一次ygc越来越慢的问题排查过程 原 荐
卧颜沉默的个人空间
工作日志
正文
一次ygc越来越慢的问题排查过程
原
荐

字数 1975
阅读 2
收藏 0
Nashorn Java JDK
开发十年,就只剩下这套架构体系了! >>> 
问题发现场景
某天突然收到线上应用的gc时间过长的告警,刚开始只有一台机器偶尔报一下,后续其他机器也纷纷告警,具体告警的阈值是应用10分钟内ygc的总时长达到了6.6s。
初步排除过程
- 按照gc问题常规排查流程,还是先保留现场,jmap -dump:format=b,file=temp.dump pid。
- 查看下gc日志,发现出问题的时候的单次ygc耗时几乎有200ms以上了。正常来说单次ygc在100ms以下,基本可以认为应用是比较健康的。所以这时候已经可以确定告警的原因就是ygc比较慢。
- jvisualvm打开刚刚dump的文件看下能不能发现什么东西,看了下,也看不出什么特殊的,因为本身dump的时候会触发一次full gc,dump下来的堆里面的内容只有1G左右(jvm参数堆内存配置的是4G)如下图,也没发现什么特殊的东西
 。
。 - 然后看下ygc近期耗时的走势图,下图纵坐标每10分钟gc总耗时(单位:s),横坐标日期,可以看到在2月22号应用重启后gc总耗时降下来了,然后随着时间推移,gc变得越来越慢,并且这个变慢的过程非常缓慢,正常情况下重启一次到应用触发gc告警,需要1至2周才能出现。
 。
。
进一步排查
- 网上搜了下有没有相关案例,相关资料也非常少,然后看到 了 http://zhuanlan.51cto.com/art/201706/543485.htm 笨神的一篇文章,这篇文章简单总结起来就是使用jdk中的1.8的nashorn js引擎使用不当触发了底层JVM的一个缺陷。然后回到我这边来,发现和我这边的场景也挺类似的,应用也大量使用了nashorn 引擎来执行javascript脚本,所以我初步猜测也是nashorn引擎使用不当导致。
- 为了验证我以上的想法,找运维加了
-XX:+PrintReferenceGC参数,经过一段时间观察,应用重启后,观察了一段时间,发现gc日志中JNI Weak Reference处理时长变得越来越长。而且占用整个ygc时长的大部分。 - 再回到刚刚dump的那张图里面,能看到实例数排在前面的也有nashorn引擎相关的内容,如下图,现在几乎可以断定问题出在的执行某个javascript脚本。
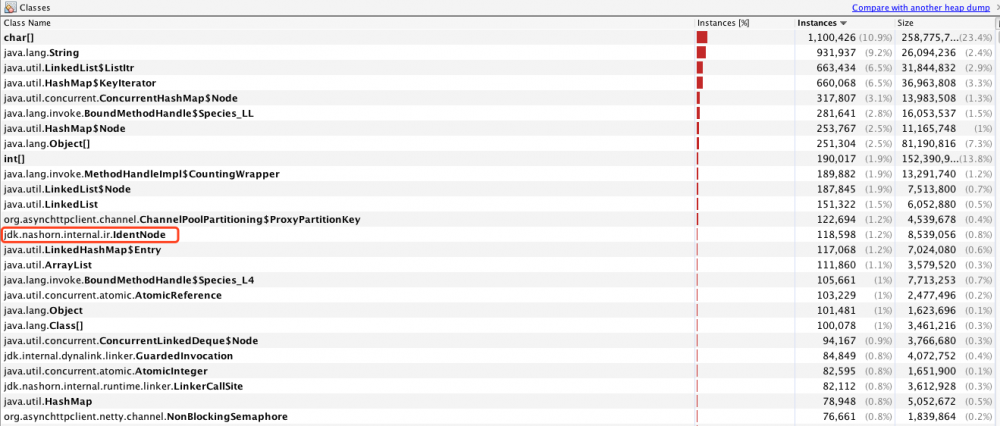
- 现在确认了出问题的大致方向。但是该应用执行的javascript脚本也有10多个,所以还没发直接定位到是哪个脚本导致的。所以接下来就是定位具体的脚本了。初步想法是直接根据上图的中的
jdk.nashorn.internal.ir.IdenNode通过引用链找到可疑的js脚本对应的String,尝试了很多次发现都失败了。主要本身对jdk.nashorn包下类不是很熟悉,再加上引用链都比较长,所以找了很久都没有找到这个类和脚本的应用关系。 - 于是换了一种思路,内存中,脚本肯定会以
String对象存在,String底层采用char[]来存储字符。所以直接找char[]实例中内容为js脚本的,但是这里又遇到一个问题,看上面的dump文件图,会发现char[]实例数当前内存有100w+,这里就抓住了部分js脚本长度比较长的一个特点。直接根据size正序排列,长度前10的字符串,就直接就找到了一个脚本,顺着引用链会轻易发现,js脚本的内容都是保存在Source$RawData对象中的,如下图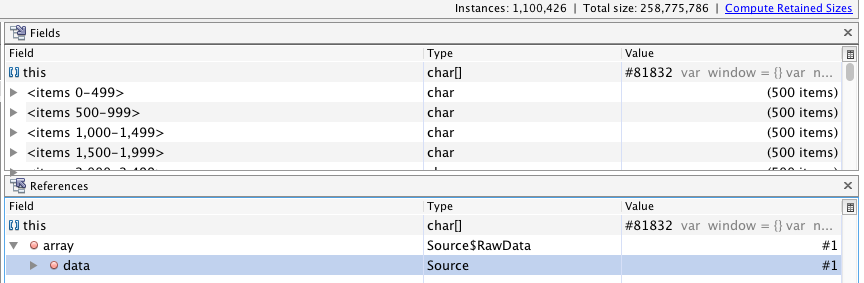
- 然后回到VisualVM的
