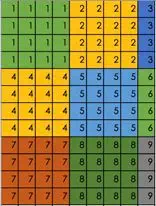
举个例子:配送人货匹配生成笛卡尔积后类似map-reduce进行分布式计算,通过鹰眼链路观察发现耗时主要在map到reduce的网络耗时,不在于计算耗时,我们将将人货匹配生成矩阵,平衡网络开销和分布式计算,最后将108次调用变为9次,性能基本提升12倍,如下矩阵:
第二路:及时发现问题是稳定的一半
服务级别-幂等、参数校验、熔断、还是静态和动态控制超时时间、重试次数来保障服务级别的高可用;
系统级别-流量调度、研发红线、代码Reivew文化、重大发布集体上光明顶、流量调度、A3/EagleEye/SLS/Xflush等的QPS/RT同比环比的服务监控还是底层的机器性能监控都能保证在第一时间发现问题。重大发布集体上光明顶是我们的一个文化,记得在双12前两周我们对整个系统架构进行了一次升级,涉及13个系统又在大促前顶着压力发布上线,最终在双12期间系统整体平稳,较双11各项指标毛刺减少,特别是双12哪几天的雨雪天气在站内批次积压严重的情况下,我们的人货追加服务较双11的QPS增加近一倍,但我们的RT却降低了50%。
其它招,比如我们在过年期间每天的专人进行核心系统的例行检查,确保系统正常运行;在稳定性知识方面,我们内外结合进行分享,同时将别的team的故障都当做自己的故障来分析原因和查找我们系统的不足。
第三路:故障预防
在系统复杂和业务需求不断导致代码腐化,我们定时对整个系统进行重构,将整个重构方案大家达成一致;在今年系统的混部环境对我们也是一个挑战,所以我们引入了超时和重试机制,特别是做到了运行期修改超时时间,防止雪崩,每一个新功能上线时都会做故障注入和故障演练,识别潜在风险。
第四路:故障缓解
我们机器留有一些buffer以防大促、线程池满等紧急扩容情况下使用,同时对高QPS有降级预案以防异常情况紧急止血。还是前面提到的业务系统一定要有产品和业务兜底方案,比如我们在和蜂鸟对接时当蜂鸟的系统如果出现问题时,我们服务端针对此种情况做了防御性编程,打开开关让蜂鸟骑手用飞鱼app进行作业,减轻对用户的影响面。在稳定上,我们不但要自己赢,也要让合作伙伴赢。
第五路:快速恢复
回滚是系统发布后出现异常最有效的止血方案,对于弱依赖我们通过柔性可用性让它跳过不阻塞继续往下走,当出现异常case时比如履约和配的状态不一致我们通过阿波罗后台进行一键修复,异常紧急订正预案、Diamond命令下发等来快速恢复。
第六路:快速补偿
我们的系统在设计的都是无状态扁平化,不存在单点,机器扩容是应对某些异常情况的快速止血方案。
第七路:发布治疗
在上述路数招数都无法快速止血的情况下只能采用发布治疗,我们有一次突然机器Load飙高,收到报警后第一反应是机器问题,但又发现部分机器的线程池也快满了,我们随即开始扩容和机器重启,一部分同学在快速扩容,一部分同学在不停的机器重启,其它同学在迅速查找问题的根本原因,最后通过DUMP发现是由于引用了一个Jar,而这个Jar包里面使用了Java的正则表达式在解析一个特殊商品名称的时候进入了死循环,找到原因后这种情况只能通过发布解决,我们迅速达成一致紧急发布解决,正是前面一部分同学的扩容和不停的重启,从而避免了一场故障。
大海航行靠舵手
盒马配送的稳定性靠的是业务方、产品、研发、测试、Web端、App端、RF端、GOC、上下游、算法、IOT、NBF、盒马安全生产、中间件、网络、气象台、雨雪冰雾、道路交通、红绿灯、小区设施、骑手装备等等各种因素,每一个组成部分都是至关重要。稳定性的探索我们还在路上,不断追求极致。
正文到此结束
- 本文标签: 定制 线程 sql 代码 开发 线程池 bug 重试机制 web 数据库 安全 可测性 参数 数据模型 做自己 幂等 java 双11 管理 组织 http 模型 限流 mysql https 功夫 数据 解析 运营 高可用 测试环境 正则表达式 质量 产品 UI App 统计 分布式 QPS 自动化 O2O 系统架构 智能 src 服务端 缓存 db 装备 配置 时间 线下 IO 灰度发布 测试 压力 map 需求 企业 钉钉 工程师 2019
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

