Dubbo源码分析(九)负载均衡算法
当我们的Dubbo应用出现多个服务提供者时,服务消费者如何选择哪一个来调用呢?这就涉及到负载均衡算法。
LoadBalance 中文意思为负载均衡,它的职责是将网络请求,或者其他形式的负载“均摊”到不同的机器上。避免集群中部分服务器压力过大,而另一些服务器比较空闲的情况。通过负载均衡,可以让每台服务器获取到适合自己处理能力的负载。在为高负载服务器分流的同时,还可以避免资源浪费,一举两得。
Dubbo中提供了4种负载均衡实现:
-
基于权重随机算法的 RandomLoadBalance
-
基于最少活跃调用数算法的 LeastActiveLoadBalance
-
基于 hash 一致性的 ConsistentHashLoadBalance
-
基于加权轮询算法的 RoundRobinLoadBalance
一、LoadBalance
在Dubbo中,所有的负载均衡实现类都继承自抽象类 AbstractLoadBalance ,该类实现 LoadBalance 接口。
@SPI(RandomLoadBalance.NAME)
public interface LoadBalance {
/**
* select one invoker in list.
*
* @param invokers invokers.
* @param url refer url
* @param invocation invocation.
* @return selected invoker.
*/
@Adaptive("loadbalance")
<T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException;
}
复制代码
可以看到,该接口的SPI注解指定了默认的实现 RandomLoadBalance ,不过不着急,我们先看看抽象类的逻辑。
1、选择服务
我们先来看负载均衡的入口方法 select,它逻辑比较简单。校验服务提供者是否为空;如果 invokers 列表中仅有一个 Invoker,直接返回即可,无需进行负载均衡;有多个Invoker就调用子类实现进行负载均衡。
public <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) {
if (invokers == null || invokers.isEmpty())
return null;
//如果只有一个服务提供者,直接返回,无需负载均衡
if (invokers.size() == 1)
return invokers.get(0);
return doSelect(invokers, url, invocation);
}
复制代码
2、获取权重
这里包含两个逻辑,一个是获取配置的权重值,默认为100;另一个是根据服务运行时长重新计算权重。
protected int getWeight(Invoker<?> invoker, Invocation invocation) {
//获取权重值,默认为100
int weight = invoker.getUrl().getMethodParameter(invocation.getMethodName(), "weight",100);
if (weight > 0) {
//服务提供者启动时间戳
long timestamp = invoker.getUrl().getParameter("remote.timestamp", 0L);
if (timestamp > 0L) {
//当前时间-启动时间=运行时长
int uptime = (int) (System.currentTimeMillis() - timestamp);
//获取服务预热时间 默认10分钟
int warmup = invoker.getUrl().getParameter("warmup", 600000 );
//如果服务运行时间小于预热时间,即服务启动未到达10分钟
if (uptime > 0 && uptime < warmup) {
//重新计算服务权重
weight = calculateWarmupWeight(uptime, warmup, weight);
}
}
}
return weight;
}
复制代码
如上代码,获取服务权重值。然后判断服务启动时长是否小于服务预热时间,然后重新计算权重。服务预热时间默认是10分钟。大致流程如下:
- 获取配置的权重值,默认为100
- 获取服务启动的时间戳
- 当前时间 - 服务启动时间 = 服务运行时长
- 获取服务预热时间,默认为10分钟
- 判断服务运行时长是否小于预热时间,条件成立则重新计算权重
重新计算权重其实就是降权的过程。
static int calculateWarmupWeight(int uptime, int warmup, int weight) {
int ww = (int) ((float) uptime / ((float) warmup / (float) weight));
return ww < 1 ? 1 : (ww > weight ? weight : ww);
}
复制代码
代码看起来很简单,但却不大好理解。我们可以把上面的代码换成下面的公式来看: uptime / warmup) * weight ,即进度百分比*权重。
假设我们把权重设置为100,预热时间为10分钟。那么:
| 运行时长 | 公式 | 计算后权重 |
|---|---|---|
| 1分钟 | 1/10 * 100 | 10 |
| 2分钟 | 2/10 * 100 | 20 |
| 5分钟 | 5/10 * 100 | 50 |
| 10分钟 | 10/10 * 100 | 100 |
由此可见,在未达到服务预热时间之前,权重都被降级了。Dubbo为什么要这样做呢?
