Android开发随记
一、性能优化
性能优化可以在这几个方面下手, 流畅性 , 稳定性 , 包体积大小
- 流畅性优化
- 启动时间优化 —在Application的onCreate的时候,会有很多SDK选择在这里进行初始化,在加上自己写的一些库也在这里初始化,这样主线程在初始化的时候将会不堪重负,导致启动很久白屏,所以在初始化的时候应当进行
- 根据库进行分步延迟加载
- 多线程加载
- 后台任务加载
- UI优化 —UI层级过深,在进行测量和定位的时候将会占用更多的CPU资源,也会导致渲染周期加长,在Android的渲染机制中,每16ms将会发起一次垂直同步信号,进行渲染,如果在16ms以内还无法更新到surface,画面将会显示上一次的画面,这样看起来就会卡顿。解决措施:
- 减少布局层级
- 使用懒加载标签ViewStub
- 避免使用include,改成使用merge标签
- 尽量避免使用复杂的矢量动画和矢量图形 ,绘制矢量图形的需要占用cpu资源,也会导致卡顿,复杂的矢量图形可以使用位图,GPU会进行缓存。
- 避免大量的IO — 大文件IO是非常占用CPU的耗时操作,必要时可以进行分布,分片的IO操作,对于不需要操作数据库的数据应当使用文件保存,小文件读写比数据库更快,也避免数据库冗余。
- 避免频繁GC — 避免频繁大量的创建对象,当内存紧张时,会频繁GC,申请大内存的对象,也会有可能触发GC,GC时会占用CPU,导致画面卡顿
- 合理的使用线程 — 线程的切换是又开销的,频繁的切换线程是会使用性能降低,应当创建cpu核数相当的线程池,合理分配线程,和使用协程
- 避免过多的复杂计算 — 作为前端也不应该进行复杂的运算,又不是超算,密集的复杂计算也会占用更多的cpu资源。
-
稳定性优化
影响App稳定性常见的有两个场景 Crash 和 ANR,它会导致App异常退出。所以解决App的稳定性应该列为最高优先级。如何避免异常的发生,可以从这几个方面入手 - 编码阶段 。人非机器,即使是机器也会出错,所以应该使用更多的工具辅助,在编码的时候尽量把异常情况排除掉。
- 空指针异常 。最常见的异常就是空指针异常的,我建议使用kotlin,有空安全类型。
- 内存泄漏 ,发生内存泄漏的主要原因的生命周期不一致的对象相互引用,比如在线程中,handler,静态单例里引用了Activity,Activity销毁后,没有被释放。要解决的这个除了改变编程习惯,也可以使用一些协同Activity的生命周期的工具类来使用线程和handler,在Activity销毁的时候把Activity的引用释放,避免不规范的创建线程,handler,导致内存泄漏。
- OOM 。在App中常见的是加载大图等内存的大户。所以图片要进行压缩,读取的时候不要直接将大图载入内存中,先获取图片信息,在设置压缩比例inSampleSize在加载,最好使用Glide,Picasso这些优秀的开源库加载,他们有对图片缓存管理。
- 至于其他的bug,如果时间允许可以编写单元测试,也可以使用类似Android Lint,Findbugs的工具排查 。多人团队开发的,可以互相审查代码,一来可以看出自己没有察觉的bug,二来也能熟悉他人的代码。
- Carsh信息监控上报 。这个很多第三方平台都有,app的必需品,这里就不打广告了。如果要自己写的话,Java层,除了设置UncaughtExceptionHandler之外,还需要获取AMS.getProcessesInErrorState,native层的话需要设置sigaction 和使用libunwind这个库了。
- 包体积的大小的优化
- 只使用一套高分辨率的资源图,使用工具对图片进行压缩,图片使用webp格式。
- 对于so文件只使用v7a平台的。当然这是牺牲性能为代价的处理方式。下列内容转自: https://www.cnblogs.com/yingsong/p/6709322.html
- armeabiv-v7a: 第7代及以上的 ARM 处理器。2011年15月以后的生产的大部分Android设备都使用它.
