Java8 - Stream API快速入门
Java8旨在帮助程序员写出更好的代码,
其对核心类库的改进也是关键的一部分, Stream 是Java8种处理集合的抽象概念,
它可以指定你希望对集合的操作,但是执行操作的时间交给具体实现来决定。
为什么需要Stream?
Java语言中集合是使用最多的API,几乎每个Java程序都会用到集合操作,
这里的Stream和IO中的Stream不同,它提供了对集合操作的增强,极大的提高了操作集合对象的便利性。
集合对于大多数编程任务而言都是基本的,为了解释集合是怎么工作,我们想象一下当下最火的外卖APP,
当我们点菜的时候需要按照 距离 、 价格 、 销量 等进行排序后筛选出自己满意的菜品。
你可能想选择距离自己最近的一家店铺点菜,尽管用集合可以完成这件事,但集合的操作远远算不上完美。
假如让你编写上面示例中的代码,你可能会写出如下:
// 店铺属性
public class Property {
String name;
// 距离,单位:米
Integer distance;
// 销量,月售
Integer sales;
// 价格,这里简单起见就写一个级别代表价格段
Integer priceLevel;
public Property(String name, int distance, int sales, int priceLevel) {
this.name = name;
this.distance = distance;
this.sales = sales;
this.priceLevel = priceLevel;
}
// getter setter 省略
}
复制代码
我想要筛选距离我最近的店铺,你可能会写下这样的代码:
public static void main(String[] args) {
Property p1 = new Property("叫了个鸡", 1000, 500, 2);
Property p2 = new Property("张三丰饺子馆", 2300, 1500, 3);
Property p3 = new Property("永和大王", 580, 3000, 1);
Property p4 = new Property("肯德基", 6000, 200, 4);
List<Property> properties = Arrays.asList(p1, p2, p3, p4);
Collections.sort(properties, (x, y) -> x.distance.compareTo(y.distance));
String name = properties.get(0).name;
System.out.println("距离我最近的店铺是:" + name);
}
复制代码
这里也使用了部分lambda表达式,在Java8之前你可能写的更痛苦一些。
要是要处理大量元素又该怎么办呢?为了提高性能,你需要并行处理,并利用多核架构。
但写并行代码比用迭代器还要复杂,而且调试起来也够受的!
但 Stream 中操作这些东西当然是非常简单的,小试牛刀:
// Stream操作
String name2 = properties.stream()
.sorted(Comparator.comparingInt(x -> x.distance))
.findFirst()
.get().name;
System.out.println("距离我最近的店铺是:" + name);
复制代码
新的API对所有的集合操作都提供了生成流操作的方法,写的代码也行云流水,我们非常简单的就筛选了离我最近的店铺。
在后面我们继续讲解Stream更多的特性和玩法。
外部迭代和内部迭代
当你处理集合时,通常会对它进行迭代,然后处理返回的每个元素。比如我想看看月销量大于1000的店铺个数。
使用for循环进行迭代
int count = 0;
for (Property property : properties) {
if(property.sales > 1000){
count++;
}
}
复制代码
上面的操作是可行的,但是当每次迭代的时候你需要些很多重复的代码。将for循环修改为并行执行也非常困难,
需要修改每个for的实现。
从集合背后的原理来看,for循环封装了迭代的语法糖,首先调用iterator方法,产生一个Iterator对象,
然后控制整个迭代,这就是 外部迭代 。迭代的过程通过调用Iterator对象的hasNext和next方法完成。
使用迭代器进行计算
int count = 0;
Iterator<Property> iterator = properties.iterator();
while(iterator.hasNext()){
Property property = iterator.next();
if(property.sales > 1000){
count++;
}
}
复制代码
而迭代器也是有问题的。它很难抽象出 未知的不能操作 ;此外它本质上还是串行化的操作,总体来看使用
for循环会将行为和方法混为一谈。
