『互联网架构』软件架构-从0到1认知分布式架构(上)(38)
不管之前接触过分布式的没有,有没有分布式的经验,跟这老铁我一起看看熟悉下,绝对收获满满,里面可是有段子啊~
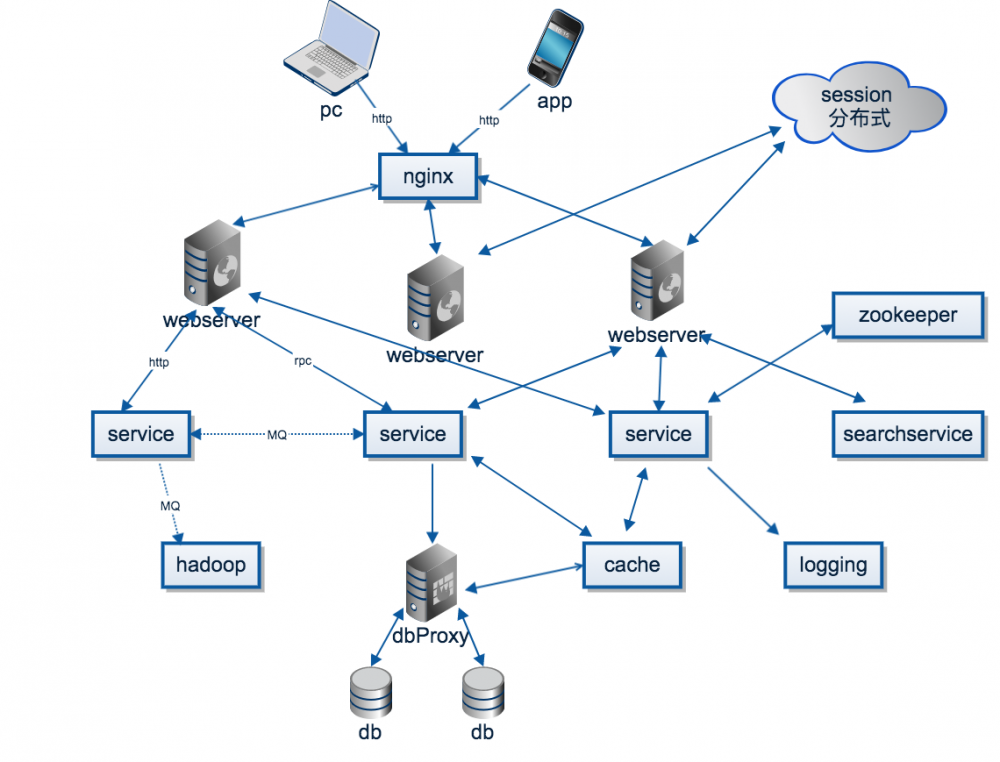
####(一)分布式发展的历史和背景
* 场景
一家做政府系统OA系统的公司老板,发现跟竞争对手比发现自己的系统的架构不是分布示的,招标的时候不是特别的顺利,就找到技术负责人问,把系统架构升级成分布示架构要多长时间啊?技术负责人网上查了查 dubbo官网,看了看 Demo 这不很简单吗,拍着胸脯一个月能升级好。
-
这位技术经理在改造过程中可能会遇到什么风险和问题?
>有些老铁有工作经验的在传统行业做过的印象比较深刻,OA,ERP,政务系统。大家一起想想,这个技术经理把单体架构改造成分布式系统说要一个月的时间升级好。
1.新功能
业务的问题,业务还是在持续的增长,新开发的业务是放到新系统上还是放在旧系统里面去,放在旧系统里面实现的周期是可以估算出来的,放在新系统可能还不稳定开发周期不容易预估,功能如果对于业务部门很重要的话,业务愿意在新系统开发吗?
2.旧bug
旧系统的bug是不是需要改2遍,新旧都要改一遍,尤其是比较大的功能,这个非常的明显。
3.业务完整性
比较大的系统都是由多个人一起开发的,A开发一半跑路了,B应聘来了继续开发,B又了新项目,让C接手,尤其是传统的功能都没有产品经理,程序员自己想自己开发。就算有产品经理也来来回回换了好几遍了。前人挖坑后人填,怎么填,拿身体去填。完整的业务都没人能说清楚,如何改造成分布式系统?就算是不改造成分布式系统,重构也会遇见这种问题。我相信有看我文章的老铁【正在经历】。看老板的思路了,一般的老铁都是选择长痛,继续玩下去选择不改造,最后忍无可忍,自己把自己从这个公司炒了。
4.团队协作方式转变
原来开发都是采用SSM这种框架,但是采用了分布式之后,还需要用到zookeeper,redis,dubbo,springcloud,这种新技术,这些开发人员如何使用这些技术还来得及吗?
