SpringCloud之Hystrix

简介
在分布式环境中,许多服务依赖关系中的一些必然会失败。Hystrix是一个库,它通过添加延迟容忍和容错逻辑来帮助您控制这些分布式服务之间的交互。Hystrix通过隔离服务之间的访问点、停止跨服务的级联故障并提供回退选项来实现这一点,所有这些选项都提高了系统的总体弹性。
目标
Hystrix的设计目的如下:
- 为通过第三方客户端库访问的依赖项(通常通过网络)提供保护和控制延迟和故障。
- 停止复杂分布式系统中的级联故障。
- 故障快速恢复。
- 在可能的情况下,后退并优雅地降级。
- 启用近实时监视、警报和操作控制。
背景
为了解决什么问题?
复杂分布式体系结构中的应用程序有几十个依赖项,每个依赖项在某个时候都不可避免地会失败。如果主机应用程序没有从这些外部故障中隔离出来,那么它就有可能与这些外部故障一起宕机。
例如,对于一个依赖于30个服务的应用程序,其中每个服务都有99.99%的正常运行时间,您可以这样期望:
99.9930 = 99.7% uptime
0.3% of 1 billion requests = 3,000,000 failures
2+ hours downtime/month even if all dependencies have excellent uptime.
现实通常更糟。
即使当所有依赖项都运行良好时,即使0.01%的停机时间对几十个服务中的每个服务的总体影响也相当于一个月潜在的停机时间(如果您不为恢复而设计整个系统)。
如下面的图演变:
当一切正常时,请求流可以是这样的:
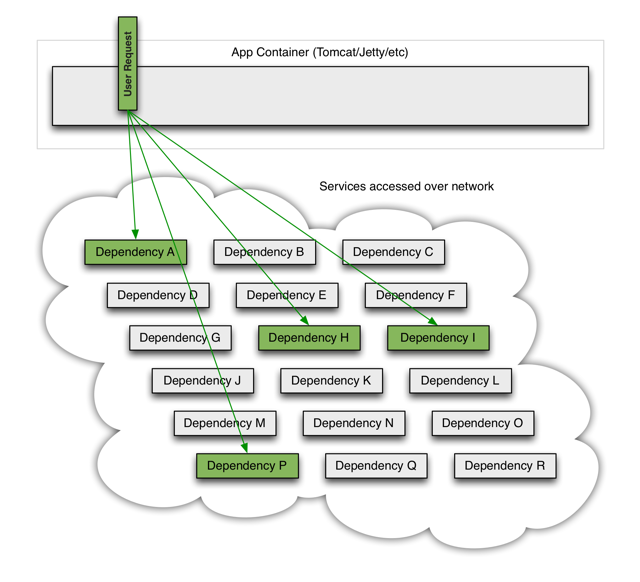
当许多后端系统之一成为潜在,它可以阻止整个用户请求:
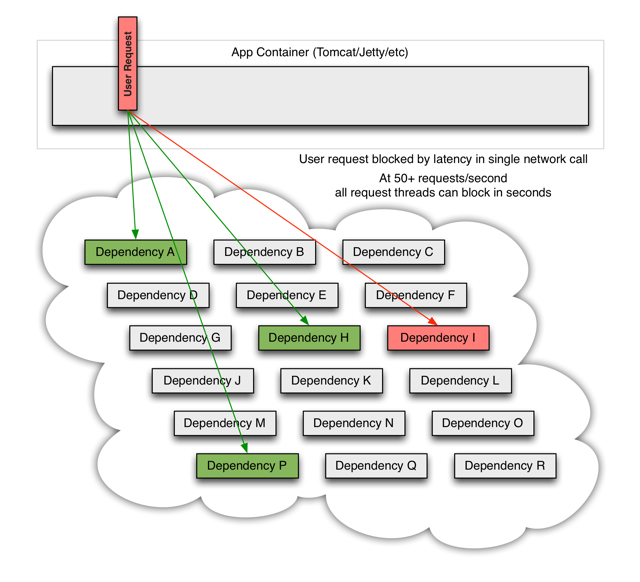
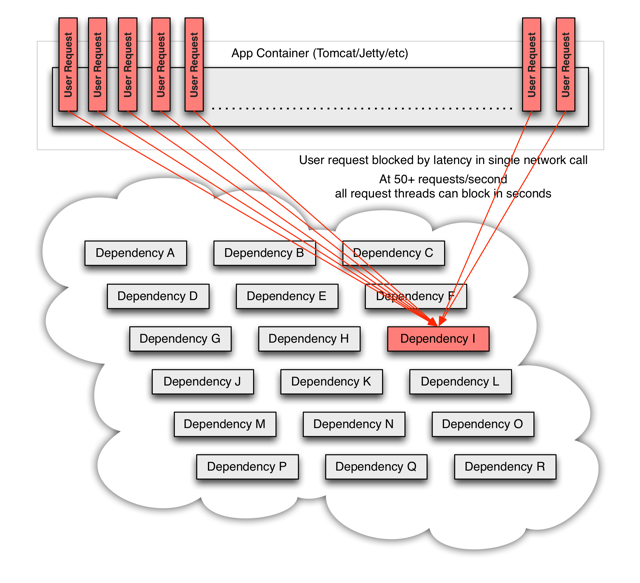
对于高流量,一个后端依赖项成为潜在,可能会导致所有服务器上的所有资源在几秒钟内饱和。
应用程序中通过网络或客户机库到达可能导致网络请求的每个点都是潜在故障的来源。比故障更糟的是,这些应用程序还可能导致服务之间的延迟增加,从而备份队列、线程和其他系统资源,从而导致系统中出现更多级联故障。
工作原理
工作流程图:
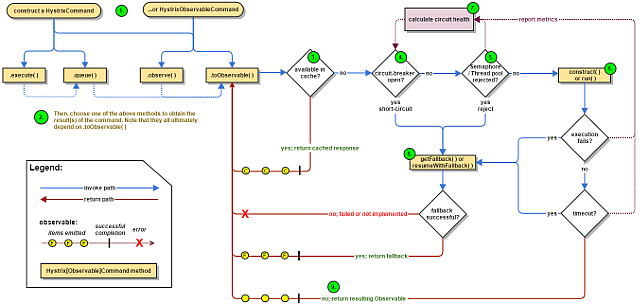
1. 构造一个HystrixCommand或HystrixObservableCommand对象
第一步是构造一个HystrixCommand或HystrixObservableCommand对象来表示对依赖项的请求。将请求发出时需要的任何参数传递给构造函数。
如果期望依赖项返回单个响应,则构造一个HystrixCommand对象。例如:
HystrixCommand command = new HystrixCommand(arg1, arg2);
如果期望依赖项返回发出响应的可观察对象,则构造一个HystrixObservableCommand对象。例如:
HystrixObservableCommand command = new HystrixObservableCommand(arg1, arg2);
2.执行命令
有四种方法可以执行命令,使用以下四种方法之一的Hystrix命令对象(前两种方法只适用于简单的HystrixCommand对象,不适用于HystrixObservableCommand):
-
execute()) — blocks, then returns the single response received from the dependency (or throws an exception in case of an error) -
queue()) — returns aFuturewith which you can obtain the single response from the dependency -