- arm64-v8a: 第8代、64位ARM处理器,很少设备,三星 Galaxy S6是其中之一。
- armeabi: 第5代、第6代的ARM处理器,早期的手机用的比较多。
- x86: 平板、模拟器用得比较多。
- x86_64: 64位的平板。
- 使用7z打包 。可以参考微信的AndResGuard
二、内存模型
Linux的进程内存模型是由 用户空间 和 内核空间 组成。
- 内核空间 。在这里CPU可以访问任何外围设备,比如什么键盘,显示器,网卡,当然这些在CPU的眼里都是一段物理地址。换句话说,在内核空间CPU可以访问所有的物理地址。 这个内核空间是所有进程共享的。
- 用户空间。 在这里CPU的访问是受限的,比如操作系统给它分配了2G的空间,它也就只能访问这2G的地址了。 这个是进程独享的,其他的进程无法访问这个空间。
在应用程序中,如果直接操作外围设备,访问时也不知道其他程序有没有在访问,也不知道哪一段可以用的,大家你争我抢的,都乱套了,而且也不安全。所以需要一位管理者--操作系统。操作系统将真实的物理地址隔离起来,给每个程序分配一段虚拟地址,通过mmap将真实地址和虚拟地址起来,比如虚拟地址是0x00,那么它真实的物理地址可能是0x1c。在真实物理地址它可能不是一段连续的地址,但是在虚拟地址是连续的就可以了。
虚拟空间还可以进行细分:
内核空间(进程管理,存储管理,文件管理,设备管理,网络系统等) ---------- 栈 FileMapping 堆 BSS Data text 复制代码
- 内核空间 。这里主要是一些进程管理,存储管理,文件管理,设备管理,网络系统等。由于这部分是所有进程共享的,为了更高效率的通信,在Android中设计了一块匿名共享内存,只要将数据从用户空间拷贝到这里其他进程就可以获取,这样就可以实现高效率的进程间通信。具体可以看看微信的MMKV的原理,Binder也是这个原理。
- 用户空间
- 栈 。这一块不是很大,主要保存一些方法的地址,局部变量表,返回地址等。所以递归很容易就StackOverFlow。
- 文件地址映射块 。这里记录了虚拟地址对实际文件物理地址的映射,包括动态链接库文件。内存文件映射的物理存储器来自一个已经存在于磁盘上的文件,而且在对该文件进行操作之前必须首先对文件进行映射。使用内存映射文件处理存储于磁盘上的文件时,将不必再对文件执行I/O操作,使得内存映射文件在处理大数据量的文件时能起到相当重要的作用。
- 堆 。这个区间是我们要重点关注的,因为它完全由我们程序员来控制。native申请的空间为native heap,Java申请的空间则为dalvik heap。在Android系统中,有对Java进程申请堆内存空间进行限制,这个阈值在不同手机上不同,比如48MB。超过了这个值就会发生OOM。如果想要突破这个限制,有两个方法
- 申请大内存。android:largeHeap=”true”
- 创建子进程。android:process
- BSS 段 。 这个区间保存的是一些没有初始化的全局变量,比如 int a;没有映射实际的物理地址,只是记录一下所需要用到的内存空间,所以这样写的变量是不会有默认的赋值。
- Data 段 。这个区间保存的是已经初始化的全局变量。比如int a=123。
- 代码 段 。保存程序文本。这个区域是只读的,防止被修改。
三、JVM 内存模型
进程由n个线程组成,在JVM中,又对进程以线程为单位对内存进行划分。
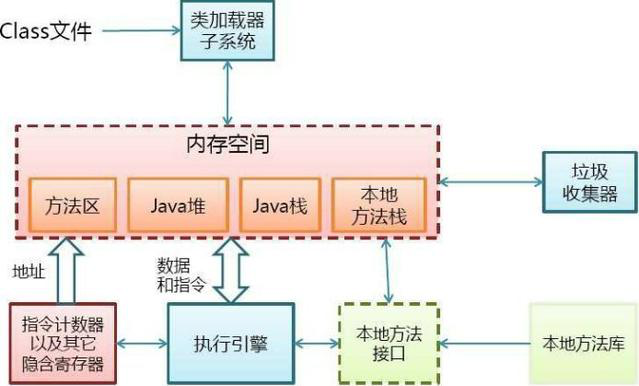
线程的内存分配:
- 栈[私有] :
- Java虚拟机栈
- 栈帧
- 局部变量表
- 操作数栈
- 动态链接
- 方法返回地址
- 附加信息
- 本地方法栈
- 程序计数器
- 堆[共享]:
- Java堆:
- 新生代
- 老年代
- 方法区:
- class信息:
- 类和接口的全限定名
- 属性名称和描述符
- 方法名称和描述符
- 运行时常量池
- 编译后的代码
在操作系统看来,JVM是一个程序,而Java程序只是运行在程序上的程序,所以JVM需要模拟程序运行的环境。
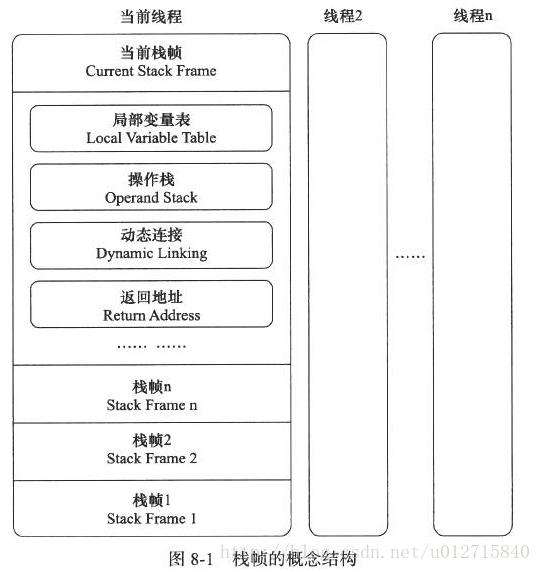
(图片来源:csdn-骁兵)
- Java虚拟机栈 。Java栈由很多个栈帧组成,每一个栈帧代表一个方法,而栈帧由局部变量表,操作数栈,动态链接,返回值地址以及一些附加信息组成,栈是方法的生存之地,当方法被调用的时候:
