来,带你鸟瞰 Java 中4款常用的并发框架!
1. 为什么要写这篇文章
几年前 NoSQL 开始流行的时候,像其他团队一样,我们的团队也热衷于令人兴奋的新东西,并且计划替换一个应用程序的数据库。 但是,当深入实现细节时,我们想起了一位智者曾经说过的话:“细节决定成败”。最终我们意识到 NoSQL 不是解决所有问题的银弹,而 NoSQL vs RDMS 的答案是:“视情况而定”。
类似地,去年RxJava 和 Spring Reactor 这样的并发库加入了让人充满激情的语句,如异步非阻塞方法等。为了避免再犯同样的错误,我们尝试评估诸如 ExecutorService、 RxJava、Disruptor 和 Akka 这些并发框架彼此之间的差异,以及如何确定各自框架的正确用法。
本文中用到的术语在这里有更详细的描述。
2. 分析并发框架的示例用例
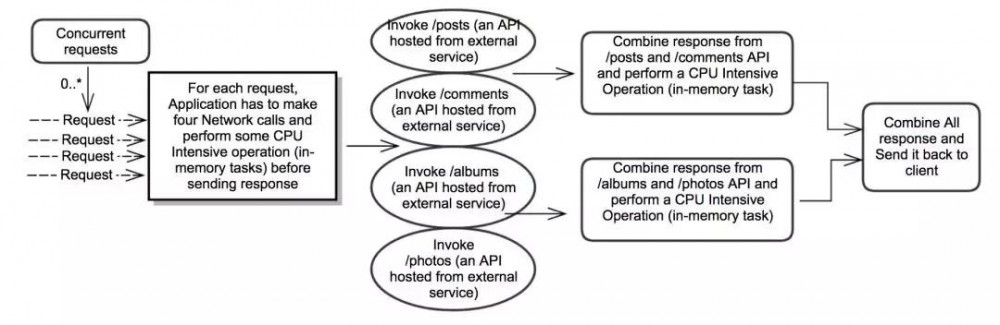
3. 快速更新线程配置
在开始比较并发框架的之前,让我们快速复习一下如何配置最佳线程数以提高并行任务的性能。 这个理论适用于所有框架,并且在所有框架中使用相同的线程配置来度量性能。
-
对于内存任务,线程的数量大约等于具有最佳性能的内核的数量,尽管它可以根据各自处理器中的超线程特性进行一些更改。
-
例如,在8核机器中,如果对应用程序的每个请求都必须在内存中并行执行4个任务,那么这台机器上的负载应该保持为 @2 req/sec,在 ThreadPool 中保持8个线程。
-
对于 I/O 任务,ExecutorService 中配置的线程数应该取决于外部服务的延迟。
-
与内存中的任务不同,I/O 任务中涉及的线程将被阻塞,并处于等待状态,直到外部服务响应或超时。 因此,当涉及 I/O 任务线程被阻塞时,应该增加线程的数量,以处理来自并发请求的额外负载。
-
I/O 任务的线程数应该以保守的方式增加,因为处于活动状态的许多线程带来了上下文切换的成本,这将影响应用程序的性能。 为了避免这种情况,应该根据 I/O 任务中涉及的线程的等待时间按比例增加此机器的线程的确切数量以及负载。
4. 性能测试结果
性能测试配置 GCP -> 处理器:Intel(R) Xeon(R) CPU @ 2.30GHz;架构:x86_64;CPU 内核:8个(注意: 这些结果仅对该配置有意义,并不表示一个框架比另一个框架更好)。

5. 使用执行器服务并行化 IO 任务
5.1 何时使用?
如果一个应用程序部署在多个节点上,并且每个节点的 req/sec 小于可用的核心数量,那么 ExecutorService 可用于并行化任务,更快地执行代码。
5.2 什么时候适用?
