Kubernetes架构为什么是这样的?
小编序:
在上周发布的 《从“鸿沟理论”看云原生,哪些技术能够跨越鸿沟?》 一文中,灵雀云CTO陈恺表示:Kubernetes在云计算领域已经成为既定标准,进入主流市场,最新版本主要关注在稳定性、可扩展性方面,在开发人员中变得非常流行。Kubernetes会越来越多往下管理所有基础设施,往上管理所有种类的应用。我们会看到,越来越多的周边技术向它靠拢,在其之上催化出一个庞大的云原生技术生态。
那么,现在最新最流行的 Kubernetes 架构是什么样子呢?本文给大家介绍一下 Kubernetes 整体架构,并深入探讨其中 2 个比较关键的问题。
Kubernetes 架构解析
首先,Kubernetes 的官方架构图是这样的:
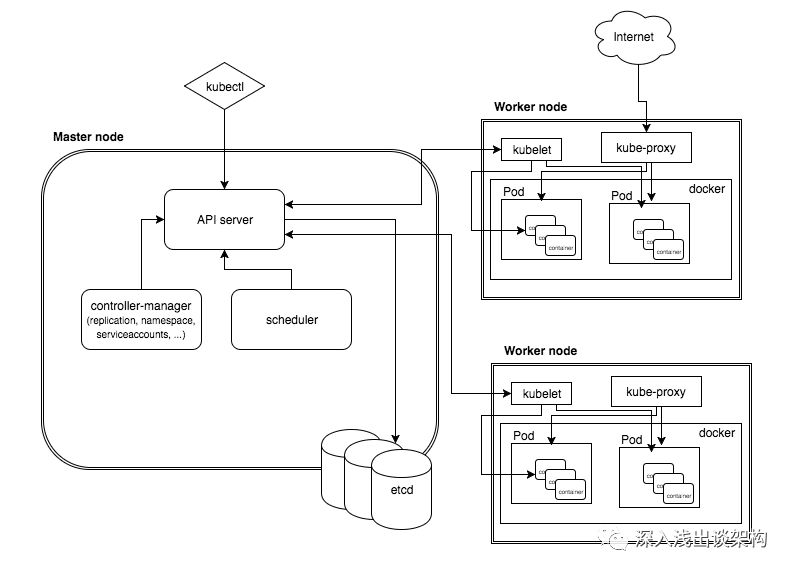
这个架构图看起来会比较复杂,很难看懂,我把这个官方的架构图重新简化了一下,就会非常容易理解了:
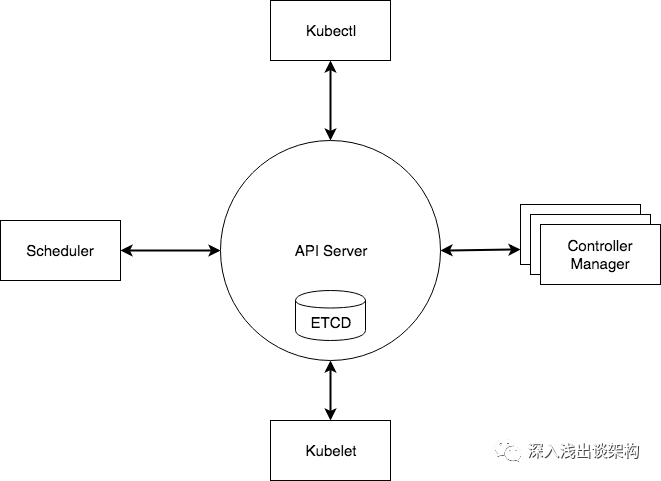
ETCD :是用来存储所有 Kubernetes 的集群状态的,它除了具备状态存储的功能,还有事件监听和订阅、Leader选举的功能,所谓事件监听和订阅,各个其他组件通信,都并不是互相调用 API 来完成的,而是把状态写入 ETCD(相当于写入一个消息),其他组件通过监听 ETCD 的状态的的变化(相当于订阅消息),然后做后续的处理,然后再一次把更新的数据写入 ETCD。所谓 Leader 选举,其它一些组件比如 Scheduler,为了做实现高可用,通过 ETCD 从多个(通常是3个)实例里面选举出来一个做Master,其他都是Standby。
API Server:刚才说了 ETCD 是整个系统的最核心,所有组件之间通信都需要通过 ETCD,实际上,他们并不是直接访问 ETCD,而是访问一个代理,这个代理是通过标准的RESTFul API,重新封装了对 ETCD 接口调用,除此之外,这个代理还实现了一些附加功能,比如身份的认证、缓存等。这个代理就是 API Server。
Controller Manager:是实现任务调度的,关于任务调度可以参考之前的文章,简单说,直接请求 Kubernetes 做调度的都是任务,比如 Deployment 、Deamon Set 或者 Job,每一个任务请求发送给Kubernetes之后,都是由Controller Manager来处理的,每一个任务类型对应一个Controller Manager,比如 Deployment对应一个叫做 Deployment Controller,DaemonSet 对应一个 DaemonSet Controller。