- 将调用方的地址入栈,也就是方法返回地址
- 给方法开辟栈帧,具体这个栈帧的需要多大的空间,在class文件就可以得到。
- 初始化栈帧空间。
- 将参数压入局部变量表。
- 将参数和局部变量压入局部变量表。
- 操作栈和程序计数器工作。
- 执行到方法返回指令,回到调用点。
- 局部变量表。 方法的执行其实就是值的存取,运算。所以方法需要以栈为基,在局部变量表中,以slot为单位,一个萝卜一个坑,用来存放int,short,float,boolean,char,byte,引用地址和返回值地址等。long 和 double 这两个不一样,一个萝卜两个坑,因为他们是64位的,前面的是32位的。如果时基本数据类型,值保存在栈中,其他引用类型存在堆中,引用地址则保存在栈中,比如int[]。至于初始化局部变量表时需要多少坑位,在方法编译成class之后就定下来了。为了节省空间,坑位也会复用,比如a变量出了作用域,后面定义的b变量就会复用。
public class Test { public void test(int b, int a) { int x = 6; if (b > 0) { String str = "VeCharm"; } int y = a; int c = y + b; } } ---------------- javac Test.java javap -v Test ---------------- class信息: Last modified 2019-3-31; size 347 bytes MD5 checksum b0e2fc2ec7a2d576136a693c77213446 Compiled from "Test.java" public class com.vecharm.lychee.sample.api.Test minor version: 0 major version: 52 flags: ACC_PUBLIC, ACC_SUPER Constant pool: ... { public com.vecharm.lychee.sample.api.Test(); descriptor: ()V flags: ACC_PUBLIC Code: stack=1, locals=1, args_size=1 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V 4: return LineNumberTable: line 3: 0 public void test(int, int); descriptor: (II)V flags: ACC_PUBLIC Code: stack=2, locals=6, args_size=3 0: bipush 6 2: istore_3 3: iload_1 4: ifle 11 7: ldc #2 // String VeCharm 9: astore 4 11: iload_2 12: istore 4 14: iload 4 16: iload_1 17: iadd 18: istore 5 20: return LineNumberTable: line 7: 0 line 8: 3 line 9: 7 line 11: 11 line 12: 14 line 13: 20 StackMapTable: number_of_entries = 1 frame_type = 252 /* append */ offset_delta = 11 locals = [ int ] } SourceFile: "Test.java" 复制代码 - 看test方法,我们来逐步分析这些JVM指令
- bipush 6。将 6 push操作栈,当int取值-1~5采用iconst指令,取值-128~127采用bipush指令,取值-32768~32767采用sipush指令,取值-2147483648~2147483647采用 ldc 指令。
- istore_3。将6这个值从操作栈弹出,存入局部变量表3号坑,为啥是3号坑而不是1和2,因为这两个坑被参数b,和参数a栈了。
- iload_1。将局部变量表中的1号坑的值push操作栈,1号坑的是b的值。