如果一个应用程序部署在多个节点上,并且每个节点的 req/sec 远远高于可用的核心数量,那么使用 ExecutorService 进一步并行化只会使情况变得更糟。
当外部服务延迟增加到 400ms 时,性能测试结果如下(请求速率 @50 req/sec,8核)。

5.3 所有任务按顺序执行示例
// I/O 任务:调用外部服务 String posts = JsonService.getPosts(); String comments = JsonService.getComments(); String albums = JsonService.getAlbums(); String photos = JsonService.getPhotos(); // 合并来自外部服务的响应 // (内存中的任务将作为此操作的一部分执行) int userId = new Random().nextInt(10) + 1; String postsAndCommentsOfRandomUser = ResponseUtil.getPostsAndCommentsOfRandomUser(userId, posts, comments); String albumsAndPhotosOfRandomUser = ResponseUtil.getAlbumsAndPhotosOfRandomUser(userId, albums, photos); // 构建最终响应并将其发送回客户端 String response = postsAndCommentsOfRandomUser + albumsAndPhotosOfRandomUser; return response;
5.4 I/O 任务与 ExecutorService 并行执行代码示例
// 添加 I/O 任务 List<Callable<String>> ioCallableTasks = new ArrayList<>(); ioCallableTasks.add(JsonService::getPosts); ioCallableTasks.add(JsonService::getComments); ioCallableTasks.add(JsonService::getAlbums); ioCallableTasks.add(JsonService::getPhotos); // 调用所有并行任务 ExecutorService ioExecutorService = CustomThreads.getExecutorService(ioPoolSize); List<Future<String>> futuresOfIOTasks = ioExecutorService.invokeAll(ioCallableTasks); // 获取 I/O 操作(阻塞调用)结果 String posts = futuresOfIOTasks.get(0).get(); String comments = futuresOfIOTasks.get(1).get(); String albums = futuresOfIOTasks.get(2).get(); String photos = futuresOfIOTasks.get(3).get(); // 合并响应(内存中的任务是此操作的一部分) String postsAndCommentsOfRandomUser = ResponseUtil.getPostsAndCommentsOfRandomUser(userId, posts, comments); String albumsAndPhotosOfRandomUser = ResponseUtil.getAlbumsAndPhotosOfRandomUser(userId, albums, photos); // 构建最终响应并将其发送回客户端 return postsAndCommentsOfRandomUser + albumsAndPhotosOfRandomUser;
6. 使用执行器服务并行化 IO 任务(CompletableFuture)
与上述情况类似:处理传入请求的 HTTP 线程被阻塞,而 CompletableFuture 用于处理并行任务
6.1 何时使用?
如果没有 AsyncResponse,性能与 ExecutorService 相同。 如果多个 API 调用必须异步并且链接起来,那么这种方法更好(类似 Node 中的 Promises)。
ExecutorService ioExecutorService = CustomThreads.getExecutorService(ioPoolSize);
// I/O 任务
CompletableFuture<String> postsFuture = CompletableFuture.supplyAsync(JsonService::getPosts, ioExecutorService);
CompletableFuture<String> commentsFuture = CompletableFuture.supplyAsync(JsonService::getComments,
ioExecutorService);
CompletableFuture<String> albumsFuture = CompletableFuture.supplyAsync(JsonService::getAlbums,
ioExecutorService);
CompletableFuture<String> photosFuture = CompletableFuture.supplyAsync(JsonService::getPhotos,
ioExecutorService);
