面试问你为什么要用Spring怎么答?
相信每个读者在工作中,学习中都了解Spring怎么使用,对于一个初级的开发工程师来说,仅仅了解怎么使用,能够很快的通过Spring来完成任务,这应该是足够了,但是呢,如果你还想向更高的级别去前进,系统的学习,掌握它的底层原理是必不可少的。

每个人在面试的时候,Spring应该都是逃不过的关卡,能够熟练的使用,这并不难,知道它的底层原理才是高出别人一步的地方。这篇文章就说简单说下Spring的一些知识,希望能在面试的路上帮助到你们。
Spring是个开源框架,它被创建出来的初衷就是解决企业级应用开发的复杂性。Spring不仅仅局限于服务端开发,任何的java应用都能借助于Spring变得更加简单,可测试性更强,松耦合性更好。
为了降低Java开发的复杂性,Spring采取了一下4种关键策略:
-
基于POJO的轻量级和最小侵入性编程;
-
通过依赖注入和面向接口实现松耦合;
-
基于切面和惯例进行声明式编程;
-
通过切面和模板减少样板式代码。
几乎Spring所做的任何事情,都是围绕着以上四种策略来实现的,其核心就是:简化java开发。 复制代码
1、轻量级POJO
在日常的开发过程中,可能大部分人都感受到了,很多框架都会强迫应用继承他们的类或者是实现他们的接口,这样就会导致程序和框架绑死,说到这,我们的现在所用的框架就是这样,各个模块,包括DAO,Service,都会强制性的继承框架的中的类,应用程序和框架绑定的死死的。Spring竭力的避免因为自身的API来搞乱你的应用代码,Spring也不会强迫你实现他的接口或者是继承它的类,最严重的也就是一个雷会使用Spring注解。Spring的非侵入式编程意味着这个类在Spring应用和非Spring应用中发挥着同样的作用。
2、依赖注入
任何一个有实际意义的应用,肯定是会有多个类组成,在没有Spring的时候,每个对象负责管理着与自己相互协作的对象的引用,这样会导致高耦合和难以测试的代码。
public class Train implements Transport{
private Water water;
public Train() {
water = new Water();
}
public void catchGoods(){
water.waterSomthing();
}
}
复制代码
可以看到上面的代码,Train在自己的构造函数中自己创建了 Water对象,这样就造成了这两个对象的紧耦合,这个火车可以运水来浇灌农田,但是如果让这个火车来运煤供暖,可能就不太符合了。
而在单元测试的时候,我们要确保catchGoods方法执行的时候,waterSomthing也能够执行,如果这样来做,那就执行不了单元测试了。
耦合是具有两面性的,一方面紧密的耦合的代码,难以测试,难以服用,难以理解,修改了一处就可能会引起别的bug(记得刚去公司的时候,讲开发规范,一个接口尽量的只做一件事情,千万不要一个接口同时为多个地方提供服务),另一方面呢完全没有耦合的代码也什么都干不了。
有了Spring之后,对象的依赖关系由负责协调各对象的第三方组件来完成,对象无需自行创建,依赖注入会将所依赖的关系自动交给目标对象,而不是让对象自己去获取。
public class Train implements Transport{
private Water water;
public Train(Water water) {
this.water = water;
}
public void catchGoods(){
water.waterSomthing();
}
}
复制代码
上面在我们的改动之后,不再由Train自行创建,而是当成一个构造器参数传进来,这也是依赖注入的一种方式:构造器注入。这也就实现了松耦合。