- ifle 11。将操作栈弹出b的值,ifle这条指令的意思当栈顶int型数值小于等于0时跳转,跳转到11偏移地址。
- ldc #2。将int、float或String型常量值从常量池中推送至操作栈栈顶。
- astore 4。将操作栈栈顶的值弹出存入局部变量表4号坑,istore就是存int值和布尔值,fstore就是存float值,astore是存引用地址的。
- iload_2。取出2号坑的值push操作栈。
- istore 4。将操作栈顶的值存入4号坑,4号坑之前str已经用过了,但是出了作用域已经无用,所以可以复用。
- iload 4。取出4号坑的值push操作栈。
- iload_1。将局部变量表中的1号坑的值push操作栈,现在操作栈有两个值了,
- iadd。将操作栈的值相加。
- istore 5。将结果存入5号坑。
- 看到这想必已经明白局部变量表的作用了。
- 操作栈。 JVM需要模拟cpu那样执行指令,但并无法像cpu那样方便调用寄存器保存临时值。所以想了一个法子,在栈中划一块区域作为类似寄存器那样的功能。
- 动态链接。 Java作为一门多态的语言,肯定少不了继承。有一Son类继承了Father类,重写了say()方法。当方法执行的时候,这个方法是属于Son这个版本还是Father这个版本呢。所以就不能写死方法是谁的,而是搞一个符号,等到运行时才替换成真正的版本,这被称为动态分配。 但也有某些方法签名是确定永不变的,比如静态方法,私有方法等这些不可重写的方法的称为非虚方法,它们的分配称为静态分配,反之可重写的为虚方法。 由于方法使用频繁,所以每一个类配备一个 虚方法表 方便索引。在Java虚拟机提供了几条方法执行的指令。
- invokestatic:调用static方法。
- invokespecial:只能调用三类方法:<init>方法;final方法;private方法;super.method()。因为这三类方法的调用对象在编译时就可以确定。
- invokevirtual:调用虚方法。
- invokeInterface:调用接口方法,会在运行时再确定一个实现此接口的对象。
- invokeDynamic:执行动态方法,它允许应用级别的代码来确定执行哪一个方法调用,先在运行时动态解析出调用点限定符所引用的方法,然后再执行该方法。
- 方法信息保存在方法区的类信息里面。
- 方法返回地址。 调用点的地址。
- 本地方法栈。执行 native方法的栈。虚拟机可以自由实现它,在HotSopt虚拟机把本地方法栈和Java栈融合在一起。
- 程序计数器。 作为一个JVM虚拟机,它执行class字节码指令,需要记录代码执行到哪一条指令,换句话说也就是行号。JVM有200多条指令,最多不超过0xff条。如果感兴趣可以访问这个 blog.csdn.net/lm2302293/a… 。
- 堆。 Java堆用来存储数据,类实例对象,所有线程共享。虽然不用关系释放,由垃圾处理器处理,但处理不慎还是会有内存泄漏的问题。
- 方法区。 Java中非常重要的一个区域,所以它和堆一样,是被线程共享的,常量嘛,肯定是共享的了。在方法区中,存储了每个类的信息。在每个类中存放:
- 运行时常量池
- 字面量
- 字段符号引用/直接引用
- 方法符号引用/直接引用
- 属性
- 字段数据。存放名称,类型,修饰符,属性。
- 方法数据。存放名称,返回类型,参数类型,修饰符,属性。
- 方法代码。
- 签名和标志位
- 字节码
- 操作栈大小,本地变量表大小,本地变量表
- 行号
- 异常表。
- 开始点
- 终结点
- 异常处理代码的位置
- 异常类在常量池的索引
- Classloader。
-
public class Test { public void test(int b, int a) { int x = 6; if (b > 0) { String str = "VeCharm"; } int y = a; int c = y + b; } } ---------------- javac Test.java javap -v Test ---------------- class信息: ... Constant pool: #1 = Methodref #4.#14 // java/lang/Object."