从一次问题排查聊聊问什么要懂原理
上周五,一同事在开发时遇到了一个问题,叫我帮忙看下.在描述这个同事遇到问题之前,我先简单做一些知识的铺垫,否则不好描述.这里面涉及到的知识点有 Spring的事务传播机制 、 数据库的隔离级别 等.
本篇重点是解决同事遇到的问题,因为这两个知识点都先简单谈谈,只为引出主题.后面这两个会专门用一篇来讲
Spring的事务传播机制
Sring的事务传播机制有七种,本文涉及到的有两种
REQUIRED : 用得最多(估计高达90%),也是默认的模式.若当前没有事务,则新建事务,若当前已存在一个事务, 则加入到该事务中
REQUIRES_NEW : 新建一个事务
Spring的事务传播机制.后面我会用一篇文章专门来讲,给大家列各种典型的题型,按照高中的题型训练模式,彻底弄懂Spring的传播机制,即使在各种 复杂嵌套 + try 场景下也能云淡风轻地确定回滚情况.包括解析之前非常经典的一道面试题
- 做51次操作,前面50次成功,第51次失败,全部回滚
- 做51次操作,前面50次成功,第51次失败,只回滚第51次,全面50次照常提交
事务的隔离级别
考虑到部分同学英文问题,我特意标记了中文
1. Read Uncommitted : 读未提交
这个基本不可能用,从字面意思你就知道了,读到别人还未提交的数据,别人都没提交,你怎么知道别人接下来是要提交还是回滚?既然不知道你就读,自然会有问题.这个问题就是我们说的 脏读 .
2. Serializable : 串行化
其实就是同步化,性能太差,基本不可能用这个.但是这个是唯一能解决 幻读 问题的.
画图分析
剩下两种隔离级别
-
Read Committed: 读已提交 -
Read Repeatable: 可重复读
就比较重要了,我们画图来分析
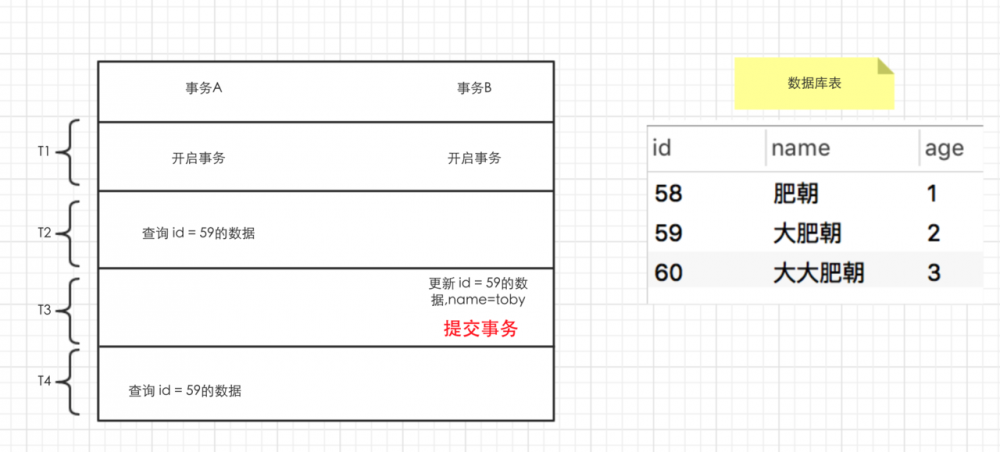
比如我问,当 t4 时,查询出来的数据,name是 大肥朝 还是 toby .其实你内心就不是很确定了,但是我如果把 提交事务 这几个字加粗标红,然后引诱一下,绝大多数同学** 根本把持不住!!! **

既然都 提交事务 了,那读出来的自然是 toby 啦.
其实 t4 读出来是 toby 还是 大肥朝 这个取决与你用的是 读已提交 、 可重复读 .其实你从这个中文名称都可以猜到了,如果是 读已提交 ,那么查出来的就是 toby .如果是 可重复读 .读出来的自然就是 大肥朝 . MySQL 默认用的是 可重复读 . Oracle 默认用的是 读已提交 .
