为啥HashMap的长度一定是2的n次方
首先你应当记住的: 不管你传不传参数,不管你传入的长度为多少,在你用HashMap的时候,他的长度都是2的n次方,且最大长度为2的30次方
最大长度
在HashMap的源码中,最大长度这个常量值是这样定义的
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
复制代码
这个值用在哪里呢?
- resize()函数,这个是用来扩容的
- tableSizeFor(),这个也是用来扩容的
- 构造函数中
- putEntries(),存放一组HashMap元素时,不是存放单个
为什么table长度一定是2的n次方
注意,源码中他们采用了 延迟初始化操作 ,也就是table只有在用到的时候才初始化,如果你不对他进行 put 等操作的话,table的长度永远为"零"
主要有两个函数保证了他的长度为2的n次方
- tableSizeFor()
- resize()
至于计算过程以及加载过程,请参考我的这篇文章: table的长度到底是多少
这篇文章我从源码分析table的创建过程,包括上面提到的函数的调用,看了这个你一定明白为啥 table 的长度一定是2的n次方
当然我针对hashMap写的一部分源码的中文注释github上也有: HashMap源码中文注释
2的n次有什么好处
- 计算方便
- hash分布更均匀
分布均匀
如果不是2的n次方,那么有些位置上是永远不会被用到
具体可以参考这篇博文,他用例子讲述了为什么,为啥长度要是2的n次方
计算方便
-
当容量一定是2^n时,h & (length - 1) == h % length
-
扩容后计算新位置,非常方便,相比 JDK1.7
JDK 1.8改动
在 JDK1.8 中,HashMap有了挺大的改动,包括
-
元素迁移算法(旧的到新的数组)
-
使用红黑树
-
链表为尾插法
其中我重点讲下元素迁移算法,JDK1.8的时候
首先看下java代码以及我的注释,如果要看完整的, 可以看我的github仓库
// 将原来数组中的所有元素都 copy进新的数组
if(oldTab != null){
for (int j = 0; j < oldCap; j++) {
Entry e;
if((e = oldTab[j]) != null){
oldTab[j] = null;
// 说明还没有成链,数组上只有一个
if(e.next == null){
// 重新计算 数组索引 值
newTable[e.h & (newCap-1)] = e;
}
// 判断是否为树结构
//else if (e instanceof TreeNode)
// 如果不是树,只是链表,即长度还没有大于 8 进化成树
else{
// 扩容后,如果元素的 index 还是原来的。就使用这个lo前缀的
Entry loHead=null, loTail =null;
// 扩容后 元素index改变,那么就使用 hi前缀开头的
Entry hiHead = null, hiTail = null;
Entry next;
do {
next = e.next;
//这个非常重要,也比较难懂,
// 将它和原来的长度进行相与,就是判断他的原来的hash的上一个 bit 位是否为 1。
//以此来判断他是在相同的索引还是table长度加上原来的索引
if((e.h & oldCap) == 0){
// 如果 loTail == null ,说明这个 位置上是第一次添加,没有哈希冲突
if(loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else{
if(hiTail == null)
loHead = e;
else
hiTail.next = e;
hiTail = e ;
}
}while ((e = next) != null);
if(loTail != null){
loTail.next = null;
newTable[j] = loHead;
}
// 新的index 等于原来的 index+oldCap
else {
hiTail.next = null;
newTable[j+oldCap] = hiHead;
}
}
}
}
}
复制代码
我们看到上面源码的最后一句, newTable[j+oldCap] = hiHead; 意思就是哪怕我们的元素从旧的数组迁移到新的数组,我们也不需要重新计算他的hash和新数组长度相与的值,只需要直接将现在的 索引值+原来数组的长度 即可
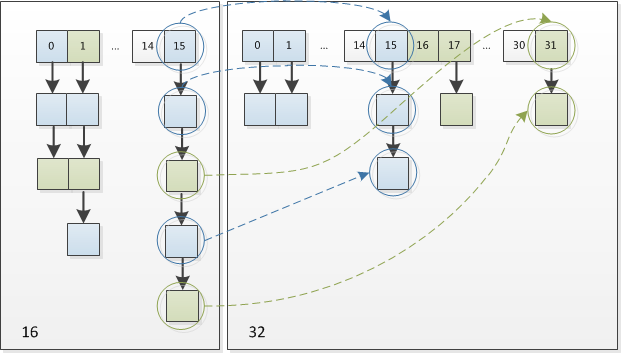
蓝色的表示不需要移动的,绿色的表示需要重新计算索引的,我们看到,他只是加了16(原来的数组table长度)
计算索引需要
我们注意到上面的源代码中,判断扩容后元素位置需不需要改变的时候,我们使用到了这个判断
if((e.h & oldCap) == 0) ,
如果为0,那么就不需要改变,使用旧的索引即可;如果为1,那么就需要使用新的索引
为啥会这样呢?
- 如果元素的索引要变那么
hash&(newTable.length-1)一定是和hash&(oldTable.length-1)+oldTable.length相等 - 因为table的长度一定是2的n次方,也就是oldCap 一定是2的n次方,也就是说 oldCap有且只有一位是1,而且这个位置在最高位;
我们来举个例子:
我们假设元素的hash值的后12位是 110111010111,数组原来的长度为16,扩容后数组长度为32
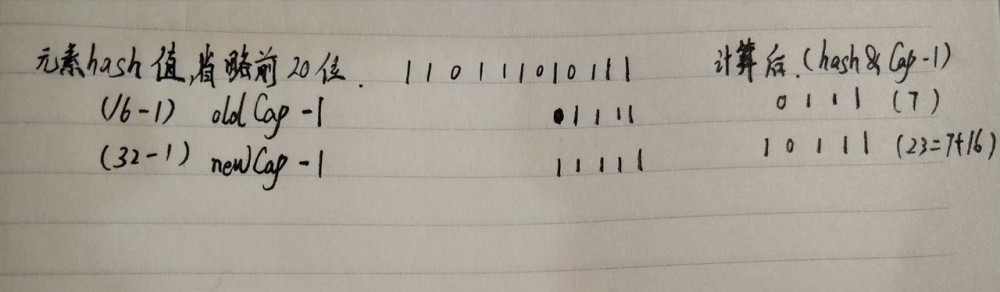
你可以试下下次扩容时,扩容到64时,索引变不变化。当然答案是不会变化,因为元素的hash值在那个位置为 0
对比1.7扩容
我们来对比JDK1.7 的方式,他如果要扩容,并且扩容后计算元素的索引的话要使用 indexFor函数
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
复制代码
也就是要把元素的hash值重新再和新的数组长度-1 再相与一次,会比较麻烦而且不优雅,完全没有我看到1.8计算方式的那种惊艳感。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