主要用于保证当服务运行时长小于服务预热时间时,对服务进行降权,避免让服务在启动之初就处于高负载状态。服务预热是一个优化手段,与此类似的还有 JVM 预热。主要目的是让服务启动后“低功率”运行一段时间,使其效率慢慢提升至最佳状态。
二、权重随机算法
RandomLoadBalance 是加权随机算法的具体实现,也是Dubbo中负载均衡算法默认的实现。这里我们需要先把服务器按照权重进行分区,比如:
假设有三台服务器:【A、B、C】 它们对应的权重为:【1、3、6】,总权重为10
那么,我们可以得出:
| 区间 | 所属服务器 |
|---|---|
| 0-1 | A |
| 1-4 | B |
| 4-10 | C |
剩下的就简单了,我们获取总权重totalWeight,然后生成[0-totalWeight]之间的随机数,计算随机数会落在哪个区间就好了。
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers,
URL url, Invocation invocation) {
//服务提供者列表数量
int length = invokers.size();
//总权重
int totalWeight = 0;
//是否具有相同的权重
boolean sameWeight = true;
//循环服务列表,计算总权重和检测每个服务权重是否相同
for (int i = 0; i < length; i++) {
//获取单个服务的权重值
int weight = getWeight(invokers.get(i), invocation);
//累加 计算总权重
totalWeight += weight;
//校验服务权重是否相同
if (sameWeight && i > 0
&& weight != getWeight(invokers.get(i - 1), invocation)) {
sameWeight = false;
}
}
if (totalWeight > 0 && !sameWeight) {
//获取[0-totalWeight]之间的随机数
int offset = random.nextInt(totalWeight);
//计算随机数处于哪个区间,返回对应invoker
for (int i = 0; i < length; i++) {
offset -= getWeight(invokers.get(i), invocation);
if (offset < 0) {
return invokers.get(i);
}
}
}
//如果权重相同,随机返回
return invokers.get(random.nextInt(length));
}
复制代码
我们以上面的例子,总结一下上面代码的流程:
- 获取服务提供者数量 = 3
- 累加,计算总权重 = 10
- 校验服务权重是否相等,不相等。依次为1、3、6
- 获取0 - 10直接的随机数,假设 offset = 6
- 第1次循环,6-=1>0,条件不成立,offset = 5
- 第2次循环,5-=3>0,条件不成立,offset = 2
- 第3次循环,2-=6<0,条件成立,返回第3组服务器
最后,如果权重都相同,直接随机返回一个服务Invoker。
三、最小活跃数算法
最小活跃数负载均衡算法对应LeastActiveLoadBalance。活跃调用数越小,表明该服务提供者效率越高,单位时间内可处理更多的请求,此时应优先将请求分配给该服务提供者。
Dubbo会为每个服务提供者Invoker分配一个active,代表活跃数大小。调用之前做自增操作,调用完成后做自减操作。这样有的服务处理的快,有的处理的慢。越快的,active数量越小,就优先分配。
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
//服务提供者列表数量
int length = invokers.size();
//默认的最小活跃数值
int leastActive = -1;
//最小活跃数invoker数量
int leastCount = 0;
//最小活跃数invoker索引
int[] leastIndexs = new int[length];
//总权重
int totalWeight = 0;
//第一个Invoker权重值 用于比较invoker直接的权重是否相同
int firstWeight = 0;
boolean sameWeight = true;
//循环比对Invoker的活跃数大小