Scheduler:是用来做资源调度的,Controller Manager会把任务对资源要求,其实就是Pod,写入到ETCD里面,Scheduler监听到有新的资源需要调度(新的Pod),就会根据整个集群的状态,给Pod分配到具体的节点上。
Kubelet:是一个Agent,运行在每一个节点上,它会监听ETCD中的Pod信息,发现有分配给它所在节点的Pod需要运行,就在节点上运行相应的Pod,并且把状态更新回到ETCD。
Kubectl: 是一个命令行工具,它会调用 API Server发送请求写入状态到ETCD,或者查询ETCD的状态。
如果还觉得不清楚,我们就用部署服务的例子来解释一下整个过程。假设要运行一个多实例的Nginx,在Kubernetes内部,整个流程是这样的:
1.通过kubectl命令行,创建一个包含Nginx的Deployment对象,kubectl会调用 API Server 往ETCD里面写入一个 Deployment对象。
2.Deployment Controller 监听到有新的 Deployment对象被写入,就获取到对象信息,根据对象信息来做任务调度,创建对应的 Replica Set 对象。
3.Replica Set Controller监听到有新的对象被创建,也读取到对象信息来做任务调度,创建对应的Pod来。
4.Scheduler 监听到有新的 Pod 被创建,读取到Pod对象信息,根据集群状态将Pod调度到某一个节点上,然后更新Pod(内部操作是将Pod和节点绑定)。
5.Kubelet 监听到当前的节点被指定了新的Pod,就根据对象信息运行Pod。
这就是 Kubernetes 内部如何实现整个 Deployment 被创建的过程。这个过程只是为了向大家解释每一个组件的职责,以及他们之间是如何相互协作的,忽略掉了一些繁琐的细节。
目前为止,我们有已经研究过几个非常有代表性的调度系统:Hadoop MRv1、YARN、Mesos和Kubernetes。当时学习完这些调度系统的架构后,脑子里面形成2个大大的疑问:
1.Kubernetes是二次调度的架构么?和Mesos相比它的扩展性如何?
2.为什么所有调度系统都是无法横向扩展的?
后面我们就针对这两个问题深入讨论一下。
Kubernetes 是否是二层调度?