CompletableFuture.allOf(postsFuture, commentsFuture, albumsFuture, photosFuture).get();
// 从 I/O 任务(阻塞调用)获得响应
String posts = postsFuture.get();
String comments = commentsFuture.get();
String albums = albumsFuture.get();
String photos = photosFuture.get();
// 合并响应(内存中的任务将是此操作的一部分)
String postsAndCommentsOfRandomUser = ResponseUtil.getPostsAndCommentsOfRandomUser(userId, posts, comments);
String albumsAndPhotosOfRandomUser = ResponseUtil.getAlbumsAndPhotosOfRandomUser(userId, albums, photos);
// 构建最终响应并将其发送回客户端
return postsAndCommentsOfRandomUser + albumsAndPhotosOfRandomUser;
7. 使用 ExecutorService 并行处理所有任务
使用 ExecutorService 并行处理所有任务,并使用 @suspended AsyncResponse response 以非阻塞方式发送响应。
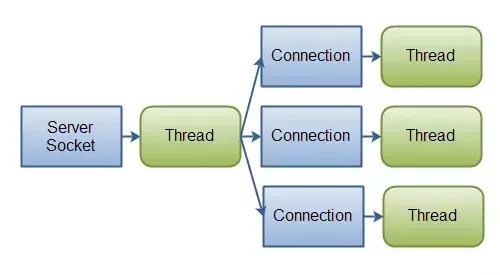
-
HTTP 线程处理传入请求的连接,并将处理传递给 Executor Pool,当所有任务完成后,另一个 HTTP 线程将把响应发送回客户端(异步非阻塞)。
-
性能下降原因:
-
在同步通信中,尽管 I/O 任务中涉及的线程被阻塞,但是只要进程有额外的线程来承担并发请求负载,它仍然处于运行状态。
-
因此,以非阻塞方式保持线程所带来的好处非常少,而且在此模式中处理请求所涉及的成本似乎很高。
-
通常,对这里讨论采用的例子使用异步非阻塞方法会降低应用程序的性能。
7.1 何时使用?
如果用例类似于服务器端聊天应用程序,在客户端响应之前,线程不需要保持连接,那么异步、非阻塞方法比同步通信更受欢迎。在这些用例中,系统资源可以通过异步、非阻塞方法得到更好的利用,而不仅仅是等待。
// 为异步执行提交并行任务
ExecutorService ioExecutorService = CustomThreads.getExecutorService(ioPoolSize);
CompletableFuture<String> postsFuture = CompletableFuture.supplyAsync(JsonService::getPosts, ioExecutorService);
CompletableFuture<String> commentsFuture = CompletableFuture.supplyAsync(JsonService::getComments,
ioExecutorService);
CompletableFuture<String> albumsFuture = CompletableFuture.supplyAsync(JsonService::getAlbums,
ioExecutorService);
CompletableFuture<String> photosFuture = CompletableFuture.supplyAsync(JsonService::getPhotos,
ioExecutorService);
// 当 /posts API 返回响应时,它将与来自 /comments API 的响应结合在一起
// 作为这个操作的一部分,将执行内存中的一些任务
CompletableFuture<String> postsAndCommentsFuture = postsFuture.thenCombineAsync(commentsFuture,
(posts, comments) -> ResponseUtil.getPostsAndCommentsOfRandomUser(userId, posts, comments),
ioExecutorService);
// 当 /albums API 返回响应时,它将与来自 /photos API 的响应结合在一起
// 作为这个操作的一部分,将执行内存中的一些任务
CompletableFuture<String> albumsAndPhotosFuture = albumsFuture.thenCombineAsync(photosFuture,
(albums, photos) -> ResponseUtil.getAlbumsAndPhotosOfRandomUser(userId, albums, photos),
ioExecutorService);
// 构建最终响应并恢复 http 连接,把响应发送回客户端
postsAndCommentsFuture.thenAcceptBothAsync(albumsAndPhotosFuture, (s1, s2) -> {
LOG.info("Building Async Response in Thread " + Thread.currentThread().getName());
String response = s1 + s2;
asyncHttpResponse.resume(response);
}, ioExecutorService);
8. RxJava
-
这与上面的情况类似,唯一的区别是 RxJava 提供了更好的 DSL 可以进行流式编程,下面的例子中没有体现这一点。
-
性能优于 CompletableFuture 处理并行任务。
8.1 何时使用?
