Spring Cloud之Finchley版学习(二十五)-Spring Cloud Sleuth与Zipkin配合使用
一个良好的监控,应该有一个人类亲和的界面,这个界面就是Zipkin。本文详细讨论Sleuth如何与Zipkin配合使用。
Zipin简介
Zipkin是Twitter开源的分布式跟踪系统,基于Dapper的论文设计而来。它的主要功能是收集系统的时序数据,从而追踪微服务架构的系统延时等问题。Zipkin还提供了一个非常友好的界面,帮助我们分析追踪数据。
TIPS
Zipkin官方网站: http://zipkin.io/
Zipkin Server搭建
- 使用 https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec 下载最新版本的Zipkin Server,例如
zipkin-server-2.11.3-exec.jar - 启动Zipkin Server
java -jar zipkin-server-2.11.7-exec.jar
- 访问
http://localhost:9411即可看到Zipkin Server的首页。
Zipkin UI
Zipkin UI首页:
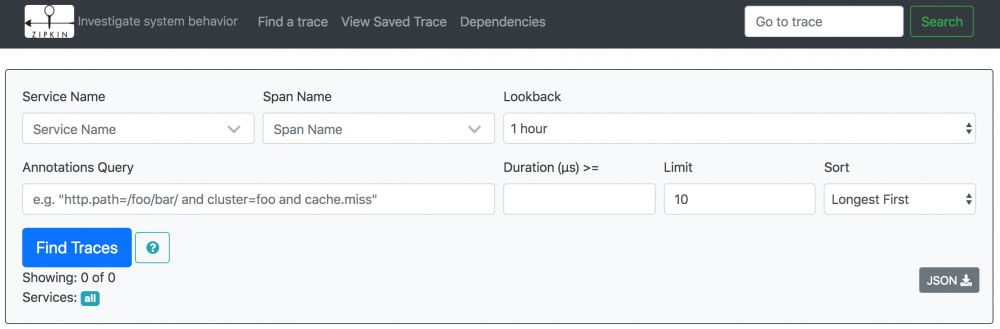
简单讲解图中各个查询条件的含义:
① Service Name表示服务名称,也就是各个微服务spring.application.name的值。
② 第二列表示span的名称,“all”表示所有span,也可选择指定span。
③ Lookback用于执行想要查看的之间段。
④ Duration表示持续时间,即span从创建到关闭所经历的时间。
⑤ Limit表示查询几条数据。类似于MySQL数据库中的limit关键词。
⑥ Annotations Query,用于自定义查询条件。
微服务整合Zipkin
在 Spring Cloud之Finchley版学习(二十四)-Spring Cloud Sleuth入门 的基础上:
- 加依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin</artifactId> </dependency>
- 加配置
spring:
zipkin:
base-url: http://localhost:9411
sleuth:
sampler:
# 采样率,模式0.1,也就是10%,为了便于观察效果,改为1.0,也就是100%。生产环境建议保持默认。
probability: 1.0
测试
- 启动微服务,访问
http://localhost:8000/users/1 - 观察
http://localhost:9411,可看到类似如下界面: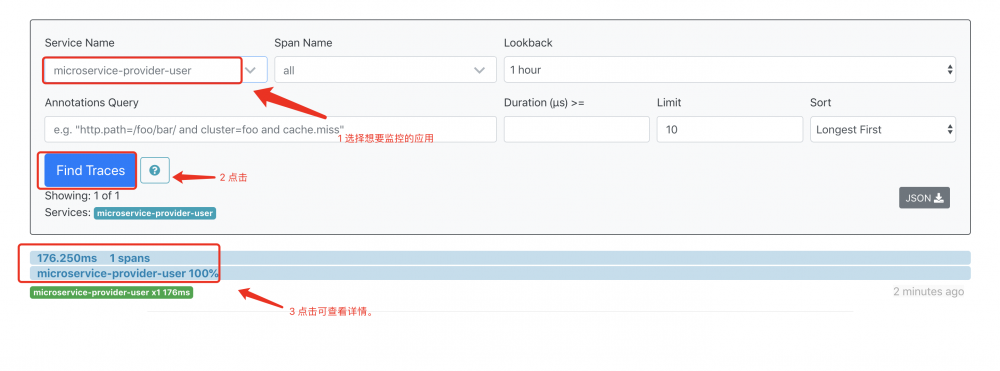
- 点击上图中标注的3,可看到类似如下的界面:
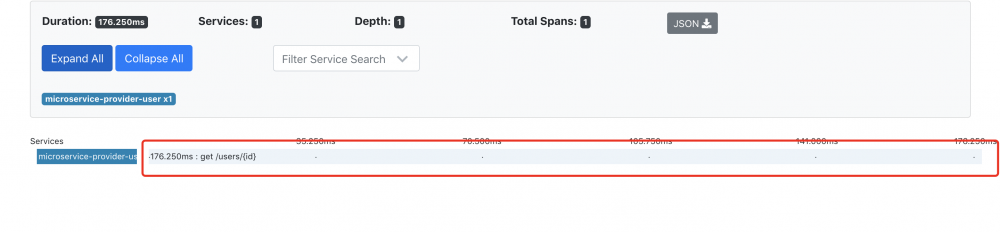
如图,已经展示了该次请求的耗时。如果你有多个应用,Zipkin将会展示每个应用消耗了多少时间,蓝色表示请求正常,红色表示请求失败。
配套代码
- GitHub: https://github.com/eacdy/spring-cloud-study/tree/master/2018-Finchley/microservice-provider-user-sleuth-zipkin
- Gitee: https://gitee.com/itmuch/spring-cloud-study/tree/master/2018-Finchley/microservice-provider-user-sleuth-zipkin
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