observe()) — subscribes to theObservablethat represents the response(s) from the dependency and returns anObservablethat replicates that sourceObservable -
toObservable()) — returns anObservablethat, when you subscribe to it, will execute the Hystrix command and emit its responses
3.是否缓存了响应
如果为该命令启用了请求缓存,并且在缓存中可用对请求的响应,则此缓存的响应将立即以可观察到的形式返回。
4. 电路打开了吗?
当您执行该命令时,Hystrix将与断路器一起检查电路是否打开。
如果电路打开(或“跳闸”),那么Hystrix将不执行命令,而是将流路由到(8)获取回退。
如果电路被关闭,则流继续到(5),检查是否有可用的容量来运行命令。
5.线程池/队列/信号量是否已满?
如果与该命令关联的线程池和队列(或信号量,如果不在线程中运行)已满,那么Hystrix将不执行该命令,而是立即将流路由到(8)获取回退。
6.HystrixObservableCommand.construct()或HystrixCommand.run ()
这里,Hystrix通过为此目的编写的方法调用对依赖项的请求,方法如下:
-
HystrixCommand.run()) — returns a single response or throws an exception -
HystrixObservableCommand.construct()) — returns an Observable that emits the response(s) or sends anonErrornotification
如果run()或construct()方法超过了命令的超时值,线程将抛出一个TimeoutException(如果命令本身不在自己的线程中运行,则单独的计时器线程将抛出一个TimeoutException)。在这种情况下,Hystrix将响应路由到8。获取回退,如果最终返回值run()或construct()方法没有取消/中断,那么它将丢弃该方法。
请注意,没有办法强制潜在线程停止工作——Hystrix在JVM上能做的最好的事情就是抛出InterruptedException。如果由Hystrix包装的工作不尊重interruptedexception,那么Hystrix线程池中的线程将继续它的工作,尽管客户机已经收到了TimeoutException。这种行为可能会使Hystrix线程池饱和,尽管负载“正确释放”。大多数Java HTTP客户端库不解释interruptedexception。因此,请确保正确配置HTTP客户机上的连接和读/写超时。
如果该命令没有抛出任何异常并返回一个响应,那么Hystrix将在执行一些日志记录和度量报告之后返回此响应。在run()的情况下,Hystrix返回一个可观察的对象,该对象发出单个响应,然后发出一个onCompleted通知;在construct()的情况下,Hystrix返回由construct()返回的相同的可观察值。
7.计算电路健康
Hystrix向断路器报告成功、失败、拒绝和超时,断路器维护一组滚动计数器,用于计算统计数据。
它使用这些统计数据来确定电路应该在什么时候“跳闸”,在这一点上,它会短路任何后续的请求,直到恢复期结束,在此期间,它会在第一次检查某些健康检查之后再次关闭电路。
8.回退
Hystrix试图恢复你的回滚命令执行失败时:当一个异常的构造()或()运行(6),当命令电路短路,因为打开(4),当命令的线程池和队列或信号能力(5),或者当命令已超过其超时长度。
详情参考官网: https://github.com/Netflix/Hy...