5.系统交付方式的转变
在传统开发方式,产品的迭代都是由业务经理来确定的,业务经理从客户那里获取到需求后,开发完成进行系统的迭代,如果是分布式的系统,这个时候变的很复杂,不可能按照业务经理推动上线。本身应该有产品迭代的周期。
6.总结
单体应用升级成分布式应用,绝对不仅仅是由技术上可以解决的,不是技术OK就OK了,你会dubbo了,你会springclud了就可以保证迁移成分布式的,这一点一定要明白要认可。这些问题解决涉及业务部门及整个技术部门(开发、测试、运维)协商与工作标准的制定。而且在升级过程中也不是一次性升级的,如果一次性升级的只会【SI】的惨。业务相关问题暂不做讨论,如何和业务部门进行友好的协商,如何将单体应用迁移成为分布式,每个公司不同的业务,不同的环境,这里就不讨论了。技术架构上应该要清楚自己的职责是,如何通过技术手段把业务波动降至最低、开发成本最低、实施风险最低。要解决这些问题的前提之一就是要对分布式架构有整体的认知,不是你会个分布式框架,会个RPC框架就搞的定的。相信举上边的例子大家应该是深有感触的。
提高分布式叫的整体认知
- 1.系统架构的发展历史
学习一门技术一定要懂它的历史,忘记历史就意味着被判,一定要了解它的历史,知道它是如何一步步走过来的。
- 2.一套分布式系统的组成
了解分布式架构的本质和理论搞清楚,不管是用dubbo或者springclud,它们底层功能点都是一样的,根据根据某个功能有强和弱之分,本质上他们是没有区别的。
- 3.分布式架构所带来的成本与风险
其实技术只是其中的一块,更多的是提前预支对开发模式的转变,提前怼风险有个预判。遇到这些问题不至于手忙脚乱。不至于很茫然。
####(二)架构的发展历史
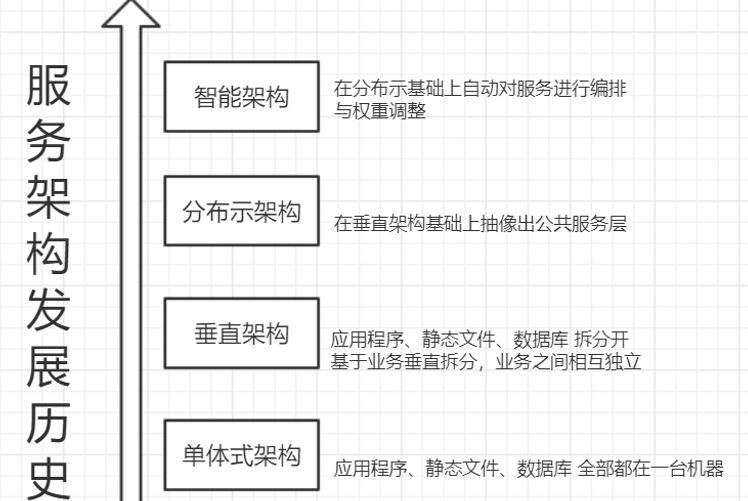
-
单体式架构
>应用程序,静态文件,数据库全部都在一台机器上。那个年代写个网站10万块,那个年代程序员不会说自己去搬砖,程序员还是一份体面的工作,那个时候马云还是推销他的阿里巴巴,马化腾还是写他的qq,那个时候的房价郑州估计才300多一平,股市只有1700多点。到现在一切都变了。
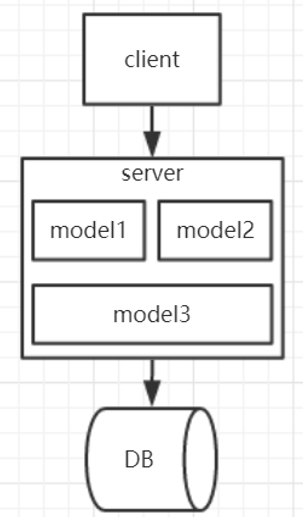
在单体架构里面,客户端可能是cs的,也可能是bs的,服务里面包括所有的模型。所有的请求都包括在server里面,数据库只有一个。实现这个架构更多的是sql语句写好,业务更多的是通过sql来实现的。那个时候hibernate还没有,也没有ORM框架,用这jdbc写的挺爽,当model越来越多的时候,开发效率变的很低,这个项目可能几百个模块,光构建就要花半个小时,我记得公司原来有个项目,那时候才大学毕业那个项目名字叫98系统,就是98年开发完毕的,构建需要半个小时,那时候电脑内存才2g,用的是奔4cpu。其中一个模块报错,需要重新构建一次,都是全部写完看了几遍才敢测试,因为构建太慢了。
-