在 Google 的一篇关于内部 Omega 调度系统的论文中,将调度系统分成三类:单体、二层调度和共享状态三种,按照它的分类方法,通常Google的 Borg被分到单体这一类,Mesos被当做二层调度,而Google自己的Omega被当做第三类“共享状态”。
论文的作者实际上之前也是Mesos的设计者之一,后来去了Google设计新的 Omega 系统,并发表了论文,论文的主要目的是提出一种全新的“Shard State”的模式,来同时解决调度系统的性能和扩展性问题。但我觉得 Shared State 模型太过理想化,根据这个模型开发的Omega系统,似乎在Google内部并没有被大规模使用,也没有任何一个大规模使用的调度系统采用 Shared State 模型。
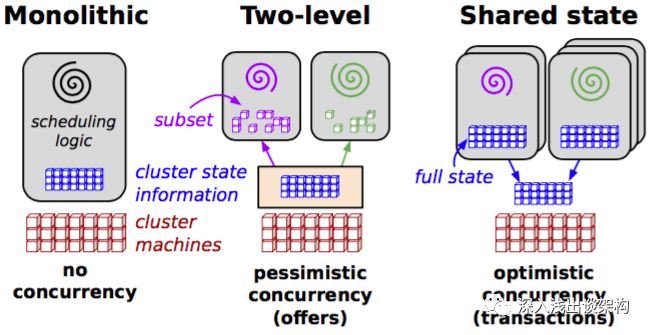
因为Kubernetes的大部分设计是延续 Borg的,而且 Kubernetes 的核心组件(Controller Manager和Scheduler)缺省也都是绑定部署在一起,状态也都是存储在ETCD里面的,所以通常大家会把Kubernetes也当做“单体”调度系统,实际上我并不赞同。
我认为 Kubernetes 的调度模型也完全是二层调度的,和 Mesos 一样,任务调度和资源的调度是完全分离的,Controller Manager承担任务调度的职责,而Scheduler则承担资源调度的职责。
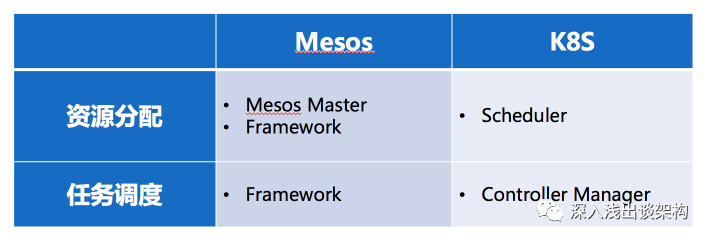
实际上Kubernetes和Mesos调度的最大区别在于资源调度请求的方式:
主动 Push 方式。是 Mesos 采用的方式,就是 Mesos 的资源调度组件(Mesos Master)主动推送资源 Offer 给 Framework,Framework 不能主动请求资源,只能根据 Offer 的信息来决定接受或者拒绝。
被动 Pull 方式。是 Kubernetes 的方式,资源调度组件 Scheduler 被动的响应 Controller Manager的资源请求。
这两种方式带来的不同,我主要从一下 5 个方面来分析。另外注意,我所比较两者的优劣,都是从理论上做的分析,工程实现上会有差异,一些指标我也并没有实际测试过。
1.资源利用率:Kubernetes 胜出
理论上,Kubernetes 应该能实现更加高效的集群资源利用率,原因资源调度的职责完全是由Scheduler一个组件来完成的,它有充足的信息能够从全局来调配资源,然后而Mesos 却做不到,因为资源调度的职责被切分到Framework和Mesos Master两个组件上,Framework 在挑选 Offer 的时候,完全没有其他 Framework 工作负载的信息,所以也不可能做出最优的决策。
