那些年挖过的SRC之我是捡漏王
*本文原创作者:zhukaiang7,本文属于FreeBuf原创奖励计划,未经许可禁止转载
前言
输出这篇文章的目的也是为了好多人在挖洞时,看到别的大佬钱拿的不要不要的时候,只能在我们自己自己电脑面前一筹莫展,这篇文章也是为了带大家打开新的思路。
俗话说得好,“不是你套路不够深,是你的基础不够扎实。”
第一步:选择一条不拥挤的道路
现在类似于漏洞盒子,补天这种平台企业SRC的开展,同时伴随着各个公司私有SRC挨个上线,我们可以讲目光聚焦到他们身上。
基础不扎实,如SQL注入,XSS,上传,稍微大一点的厂商,一个WAF就打死了一群工具小子,这里我暂且不谈,直接放弃,来选择扫描器无法的发现漏洞。
如果想挖洞赚钱,只有2条路:
1.客户端漏洞
这样的漏洞挖掘竞争的人会比常见web漏洞和主机端口漏洞少不少。
2.子域名下漏洞
主要讲的是一些边缘业务或者是刚上线的业务。
第二步:信息收集
老生常谈的一个东西了,举个简单的例子,像一些用户比较多的软件,一旦出现漏洞,影响的用户量是相当巨大的。
比如struts漏洞,这些框架漏洞也出了很久了吧,还是有人喜欢用它。
不管你去谷歌还是bing然后采集一波该特征的URL,扔到这个批量验证工具里面,仍然存在大把的ip存在struts命令执行漏洞。
这就是信息收集的成功因素的之一,更何况,现在还有钟馗之眼,傻蛋,fofa这些平台API的开放,无时无刻不在帮我们做着信息收集的工作,让我们多了一把更锋利的武器。
以上是废话,我们不赘诉了。
再谈谈SRC,举个简单的例子,SRC他们在平台上只声明了大致方向,只要属于他们的业务漏洞都收。
那么我们如何定位呢。
我的思路:
1.他的域名对应的真实IP,对应的C段,甚至B段; 2.他的子域名; 3.其他平台(如hackerone)。
如:
https://hackerone.com/alibaba
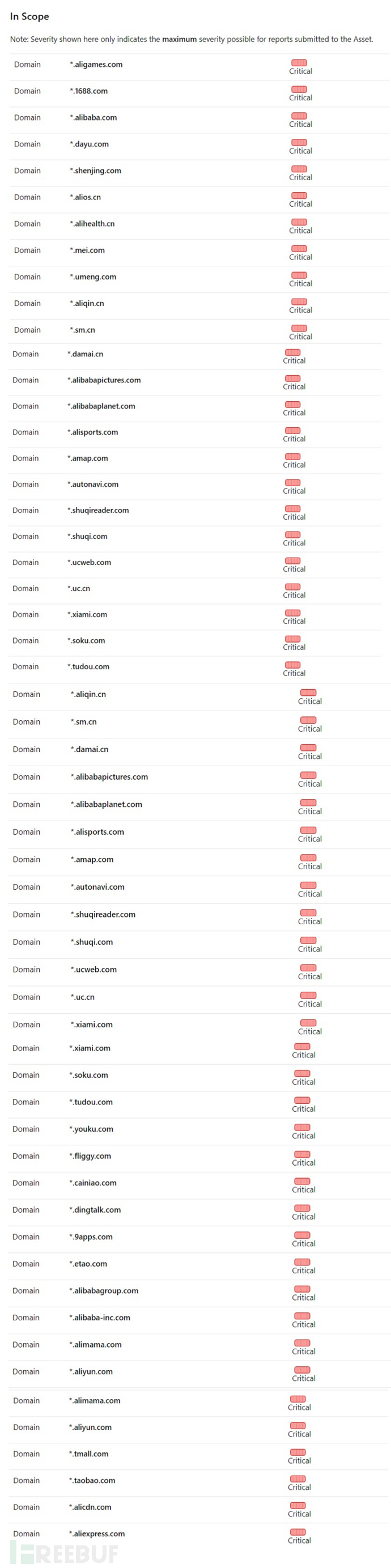
梦寐以求的目标范围,只要去国外的漏洞网站就能轻轻松松看到。惊不惊喜,意不意外?