for (int i = 0; i < length; i++) {
//获取当前Invoker对象
Invoker<T> invoker = invokers.get(i);
//获取活跃数大小
int active = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName()).getActive();
//获取权重值
int weight = invoker.getUrl().getMethodParameter(invocation.getMethodName(), "weight", 100);
//对比发现更小的活跃数,重置
if (leastActive == -1 || active < leastActive) {
//更新最小活跃数
leastActive = active;
//更新最小活跃数 数量为1
leastCount = 1;
//记录坐标
leastIndexs[0] = i;
totalWeight = weight;
firstWeight = weight;
sameWeight = true;
//如果当前Invoker的活跃数 与 最小活跃数相等
} else if (active == leastActive) {
leastIndexs[leastCount++] = i;
totalWeight += weight;
if (sameWeight && i > 0
&& weight != firstWeight) {
sameWeight = false;
}
}
}
//如果只有一个Invoker具有最小活跃数,直接返回即可
if (leastCount == 1) {
return invokers.get(leastIndexs[0]);
}
//多个Invoker具体相同的最小活跃数,但权重不同,就走权重的逻辑
if (!sameWeight && totalWeight > 0) {
int offsetWeight = random.nextInt(totalWeight);
for (int i = 0; i < leastCount; i++) {
int leastIndex = leastIndexs[i];
offsetWeight -= getWeight(invokers.get(leastIndex), invocation);
if (offsetWeight <= 0)
return invokers.get(leastIndex);
}
}
//从leastIndexs中随机获取一个返回
return invokers.get(leastIndexs[random.nextInt(leastCount)]);
}
复制代码
以上代码分为两部分。第一是通过比较,确定最小活跃数的Invoker;第二是根据权重确定Invoker。我们再分步骤总结一下:
-
定义变量-最小活跃数大小、数量、数组、权重值
-
循环invokers数组,获取当前Invoker活跃数大小和权重
-
比对当前Invoker的活跃数,是否比上一个小;条件成立则重置最小活跃数;如果相等,则累加权重值,并且判断权重是否相同
-
比对完成,如果只有一个最小活跃数,就直接返回Invoker
-
如果多个Invoker,具有相同的活跃数,但权重不同;就走权重的逻辑
-
如果以上两个条件都不成立,就在最小活跃数 数量范围内取得随机数,返回Invoker
看到这里,你有没有想到另外一个问题,那就是针对活跃数在哪里自增、自减的呢?
这就要说到Dubbo的过滤器,涉及到 ActiveLimitFilter 这个类。在这个类中,有这样一段代码:
//触发active自增操作 RpcStatus.beginCount(url, methodName); Result result = invoker.invoke(invocation); //触发active自减操作 RpcStatus.endCount(url, methodName, System.currentTimeMillis() - begin, true); return result; 复制代码
最后,这个Filter需要手动添加一下,在配置文件我们这样定义: <dubbo:consumer filter="activelimit">
四、hash 一致性算法
一致性 hash 算法由麻省理工学院的 Karger 及其合作者于1997年提供出的,算法提出之初是用于大规模缓存系统的负载均衡。
它的原理大致如下:
