Java 的网络 IO 模型彻底讲解
JAVA 的网络 IO 模型彻底讲解
1 ,最原始的 BIO 模型
该模型的整体思路是有一个独立的 Acceptor 线程负责监听客户端的链接,它接收到客户端链接请求之后为每个客户端创建一个新的线程进行链路处理,处理完成之后,通过输出流返回应答给客户端,线程销毁。这就是典型的一请求一应答的通讯模型。
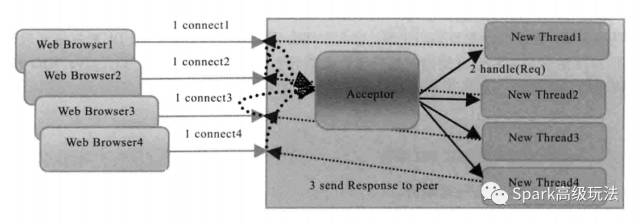
该模型的最大问题就是缺乏弹性伸缩能力,当客户端并发访问量增加后,服务端的线程数和客户端并发访问数呈现 1:1 的正比关系,由于线程是 Java 虚拟机非常宝贵的系统资源,当线程数膨胀之后,系统性能将极具下降,随着并发访问量的继续增大,系统会发生线程对栈溢出、创建新线程失败等问题,并最终导致进程宕机或者僵死,不能对外提供服务。
2 ,伪异步 IO ,改进版 BIO
相对于 BIO 该方式做了两点改进 :
一,采用线程池代替原来的一个连接对应一个线程的后端处理模型。
二,增加了一个任务队列。
具体过程就是,当有新的客户端请求接入的时候,将客户端的 Socket 封装成一个 task (实现 Runnable 接口)投递到任务队列里面,然后由线程池去处理。由于任务队列的大小和线程池的线程数目都是可控的,因此,它的资源占用是可控的,无论多少个客户端并发访问,都不会导致资源耗尽和宕机。
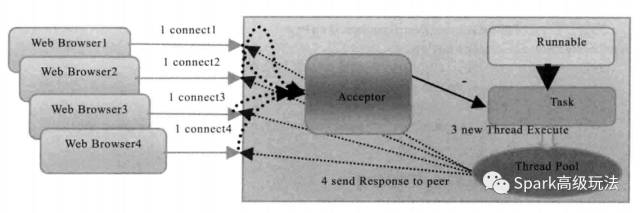
该方式最终也还没有从根本上解决通信线程阻塞的问题。
3 , NIO 模型
NIO 模型是在 JDK1.4 开始引入的,弥补了原来同步阻塞 IO 的不足。要了解 IO 就要彻底搞明白几个概念。
A) , 缓冲区 Buffer
在面向流的 IO 中,可以将数据直接写入或者将数据直接督导 Stream 对象中。在 NIO 库中,所有的数据都是用缓冲区进行处理的。在读数据时,它是直接读到缓冲区中的 ; 在写数据时,写入到缓冲区中。任务和访问 NIO 中的数据,都是通过缓冲区进行操作的。 Java NIO 有以下 Buffer 类型 :
ByteBuffer
MappedByteBuffer
CharBuffer
DoubleBuffer
FloatBuffer
IntBuffer
LongBuffer
ShortBuffer
A) , 通道 Channel
Channel 是一个通道,网络数据通过 Channel 读取和写入。通道和流的不同之处在于通道是双向的,流只是在一个方向上移动 ( 一个流必须是 InputStream 或者 OutputStream 的子类 ) ,而且通道可以用于读、写或者同时用于读写。
B) , 多路复用器 Selector