查找子域名的文章太多太多,这里也不讲太多了。
当然也可以收集QQ群,微信讨论组,暗网的信息然后去提交威胁情报。
第三步:局部性挖掘
这里就针对目标SRC的资产做一个收集。
以补天的专属为例:
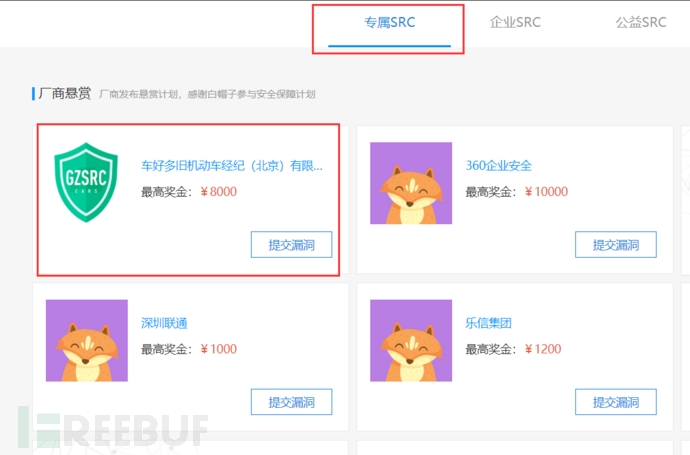
给了我们非常少的范围:

我们先whois查询一下:
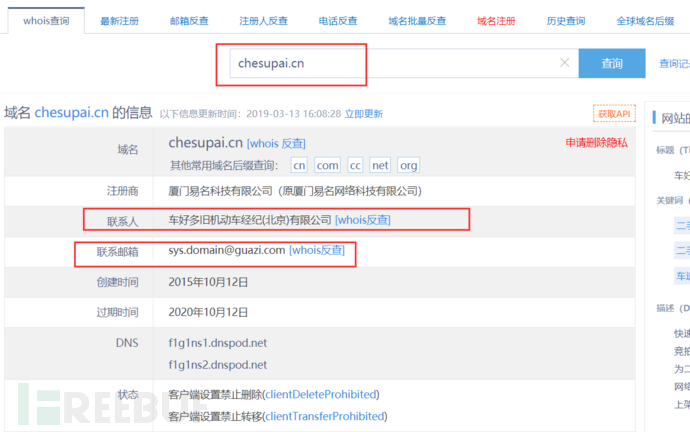
然后反查:
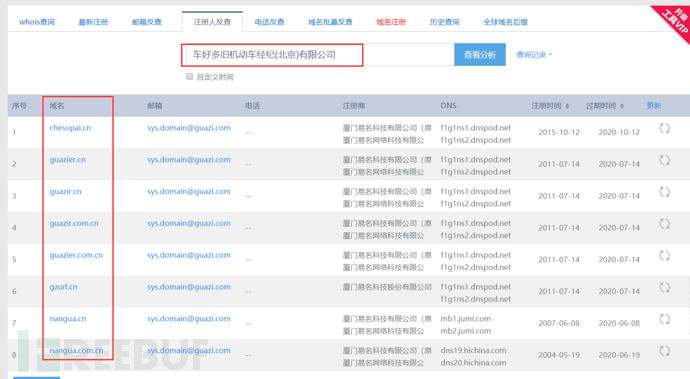
查到该公司对应的域名。
这里可以收集顶级域名,然后通过子域名挖掘工具获取二级及三级域名。
李姐姐的神器: https://github.com/lijiejie/subDomainsBrute
高并发DNS暴力枚举,发现其他工具无法探测到的域名:
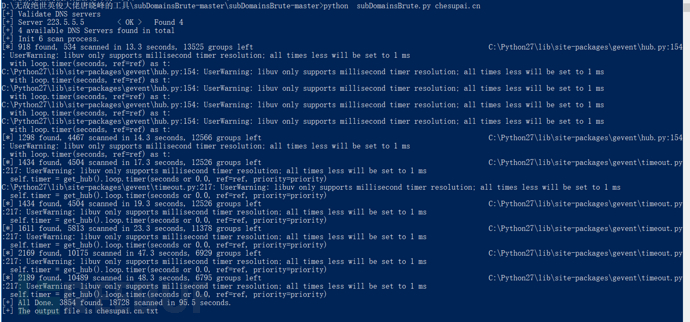 效果:
效果:
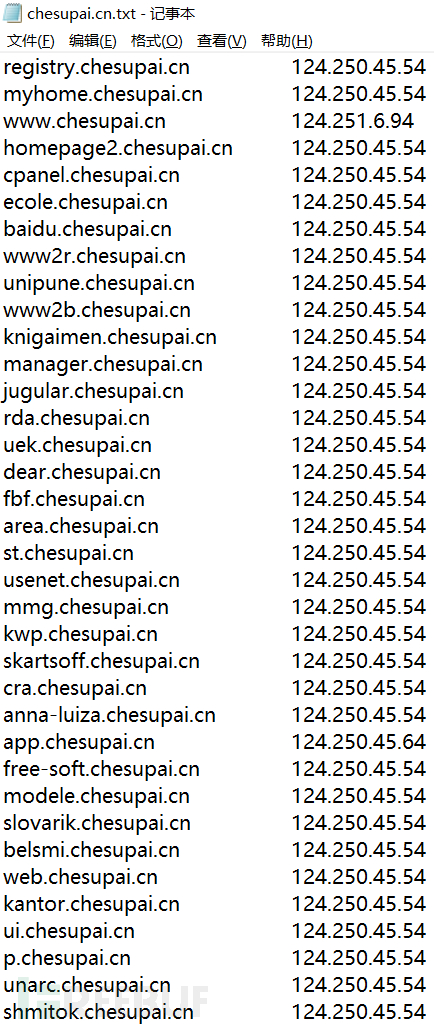
或者在线版的:
https://phpinfo.me/domain/
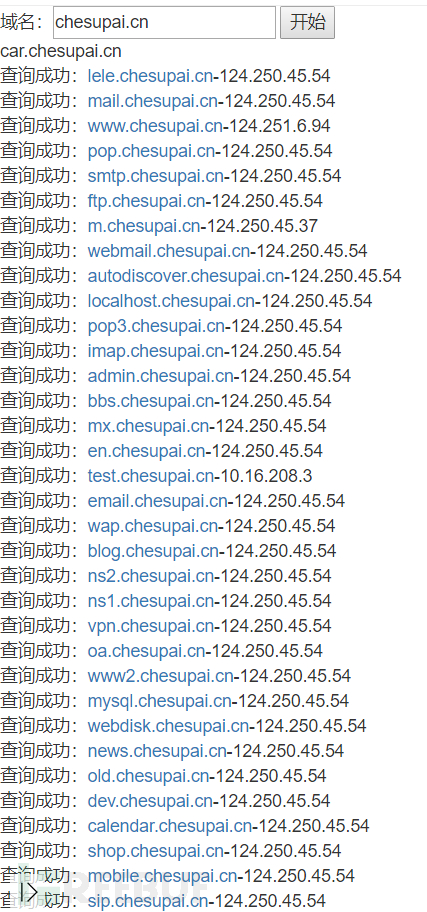 利用下面的脚本处理结果:
利用下面的脚本处理结果:
#coding=utf8
import re
import os
def getlist():
filename = raw_input('filename')
print filename
ft = open("url.txt",'w+')
with open(str(filename), 'r') as f:
lines = [line.strip() for line in f.readlines()]
for x in lines:
lists=x.split('-')
result = lists[1]
ft.write(result+'/n')
print result
getlist()
print 'done'
删除重复项:
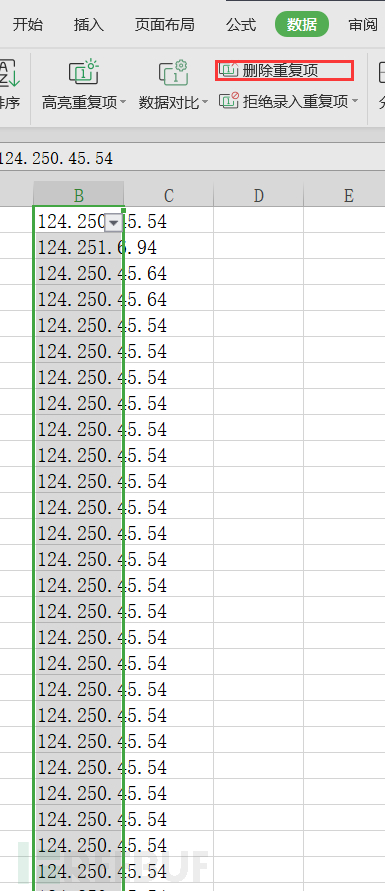 上面2个方法分别导出的结果如下图所示:
上面2个方法分别导出的结果如下图所示:
 这里就回答了好多人经常问我的,为啥子域名挖掘工具要用那么多,因为你用的越多,你收集的越全面。
这里就回答了好多人经常问我的,为啥子域名挖掘工具要用那么多,因为你用的越多,你收集的越全面。
大部分大公司基本都是整个C段买下来,这里因为这里的目标使用的是代理商,所以我没有跑C段,不然资产可以爆炸多,包大家挖洞挖到眼泪流下来。
第三步:处理收集到的信息
把筛选出来的ip保存到url.txt,然后使⽤nmap命令将结果输出为.gnmp⽂件:
nmap -sS -p 80,443,8080 -Pn -iL url.txt -oA [绝对路径]
我用的命令是:
nmap -sS -O -sV -iL url.txt -p 80,8080,443 -v -T4 -Pn -oA C:/Users/Administrator.DESKTOP-0MHPHKA/Desktop/result
再使用python转化为xsl格式:
#coding:utf8
import sys
log = open("result.gnmap","r")
xls = open("output.csv","a")
xls.write("IP,port,status,protocol,service,version/n")
for line in log.readlines():
if line.startswith("#") or line.endswith("Status: Up/n"):
continue
result = line.split(" ")
#print result
host = result[0].split(" ")[1]
#print host
port_info = result[1].split("/, ")
#print port_info
port_info[0] = port_info[0].strip("Ports: ")