先构造一个长度为2 32 的整数环(一致性Hash环),然后根据节点名称的Hash值(分布在0 - 2 32 -1)将服务器节点放置在这个Hash环上。最后,根据数据的Key值计算得到其Hash值,在Hash环上顺时针查找距离这个Key值的Hash值最近的服务器节点,完成Key到服务器的映射查找。
关于一致性Hash算法,如有不了解的,需自行补充相关知识。
在Dubbo中,引入了虚拟节点用于解决数据倾斜问题。图示如下:
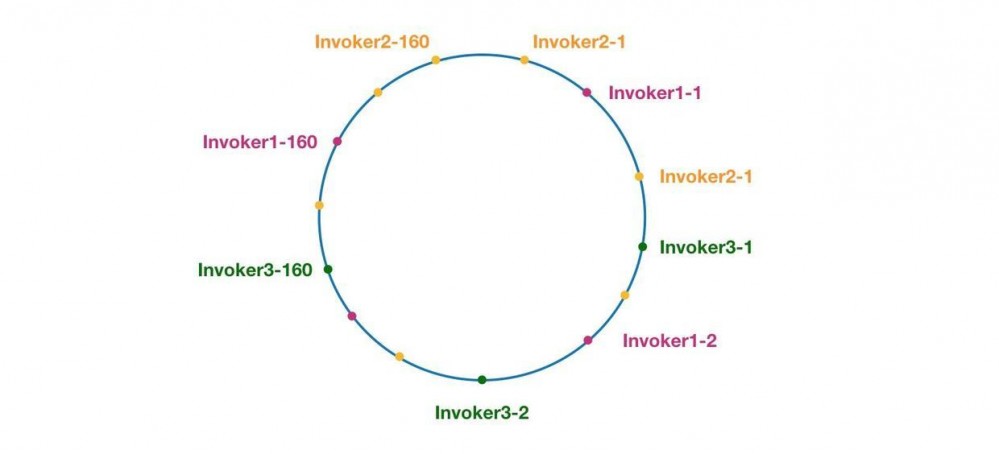
这里相同颜色的节点均属于同一个服务提供者,比如 Invoker1-1,Invoker1-2,…,Invoker1-160。即每个Invoker会共创建160个虚拟节点,Hash环总长度为160*节点数量。
我们先来看 ConsistentHashLoadBalance.doSelect 实现。
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
//请求类名+方法名
//比如:com.viewscenes.netsupervisor.service.InfoUserService.sayHello
String key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName();
//对当前的invokers进行hash取值
int identityHashCode = System.identityHashCode(invokers);
ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key);
//如果ConsistentHashSelector为空 或者 新的invokers hashCode取值不同
//说明服务提供者列表可能发生变化,需要获取创建ConsistentHashSelector
if (selector == null || selector.identityHashCode != identityHashCode) {
selectors.put(key, new ConsistentHashSelector<T>(invokers, invocation.getMethodName(), identityHashCode));
selector = (ConsistentHashSelector<T>) selectors.get(key);
}
//选择Invoker
return selector.select(invocation);
}
复制代码
以上代码,主要是为了获取ConsistentHashSelector,然后调用它的方法选择Invoker返回。还有一点需注意,如果服务提供者列表发生变化,那么它们两次的HashCode取值会不同,此时会重新创建ConsistentHashSelector对象。 此时的问题的关键就变成了,ConsistentHashSelector是如何被创建的?
1、创建ConsistentHashSelector
这个类有几个属性,我们先来看一下。
private static final class ConsistentHashSelector<T> {
//使用 TreeMap 存储 Invoker 虚拟节点
private final TreeMap<Long, Invoker<T>> virtualInvokers;
//虚拟节点数量,默认160
private final int replicaNumber;
//服务提供者列表的Hash值
private final int identityHashCode;
//参数下标
private final int[] argumentIndex;
}
复制代码
再看它的构造方法,主要是创建虚拟节点Invoker,放入virtualInvokers中。
ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {
//初始化TreeMap
this.virtualInvokers = new TreeMap<Long, Invoker<T>>();
//当前invokers列表的Hash值
this.identityHashCode = identityHashCode;
URL url = invokers.get(0).getUrl();
//获取虚拟节点数,默认为160
this.replicaNumber = url.getMethodParameter(methodName, "hash.nodes", 160);