多路复用器提供选择已经就绪的任务的能力。简单来讲, Selector 会不断地轮训注册在其上的 Channel ,如果某个 Channel 上面有新的 TCP 链接接入、读和写事件,这个 Channel 就处于就绪状态,会被 Selector 轮询出来,然后通过 SelectionKey 可以获取就绪 Channel 的集合,进行后续的 IO 操作。先前的实现是基于 select ,有句柄数目限制 1024 ,后面 NIO2.0 改成了 epoll(AIO) 就突破了最大链接句柄限制。异步通道提供两种方式获取结果:
1), 通过 java.util.concurrent.Future 类来表示异步操作的结果 ;
2), 在执行异步操作的时候传入一个 java.nio.channels 。由 CompletionHandler 接口的实现类作为操作完成的回调。
NIO2.0 的异步套接字是真正的异步非阻塞 IO ,它对应 UNIX 网络编程中的事件驱动 IO(AIO) ,它不需要通过多路复用器 (selector) 对注册的通道进行轮询操作即可实现异步读写,从而简化了 NIO 的编程模型。
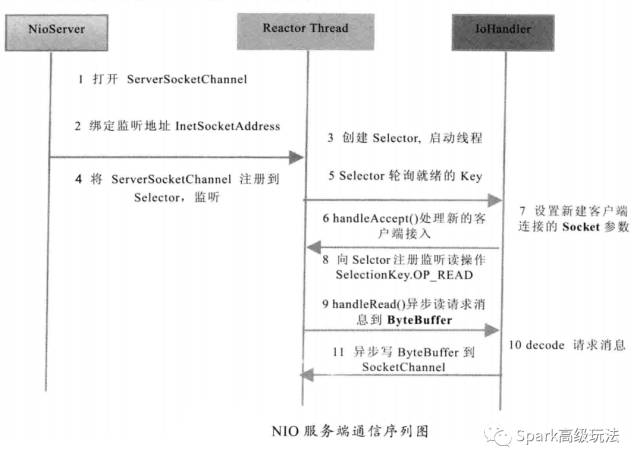
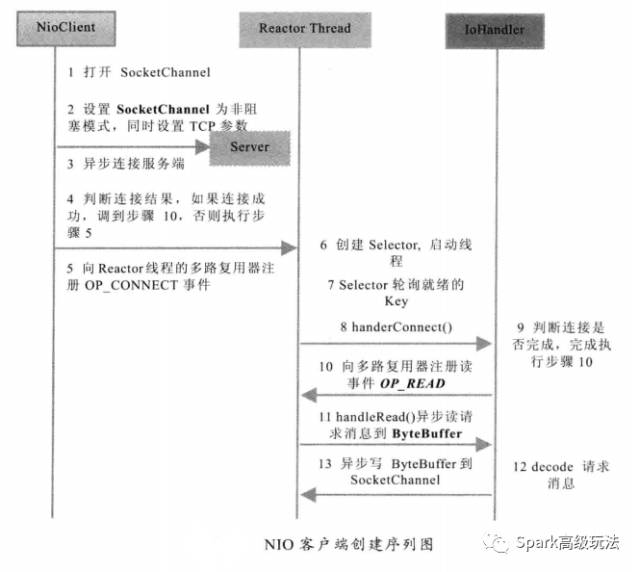
NIO服务端及客户端通讯时序图如下
4 , Reactor 线程模型
1),Reactor 单线程模型

由于 Reactor 模式使用的是异步非阻塞 IO ,所有操作都不会导致阻塞,理论上一个线程可以独立处理所有 IO 相关的操作。从架构层面来看,一个 NIO 线程确实完全可以承担起职责。例如,通过 Acceptor 类接收客户端的 TCP 链接请求消息,当链路建立成功之后,通过 Dispatch 将对应的 ByteBuffer 派发给指定的 Handler 上进行编解码。用户线程消息编码后通过 NIO 线程将消息发送给客户端。不适合,高负载,大并发的应用场景,主要原因如下 :
A), 一个 NIO 线程同时处理成百上千的链路,性能上无法支撑,即便 NIO 线程的 CPU 负荷达到 100% ,也无法满足海量消息的编码、解码、读取和发送。
B), 当 NIO 线程负载过重之后,处理速度将变慢,这会导致大量客户端链接超时,超时之后往往会进行重发,这更加重了 NIO 线程的负载,最终会导致大量消息积压和处理超时,成为系统的性能瓶颈。
C), 可靠性问题 : 一旦 NIO 线程意外跑飞,或者进入死循环,会导致整个系统通讯模块不可用,不能接受和处理外部消息,造成节点故障。
2) ,Reactor 多线程模型
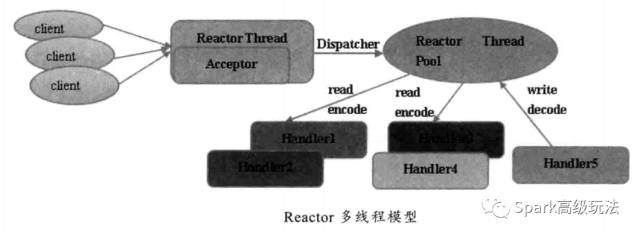
Reactor 多线程模型有以下特点 :
A), 有一个 NIO 线程 -Acceptor 线程用于监听服务端,接受客户端的 TCP 链接请求。