温馨提示: 这个后面也可以考虑再写一篇详细讲一下这个隔离级别,因为一般问到 可重复读 ,有深度的面试官会继续追问,可重复读是如何实现的?具体怎么实现的我们可以先关注肥朝公众号,后面再具体说数据库的 MVCC 机制
问题描述
由于业务具有一定的复杂度,不利于大家观看,因此我这里特意抽象简化了模型.
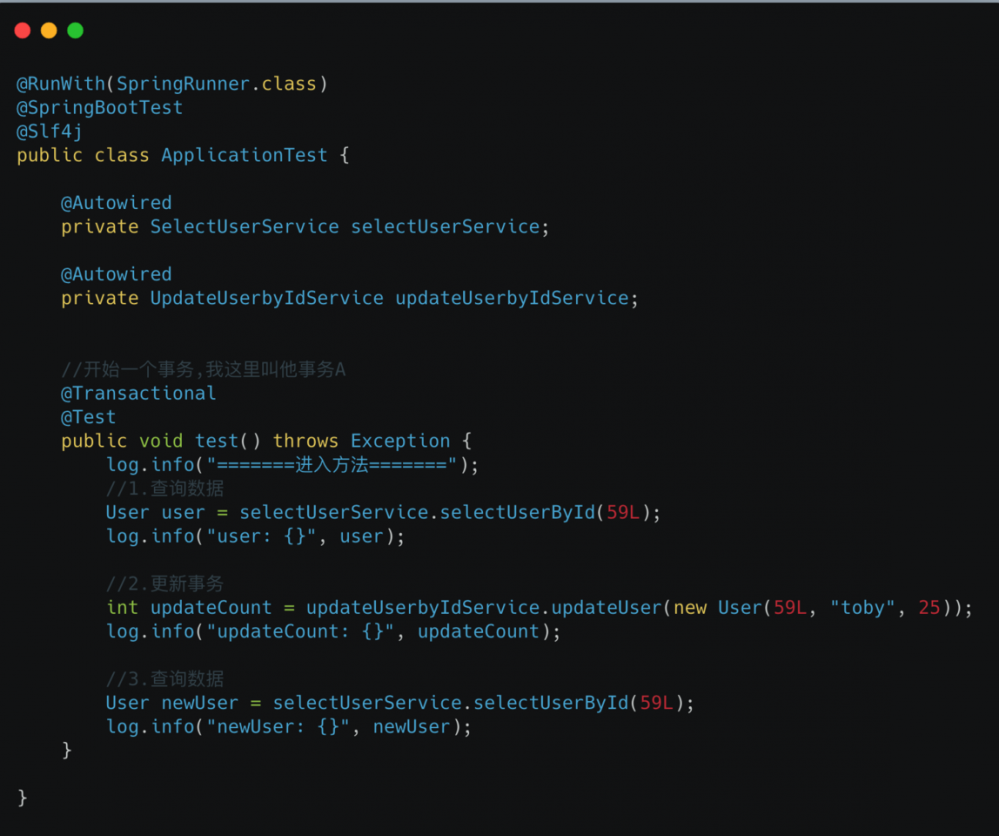



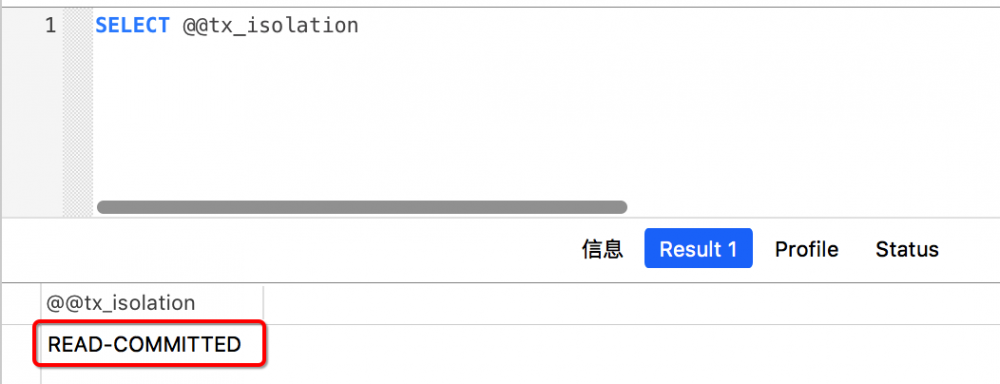