//默认对第一个参数进行hash取值
String[] index = Constants.COMMA_SPLIT_PATTERN.split(
url.getMethodParameter(methodName, "hash.arguments", "0"));
argumentIndex = new int[index.length];
for (int i = 0; i < index.length; i++) {
argumentIndex[i] = Integer.parseInt(index[i]);
}
//循环创建虚拟节点Invoker
for (Invoker<T> invoker : invokers) {
String address = invoker.getUrl().getAddress();
for (int i = 0; i < replicaNumber / 4; i++) {
byte[] digest = md5(address + i);
for (int h = 0; h < 4; h++) {
long m = hash(digest, h);
virtualInvokers.put(m, invoker);
}
}
}
}
复制代码
以上代码的重点就是创建虚拟节点Invoker。
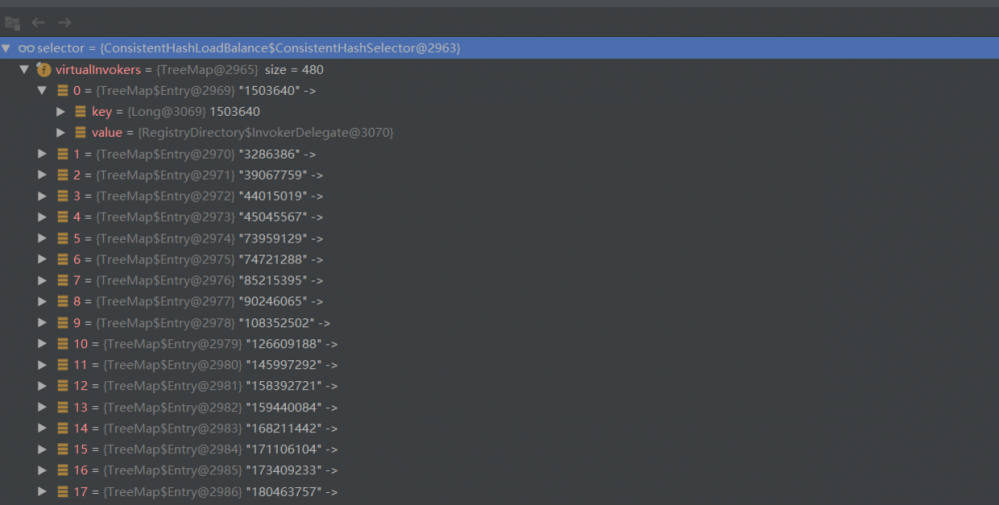
首先,先获取通信服务器的地址,比如 192.168.1.1:20880 ; 然后,先对 address + i 进行MD5运算,得到一个数组,接着对这个数组的部分字节进行4次 hash 运算,得到四个不同的 long 型正整数; 最后将hash和invoker的映射关系存储到TreeMap中。
此时,如果我们有3个服务提供者,来算一算一共会有多少个虚拟节点。呔!不许拿计算器,请心算。 没错,480个啦。它们的映射关系如下:
2、选择
创建完了ConsistentHashSelector,就该调用它的方法来选择一个Invoker了。
public Invoker<T> select(Invocation invocation) {
String key = toKey(invocation.getArguments());
byte[] digest = md5(key);
return selectForKey(hash(digest, 0));
}
复制代码
以上代码很简单,我们分为两部分来看。
2.1、转换参数
获取到参数列表,然后通过 toKey 方法,转换为字符串。这里看似简单,却隐含着另外一层逻辑。它只会取第一个参数,我们看 toKey 方法。
private String toKey(Object[] args) {
StringBuilder buf = new StringBuilder();
for (int i : argumentIndex) {
if (i >= 0 && i < args.length) {
buf.append(args[i]);
}
}
return buf.toString();
}
复制代码
获取到参数值key后,对字符串key进行MD5运算,接着通过hash获取 long 型正整数。这一步总的来说,就是把参数列表中的第一个参数值转换为一个long型正整数。 那么,相同的参数值就会得到同一个hash值,所以, 这里的负载均衡逻辑就会只受参数值影响,具有相同参数值的请求将会被分配给同一个服务提供者。
2.2、确定
计算出Hash值之后,事情就变得简单了。按照一致性Hash算法中的原理来说就是 在Hash环上顺时针查找距离这个Key值的Hash值最近的服务器节点 。落实到Dubbo上来说,就是在 virtualInvokers 这个TreeMap中,返回其键大于或等于Hash值的部分数据,然后取第一个。
private Invoker<T> selectForKey(long hash) {
Map.Entry<Long, Invoker<T>> entry = virtualInvokers.tailMap(hash, true).firstEntry();
if (entry == null) {
entry = virtualInvokers.firstEntry();
}
return entry.getValue();
}
复制代码
五、加权轮询算法
说起轮询,我们都知道呀。就是按照顺序一个个的来呗,不偏不倚,绝对公正。如果采购的服务器性能大致相同,那采用轮询再合适不过了,简单高效。
那啥又是加权轮询呢?