另一种办法是使用内部迭代完成, properties.stream() 该方法返回一个Stream而不是迭代器。
使用内部迭代进行计算
long count = properties.stream()
.filter(p -> p.sales > 1000)
.count();
复制代码
上述代码是通过Stream API完成的,我们可以把它理解为2个步骤:
- 找出所有销量大于1000的店铺
- 计算出店铺个数
为了找出销量大于1000的店铺,需要先做一次过滤:filter,你可以看看这个方法的入参就是前面讲到的Predicate断言型函数式接口,
测试一个函数完成后,返回值为boolean。
由于Stream API的风格,我们没有改变集合的内容,而是描述了Stream的内容,最终调用count()方法计算出Stream
里包含了多少个过滤之后的对象,返回值为long。
创建Stream
你已经知道Java8种在Collection接口添加了Stream方法,可以将任何集合转换成一个Stream。
如果你操作的是一个数组可以使用 Stream.of(1, 2, 3) 方法将它转换为一个流。
也许有人知道JDK7中添加了一些类库如 Files.readAllLines(Paths.get("/home/biezhi/a.txt")) 这样的读取文件行方法。
List 作为 Collection 的子类拥有转换流的方法,那么我们读取这个文本文件到一个字符串变量中将变得更简洁:
String content = Files.readAllLines(Paths.get("/home/biezhi/a.txt")).stream()
.collect(Collectors.joining("/n"));
复制代码
这里的collect是后面要讲解的 收集器 ,对Stream进行了处理后得到一个文本文件的内容。
JDK8也为我们提供了一些便捷的Stream相关类库:
创建一个流是很简单的,下面我们试试用创建好的Stream做一些操作吧。
流操作
java.util.stream.Stream中定义了许多流操作的方法,为了更好的理解Stream API掌握它常用的操作非常重要。
流的操作其实可以分为两类: 处理操作 、 聚合操作 。
- 处理操作:诸如filter、map等处理操作将Stream一层一层的进行抽离,返回一个流给下一层使用。
- 聚合操作:从最后一次流中生成一个结果给调用方,foreach只做处理不做返回。
filter
filter看名字也知道是过滤的意思,我们通常在筛选数据的时候用到,频率非常高。
filter方法的参数是 Predicate<T> predicate 即一个从T到boolean的函数。
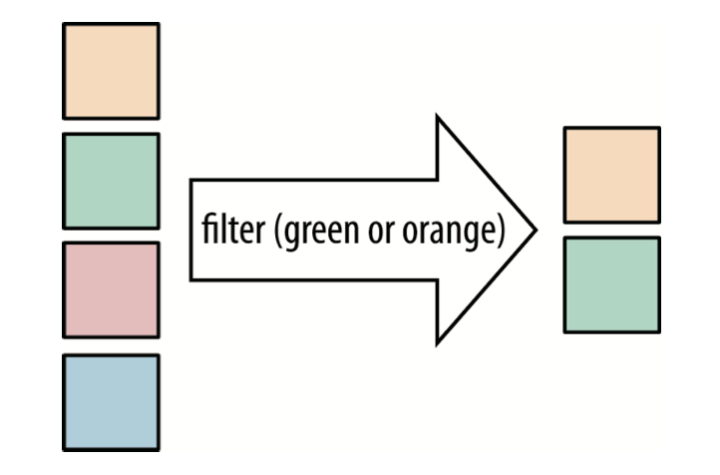
筛选出距离我在1000米内的店铺
properties.stream()
.filter(p -> p.distance < 1000)
复制代码
筛选出名称大于5个字的店铺
properties.stream()
.filter(p -> p.name.length() > 5);
复制代码
map
有时候我们需要将流中处理的数据类型进行转换,这时候就可以使用map方法来完成,将流中的值转换为一个新的流。
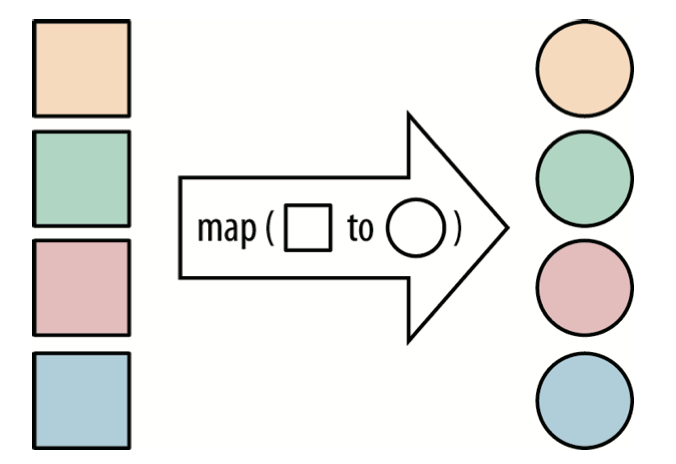
列出所有店铺的名称
properties.stream()
.map(p -> p.name);
复制代码
传给map的lambda表达式接收一个Property类型的参数,返回一个String。
参数和返回值不必属于同一种类型,但是lambda表达式必须是Function接口的一个实例。
flatMap
有时候我们会遇到提取子流的操作,这种情况用的不多但是遇到flatMap将变得更容易处理。
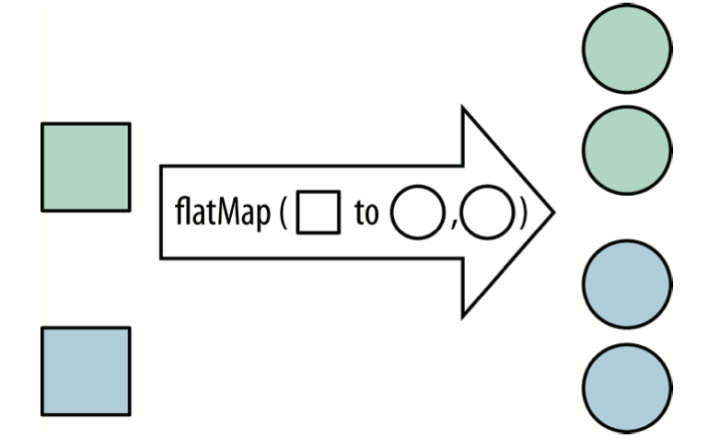
例如我们有一个 List<List<String>> 结构的数据:
List<List<String>> lists = new ArrayList<>();
lists.add(Arrays.asList("apple", "click"));
lists.add(Arrays.asList("boss", "dig", "qq", "vivo"));
lists.add(Arrays.asList("c#", "biezhi"));
复制代码
要做的操作是获取这些数据中长度大于2的单词个数
lists.stream()
.flatMap(Collection::stream)
.filter(str -> str.length() > 2)
.count();
复制代码
在不使用flatMap前你可能需要做2次for循环。这里调用了List的stream方法将每个列表转换成Stream对象,
其他的就和之前的操作一样。
max和min
Stream中常用的操作之一是求最大值和最小值,Stream API 中的max和min操作足以解决这一问题。
我们需要筛选出价格最低的店铺:
Property property = properties.stream()
