走进 JDK 之 Byte
整理一下前面几篇文章,按顺序阅读效果更好。
走进 JDK 之 Integer
走进 JDK 之 Long
走进 JDK 之 Float
今天来说说 Byte 。
类声明
public final class Byte extends Number implements Comparable<Byte> 复制代码
和之前的一模一样,不可变类,继承了抽象类 Number ,实现了 Comparable 接口。
字段
private final byte value; // 包装的 byte 值
public static final byte MIN_VALUE = -128; // 最小值是 -128
public static final byte MAX_VALUE = 127; // 最大值是 127
public static final Class<Byte> TYPE = (Class<Byte>) Class.getPrimitiveClass("byte");
public static final int SIZE = 8; // byte 占 8 bits
public static final int BYTES = SIZE / Byte.SIZE; // byte 占一个字节
private static final long serialVersionUID = -7183698231559129828L;
复制代码
都是很熟悉的属性,不再过多分析了。这里提第一个问题,为什么最大值是 127 ,最小值是 -128 ,最小值的绝对值可以比最大值的绝对值大 1 呢 ?这里先不说,看完代码再来解答。
构造函数
public Byte(byte value) {
this.value = value;
}
public Byte(String s) throws NumberFormatException {
this.value = parseByte(s, 10);
}
复制代码
两个构造函数。第一个传入 byte 直接给 value 赋值,第二个传入字符串,调用 parseByte() 方法转换为 byte 。
方法
parseByte()
public static byte parseByte(String s, int radix)
throws NumberFormatException {
int i = Integer.parseInt(s, radix);
if (i < MIN_VALUE || i > MAX_VALUE)
throw new NumberFormatException(
"Value out of range. Value:/"" + s + "/" Radix:" + radix);
return (byte)i;
}
复制代码
调用 Integer.parseInt() 方法转换为 int ,再强转 byte 。 Integer.parseInt() 详细解析见走进 JDK 之 Integer 。不光是 parseInt() 方法, Byte.java 中还有好几个地方都是当做 int 来处理,后面的分析中将会看到。
这里再提一个问题, 作为方法内部局部变量的 byte 在内存中占几个字节 ?
valueOf()
public static Byte valueOf(String s, int radix)
throws NumberFormatException {
return valueOf(parseByte(s, radix));
}
public static Byte valueOf(byte b) {
final int offset = 128;
return ByteCache.cache[(int)b + offset];
}
复制代码
再来看一下 ByteCache :
private static class ByteCache {
private ByteCache(){}
static final Byte cache[] = new Byte[-(-128) + 127 + 1];
static {
for(int i = 0; i < cache.length; i++)
cache[i] = new Byte((byte)(i - 128));
}
}
复制代码
同样也是缓存了 -128 到 127 ,也就是说缓存了 byte 的所有可取值。
toString()
public String toString() {
return Integer.toString((int)value);
}
复制代码
toString() 方法直接调用了 Integer.toString() 。
其他的确没啥好说的了, Byte 类源码比较简单,认真度过 Integer 源码的同学,大概浏览一下就有数了。后面来回答一下前面提问的两个问题。
为什么 Byte 最小值的绝对值比最大值的绝对值大 1 呢 ?
其实不光是 Byte ,Java 的所以基本整数类型都是这样(当然不包括 char ) :
| 基本类型 | 最大值 | 最小值 |
|---|---|---|
| byte | 127 | -128 |
| short | 2 15 -1 | - 2 15 |
| int | 2 31 -1 | 2 31 |
| long | 2 63 -1 | -2 63 |
可以看到取值范围都是不对称的,负数的范围比正数的范围都大 1 。解释这个问题之前,先来看几个基本概念:
例如 -8 ,其原码是 1000 1000 ,反码是 1111 0111 ,补码是 1111 1000 。那么计算机中到底存储的是哪种形式呢?这就要涉及到减法运算了。相比减法运算,计算机是更乐意做加法运算的,如果遇到 1 - 8 这道题目,它就会想我计算 1 + (-8) 不是一个道理吗,最好我还能不把符号位当符号位,一起作加法,还能提高一点运算效率。那么,负数的加法运算怎么做的,我们来尝试一下。
首先,我们按原码计算:
1 + (-8) = (0000 0001)(原) + (1000 1000)(原) = (1000 1001)(原) = -9 复制代码
显然不正确。再看反码:
1 + (-8) = (0000 0001)(反) + (1111 0111)(反) = (1111 1000)(反) = (1000 0111)(原) = -7 复制代码
好像没什么毛病,计算结果很正确。再换个例子看看:
1 + (-1) = (0000 0001)(反) + (1111 1110)(反) = (1111 1111)(反) = (1000 0000)(原) = -0 复制代码
上篇文章解析Float 时说过,浮点数是区分 +0.0 和 -0.0 的。但是整数的 0 是没有正负之分的,用反码没法解决 -0 的问题。最后来看一下补码运算是否会存在 -0 :
1 + (-1) = (0000 0001)(补) + (1111 1111)(补) = (0000 0000)(补) = (0000 0000)(原) = 0 复制代码
通过进位把符号位的 1 给溢出了,从而避免产生了 -0 。
综上所述,补码是比较适合在计算机中来表示整数的,实际上大多数计算机也正是这么做的。再回到这个 -0 ,二进制表示为 1000 0000 ,总不能把它丢掉吧,多点表示范围总是好的,就把它定为了 -128 ,并且它没有反码,也没有补码,它就是 -128 。
现在我们知道了 -128 其实就是替代了 -0 的存在。再来说一个知识点,你会更加直观的了解 -128 。如何快速的将补码转换为十进制数?其实不论正数还是负数,补码二进制转换为我们熟悉的十进制都遵循相同的规律。看看下面几个转换:
15 = (0000 1111)(补)
= - 0*2^8 + (1*2^3 + 1*2^2 + 1*2^1 +1*2^0)
= 0 + 8 + 4 + 2 + 1
-15 = (1111 0001)(补)
= - 1*2^8 + (1*2^6 + 1*2^5 + 1*2^4 +1*2^0)
= -128 + 64 + 32 + 16 + 1
复制代码
不需要转换为源码,直接按补码计算。正数符号位表示为 0 ,负数符号位表示为 -128 。显而易见,最小的负数肯定是 10000 0000 = -128 + 0 + 0 + ... 。现在你应该对个问题很清楚了吧。下面看第二个问题:
作为方法内部局部变量的 byte 在内存中占几个字节 ?