首先,我先把数据库的隔离级别改成 读已提交 .截图为证:
那么问题来了,请问步骤3查询出来的数据是什么呢.我们一起来见证
##见证答案
1.查询完数据,准备更新数据

2.更新完成提交了事务,我们看得出此时数据库已经改成了 toby
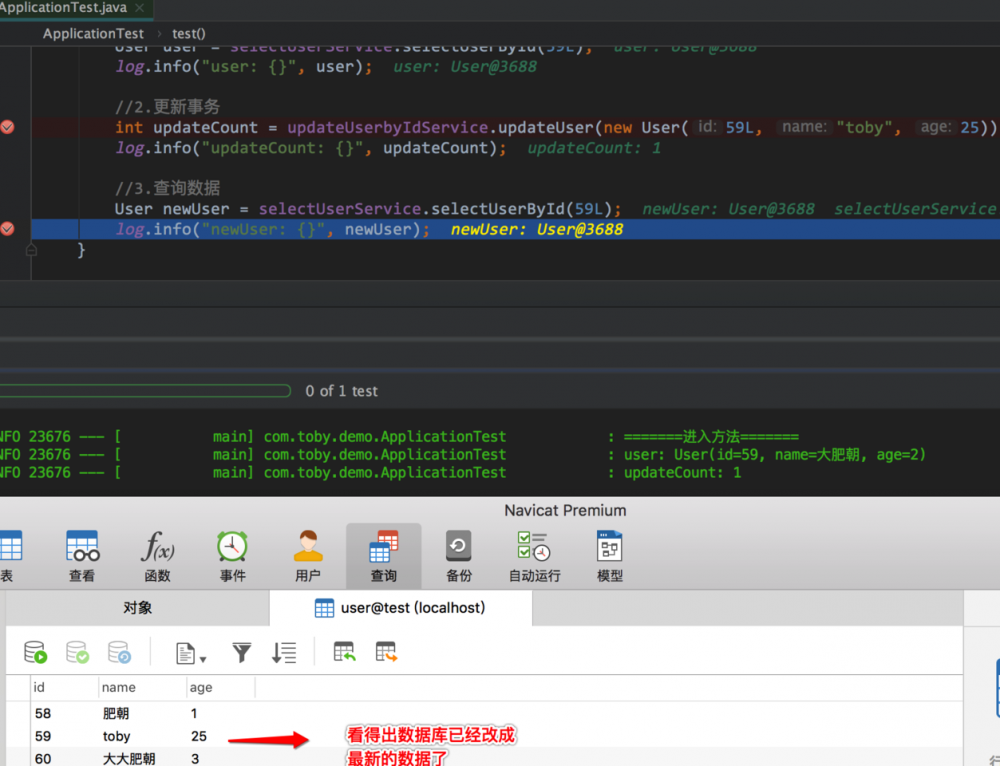
3.震惊!查出来的数据竟然是 大肥朝

这个时候似乎就不厚道了,肥朝你前面怎么说的,你前面说 读已提交 读出来的是别人已经提交的,那么应该是 toby 才对啊,怎么还是 大肥朝 ?.