.max(Comparator.comparingInt(p -> p.priceLevel))
.get();
复制代码
查找Stream中的最大或最小元素,首先要考虑的是用什么作为排序的指标。
以查找价格最低的店铺为例,排序的指标就是 店铺的价格等级 。
为了让Stream对象按照价格等级进行排序,需要传给它一个Comparator对象。
Java8提供了一个新的静态方法comparingInt,使用它可以方便地实现一个比较器。
放在以前,我们需要比较两个对象的某项属性的值,现在只需要提供一个存取方法就够了。
收集结果
通常我们处理完流之后想查看一下结果,比如获取总数,转换结果,在前面的示例中你发现调用了
filter、map之后没有下文了,后续的操作应该调用Stream中的collect方法完成。
获取距离我最近的2个店铺
List<Property> properties = properties.stream()
.sorted(Comparator.comparingInt(x -> x.distance))
.limit(2)
.collect(Collectors.toList());
复制代码
获取所有店铺的名称
List<String> names = properties.stream()
.map(p -> p.name)
.collect(Collectors.toList());
复制代码
获取每个店铺的价格等级
Map<String, Integer> map = properties.stream()
.collect(Collectors.toMap(Property::getName, Property::getPriceLevel));
复制代码
所有价格等级的店铺列表
Map<Integer, List<Property>> priceMap = properties.stream()
.collect(Collectors.groupingBy(Property::getPriceLevel));
复制代码
并行数据处理
并行和并发
并发是两个任务共享时间段,并行则是两个任务在同一时间发生,比如运行在多核CPU上。
如果一个程序要运行两个任务,并且只有一个CPU给它们分配了不同的时间片,那么这就是并发,而不是并行。
并行化是指为缩短任务执行时间,将一个任务分解成几部分,然后并行执行。
这和顺序执行的任务量是一样的,区别就像用更多的马来拉车,花费的时间自然减少了。
实际上,和顺序执行相比,并行化执行任务时,CPU承载的工作量更大。
数据并行化是指将数据分成块,为每块数据分配单独的处理单元。
还是拿马拉车那个例子打比方,就像从车里取出一些货物,放到另一辆车上,两辆马车都沿着同样的路径到达目的地。
当需要在大量数据上执行同样的操作时,数据并行化很管用。
它将问题分解为可在多块数据上求解的形式,然后对每块数据执行运算,最后将各数据块上得到的结果汇总,从而获得最终答案。
人们经常拿任务并行化和数据并行化做比较,在任务并行化中,线程不同,工作各异。
我们最常遇到的JavaEE应用容器便是任务并行化的例子之一,每个线程不光可以为不同用户服务,
还可以为同一个用户执行不同的任务,比如登录或往购物车添加商品。
Stream并行流
流使得计算变得容易,它的操作也非常简单,但你需要遵守一些约定。默认情况下我们使用集合的stream方法
创建的是一个串行流,你有两种办法让他变成并行流。
- 调用 Stream 对象的 parallel 方法
- 创建流的时候调用 parallelStream 而不是stream方法
我们来用具体的例子来解释串行和并行流
串行化计算
筛选出价格等级小于4,按照距离排序的2个店铺名
properties.stream()
.filter(p -> p.priceLevel < 4)
.sorted(Comparator.comparingInt(Property::getDistance))
.map(Property::getName)
.limit(2)
.collect(Collectors.toList());
复制代码
调用 parallelStream 方法即能并行处理
properties.parallelStream()
.filter(p -> p.priceLevel < 4)
.sorted(Comparator.comparingInt(Property::getDistance))
.map(Property::getName)
.limit(2)
.collect(Collectors.toList());
复制代码
读到这里,大家的第一反应可能是立即将手头代码中的stream方法替换为parallelStream方法,
因为这样做简直太简单了!先别忙,为了将硬件物尽其用,利用好并行化非常重要,但流类库提供的数据并行化只是其中的一种形式。
我们先要问自己一个问题: 并行化运行基于流的代码是否比串行化运行更快? 这不是一个简单的问题。
回到前面的例子,哪种方式花的时间更多取决于串行或并行化运行时的环境。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