9. 返回成功的响应
如果Hystrix命令成功,它将以可观察到的形式返回响应或响应给调用者。根据您如何调用上面步骤2中的命令,这个可观察对象可能在返回给您之前进行转换:
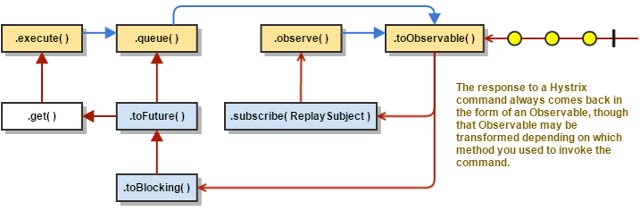
- execute() — 以与.queue()相同的方式获取一个Future,然后在这个Future上调用get()来获取可观察对象发出的单个值.
- queue() — 将可观察对象转换为BlockingObservable,以便将其转换为未来,然后返回此未来
- observe() — 立即订阅可观察对象,并开始执行命令的流;返回一个可观察对象,当您订阅该对象时,将重播排放和通知
- toObservable() — 返回可观察值不变;您必须订阅它,才能真正开始执行命令的流程
更多原理可以移步官网
https://github.com/Netflix/Hy...使用
加入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
在ribbon中使用
使用@EnableHystrix开启
@SpringBootApplication
@EnableEurekaClient
@EnableDiscoveryClient
@EnableHystrix
public class CloudServiceRibbonApplication {
public static void main(String[] args) {
SpringApplication.run(CloudServiceRibbonApplication.class, args);
}
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
}
}
该注解对该方法创建了熔断器的功能,并指定了fallbackMethod熔断方法,熔断方法直接返回了一个字符串,字符串为"hi,"+name+",sorry,error!"
@Service
public class TestService {
@Autowired
RestTemplate restTemplate;
@HystrixCommand(fallbackMethod = "hiError")
public String hiService(String name) {
return restTemplate.getForObject("http://CLOUD-EUREKA-CLIENT/hi?name="+name,String.class);
}
public String hiError(String name) {
return "hi,"+name+",sorry,error!";
}
}
在Feign中使用
feign.hystrix.enabled: true开启hystrix
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
server:
port: 8765
spring:
application:
name: cloud-service-feign
feign.hystrix.enabled: true
@EnableFeignClients启动
@SpringBootApplication
@EnableEurekaClient
@EnableDiscoveryClient
@EnableFeignClients
public class CloudServiceFeginApplication {
public static void main(String[] args) {
SpringApplication.run(CloudServiceFeginApplication.class, args);
}
}
fallback:配置连接失败等错误的返回类
@FeignClient(value = "cloud-eureka-client",fallback = TestServiceHystric.class)
public interface TestService {
@RequestMapping(value = "/hi",method = RequestMethod.GET)
String sayHiFromClientOne(@RequestParam(value = "name") String name);
}
当访问接口有问题时,直接调用此接口返回。
@Component
public class TestServiceHystric implements TestService{
@Override
public String sayHiFromClientOne(String name) {
return "sorry "+name;
}
}
更多使用技巧可参考官网:
https://github.com/Netflix/Hy...总结
在微服务架构中通常会有多个服务层调用,基础服务的故障可能会导致级联故障,进而造成整个系统不可用的情况,这种现象被称为服务雪崩效应。服务雪崩效应是一种因“服务提供者”的不可用导致“服务消费者”的不可用,并将不可用逐渐放大的过程。
熔断器的原理很简单,如同电力过载保护器。它可以实现快速失败,如果它在一段时间内侦测到许多类似的错误,会强迫其以后的多个调用快速失败,不再访问远程服务器,从而防止应用程序不断地尝试执行可能会失败的操作,使得应用程序继续执行而不用等待修正错误,或者浪费CPU时间去等到长时间的超时产生。熔断器也可以使应用程序能够诊断错误是否已经修正,如果已经修正,应用程序会再次尝试调用操作。
更多优质文章:
-
- http://www.ityouknow.com/spri...
-
- https://www.fangzhipeng.com/s...
-
- http://blog.didispace.com/tag...
最后
如果对 Java、大数据感兴趣请长按二维码关注一波,我会努力带给你们价值。觉得对你哪怕有一丁点帮助的请帮忙点个赞或者转发哦。

正文到此结束
- 本文标签: dependencies 线程池 配置 分布式系统 value tag 统计 spring https IO 大数据 Feign 参数 文章 db map springboot Excel 微服务 src git bean IDE ribbon REST ACE 服务器 cat 分布式 App 缓存 client struct Service 数据 springcloud Eureka http 备份 线程 id 时间 JVM 总结 queue ip UI Hystrix 二维码 主机 java tar 工作原理 GitHub Netflix
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