<init>":()V #2 = String #15 // VeCharm #3 = Class #16 // com/vecharm/lychee/sample/api/Test #4 = Class #17 // java/lang/Object #5 = Utf8 <init> #6 = Utf8 ()V #7 = Utf8 Code #8 = Utf8 LineNumberTable #9 = Utf8 test #10 = Utf8 (II)V #11 = Utf8 StackMapTable #12 = Utf8 SourceFile #13 = Utf8 Test.java #14 = NameAndType #5:#6 // "<init>":()V #15 = Utf8 VeCharm #16 = Utf8 com/vecharm/lychee/sample/api/Test #17 = Utf8 java/lang/Object ... SourceFile: "Test.java" 复制代码 - 运行时常量池。 每一个类都分配一个运行时常量池,用来保存类的一些数据,按照类型分类。
- 常见的常量池的数据项类型:
CONSTANT_Utf8 UTF-8编码的Unicode字符串 CONSTANT_Integer int类型字面值 CONSTANT_Float float类型字面值 CONSTANT_Long long类型字面值 CONSTANT_Double double类型字面值 CONSTANT_Class 对一个类或接口的符号引用 CONSTANT_String String类型字面值 CONSTANT_Fieldref 对一个字段的符号引用 CONSTANT_Methodref 对一个类中声明的方法的符号引用 CONSTANT_InterfaceMethodref 对一个接口中声明的方法的符号引用 CONSTANT_NameAndType 对一个字段或方法的部分符号引用 - 编译后的代码。 一个Java类被编译成class代码,编译的时候并不能确定类的地址,只能用符号代替,编译后的class文件,在ClassLoad而之后将会被提取分类保存在方法区,方法区保存的是类的信息,堆中保存的是类的对象,obj.getClass获取的信息就是在方法区的。方法区也会溢出,当方法区的信息超过了阈值也会OOM,比如使用动态代理MethodInterceptor。
看到这想必就已经知道了一个从一个Java文件到内存是如何运作的了。类从加载到虚拟机内存中开始到卸载内存为止,它的整个生命周期包括:加载,验证,准备,解析,初始化,使用,和卸载7个阶段,其中验证,准备,解析3个部分被称为连接。
加载,验证,准备,初始化和卸载这5个阶段是确定的,类的加载过程是必须按照顺序来,而解析阶段这个可以在初始化之后开始,这是为了支持运行时绑定(动态绑定)。
- 遇到new,getStatic,putStatic,invokeStatic这4条指令时,如果没有初始化,则需要先触发器初始化。
- 反射类的时候,会去常量池查查,如果没有就会加载,初始化。
- 当初始化一个类的,作为一个它的父类,如果没有初始化就会先进行初始化。
- 当虚拟机启动时,会先初始化用户指定的主类。
- 使用MethodHandle。
说到底,编程就是编的只是数据和指令,来总结一下流程。
- 通过一个类的全限定名来获取定义此类的二进制字节流。
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
- 在内存中生存一个代表这个类的java.lang.Class对象,作为方法区这个类各种数据的访问入口。这个对象比较特殊,它存在方法区,不在堆区。并设置加载此class的ClassLoader引用。
- 验证。验证代码的安全性。这个阶段是否严谨,直接决定了Java虚拟机是否能承受恶意代码的攻击。
- 准备。正式为类变量分配内存并设置类变量的初始值的阶段,这些变量所使用的内存都将在方法区进行分配,这时候分配的变量都是静态变量,不是实例变量,实例变量会在对象实例化时随着对象一起分配在Java堆中。
- 解析。解析阶段时虚拟将常量池内的符号引用替换为直接引用的过程。符号引用与虚拟机实现的内存布局无关,引用的目标并不一定加载到内存中,同一个符号引用在不同虚拟机实例上翻译出来的直接引用一般不会相同。
- 初始化。静态方法使用<cinit>,实例对象使用<init>,对象存进Java堆。
