智能扩展:成功使用云原生技术扩展基础架构的4个关键技巧
作者:Reda Benzair
今天的帖子来自CNCF大使兼Streamroot工程副总裁Reda Benzair。文章最初在Streamroot技术开发者的博客上发布。
在这篇文章中,我想与工程经理和后端团队分享一些高级别的要点,以帮助他们成功扩展业务,同时避免一些最常见的陷阱和短视决策。
本文伴随Streamroot首席后端工程师Jordan Pittier发布的第一篇文章,以及我们去年11月在HighLoad Moscow的历程演讲。这些分享了我们在从基于VM的架构迁移到基于容器的架构,以及将我们的基础架构迁移到运行在Google Cloud上的Kubernetes的整个过程中所面临的经验和挑战。
介绍和背景
首先,我将向你介绍Streamroot的一些背景知识,以及为什么我们花时间调整我们的Kubernetes Engine架构,不仅要扩展规模,还要使我们的架构更具容错性。
Streamroot是一家为主要内容所有者提供服务的技术供应商 - 媒体集团、电视网络和视频平台。我们的点对点视频传输解决方案为广播者提供了更高的质量和更低的成本,并与现有的CDN基础设施协同工作。
去年我们(以及我们客户)面临的最大挑战之一是扩大到FIFA世界杯的破纪录的观众。事实证明,2018年世界杯是有史以来规模最大的直播赛事,Akamai在峰值时的记录的速度为22 Tbps,超过了之前超级碗记录的两倍。Akamai测量的峰值量超过22 Tbps。这是他们在2014年看到的峰值的3倍。
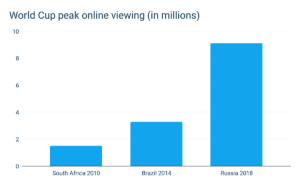
Streamroot为法国最大的私人广播公司TF1,以及南美洲的国家电视网络提供了世界杯。为了能够以这种规模为我们的客户服务,我们需要扩展我们自己的Kubernetes引擎并能够更快地扩展。我们需要:
- 处理大量流量,每分钟有数十万个请求到我们的后端
- 在每届世界杯比赛开始时,在几分钟内达到巨大的峰值
- 确保100%防故障、完全容错、坚固的后端能够承受任何故障。作为一名体育爱好者,我知道在现场直播期间甚至有两分钟的停机时间是完全不可接受的...
最后但并非最不重要的是,我们必须通过只有少数后端工程师的创业规模团队完成所有这些工作...
如果你对我们过去几个月的扩展历程感兴趣,并希望深入了解技术细节,你可以在Jordan Pittier和Nikolay Rodionov在莫斯科举行的HighLoad++会议 演讲 ,以及我们的 幻灯片 中查看。
技巧#1:新事物并不总是好事:使用云原生技术轻装上阵。
自加入云原生计算基金会(CNCF)以来,Kubernetes已呈指数级增长,对这一复杂解决方案的兴趣日益浓厚,这是一种开源云原生技术的组合。去年12月,CNCF的KubeCon + CloudNativeCon在西雅图集合了来自世界各地的8000多名与会者。
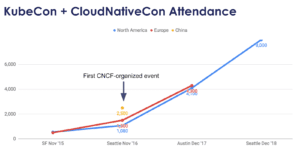
Kubernetes是云原生技术组件之一。还存在许多其他组件,有一些在CNCF托管( https://landscape.cncf.io/ ),有一些在CNCF之外,如Istio。
云原生技术还很年轻,每月在不同领域涌现出各种新组件:存储、安全性、服务发现、软件包管理等。
我们的建议:谨慎使用这些新组件,并保持简单(、傻瓜)。这些技术是新的,有时仍然比较粗糙,并以令人难以置信的速度发展。尝试使用所有最新的闪亮技术是没有意义的,特别是在生产中,除非这些技术是出于真正的需要。即使你拥有庞大的优秀工程师团队,你也需要考虑维护、运营和调试这些有时缺乏稳定性的新技术的成本(资源和时间)。
作为经理和CNCF大使,我建议遵循CNCF分类( https://www.cncf.io/projects/ )来选择具有足够成熟度级别的原生组件。CNCF定义的标准包括采用率、寿命以及是否可以依赖开源项目来构建生产工具。今天,Streamroot只利用了3个项目(Kubernetes、Prometheus和Envoy),这些项目处于成熟水平,并根据CNCF基金会已经“毕业”。那里的大量组件仍处于孵化阶段或沙箱阶段。你仍然可以使用这些,但请记住,你将面临一些风险:稳定性、错误、有限的社区、学习曲线等。
最重要的是,要明白,即使可能普遍相信孵化或沙箱阶段的所有原生项目都可以填补空白并成熟生产,但这也需要考虑不会增加架构复杂性的问题。在从CNCF或CNCF外部添加任何新组件之前,请务必先问自己以下事项:
- 我真的需要这个组件吗?