#print port_info[0]
for i in port_info:
j = i.split("/")
#print j
output = host + "," + j[0] + "," + j[1] + "," + j[2] + ","+ j[4] + "," + j[6] + "/n"
xls.write(output)
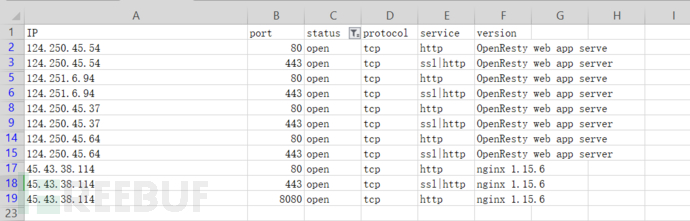
然后本地搭建一个php环境,写一个url跳转代码:
<?php
$url = $_GET['url'];
Header("Location:$url");
?>
抓包:
GET /url.php?url= http://1.1.1.1:80 HTTP/1.1
Host: 127.0.0.1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Connection: close
Upgrade-Insecure-Requests: 1
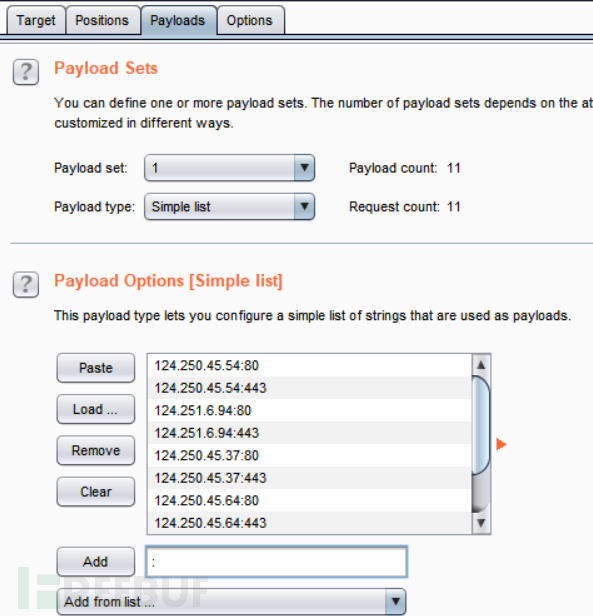
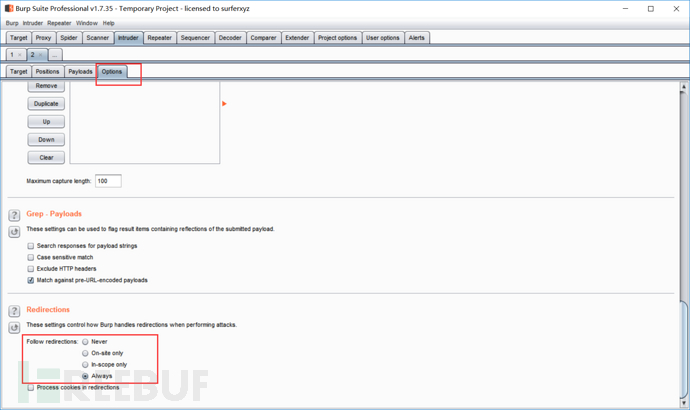
burpsuite跑结果:
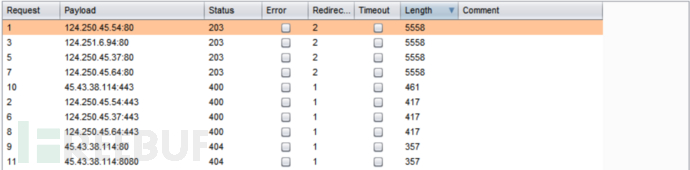
全文不涉及敏感信息,就不打码了。
第四步:结束语
献给所有在挖洞道路走的越来越远的兄弟们。
本文脚本已全部上传 github 。

文章参考:
https://mp.weixin.qq.com/s/yl1LgC_DHPJtaWh92va_Vw
https://blog.csdn.net/qq_21405949/article/details/78487062
*本文原创作者:zhukaiang7,本文属于FreeBuf原创奖励计划,未经许可禁止转载
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