如果编码的场景适合异步非阻塞方式,那么可以首选 RxJava 或任何响应式开发库。 还具有诸如 back-pressure 之类的附加功能,可以在生产者和消费者之间平衡负载。
int userId = new Random().nextInt(10) + 1;
ExecutorService executor = CustomThreads.getExecutorService(8);
// I/O 任务
Observable<String> postsObservable = Observable.just(userId).map(o -> JsonService.getPosts())
.subscribeOn(Schedulers.from(executor));
Observable<String> commentsObservable = Observable.just(userId).map(o -> JsonService.getComments())
.subscribeOn(Schedulers.from(executor));
Observable<String> albumsObservable = Observable.just(userId).map(o -> JsonService.getAlbums())
.subscribeOn(Schedulers.from(executor));
Observable<String> photosObservable = Observable.just(userId).map(o -> JsonService.getPhotos())
.subscribeOn(Schedulers.from(executor));
// 合并来自 /posts 和 /comments API 的响应
// 作为这个操作的一部分,将执行内存中的一些任务
Observable<String> postsAndCommentsObservable = Observable
.zip(postsObservable, commentsObservable,
(posts, comments) -> ResponseUtil.getPostsAndCommentsOfRandomUser(userId, posts, comments))
.subscribeOn(Schedulers.from(executor));
// 合并来自 /albums 和 /photos API 的响应
// 作为这个操作的一部分,将执行内存中的一些任务
Observable<String> albumsAndPhotosObservable = Observable
.zip(albumsObservable, photosObservable,
(albums, photos) -> ResponseUtil.getAlbumsAndPhotosOfRandomUser(userId, albums, photos))
.subscribeOn(Schedulers.from(executor));
// 构建最终响应
Observable.zip(postsAndCommentsObservable, albumsAndPhotosObservable, (r1, r2) -> r1 + r2)
.subscribeOn(Schedulers.from(executor))
.subscribe((response) -> asyncResponse.resume(response), e -> asyncResponse.resume("error"));
9. Disruptor
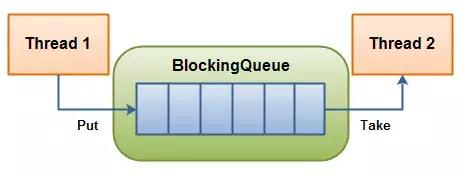
[Queue vs RingBuffer]
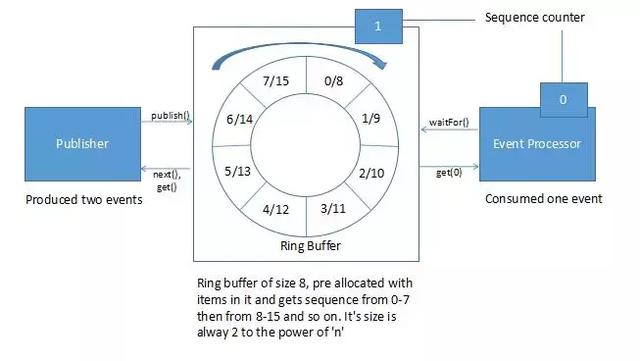
-
在本例中,HTTP 线程将被阻塞,直到 disruptor 完成任务,并且使用 countdowlatch 将 HTTP 线程与 ExecutorService 中的线程同步。
-
这个框架的主要特点是在没有任何锁的情况下处理线程间通信。在 ExecutorService 中,生产者和消费者之间的数据将通过 Queue传递,在生产者和消费者之间的数据传输过程中涉及到一个锁。 Disruptor 框架通过一个名为 Ring Buffer 的数据结构(它是循环数组队列的扩展版本)来处理这种生产者-消费者通信,并且不需要任何锁。
-
这个库不适用于我们在这里讨论的这种用例。仅出于好奇而添加。
9.1 何时使用?