- 我在解决一个真正的基础设施问题吗?
- 我的工程师现在和从长远来看能够应付它吗?

图:CNCF分类
技巧#2:控制你的成本
当启动一个重要的项目,比如将服务从基于VM的服务,转移到Kubernetes支持的基于容器的体系结构时,你的主要关注点可能不是成本,而是成功迁移。虽然你的后端成本可能不是一个即时或中期的问题,但从第一天开始就要考虑到这一点。我强烈建议你尽早跟踪Kubernetes Engine扩展成本,原因如下:
- 清楚地了解你的资源使用情况和软件效率。后端团队的主要关注点是交付,从管理角度来看,通常很难传达高效软件和资源使用的重要性。
- 在你的架构中发现改进的空间。对来自监控和成本进展的信息进行三角测量,有助于我们确定架构的改进。通过简单地使我们的实例适应我们的使用,并更好地了解资源的使用和消耗方式,我们能够将成本降低22%。
- 利用基于数量的成本节约。大多数云供应商(包括Google Cloud和Amazon AWS)都会为提交的实例提供有趣的折扣。不要犹豫,为你的利益使用基础设施成本核算(和减少)。一旦达到一定的支出,即使降低10%的成本,也可以在预算中增加几千甚至几十万美元,这可以用来派遣你的团队参加会议,甚至可以雇用一个新资源来构建你的产品更快!
为了说明我的第三点,GCP提供持续使用折扣选项,为长期承诺的实例提供显着折扣。例如,如果你承诺一整年的资源,你可以获得30%的折扣(就只一次,实际上很高兴在月底看到账单!)。这些折扣最高可达57%(!),为期3年。当然,我建议在承诺任何内容之前至少等待6个月,以便确定你最少使用的平均CPU和RAM资源。
别怕!你无需成为公司财务或计费方面的专家即可有效跟踪你的成本。例如,如果你希望跟踪每月使用情况,则可以默认为每个项目启用费用提醒,然后使用CSV导出功能输入你喜欢的电子表格工具。或者,在GCP上,你可以启用Bigquery Billing Export选项,以便每日导出资源消耗的所有详细信息。然后,花几分钟时间构建一个带有SQL导出或Excel的简单仪表板(不要忘记让工程师正确设置资源标签以识别不同的行)。

技巧#3:隔离并保持你的生产安全
许多博客和文章建议你仅使用一个K8群集,但为不同的环境使用不同的命名空间(例如,Dev、Staging和Production)。命名空间是一个非常强大的功能,可以帮助你组织Kubernetes资源并提高团队的速度。但是这种设置并不容易:你需要确保有一个完善的CI/CD环境,以避免你的staging和prod环境之间的任何干扰,以及像部署错误组件在错误的命名空间中的“愚蠢”错误。读到这篇文章时,你可能会想:“当然,但我们有一个超级聪明的团队,所以我们能够处理它。”在那里停一停:每个人都犯愚蠢的错误,错误越愚蠢,它会发生的机会越多...所以,除非你想要在生产中救火过最紧张的日子,只因为你在那里推动了一个Staging版本,如果使用命名空间的选项,你必须花几周的时间建立一个顶级的CI/CD工作流程。
在我们这边,我们选择了另一个选项来保持我们的环境分离:我们决定为我们的登台(Staging)和生产环境创建完全自治的集群。这消除了人为错误和安全性故障传播的所有风险,因为两个集群都是完全隔离的。这种方法的缺点是它会增加你的固定成本:你需要更多的计算机来保持两个集群的正常运行。但它带来的安全和安心对我们来说是非常值得的。
此外,你可以通过使用GCP的短暂实例来降低成本开销,这比普通实例便宜80%。当然,这有一个问题:如果Google Cloud需要其他客户,那么这些实例可能会随时关闭。但是当我们仅将它们用于我们的临时环境时,丢失一台机器并不会真正影响我们,我们甚至学会了利用它来发挥我们的优势。对我们来说,完美的测试是看看我们的架构如何对我们的一个组件的随机故障作出反应:一种完全不可预测的红队试图摧毁系统,由Google Cloud免费提供给你