B), 网络 IO 操作 --- 读写等由一个 NIO 线程池负责,线程池可以采用标准的 JDK 线程池实现,它包含一个任务队列和 N 个可用的线程,由这些 NIO 线程负责消息的读取、解码、编码和发送。
C), 一个 NIO 线程可以同时处理 N 条链路,但是一个链路只对应一个 NIO 线程,防止并发操作问题。
在绝大多数场景下, Reactor 多线程模型可以满足性能需求。但是,在个别特殊场景中,一个 NIO 线程负责监听和处理所有客户端链接可能会存在性能问题。例如并发百万客户端链接,或者服务端需要多客户端握手进行安全认证,但是认证本身非常损耗性能。在这种场景下,单独一个 Acceptor 线程可能会存在性能不足的问题,为了解决性能问题,产生了第三种 Reactor 线程模型 --- 主从 Reactor 多线程模型。
3) , Reactor 主从多线程模型
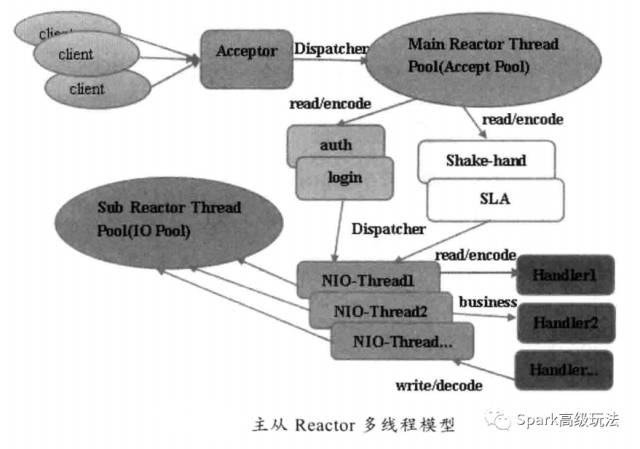
主要特点是 : 服务端用于接收客户端链接不再是一个单独的 NIO 线程,而是一个独立的 NIO 线程池。 Acceptor 接收到客户端 TCP 链接请求并处理完成后 ( 可能包含接入认证等 ) ,将新创建的 SocketChannel 注册到 IO 线程池 (sub reactor 线程池 ) 的某个 IO 线程上,由它负责 SocketChannel 的读写和编码工作。 Acceptor 线程池仅仅用于客户端的登录、握手和安全认证,一旦链路建立成功,就将链路注册到后端 subReactor 线程池的 IO 线程上,由 IO 线程负责后续的 IO 操作。
5 , netty 的线程模型
Netty 框架的主要线程模型就是 IO 线程,线程模型设计的好坏,决定了系统的吞吐量、并发性和安全性等架构质量属性。
Netty 的线程模型被精心的设计,即提升了框架的并发性能,又能在很大程度避免锁,局部实现了无锁化设计。
Netty 的线程模型并不是一成不变的,它实际取决于用户的启动参数配置。通过设置不同的启动参数, Netty 可以同时支持 Reactor 单线程模型,多线程模型和主从 Reactor 多线程模型。
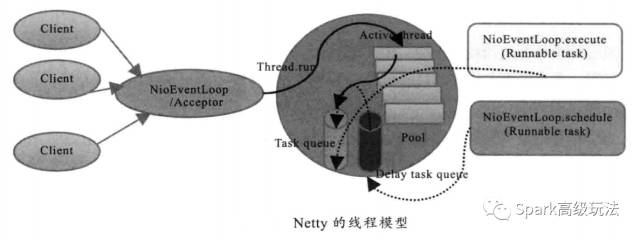
服务启动的时候,会创建两个 NioEventLoopGroup ,它们实际是两个独立的 Reactor 线程池。一个用于接收客户端的 TCP 链接,另一个用于处理 IO 相关的读写操作,或者执行系统 Task 、定时任务 Task 等。
Netty 用于接收客户端请求的线程池职责如下 :
1), 接收客户端 TCP 链接,初始化 Channel 参数 ;
2), 将链路状态变更时间通知给 ChannelPipeLine 。