举个例子,比如我们希望把对耗费 CPU的工作负载和耗费内存的工作负载尽可能调度到同一台主机上,在Mesos里面不太容易做到,因为他们分属不同的 Framework。
2.扩展性:Mesos胜出
从理论上讲,Mesos 的扩展性要更好一点。原因是Mesos的资源调度方式更容易让已经存在的任务调度迁移上来。举个例子,假设已经有了一个任务调度系统,比如 Spark,现在要迁移到集群调度平台上,理论上它迁移到 Mesos 比 Kubernetes 上更加容易。
如果迁移到 Mesos ,没有改变原来的工作流程和逻辑,原来的逻辑是:来了一个作业请求,调度系统把任务拆分成小的任务,然后从资源池里面挑选一个节点来运行任务,并且记录挑选的节点 IP 和端口号,用来跟踪任务的状态。迁移到 Mesos 之后,还是一样的逻辑,唯一需要变化的是那个资源池,原来是自己管理的资源池,现在变成 Mesos 提供的Offer 列表。
如果迁移到 Kubernetes,则需要修改原来的基本逻辑来适配 Kubernetes,资源的调度完全需要调用外部的组件来完成,并且这个变成异步的。
3.灵活的任务调度策略:Mesos 胜出
Mesos 对各种任务的调度策略也支持的更好。举个例子,如果某一个作业,需要 All or Nothing 的策略,Mesos 是能够实现的,但是 Kubernetes 完全无法支持。所以All or Nothing 的意思是,价格整个作业如果需要运行 10 个任务,这 10个任务需要能够全部有资源开始执行,否则就一个都不执行。
4.性能:Mesos 胜出
Mesos 的性能应该更好,因为资源调度组件,也就是 Mesos Master 把一部分资源调度的工作甩给 Framework了,承担的调度工作更加简单,从数据来看也是这样,在多年之前 Twitter 自己的 Mesos 集群就能够管理超过 8万个节点,而 Kubernetes 1.3 只能支持 5千个节点。
5.调度延迟: Kubernetes 胜出
Kubernetes调度延迟会更好。因为Mesos的轮流给Framework提供Offer机制,导致会浪费很多时间在给不需要资源的 Framework 提供Offer。
为什么不支持横向扩展?
可能大家已经注意到了,几乎所有的集群调度系统都无法横向扩展(Scale Out),比如早期的 Hadoop MRv1 的管理节点是单节点,管理的集群上限是 5000 台机器,YARN 资源管理节点同时也只能有一个节点工作,其他都是备份节点,能够管理的机器的上限1万个节点,Mesos通过优化,一个集群能够管理 8 万个节点,Kubernetes 目前的 1.13 版本,集群管理节点的上限是 5000 个节点。