垂直架构
>大家后来都想开了,都在一个项目开发太费劲了,不如分成很多的小项目吧,各自维护各自的数据库。每个团队维护自己的,性能和效率都解决了。
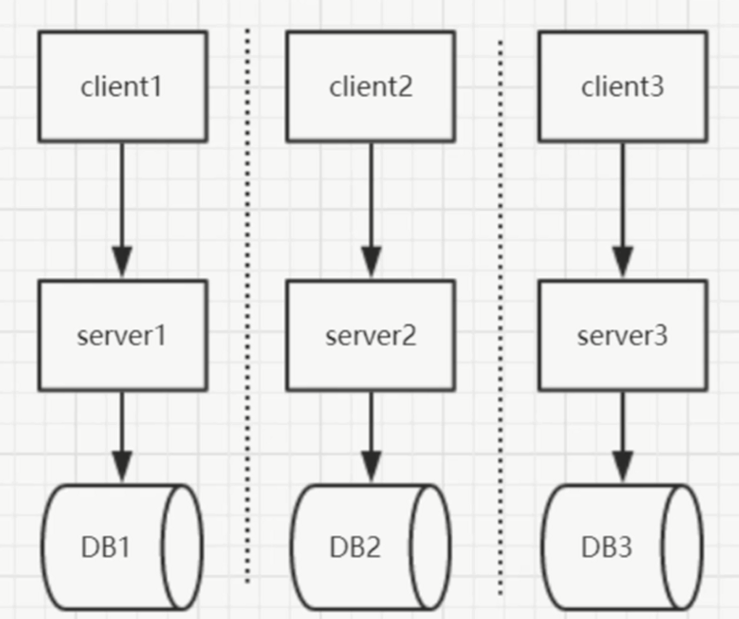
这种的问题server1和server2有相同的功能的话,它们之间是不会有任何的交互的,完全是进行隔离的。当初09年开始做开发的时候,为了让2个系统结合起来就用了cas做统一登录,用户在B系统中想看A系统的信息,需要登录A系统的模块,输入查询的内容进行查看,用户并不知道是2个系统,其实我们很清楚。他在两个系统之间进行跳转。数据基本不共享。更多的是关心界面,基本界面开发完了,系统也就开发完了。60%–80%是开发界面。没有接口的概念。完完全全是隔离开来的。如果想交互成本很高。当时有同事用kettle的etl进行数据抽取,抽取后定时的放到B系统中。
-
分布示架构
>将公共的部分抽取成一个服务。公共部分是在通过公共服务来提供。之前垂直的架构,复杂的业务,不熟悉另一个系统的业务的话,根本数据库是看不懂的。
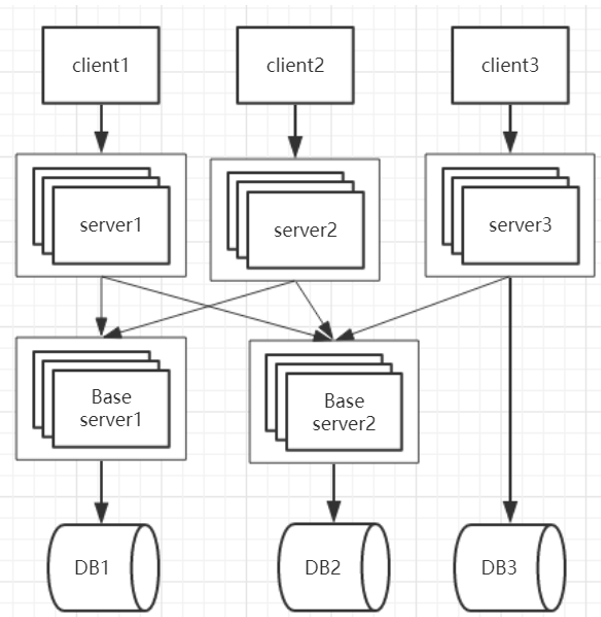
公共部分的抽离,如果性能受不了,可以部署在不同的机器上,它们各自的数据库。 也就分了:UI层,业务层,底层服务层,存储层。这也就是分布式框架常用的层次逻辑。提高弹性扩展能力。
抽取公共服务,保证程序的弹性扩张,也就是程序量增加的时候访问量也随之增加。分布式架构的初衷。分布式架构不会提高开发上的效率。更多是加大了开发的复杂度。让生产效率变慢。有些老板不懂盲目的追求技术,记得原来做桌面开发,其实c#更合适,但是有的老板觉得java特别特别的热去搞java开发,后来发现用java这些桌面程序人难找,人又贵,肠子都悔青了。合适性。07年才工作的时候,公司用delphi更佳,是不是暴露年龄了哈哈。
-
智能架构
> 节点特别多,内网开销非常的大,如果采用智能编排,采用部署在同一台机器上,通过监控工具,智能的在同一台机器,是不是内网的IO就得到了很好的解决,并发很大的时候性能的瓶颈就是在内网IO上面,1000MB的带宽都带不动。如果server1有10个节点访问很频繁,server2也是10个节点都没多少人访问,如果有了只能架构,也就是容器编排就可以很好的进行编排,让server1随时的加大,server2随时的减少。这个是随时通过按钮就可以进行编排的了,跟nginx负载不是一个概念。智能的追踪服务调用链之间的关系,如果是base server1修改后,智能的分析出来那些用例收到了影响。好进行回归测试。这也是未来的架构,智能的服务编排。开始学docker吧。未来属于它。
-
回顾
>那时候机器都是上百万的,用的数据库都是oracle的,关联查询随便写,但是现在用了分布式mysql,不敢写,随时可能让数据库崩。一个技术非常先进,但是不能落地的系统只有一个作用,就是写ppt。写完ppt用来吹NB。
