HashSet源码解析从一道面试题说起:HashSet内部是怎么实现的?
前段时间朋友面试遇到这个问题:谈一谈HashSet的特点,它是怎么实现的,使用时有什么需要注意的点呢?恰好最近在写这方面的文章,于是正好通过本篇文章讲解下 HashSet 的源码实现,需要注意的点。
HashSet 实现了 Set 接口,是一个不能够存放重复元素的容器,内部直接使用 HashMap 实现,即底层使用数组存储数据,HashSet没有任何同步手段,在多线程环境下需慎重考虑,可以使用 Collections.synchronizedSet(new HashSet(...)); 给原有的Set方法同步。

友情链接: HashMap源码全解析从一道面试题说起:请一行一行代码描述下hashmap put方法
HashSet结构详解
类结构
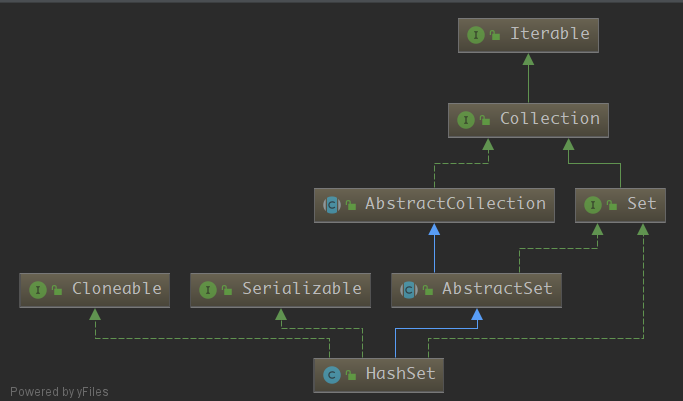 关系图没有需要注意的点,
关系图没有需要注意的点, HashSet 实现了 Set 接口,Set是 集合 的抽象概念,它内部不允许出现重复的元素。
类成员
前面我们已经说过,Set内部是不能够存在重复元素的,那HashSet内部是怎么做的呢?如图:

直接使用HashMap存放数据,因HashMap的Key须唯一,所以可以将我们需要存放的数据放到Key,而所有的value对应一个内部的对象PRESENT即可。
源码详解
构造器
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
简单明了,直接new一个HashMap。 这里需要注意的是,它还有另一个不常用的构造方法:
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
使用这个构造方法会内部将不再使用HashMap操作元素,而是 LinkedHashMap ,而LinkedHashMap继承自HashMap,他们之间的不同是LinkedHashMap在HashMap底层使用数组的是线上加了两个“指针”分别指向头和尾。

add(E e) 添加元素
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
直接调用HashMap的put方法,将元素e放到map的key位置来保证唯一性。我们知道HashMap的put方法如果该位置已经存在一个一样的Key(==或者equals相等),会用新的value替换原来的旧的value,并且返回旧的value,所以对于HashSet而言第一次插入返回null就代表成功,以后再次插入同样的元素,返回的是一个对象,表示已经存在这样的元素了,插入失败!
其它remove,contains方法类似。
注意点
- HashSet中存储的元素都是“无序的”,因为底层使用数组实现,存储时将key进行hash得出数组位置,这是一个随机的过程,所以存储的元素时无序的。
- 为了HashSet迭代时的性能考虑,初始容量可以尽量设置的小一点,而加载引子则可以设置的大一点(默认0.75)。因为HashSet和HashMap关注的中心不同,HashMap关注的是其中的键值对的存储以及扩容时的性能考虑。
HashSet的迭代方法直接调用HashMap内部KeySet的iterator方法,返回KeyIterator。public Iterator<E> iterator() { return map.keySet().iterator(); }
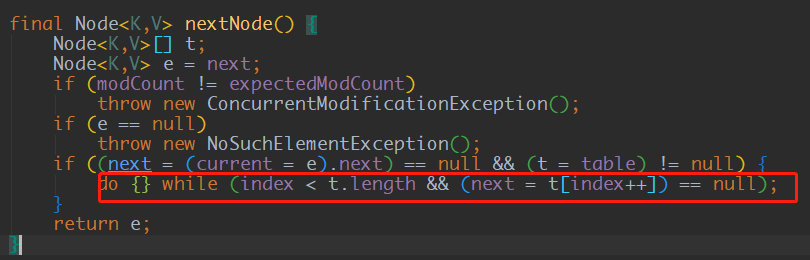 该方法在迭代时循环判断数组是否为null,不为null则认为该位置上有元素。所以确定初始容量,尽量设置的更小有利于HashSet迭代其中的key。
该方法在迭代时循环判断数组是否为null,不为null则认为该位置上有元素。所以确定初始容量,尽量设置的更小有利于HashSet迭代其中的key。
总结
- HashSet是一个元素不会重复并且无序的容器。
- HashSet内部使用HashMap实现,即最终依然使用数组存储数据。
- 使用时应该尽可能确定容器的大小,尽量设置初始容量小一点,并且加载引子大一点以加快迭代性能。
关注我,这里只有干货!
关联文章:
HashMap源码全解析从一道面试题说起:请一行一行代码描述下hashmap put方法
jdk1.8源码解析-ArrayList
jdk1.8 LinkedList源码全分析
线程池?面试?看这篇就够了!正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