Classes栏目,直接搜索Source$RawData,可以看到有241个实例,如下图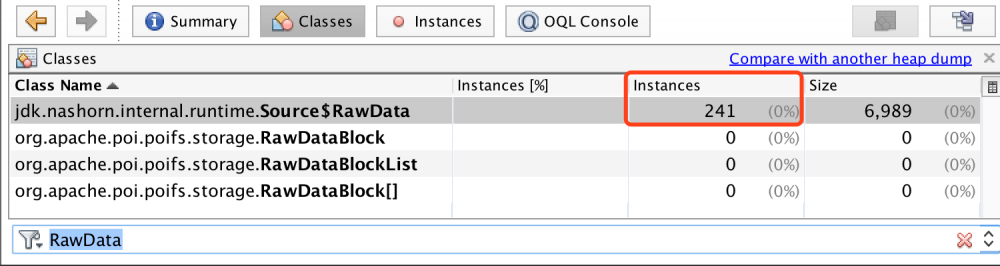 ,这241个,然后找了出现频率比较高的几个js脚本,然后看了对应脚本的调用方式,发现其中一个脚本每次执行都是通过
,这241个,然后找了出现频率比较高的几个js脚本,然后看了对应脚本的调用方式,发现其中一个脚本每次执行都是通过 ScriptEngine.eval这种方式来执行,就造成了``JNIHandleBlock```,不断增长的问题,最终导致ygc时,处理JNI Weak Reference的时间越来越长。 - 如何解决:修改了这个脚本的调用方式。不用每次执行
eval方法,换成Bindings的方式调用。 - 修改后,经过一周的观察。ygc时间以及区域稳定了,如下图

总结
- 小插曲:其实这个问题在18年10月份左右都出现了,早期也考虑彻底解决过,也探索了不少方法。比如下:
- 最开始的时候怀疑是G1 收集器的问题,直接把G1收集器改回CMS收集器,其中调整该参数的过程中也发生了一个小问题,具体如下。
- 从G1改到CMS改回来的参数设置堆空间大小相关的参数变成了
-Xms4000m -Xmx4000m -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:MaxDirectMemorySize=512m -XX:+UseCMSInitiatingOccupancyOnly -XX:SurvivorRatio=8 -XX:+ExplicitGCInvokesConcurrent -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:-OmitStackTraceInFastThrow -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/var/www/logs/gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=10m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/var/www/logs -Djava.io.tmpdir=/var/www/tmp -Dio.netty.availableProcessors=4 -XX:ParallelGCThreads=4 -Dpinpoint.applicationName=crawler-worker.product-bank这样,其中-Xms4000m是初始化堆大小,-Xmx4000m是最大堆大小,然后重启应用,重启后,就收到ygc频繁的告警,然后用jstat -gc pid 3000看了下,发现了奇怪的地方(如下图) 年轻代总容量才300多m(S0C+S1C+EC),而年老大总容量(OC)有3700多m,这种情况就直接导致了,直接分配对象空间的eden区域很容易就占满了,而直接触发ygc,而导致这个问题的原因呢,是忘记配置
年轻代总容量才300多m(S0C+S1C+EC),而年老大总容量(OC)有3700多m,这种情况就直接导致了,直接分配对象空间的eden区域很容易就占满了,而直接触发ygc,而导致这个问题的原因呢,是忘记配置 -Xmn1024m参数导致,这个参数就是制定年轻代的大小,这里的大小配置成整个堆的1/4至1/2都是合理的,加上这个参数后,刚启动应用就ygc时间过长的问题就得到了解决。
- 从G1改到CMS改回来的参数设置堆空间大小相关的参数变成了
- 后面发现也没什么效果,又怀疑是堆空间年轻代的空间设置小了。之前整个堆4000M,年轻代设置的1000M。后面把年轻代的空间调整至1200M,发现也没什么效果。在这个过程中,发现也没什么效果,再加上这个过程非常缓慢,重启一次应用也能撑个1至2周,所以也拖到了现在也就是19年2月底,算是彻底解决了这个问题。