如果我们的服务器性能是有差异的,就不好用简单的轮询来做。小身板服务器表示扛不住那么大的压力,请求降权。
假设,我们有服务器【A、B、C】,权重分别是【1、2、3】。面对6次请求,它们负载均衡的结果如下:【A、B、C、B、C、C】。
该算法对应的类是 RoundRobinLoadBalance ,在开始之前我们先看它的两个属性。
sequences
它是一个编号,记录的是服务的调用编号,它是一个 AtomicPositiveInteger 实例。根据 全限定类名 + 方法名 来获取,如果为空则创建。
AtomicPositiveInteger sequence = sequences.get(key);
if (sequence == null) {
sequences.putIfAbsent(key, new AtomicPositiveInteger());
sequence = sequences.get(key);
}
复制代码
然后在每次调用服务前,做自增操作来获取当前的编号。 int currentSequence = sequence.getAndIncrement();
IntegerWrapper
这个也很简单,就是一个int类型的包装类,主要是一个自减方法。
private static final class IntegerWrapper {
private int value;
public IntegerWrapper(int value) {
this.value = value;
}
public int getValue() {
return value;
}
public void setValue(int value) {
this.value = value;
}
public void decrement() {
this.value--;
}
}
复制代码
然后我们来看doSelect方法,为方便解析,我们拆开来看。
1、获取权重
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
//全限定类型+方法名
String key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName();
//服务提供者数量
int length = invokers.size();
//最大权重
int maxWeight = 0;
//最小权重
int minWeight = Integer.MAX_VALUE;
final LinkedHashMap<Invoker<T>, IntegerWrapper> invokerToWeightMap =
new LinkedHashMap<Invoker<T>, IntegerWrapper>();
int weightSum = 0;
//循环主要用于查找最大和最小权重,计算权重总和等
for (int i = 0; i < length; i++) {
int weight = getWeight(invokers.get(i), invocation);
maxWeight = Math.max(maxWeight, weight); // Choose the maximum weight
minWeight = Math.min(minWeight, weight); // Choose the minimum weight
if (weight > 0) {
//将Invoker对象和对应的权重大小IntegerWrapper放入Map中
invokerToWeightMap.put(invokers.get(i), new IntegerWrapper(weight));
weightSum += weight;
}
}
}
复制代码
如上代码,主要就是获取Invoker的权重大小、计算总权重。其中重点在于向 invokerToWeightMap 中放入Invoker对象和其对应的权重大小 IntegerWrapper 。
2、获取服务调用编号
每次调用前都会对 sequence 进行自增来获取服务调用编号,需要注意它的获取key为全限定类名+方法名。
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
//全限定类型+方法名
String key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName();
//.....
AtomicPositiveInteger sequence = sequences.get(key);
if (sequence == null) {
sequences.putIfAbsent(key, new AtomicPositiveInteger());
sequence = sequences.get(key);
}
int currentSequence = sequence.getAndIncrement();
}
复制代码
3、权重
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
//......
//调用编号
int currentSequence = sequence.getAndIncrement();
if (maxWeight > 0 && minWeight < maxWeight) {
//使用调用编号对权重总和进行取余操作
int mod = currentSequence % weightSum;
//遍历 最大权重大小 次数
for (int i = 0; i < maxWeight; i++) {
//遍历invokerToWeightMap
for (Map.Entry<Invoker<T>, IntegerWrapper> each : invokerToWeightMap.entrySet()) {
//当前Invoker
final Invoker<T> k = each.getKey();
//当前Invoker对应的权重大小
final IntegerWrapper v = each.getValue();
//取余等于0 且 当前权重大于0 返回Invoker
if (mod == 0 && v.getValue() > 0) {
return k;
}
//如果取余不等于0 且 当前权重大于0 对权重和取余数--
if (v.getValue() > 0) {
v.decrement();
mod--;
}
}
}
}
}
复制代码
以上代码就是根据权重轮询来获取Invoker的过程,只看代码的话其实有点晦涩难懂。但如果我们Debug来看,就能更好的理解它。 我们以上面的例子模拟一下运行过程,此时有服务器【A、B、C】,权重分别是【1、2、3】,总权重为6,最大权重为3。
mod = 0:满足条件,此时直接返回服务器 A
mod = 1:自减1次后才能满足条件,此时返回服务器 B
mod = 2:自减2次后才能满足条件,此时返回服务器 C
mod = 3:自减3次后才能满足条件,经过递减后,服务器权重为 [0, 1, 2],此时返回服务器 B
mod = 4:自减4次后才能满足条件,经过递减后,服务器权重为 [0, 0, 1],此时返回服务器 C
mod = 5:只剩服务器C还有权重,返回C。
这样6次调用,得到的结果就是【A、B、C、B、C、C】。
当第7次调用时,此时调用编号为6,总权重大小也为6;mod则为0,重新开始。
正文到此结束
- 本文标签: 一致性 UI parse rand final 源码 Atom 压力 JVM 时间 key build db id 配置 遍历 tk 参数 服务器 ACE tar 索引 代码 实例 consumer node IO map 解析 CST 快的 http HashMap IDE Select dubbo remote constant 集群 App 缓存 list entity 负载均衡 bug 数据 DOM 总结 tab Service cat CTO 构造方法 value src https
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