- 寻找main方法执行,之后就是一个方法堆着一个方法的用了。
四、垃圾回收机制
在内存模型中,我们需要重点关注的就是Heap。因为它是由我们来控制的,处理不当容易发生OOM。内存处理的步骤无非也就三个: 申请,整理,清除。管理内存打个比方就和管理卖戏票的,观众台也就几十个座位,都是宝贵的资源。vip大户,里边走,直接坐贵席。其他的买计时票看,每隔一定时间把到时的人清出去,但经常有人到时赖着不走,隔一段时间催他才走。有时候座满了,只能把到时的赖皮清出去,不想走可以交钱。有时候人家三五成群的买票,自然要调配一下,清理出一些连座的给客户对吧。如果是一大帮人来看,更是欢迎,vip里面请。
在Java的堆模型中划分为三个区。
- 新生代 。这个区域的对象活动频繁,朝生暮死的。能活下来的对象最终会被转移到老年代,为了管理这些对象,新生代还进行更细的划分。
- Eden
- From Survivor
- To Survivor
- 老年代 。这个区域的对象存活比较久。一般能在GC下躲过15次的对象都会保存到这里。如果申请大内存空间的对象,也是直接分配到这里。分配担保,最坏的情况,新生代没有足够的内存分配,则会分配到老年代,当然也会分析老年代剩余空间,判断是否要进行一次Full GC。
管理对象的生命周期
生存还是毁灭,是通过这个对象到GC Root的可到达性来决定的。能作为GC Root的对象有四种。
- 虚拟机栈引用的对象
- 方法区中常量引用的对象
- 方法区中静态属性引用的变量
- 本地方法栈中native方法引用的对象
引用类型有四种,强引用,软引用,弱引用,虚引用。
- 新生代对象的整理--复制整理法。 这个区域由于活动频繁,容易更快的产生内存碎片,整理的时候还不能有大动作,所以这里使用复制法,对cpu停顿小,代价是占用一定的空间。
- 如果发生Minor GC的时候,将Eden 存活下来的对象复制到 From Survivor ,对象在From Survivor每躲过一次GC 年龄就会+1,达到一定的程度,就会被移动到老年代,否则还没死的话,就会移动到To Survivor ,如果To Survivor放不下了,这个对象会被移动到老年代。最后清空Eden 和 From Survivor,接着将To 和 From 交换,当To Survivor满了就会将这些移动到老年代。
- 如何保证新生代对象被老年代引用的时候不被gc?有些新生代对象会被老年代对象引用,然而老年代空间很大,如果每次Minor GC 都扫描一遍老年代,效率将大大降低,所有在老年代会划分一个小区域来管理卡表,这写卡表记录了老年代和新生代的引用,也就是说这些老年代被当成新生代的GC roots。
- 老年代对象的整理--标记整理法。 这个区域整理的时间间隔比较长,因为它们都是比较长久的数据,所以可以使用标记法来处理,但对cpu停顿大。
- 初始化标记。 这时候会暂停“全世界(stop-the-world)”,开始进行标记。仅仅标记GC Roots能直接关联到的对象。
- 并发标记。 从GC Roots开始进行可达性分析,找出存活对象,耗时长,就是进行追踪引用链的过程,可与用户线程并发执行。
- 重新标记。 修正并发标记阶段因用户线程继续运行而导致标记发生变化的那部分对象的标记记录。这个阶段也会再次暂停所有事件。
- 并行清理。 最后执行清理,这个阶段也是并行的。
结语,限于篇幅,只是初略的整理了一下大致的流程,参考《深入Java虚拟机》等。
正文到此结束
- 本文标签: 并发 突破 操作系统 map http 内存模型 垃圾回收 Android 字节码 tab 广告 开源 NSA 处理器 时间 模型 root https 参数 单元测试 安全 src 多线程 IO HTML JVM 测试 数据库 总结 IDE 线程池 代码 id web 网卡 快的 缓存 cat lib API 图片 程序员 索引 翻译 2019 find final 数据 ACE 编程习惯 mmap java ip 实例 静态方法 进程 同步 管理 constant App 性能优化 编译 递归 开发 UI 生命 SDN MQ linux 解析 Full GC db 线程 Java类 大数据 Action 空间 bug ssl
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