Netty 处理 IO 操作的 Reactor 线程池职责如下 :
1), 异步读取通讯端的数据报,发送读事件到 ChannelPipeLine
2), 异步发送消息到通信对端,调用 ChannelPipeLine 的消息发送接口
3), 执行系统调用 Task
4), 执行定时任务 Task ,例如链路空闲状态监测定时任务。
具体启动代码如下:

为了尽可能的提示性能, Netty 在很多地方进行了无锁化的设计,例如在 IO 线程内部进行,线程操作,避免多线程竞争导致的性能下降问题。表面上看,串行化设计似乎 CPU 利用率不高,并发度不够。但是通过调整 NIO 线程池的线程参数,可以同时启动多个串行化的线程并行运行,这种局部无锁化的串行设计相比一个队列 --- 多个工作线程的模型更优。设计原理如下图 :
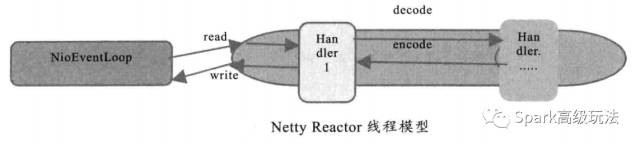
Netty 的 NioEventLoop 读取到消息之后,直接调用 ChannelPipeLine 的 fireChannelRead(Object msg). 只要用户不主动切换线程,一直都是由 NioEventLoop 调用用户的 Handler ,期间不进行线程切换。这种串行化处理方式避免了多线程操作导致的锁的竞争,从性能角度看是最优的。
Netty 的多线程编程最佳实践如下:
1), 创建两个 NioEventLoopGroup ,用于隔离 NIO Acceptor 和 NIO IO 线程。
2), 尽量不要在 ChannelHandler 中启动用户线程 ( 解码后用于将 POJO 消息派发到后端业务线程的除外 ) 。
3), 解码要放在 NIO 线程调用的解码 Handler 中进行,不要切换到用户线程中完成消息的解码。
4), 如果业务逻辑操作非常简单,没有复杂的业务逻辑计算,没有可能会导致线程被阻塞的磁盘操作,数据库操作,网络操作等,可以直接在 NIO 线程上完成业务逻辑编排,不需要切换到用户线程。
5), 如果业务逻辑处理复杂,不要在 NIO 线程上,完成,建议将解码后的 POJO 消息封装成 Task ,派发到业务线程池中由业务线程执行,以保证 NIO 线程尽快被释放,处理其他的 IO 操作。
推荐的线程数量计算公式有以下两种。
1), 公式 1: 线程数量 =( 线程总时间 / 瓶颈资源时间 )* 瓶颈资源线程的并行数;
2), 公式 2:QPS=1000/ 线程总时间 * 线程数。
由于用户场景的不同,对于一些复杂的系统,实际上很难计算出最优线程配置,只能是根据测试数据和用户场景,结合公式给出一个相对合理的范围,然后对范围内的数据进行性能测试,选择相对最优值。
注:
本文主要参考 netty 权威指南。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