乍看之下我在问一个废话, byte 那不肯定是 1 个字节吗 !没错, byte 是一个字节,但是我这个问题有特定的条件, 作为方法内部局部变量的 byte 。我们通常所说的 byte 占一个字节,指的是如果在 java 堆上分配一个 byte ,那么就是一个字节。同理, int 就是四个字节。那么, 方法内的局部变量 是存储在堆上的吗?显然不是的,它是存储在栈中的。如果不理解的话,我们先来回顾一下 Java 的运行时数据区域。
Java 的运行时数据区包含一下几块:
- 程序计数器:当前线程所执行的字节码的行号指示器
- Java 虚拟机栈:描述的是 Java 方法执行的内存模型
- 本地方法栈:为 native 方法服务
- Java 堆:所有的对象实例以及数组都在这里分配
- 方法区:存储已被虚拟机加载的类信息、常量、静态常量、即时编译器编译后的代码等数据
- 运行时常量池:方法区的一部分,存放编译期生成的各种字面量和符号引用
我们通常所说的栈就是指 Java 虚拟机栈。每一个线程都有自己的 Java 虚拟机栈,用于存储栈帧。栈帧是用于支持虚拟机进行方法调用和方法执行的数据结构。每个方法在执行的同时都会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行完成的过程,就对应一个栈帧在虚拟机栈中入栈到出栈的过程。所以, 方法内的局部变量 byte 不出意外应该就是存储在局部变量中了。那么,局部变量表的结构又是怎么样的呢?
局部变量表是一组变量值存储空间,用于存放方法参数和方法内部定义的变量。在 Java 程序编译 Class 文件时,就在方法的 Code 属性的 max_locals 数据项中确定了该方法所需分配的局部变量表的最大容量。在我之前一篇文章Class 文件格式详解 中,详细解析了 Class 文件结构,我们再来回顾一下它的 main() 方法的 Code 属性:
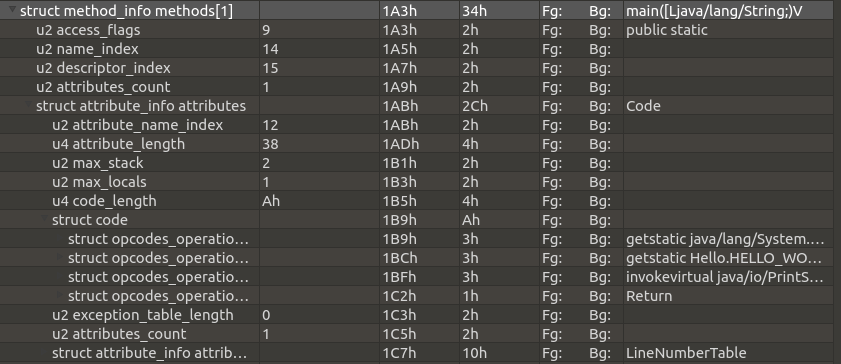
max_stack 代表了操作数栈深度的最大值。在方法执行的任意时刻,操作数栈都不会超过这个深度。虚拟机运行的时候需要根据这个值来分配栈帧中的操作栈深度。
max_locals 代表了局部变量表所需的存储空间,以 slot 为单位。Slot 是虚拟机为局部变量分配内存所使用的最小单位。简而言之,栈帧就是一个 Slot[] ,利用下标来访问数组元素。那么,对于不同的数据类型是如何处理的呢?这里就是典型的以空间换时间。除了 long 和 double 占用两个 Slot 以外,其他基本类型 boolean 、 byte 、 char 、 short 、 int 、 float 等都占用一个 Slot 。这样就而已快速的利用下标索引来进行定位了。所以,在局部变量表中, byte 和 int 占用的内存是一样的。
总结
Byte 源码没有说的很多,很多方法都是直接调用 Integer 类的方法。后面主要说了两个知识点:
- 补码表示法更加利用运算,把减法当加法算,且可以多表示一个
-128,也就是1000 0000 - 基本类型作为方法局部变量是存储在栈帧上的,除了
long和double占两个Slot,其他都占用一个Slot
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