- 最开始的时候怀疑是G1 收集器的问题,直接把G1收集器改回CMS收集器,其中调整该参数的过程中也发生了一个小问题,具体如下。
- 个人觉得ygc缓慢相关的问题不太好排查,相比full gc问题或者OOM的相关问题,本身ygc带给我们的东西不够多,并且dump下来的信息,也不是保证有用的,可能也是问题被掩盖后的一些无关信息。
- 在排查gc相关问题,个人觉得需要对整个jvm堆内存的划分,以及gc的一系列流程,有所了解和掌握,才能够快速的定位和排查问题。
参考文章
- http://zhuanlan.51cto.com/art/201706/543485.htm
版权声明 作者:wycm
出处: https://my.oschina.net/wycm/blog/3023965
您的支持是对博主最大的鼓励,感谢您的认真阅读。
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

© 著作权归作者所有
共有人打赏支持
上一篇: 无界面Ubuntu服务器搭建selenium+chromedriver+VNC运行环境
下一篇: 一次频繁Full GC问题排查过程分享

卧颜沉默
粉丝 2
博文 10
码字总数 17850
作品 0
成都
提问相关文章 最新文章
windows server 2008R2 已断开会话处理
问题描述: 生产环境上线堡垒机后,使用2008R2作为应用发布服务器,提供一些windows程序应用服务。使用一段时间后,发现远程桌面会话打开越来越慢,在服务器上上传下载速度也越来越慢。 临时...
FJCA
2018/08/10
0
0
HBase工程师线上工作经验总结----HBase常见问题及分析
阅读本文可以带着下面问题: 1.HBase遇到问题,可以从几方面解决问题? 2.HBase个别请求为什么很慢?你认为是什么原因? 3.客户端读写请求为什么大量出错?该从哪方面来分析? 4.大量服务端e...
vieky
2014/12/10
0
0
记一次查内存异常问题(续《记一次Web应用CPU偏高》)
继上一次查应用的CPU飙高问题(http://www.cnblogs.com/hzmark/p/JVM_CPU.html)过去10天了。上次只是定位到了是一个第三方包占用了大量的CPU使用,但没有细致的去查第三方包为什么占用了这么...
蘑菇街隐修
2014/06/16
0
0
UEditor导致的上传大文件失败
之前写过一篇 《闹心的Broken pipe》,nginx导致的请求超时,但是今天又碰到个奇葩事儿,容我喝一口82年的白开水慢慢道来 源起 项目中用到视频上传,两种上传方式,一种直接表单提交,一种内...
小尘哥
2018/10/18
0
0
ignite 通写速度变慢
@李老师 你好,想跟你请教个问题: Ignite 1.9配置的通写ORACLE,配置了事务支持CacheAtomicityMode.TRANSACTIONAL,关闭了后写缓存, 在测试时单表put时,当数据库数据越来越多,Ignite ca...
liwenlin000
2017/05/26
124
1
没有更多内容
加载失败,请刷新页面
加载更多
《从0到1学习Flink》—— Flink 写入数据到 ElasticSearch
前言 前面 FLink 的文章中我们已经介绍了说 Flink 已经有很多自带的 Connector。 1、《从0到1学习Flink》—— Data Source 介绍 2、《从0到1学习Flink》—— Data Sink 介绍 其中包括了 Sour...
火力全開
12分钟前
0
0
Java实现几种常见排序方法——冒泡排序
冒泡排序 比较相邻的元素。如果第一个比第二个小,就交换他们两个。 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最小的数。 针对所有的元素...