(三)如何着手架构一套分布式系统
拒绝吹NB。实现分布式框架最核心的功能是什么?
我来回答:【调用】
-
RPC远程调用技术:
>拿几个大家比较熟悉的来举例:RMI 、Web
Service、Http

| 协议 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| RMI | JAVA 远程方法调用、使用原生二进制方式进行序列化 | 简单易用、SDK支持,提高开发效率 | 不支持跨语言 |
| Web Service | 比较早系统调用解决方案 ,跨语言, 其基于WSDL 生成 SOAP 进行消息的传递。 | SDK支持、跨语言 | 实现较重,发布繁琐 |
| Http | 采用htpp +json 实现 | 简单、轻量、跨语言 | 不支持SDK |
- 如果服务端不是单个的话,实际是服务端是多个,要解决的问题又来了?
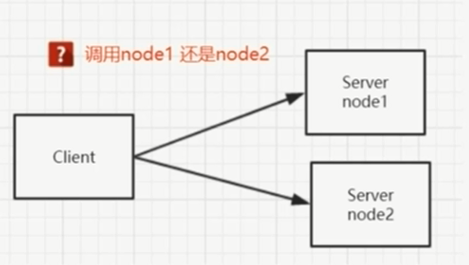
1.负载均衡
到底是随机调还是轮询调,这个就是负载均衡
2.容错
如果调用其中一台调用出错了怎么办?继续调?还是换个节点?还是等一会在调?
3.服务配置
服务端地址配置在哪里?client需要知道node1和node2的IP,直接在client直接写ip,如果增加node3,或者把node1去掉,是不是要频繁的修改,服务频繁的重启,麻烦啊!可以搞个注册中心。节点起来了部署到注册中心中。节点发生变化通知client。
3.健康检测
服务关了宕机了,恢复后怎么办?
PS:另外分享一个心得:很多公司需要一套框架,业内有比较成熟的开源系统,但是技术经理还是要选择自主去开发一套,这是为什么呢?为了kpi,大公司kpi要求比较高,为了突显业绩。也是一种自我保护。做开发不能老开发,也要学会自我的保护。程序员也是要追逐利益的。说服一个人不要光讲道理,有句话是利益对了道理自然对了。自我成长的时候,学习只选择最对的。
>>原创文章,欢迎转载。转载请注明:转载自,谢谢!>>原文链接地址:上一篇:已是最新文章
正文到此结束
- 本文标签: web https 网站 redis 软件 src IO springcloud java ip 产品 数据 Docker client ORM 本质 2019 spring db 互联网 UI json dubbo 业务层 bug 部署 rmi node 数据库 系统架构 程序员 Service 模型 并发 云 tab Oracle 配置 智能 开源 文章 分布式系统 JDBC mysql 测试 sql 时间 总结 http 分布式 回答 协议 负载均衡 zookeeper 需求 开发 马云 id 注册中心 Nginx js 阿里巴巴 SOA 关联查询 马化腾 服务端 bus
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