技巧#4:从一开始就统一并自动化你的工作流程
当你开始一个新项目时,你考虑的最后一件事是如何与其他开发者共享代码,或者在需要执行紧急回滚时如何在生产和Staging之间推送构建。这是正常而且非常明智:在你真正构建了可以向世界展示的任何东西之前,没有必要进行过度优化。但另一方面,让这些问题潜伏在永恒中是一个常见的错误。因为你没有时间,需要发布下一个功能,使你的产品最终跨越鸿沟并神奇地带来数百万用户。我对此的建议是花时间尽早创建一个简单有效的工作流程。
首先,一旦你开始与其他人合作,你应该退后一步,创建一个统一且易于转移的开发环境。10年前,这不是一件容易的事:你需要在每个人的计算机上配置特殊虚拟机,或者在Mac和Windows用户之间进行修改。这是一场真正的噩梦,并引发了许多不必要的和调试不了的问题。今天,多得了像Docker这样的容器化工具,它可以在不到几天的时间内完成,那么为什么不从一开始就实现呢?这将大大简化所有开发者的生活,并使新员工的入职变得简单直接。对于你将节省的所有调试和设置周数来说,这是一笔非常小的投资。
其次,一旦你有生产流量,就应该考虑创建一个简单但有效的QA/CI/CD工作流程。不需要过早设计过度,但我们非常幸运地生活在自动化和CI工具的黄金时代,这使你可以毫无困难地实现自动化的一流CI和CD。符合kubernetes API的CI工具列表很长,例如10.1版GitLab引入了与Kubernetes或Jenkins X的集成。大多数公司为小规模项目提供低成本计划,并为开源项目提供免费计划,所以你真的没有任何借口不使用它们!这不是火箭科学,它将为你节省时间、精力和无数头痛,让你的开发者的生活更轻松!
总结一下
Kubernetes和云原生提供了出色的技术,可以简化和支持在云上构建可扩展且灵活的解决方案。不久之后,我们将Kubernetes视为云技术中无处不在的一部分,就像我们现在使用Linux和TCP/IP等技术。
由于我们成功地迁移到这些服务,我们能够将我们的基础设施持续扩展到世界杯观众及其他人。在历史上规模最大的体育赛事中,我们提供超过1.2 Tbps的流量,零停机时间 - 所有这一切都只有两名后端工程师。我们现在能够处理数百万观众的视频流,峰值每秒有数万个新请求到达。
归功我在本文中讨论过的最佳实践,我们不仅能够从架构、成本和资源角度实现我们的短期交付目标,还能实现基础架构的长期可扩展性。总结我们的主要内容:
- 当工具符合实际需要时,请小心谨慎地使用Kubernetes和云原生。
- 今天就想想未来,无论是成本、分离环境还是实施自动化工作流程。从第一天开始就把这些挑战有效地融入你的项目中,当这些考虑成为关键任务时,你将浪费更少的时间资源进行调整。
作为一家初创公司,我们一直在努力不断改进我们的技术和工作流程,并且在我们的扩展过程中学到的所有经验教训之后,我们期待着应对下一个挑战:构建多云架构!
KubeCon + CloudNativeCon + Open Source Summit大会日期:
- 会议日程通告日期:2019 年 4 月 10 日
- 会议活动举办日期:2019 年 6 月 24 至 26 日
正文到此结束
- 本文标签: 基金 代码 Docker Amazon 黄金时代 2019 测试 CDN 配置 Google 实例 文章 部署 root https sql API google cloud 开源 博客 tag 云 git 安全 管理 Kubernetes 总结 http stream linux ip 开源项目 智能 开发 运营 工程师 质量 集群 调试 空间 软件 src 希望 jenkins 产品 开发者 TCP 组织 投资 IO 自动化 创业 UI 时间 Excel Uber 免费 windows
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