基围虾21
14分钟前
0
0
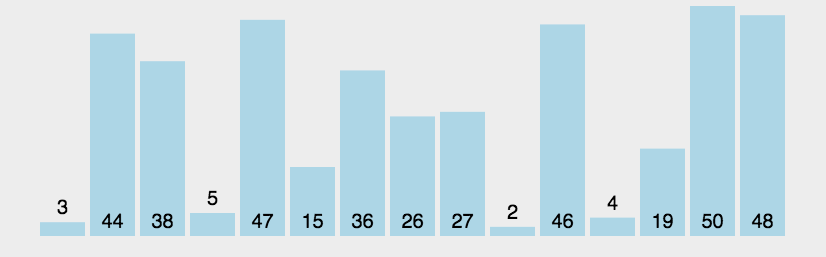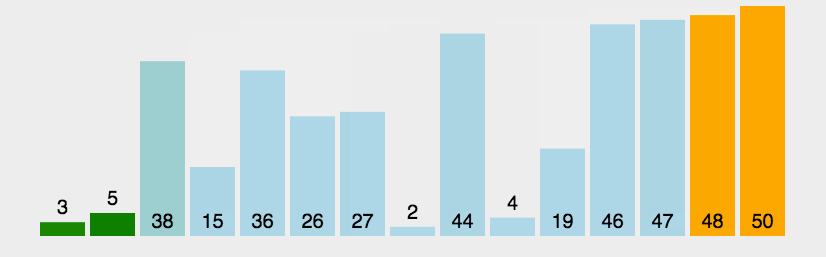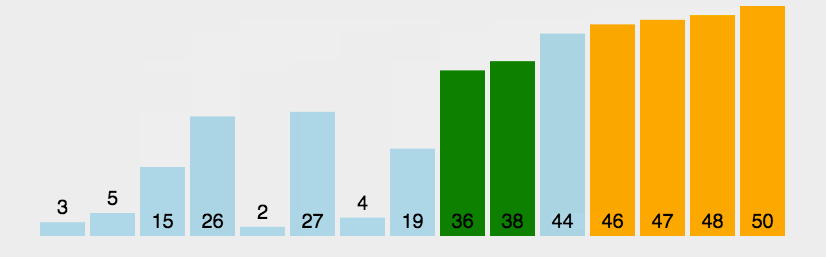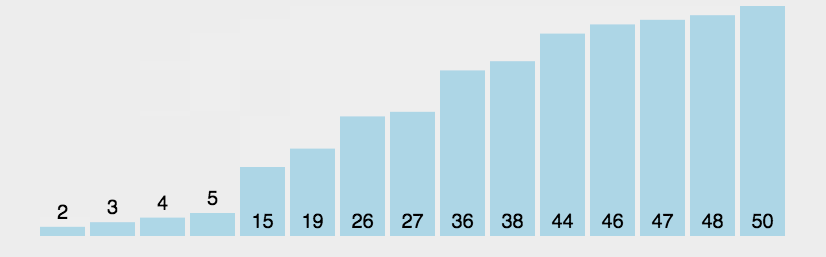
Nginx源码编译安装及详细参数解释
nginx源码编译参数细述 --prefix= 指向安装目录--sbin-path 指向(执行)程序文件(nginx)--conf-path= 指向配置文件(nginx.conf)--error-log-path= 指向错误日志目录--p...
问题终结者
24分钟前
0
0
createDrawerNavigator
createDrawerNavigator抽屉效果,侧边滑出: createDrawerNavigator API createDrawerNavigator(RouteConfigs, DrawerNavigatorConfig): RouteConfigs(必选):路由配置对象是从路由名称到路......
不负好时光
27分钟前
1
0
【VSCode】Windows下VSCode便携式c/c++环境【更新 2018.03.27】
版权声明:本文为博主原创文章,转载请注明出处。 https://blog.csdn.net/c_duoduo/article/details/52083494 Windows下VSCode便携式c/c++环境 ——————2018.03.27更新—————— Visu...
shzwork
38分钟前
0
0
没有更多内容
加载失败,请刷新页面
加载更多正文到此结束
- 本文标签: CTO 源码 jvisualvm ORM cat JVM API web 经验总结 文章 https 服务端 配置 空间 测试 总结 Action 数据库 提问 NSA java 实例 ACE ip 十年 安装 pinpoint 时间 编译 开发 JavaScript Oracle 工程师 IDE Ubuntu HTML node http IO map 缓存 SDN 服务器 参数 Atom Elasticsearch 数据 目录 App windows src cache HBase Full GC Netty Nginx Chrome 下载 js id UI
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