所有的集群调度系统的架构都是无法横向扩展的,如果需要管理更多的服务器,唯一的办法就是创建多个集群。集群调度系统的架构看起来都是这个样子的:
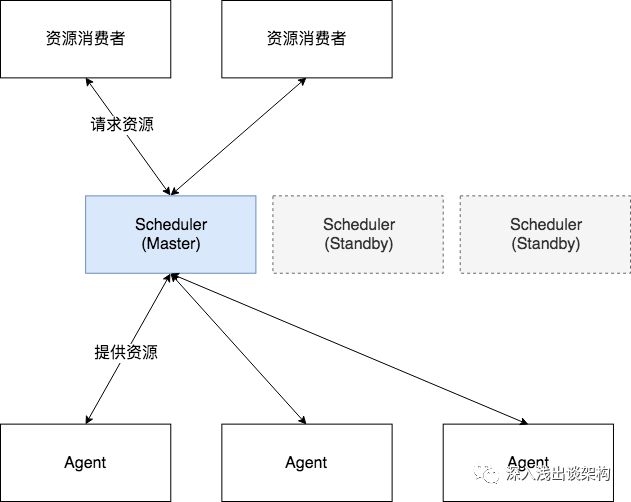
中间的 Scheduler(资源调度器)是最核心的组件,虽然通常是由多个(通常是3个)实例组成,但是都是单活的,也就是说只有一个节点工作,其他节点都处于 Standby 的状态。为什么会这样呢?看起来不符合互联网应用的架构设计原则,现在大部分互联网的应用通过一些分布式的技术,能够很容易的实现横向扩展,比如电商应用,促销时,通过往集群里面添加服务器,就能够提升服务的吞吐量。如果是按照互联网应用的架构,看起来应该是这样的:
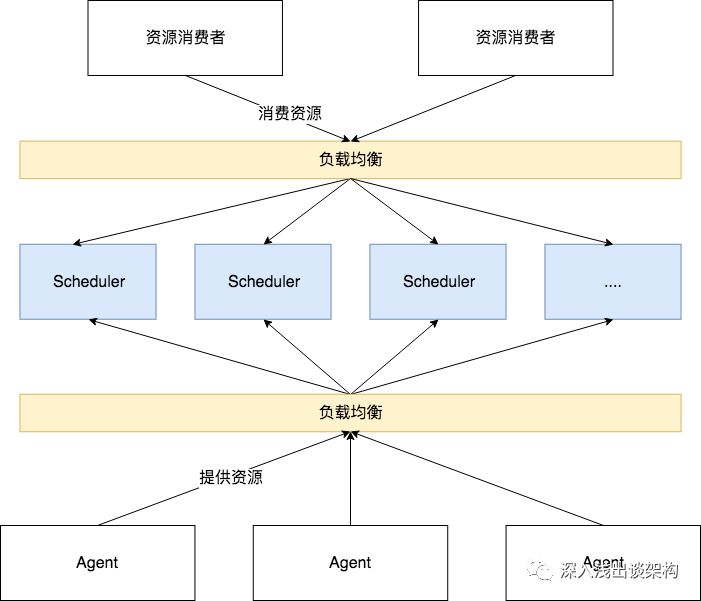
Scheduler 应该是可以多活的,有任意多的实例一起对外提供服务,无论是资源的消费者,还是资源的提供者在访问 Scheduler 的时候,都需要经过一个负载均衡的组件或者设备,负责把请求分配给某一个 Scheduler 实例。为什么这种架构在集群调度系统里面变得不可行么?为了理解这件事情,我们先通过一个互联网应用的架构的例子,来探讨一下具备横向扩展需要哪些前提条件。
横向扩展架构的前提条件
假设我们要实现这样一个电商系统:
1.这是一个二手书的交易平台,有非常多的卖家在平台上提供二手书,我们暂且把每一本二手书叫做库存;
2.卖家的每一个二手书库存,根据书的条码,都可以找到图书目录中一本书,我们把这本书叫做商品;
3.卖家在录入二手书库存的时候,除了录入是属于哪一个商品,同时还需要录入其他信息,比如新旧程度、价钱、发货地址等等。
4.买家浏览图书目录,选中一本书,然后下单,订单系统根据买家的要求(价格偏好、送货地址等),用算法从这本书背后的所有二手书库存中,匹配一本符合要求的书完成匹配,我们把这个过程叫订单匹配好了。
这样一个系统,从模型上看这个电商系统和集群调度系统没啥区别,这个里面有资源提供者(卖家),提供某种资源(二手书),组成一个资源池(所有二手书),也有资源消费者(买家),提交自己对资源的需求,然后资源调度器(订单系统)根据算法自动匹配一个资源(一本二手书)。
但是很显然,这个电商系统是可以设计成横向扩展架构的,为什么呢?这个电商系统和集群调度系统的区别到底在什么地方? 在回答这个问题之前,我们先来回答另外一个问题:这个电商系统横向扩展的节点数是否有上限,上限是多少,这个上限是有什么因素决定的?