Disruptor 框架在下列场合性能更好:与事件驱动的体系结构一起使用,或主要关注内存任务的单个生产者和多个消费者。
static {
int userId = new Random().nextInt(10) + 1;
// 示例 Event-Handler; count down latch 用于使线程与 http 线程同步
EventHandler<Event> postsApiHandler = (event, sequence, endOfBatch) -> {
event.posts = JsonService.getPosts();
event.countDownLatch.countDown();
};
// 配置 Disputor 用于处理事件
DISRUPTOR.handleEventsWith(postsApiHandler, commentsApiHandler, albumsApiHandler)
.handleEventsWithWorkerPool(photosApiHandler1, photosApiHandler2)
.thenHandleEventsWithWorkerPool(postsAndCommentsResponseHandler1, postsAndCommentsResponseHandler2)
.handleEventsWithWorkerPool(albumsAndPhotosResponseHandler1, albumsAndPhotosResponseHandler2);
DISRUPTOR.start();
}
// 对于每个请求,在 RingBuffer 中发布一个事件:
Event event = null;
RingBuffer<Event> ringBuffer = DISRUPTOR.getRingBuffer();
long sequence = ringBuffer.next();
CountDownLatch countDownLatch = new CountDownLatch(6);
try {
event = ringBuffer.get(sequence);
event.countDownLatch = countDownLatch;
event.startTime = System.currentTimeMillis();
} finally {
ringBuffer.publish(sequence);
}
try {
event.countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
10. Akka

-
Akka 库的主要优势在于它拥有构建分布式系统的本地支持。
-
它运行在一个叫做 Actor System 的系统上。这个系统抽象了线程的概念,Actor System 中的 Actor 通过异步消息进行通信,这类似于生产者和消费者之间的通信。
-
这种额外的抽象级别有助于 Actor System 提供诸如容错、位置透明等特性。
-
使用正确的 Actor-to-Thread 策略,可以对该框架进行优化,使其性能优于上表所示的结果。 虽然它不能在单个节点上与传统方法的性能匹敌,但是由于其构建分布式和弹性系统的能力,仍然是首选。
10.1 示例代码
// 来自 controller :
Actors.masterActor.tell(new Master.Request("Get Response", event, Actors.workerActor), ActorRef.noSender());
// handler :
public Receive createReceive() {
return receiveBuilder().match(Request.class, request -> {
Event event = request.event; // Ideally, immutable data structures should be used here.
request.worker.tell(new JsonServiceWorker.Request("posts", event), getSelf());
request.worker.tell(new JsonServiceWorker.Request("comments", event), getSelf());
request.worker.tell(new JsonServiceWorker.Request("albums", event), getSelf());
request.worker.tell(new JsonServiceWorker.Request("photos", event), getSelf());
}).match(Event.class, e -> {
if (e.posts != null && e.comments != null & e.albums != null & e.photos != null) {
int userId = new Random().nextInt(10) + 1;
String postsAndCommentsOfRandomUser = ResponseUtil.getPostsAndCommentsOfRandomUser(userId, e.posts,
e.comments);
String albumsAndPhotosOfRandomUser = ResponseUtil.getAlbumsAndPhotosOfRandomUser(userId, e.albums,
e.photos);
String response = postsAndCommentsOfRandomUser + albumsAndPhotosOfRandomUser;
e.response = response;
e.countDownLatch.countDown();
}
}).build();
}
11. 总结
-
根据机器的负载决定 Executor 框架的配置,并检查是否可以根据应用程序中并行任务的数量进行负载平衡。
-
对于大多数传统应用程序来说,使用响应式开发库或任何异步库都会降低性能。只有当用例类似于服务器端聊天应用程序时,这个模式才有用,其中线程在客户机响应之前不需要保留连接。
-
Disruptor 框架在与事件驱动的架构模式一起使用时性能很好; 但是当 Disruptor 模式与传统架构混合使用时,就我们在这里讨论的用例而言,它并不符合标准。 这里需要注意的是,Akka 和 Disruptor 库值得单独写一篇文章,介绍如何使用它们来实现事件驱动的架构模式。
正文到此结束
- 本文标签: java https sql 多线程 json src Service 线程同步 spring struct cat API DOM build 处理器 分布式系统 部署 ip 进程 IDE Disruptor 同步 queue 分布式 rand node 线程 数据 CTO 总结 kk id 并发 tab 数据库 UI back-pressure final 文章 Master Reactor 测试 tar 配置 响应式 锁 ACE IO CountDownLatch 服务器 map 时间 开发 http executor zip js NOSQL 代码 list ask ioc ArrayList
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