开始排查
我们把配置文件设置成`debug级别一切就豁然开朗了
logging.level.com.toby.demo.dao=debug logging.level.org.mybatis=debug 复制代码
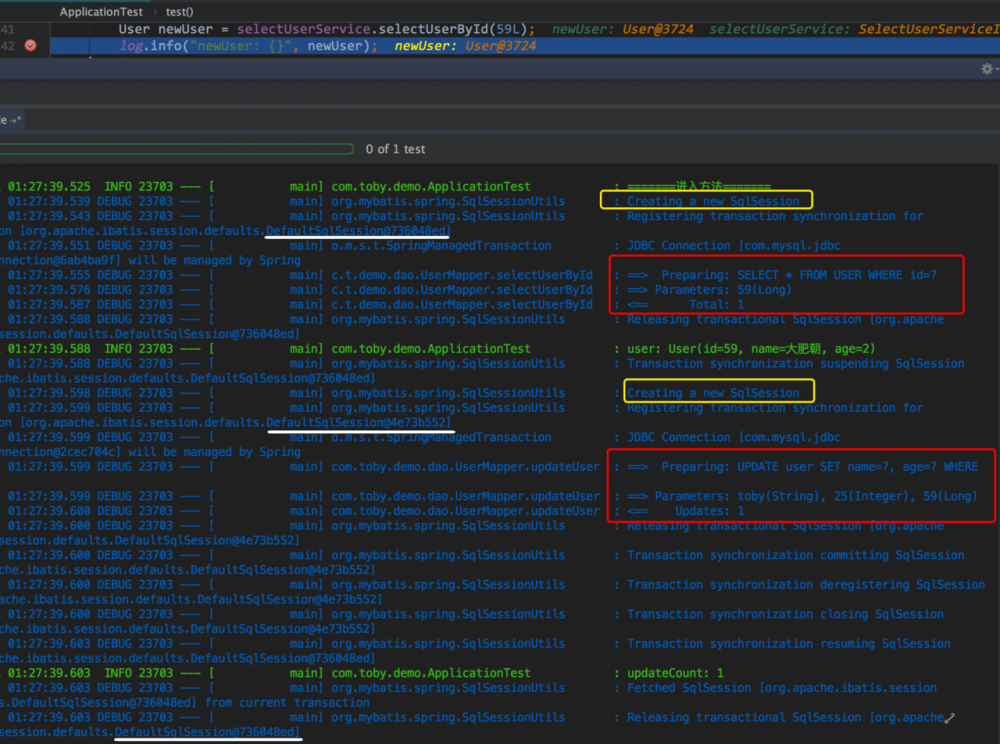
这里我特意用不同颜色给大家标记清楚了,其实看到只输出两次 SQL 日志大家就知道了.第三次查询没有输出SQL,这很明显是用到了 Mybatis 的缓存了.再根据我标记的 SqlSession 信息来看,这里就是用到了 Mybatis 的 一级缓存
解决办法
解决办法有很多,我们知道Mybatis一级缓存的作用域是 SqlSession ,那么只要两次查询是不同的 SqlSession 那自然这个一级缓存就失效了.一级缓存失效了.就会查询两次,输出两次sql.这个时候是 toby 还是 大肥朝 就真的取决于我前面说的 隔离级别 了.比如一个简单的改法是
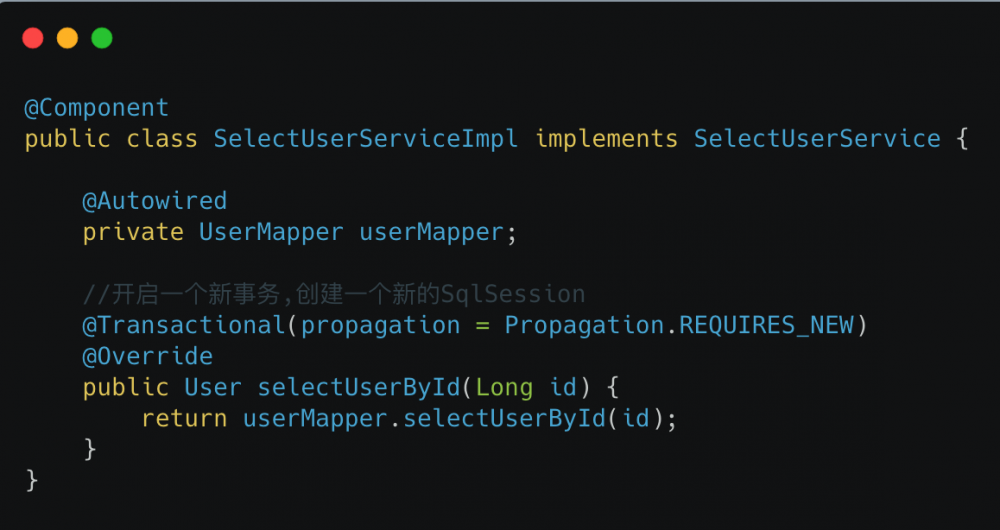
改法有很多,具体根据那么的业务来就可以了,当然也可以采用上面那种
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