系统理论上的并发数量决定了横向扩展的节点数
假设系统架构设计的时候,不考虑任何物理限制(比如机器的资源大小,带宽等),能够并发处理 1000个请求,那么很显然,横向扩展的节点数量上限就是1000,因为就算部署了 1001个节点,在任何时候都有一个节点是处于空闲状态,部署更多的节点已经完全无法提高系统的性能。我们下面需要想清楚的问题其实就变成了:系统理论上能够并发处理请求的数量是多少,是有什么因素决定的。
系统的并发数量是由“独立资源池”的数量决定的
“独立资源池”是我自己造出来的一个词,因为实在想不到更加合适的。还是以上面的电商系统为例,这个订单系统的理论上能够处理的并发请求(订购商品请求)数量是由什么来决定的呢?先看下面的图:
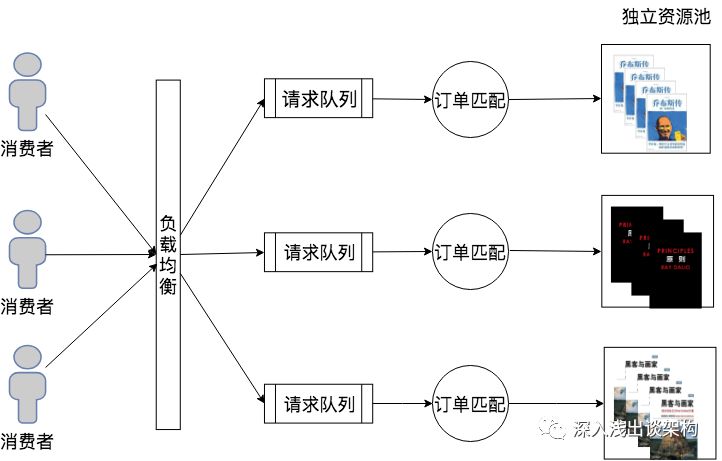
在订单系统在匹配需求的时候,实际上应该是这样运行的,在订单请求来了之后,根据订单请求中的购买的商品来排队,购买同一个商品的请求被放在一个队列里面,然后订单的调度系统开始从队列里面依次处理请求,每次做订单匹配的时候,都需根据当前商品的所有库存,从里面挑选一个最佳匹配的库存。
虽然在实现这个系统的时候,这个队列不见得是一个消息队列,可能会是一个关系型数据库的锁,比如一个购买《乔布斯传》的订单,系统在处理的时候需要先从所有库存里面查询出《乔布斯传》的库存,将库存记录锁住,并做订单匹配且更新库存(将生成订单的库存商品设置为”不可用”状态)之后,才会将数据库锁释放,这时候所有后续购买《乔布斯传》的订单请求都在队列中等待。
也有些系统在实现的时候采用“乐观锁”,就是每次订单处理时,并不会在一开始就锁住库存信息,而是在最后一步更新库存的时候才会锁住,如果发生两个订单匹配到了同一个库存物品,那么其中一个订单处理就需要完全放弃然后重试。这两种实现方式不太一样,但是本质都是相同的。
所以从上面的讨论可以看出来,之所以所有购买《乔布斯传》的订单需要排队处理,是因为每一次做订单匹配的时候,需要《乔布斯传》这个商品的所有库存信息,并且最后会修改(占用)一部分库存信息的状态。在该订单匹配的场景里面,我们就把《乔布斯传》的所有库存信息叫做一个“独立资源池”,订单匹配这个“调度系统”的最大并发数量就完全取决于独立资源池的数量,也就是商品的数量。我们假设一下,如果这个二手书的商城只卖《乔布斯传》一本书,那么最后所有的请求都需要排队,这个系统也几乎是无法横向扩展的。
集群调度系统的“独立资源池”数量是 1
我们再来看一下集群调度系统,每一台服务器节点都是一个资源,每当资源消费者请求资源的时候,调度系统用来做调度算法的“独立资源池”是多大呢?答案应该是整个集群的资源组成的资源池,没有办法在切分了,因为:
1.调度系统的职责就是要在全局内找到最优的资源匹配。
2.另外,哪怕不需要找到最优的资源匹配,资源调度器对每一次资源请求,也没办法判断应该从哪一部分资源池中挑选资源。
正是因为这个原因,“独立资源池”数量是 1,所以集群调度系统无法做到横向扩展。
原文 http://dockone.io/article/8696正文到此结束
- 本文标签: 认证 数据库 API 消息队列 http 希望 缓存 测试 RESTful 实例 主机 IO 回答 服务器 负载均衡 管理 解析 src Twitter 架构设计 备份 https 数据 Kubernetes Uber 调度器 本质 Nginx ip UI CTO Job 模型 目录 db 系统架构 时间 锁 任务调度 高可用 部署 云 端口 集群 需求 开发 订单处理 分布式 并发 Hadoop 互联网 Google REST 文章 Master Agent
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