创建应用组件之间协作的行为通常称为装配,Spring有着多种装配bean的方式,XML就是一种常用的方式。
<?xml version="1.0" encoding="UTF-8"?>
<!--DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN" "http://www.springframework.org/dtd/spring-beans.dtd" -->
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="train" class="com.kr.caption.spring.Train">
<constructor-arg ref="water"/>
</bean>
<bean id="water" class="com.kr.caption.spring.Water"/>
</beans>
复制代码
在上面的xml文件中,两个对象被声明为了Spring中的bean,在Train中,在构造时传入了对Water的引用,作为构造器参数。
@Configuration
public class TrainConfig {
@Bean
public Transport train(){
return new Train(water());
}
@Bean
public Water water(){
return new Water();
}
}
复制代码
上面的是基于java的配置,这两种配置都是一样的效果。
Spring通过应用的上下文,来装载bean的定义,并把他们组装起来,Spring应用上下文全权负责对象的创建和组装,Spring有多种上下文的实现,它们之间主要的区别仅仅在于如何加载配置。
public class application {
public static void main(String[] args) {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("classpath:application_example.xml");
Train bean = context.getBean(Train.class);
bean.catchGoods();
}
}
复制代码
这里的main方法基于application_example.xml创建了一个Spring应用上下文,随后就能得到一个实例对象,直接调用方法即可。
3、面向切面编程
系统由不同的组件组成,而这些组件除了实现自身的核心功能外,还承担着其他的一些职责。比如日志、事务管理和安全这些通常会贯穿着整个项目中的各个组件。如果没有系统性的处理这部分,那么你的代码会含有大量的重复代码。如果你把这些单独抽象为一个模块,其他模块只是调用它的方法,方法的调用还是会出现各个模块。
AOP会使这些服务模块化,以声明的方式应用到它们需要影响的模块去,这样其他的模块就会只关注它们自身的业务,完全不需要了解这些服务的相关逻辑和代码。
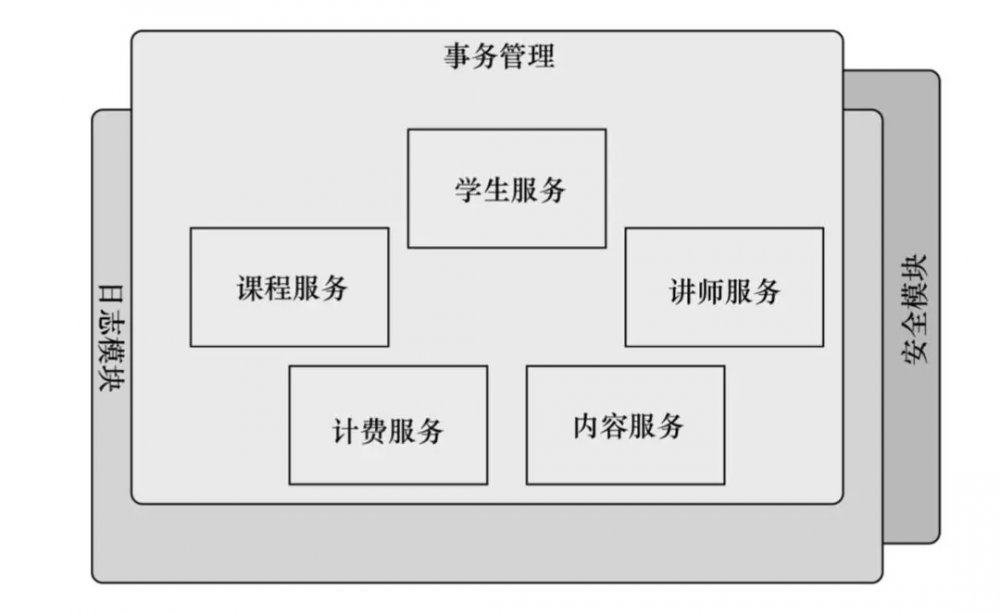
看到上面的图片,我们可以把切面想象为覆盖在很多组件上的一个外壳,借助AOP可以使那些功能层去包裹核心业务层,这些功能层以声明的方式灵活的应用到系统中,其他的业务应用根本不知道它的存在。
写在最后
这里没有太多的花言巧语,如果本文对你有所帮助,希望点击下面的二维码关注一波,或者是朋友圈分享一下,点个好看也是棒棒的。
这样的分享我会一直持续,你的关注、转发和好看是对我最大的支持,感谢。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

