JDK 5 中的 Lock 和 synchronized 的比较

前言
上一篇介绍了高效并发的前提条件:线程安全,从中我们学习到java语言通过”互斥同步“、”非阻塞同步“以及”无同步方案“等处理确保了并发情况下程序可以正确执行,解决了正确性的问题之后,我们将视线收回来:java如何实现并发情况下的高效处理呢?
jdk1.5之前,线程的锁处理主要依赖synchronized处理,jdk1.5版本中引入了java.util.concurrent包,提供了一个重要的接口Lock,ReentrantLock类作为Lock的重要实现,那我们难免要做一番比较,为啥要引入RentrantLock,synchronized修饰符过时了吗? 本章参考 Brian Goetz 的论文《More flexible, scalable locking in JDK 5.0》分析下JDK1.5中lock和synchronized的区别。
synchronized 分析
前面讲Java内存模型时我们聊到,synchronized是个全能型选手,可以同时满足原子性,可见性,有序性,使用方式支持修饰成员方法,静态方法,方法块,功能很强大,看起来很不错,那么,为什么JSR 166组要花这么多时间开发java.util.concurrent.lock框架呢 ?
答案很简单——synchronized很好,但并不完美。它有一些功能限制:
-
不可能中断正在等待获取锁的线程
-
也不可能轮询一个锁或尝试获取一个锁而不愿意永远等待它。
-
同步还要求在哪个栈帧中获得锁就要在哪个栈帧中释放锁,这在大多数情况下是正确的(并且与异常处理很好地交互),但也有少数情况下,非块结构锁(non-block-structured locking)可能是更好的选择。
ReentrantLock类介绍
java.util.concurrent.lock包中的锁框架是抽象的,它允许将锁的实现为Java类而不是语言特性(synchronized关键字是java的语言特性,而lock是基于jdk api实现),这为Lock的多种实现腾出了空间,这些实现可能具有不同的调度算法、性能特征或锁定语义。实现Lock接口的ReentrantLock类具有与synchronized相同的并发性和内存语义,而且还添加了锁轮询、定时等待和等待可中断等特性。此外,在激烈的竞争下,它提供了更好的性能。
ReentrantLock中文翻译为“可重入锁”,那么“可重入”是什么意思?简单地说,有一个与锁关联的计数器,如果持有锁的线程再次获得它,则将计数器加1,每次释放锁时计数器的值减1,当计数器的值为0时,才能真正释放锁。这与synchronized的语义相似(synchronized也支持可重入)。
ReentrantLock的使用方式如下:
Lock lock = new ReentrantLock();
lock.lock();
try {
// update object state
}
finally {
lock.unlock();
}
注意,如上代码所示,可以发现Lock和synchronized之间的一个直接区别——lock必须在finally块中释放。否则,如果受保护代码抛出异常,则可能永远不会释放锁!这种区别听起来可能微不足道,但实际上,它非常重要。忘记释放finally块中的锁会在您的程序中创建一个定时炸弹,当它最终在您身上爆炸时,您将很难跟踪它的源代码。通过同步,JVM可以确保锁被自动释放。
另外,ReentrantLock的实现在争用情况下比synchronized的伸缩性要好很多。这意味着,当许多线程都争用同一个锁时,使用ReentrantLock通常比使用synchronized的总吞吐量更好。
比较ReentrantLock与synchronized的吞吐量
有一组测试数据,测试结果如下:
-
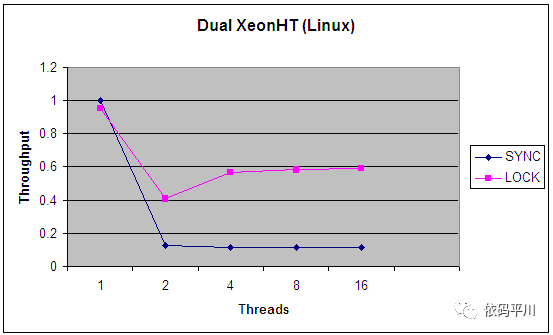
图1:单CPU,linux操作系统下synchronized与Lock的吞吐量对比
-
图2: 四cpu,windows操作系统下synchronized与Lock的吞吐量对比
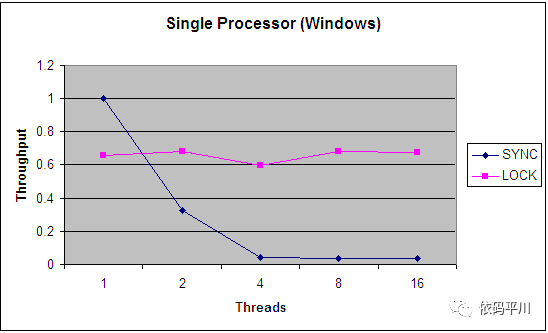
图3. 四cpu,linux操作系统下synchronized、非公平锁(Lock)和公平锁(FAIR)的相对吞吐量
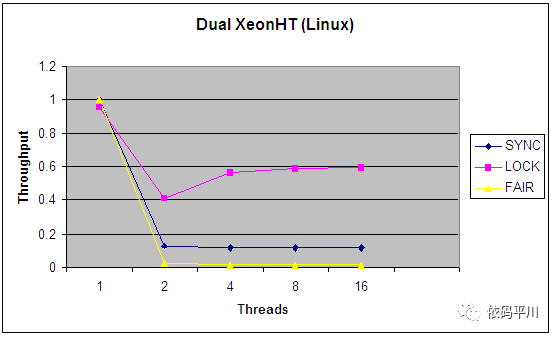
图4. 单个CPU,windows操作系统下,synchronized、非公平锁(Lock)和公平锁(FAIR)的相对吞吐量
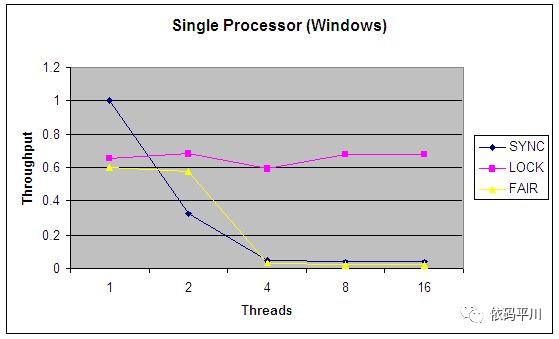
从以上的对比图中可以发现,synchronized 版本在面对任何类型的争用时表现得相当差,而Lock版本在调度开销上花费的时间要少得多,从而为更高的吞吐量和更有效的CPU利用率腾出了空间。
图三和图四比较了ReentrantLock的公平锁与非公平锁的吞吐量对比,从中可以发现,实现公平锁还是有比较大的开销的,会严重影响处理的吞吐率。
ReentrantLock各方面都好吗?
看起来ReentrantLock在各个方面都比synchronized好——它可以做synchronized做的所有事情,具有相同的内存和并发语义,具有synchronized没有的特性,并且在负载下具有更好的性能。那么,我们是否应该忘记synchronized,把它废弃呢?或者甚至根据ReentrantLock重写现有的同步代码?
事实上,有几本关于Java编程的介绍性书籍在其多线程章节中采用了这种方法,它们的示例完全是根据Lock来转换的,而只是顺便提到了synchronized, 个人认为,这种做法为时过早。
synchronized修饰符应该被抛弃吗?
虽然ReentrantLock是一个非常令人印象深刻的实现,并且与同步相比具有一些显著的优点,但是急着将synchronized看作是一个不受欢迎的特性会是一个严重的错误。java.util.concurrent.lock是针对高级用户和场景的高级工具。一般来说,您应该坚持使用synchronized,除非您对Lock的一个高级特性有特定的需求,或者您已经证明(不仅仅是怀疑)在这种特定情况下synchronized是可伸缩性瓶颈。
比较来看,ReentrantLock明显“更好”,为什么我们还要建议坚持使用synchronized呢?这么做是不是太“保守”了,不够"open",不够拥抱最新技术?
其实,与java.util.concurrent.lock中的锁定类相比,synchronized 仍然有一些优势:
-
首先,在使用synchronized时不可能忘记释放锁;当您退出同步块时,JVM会为您完成这项工作。相比之下,使用ReentrantLock则很容易忘记使用finally块来释放锁,从而对程序造成极大的损害。一旦因此出问题则很难找出原因(这本身就是不让初级开发人员使用lock的一个很好的理由)。
-
其次,当JVM使用synchronized管理锁获取和释放时,JVM能够在生成线程转储时包含锁信息。这些对于调试非常有用,因为它们可以确定死锁或其他意外行为的来源。Lock类只是普通类,JVM不知道哪些锁对象由特定的线程拥有。
-
最后,几乎每个Java开发人员都熟悉synchronized,并且可以在所有版本的JVM上工作。在JDK 5.0成为标准之前,使用Lock类将意味着利用不是每个JVM上都有的特性,也不是每个开发人员都熟悉的特性。
何时在synchronized上选择ReentrantLock
那么,什么时候应该使用ReentrantLock呢?答案非常简单——当synchronized无法真正满足你的需要时,比如定时等待锁、可中断锁、非块结构锁、绑定多个条件变量或锁轮询。ReentrantLock还具有可伸缩性的优点,如果您确实遇到了显示高争用的情况,那么应该使用它,但是请记住,绝大多数同步块几乎不显示任何争用,更不用说高争用了。我建议在证明synchronized不足之前使用synchronized进行开发,而不是简单地假设使用ReentrantLock“性能会更好”。请记住,这些都是面向高级用户的高级工具。(真正的高级用户倾向于选择他们能找到的最简单的工具,直到他们确信这些简单的工具是不够用的。)像往常一样,先把事情做好,然后再考虑是否要加快速度。
总结
Lock框架是synchronized的兼容替代品,它提供了synchronized没有提供的许多特性,以及在高并发情况下提供更好性能的实现。然而,存在这些明显的好处并不是始终选择ReentrantLock而不选synchronized的充分理由。相反,应该根据是否需要ReentrantLock的功能来进行决策。在绝大多数情况下,你不会使用到ReentrantLock,因为synchronized可以很好地工作:适用于所有jvm,更广泛的开发人员可以理解它,而且更不容易出错。
通过以上信息,我们了解到,jdk1.5中synchronized的性能明显低于ReentrantLock,但synchronized并没有被放弃,相反还被推荐优先使用,这就意味着其还有较大的优化空间,聪明的jvm开发人员在jdk1.6版本对synchronized锁进行了一些列高效的优化,优化完成后性能已经与ReentrantLock不相上下,究竟是怎么做到的呢?
且听下回分解。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

