深入理解 Java 虚拟机:锁优化

前言
上一篇介绍了jdk1.5引入了java.util.concurrent.lock包,实现了api层面的可重入锁——ReentrantLock,并对比了synchronized与ReentrantLock的区别, 看起来ReentrantLock在各个方面都比synchronized好,但是仍然推荐优先使用synchronized处理并发问题,说明jdk1.5中的synchronized锁还有很大的优化空间,为提升synchronized锁性能,JVM团队在后续版本中进行了优化,这就要从JDK1.6开始说起。
高效并发是JDK1.6的一个重要主题,HotSpot团队在这个版本上花费了大量的精力去实现各种锁的优化技术,如:自旋锁、自适应自旋、锁消除、锁粗化、轻量级锁、偏向锁等,这些技术都是为了在线程之间更高效地共享数据,以及解决竞争问题,从而提高程序的执行效率。本节我们重点来了解下这些锁优化技术。
自旋锁
-
阻塞实现的弊端
-
互斥同步对性能影响最大的是阻塞的实现,线程的挂起和恢复操作都要转入内核态完成,这些为操作系统的并发性能带来了很大的压力。
-
虚拟机的开发团队也注意到在许多应用上,共享数据的锁定状态只会持续很短的一段时间,为了这段时间去挂起和恢复线程并不值得。
-
解决方案——自旋锁
当多个线程并行执行时,让后面请求锁的线程“稍等一下”,但不放弃CPU的处理时间,看看持有锁的线程是否很快就会释放锁。为了让线程等待,我们只需要让线程执行忙循环(自旋),这项技术就是所谓的自旋锁。示例代码如下:
for(;;){ doSomething() } -
自旋锁一定好吗?
自旋等待虽然避免了线程切换的开销,但它是要占用处理器时间的,如果锁被占用的时间很短,自旋等待的效果会非常好;否则,如果锁被占用的时间很长,那么自旋的线程只会白白消耗处理器资源,而不会做任何有用的工作,反而会带来性能上的浪费。
因此,自旋等待的时间必须要有一定的限度,如果自旋超过了限定的次数仍然没有成功获得锁,就应当使用传统的方式去挂起线程了。自旋次数的默认值是10,可以使用参数-XX:PreBlockSpin来更改。
-
注: JDK1.4.2就已经引入自旋锁,只不过默认是关闭的,可以使用 -XX:UseSpinning参数开启,在JDK1.6中就已经改为默认开启了。
自适应自旋
-
什么是自适应自旋
在JDK1.6中引入了自适应的自旋锁。自适用意味着自旋的时间不在固定了,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。
-
如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也很有可能在此成功,进而它将允许自旋等待持续相对更长的时间,比如100个循环。
-
如果对于某个锁,自旋很少成功获得过,那在以后要获取这个锁时将可能省略掉自旋过程,以免浪费处理器资源。
-
自适应自旋的好处
有了自适应自旋,随着程序运行和性能监控信息的不断完善,虚拟机对程序锁的状况预测就会越来越准确(有点像机器学习),虚拟机就会变得越来越"聪明"了。
锁消除
-
什么是锁消除?
锁消除是指虚拟机及时编译器在运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行消除。
-
锁消除的原理
锁消除的主要判定依据来源于逃逸分析的数据支持(逃逸分析技术请自行查阅相关资料),如果判断到一段代码中,在堆上的所有数据都不会逃逸出去被其他线程访问到,那就可以把它们当做栈上数据对待,认为它们是线程私有的,同步加锁自然也就无须进行。
-
参考案例
以下是一段看起来没有同步的代码
public String concatString(String s1,String s2,String s3){ return s1+s2+s3; }这段代码通过javac转换后会变为字符串的连接操作,在JDK1.5之前的版本中使用的是StringBuffer的append()操作。
public String concatString(String s1,String s2,String s3){ StringBuffer sb = new StringBuffer(); sb.append(s1); sb.append(s2); sb.append(s3); return sb.toString(); }从中可以看出,虽然源代码貌似没有加锁处理,但到了虚拟机底层,会使用的StringBuffer的append()做拼接操作,而StringBuffer的append操作通过跟踪代码,可以发现是有加锁处理的:
@Override public synchronized StringBuffer append(String str) { toStringCache = null; super.append(str); return this; }以上代码,虚拟机观察变量sb,很快就会发现它的动态作用域被限制在concatString()方法内部,也就是sb的所有引用永远不会“逃逸”到concatString()方法之外,其他线程无法访问到它,所以这里虽然有锁,但是可以被安全地消除掉,在即时编译之后,这段代码会忽略掉所有的同步而直接执行了。
注:在JDK1.5之后的版本,字符串的拼接由StringBuffer的append()操作(有synchronize修饰)优化为StringBuilder中的append()操作(无synchronized修饰)了,进一步减少了底层处理逻辑,提升了效率。
锁粗化
原则上,我们在编写代码的时候,总是推荐将同步块的作用范围限制得尽量小——只在共享数据的实际作用域中才进行同步,这样是为了使得需要同步的操作数量尽可能变小,如果存在竞争锁,那等待锁的线程也能尽快地拿到锁。
大部分情况下,上面的原则都是正确的,但是如果一系列的连续操作都对同一个对象反复加锁和解锁,甚至加锁操作都是出现在循环体中的,那即使没有线程竞争,频繁地进行互斥同步操作也会导致不必要的性能损耗。
如果虚拟机探测到有这样的一串零碎的操作都对同一个对象加锁,将会把加锁同步的范围扩展(粗化)到整个操作序列的外部,这样只需要加锁一次就可以了。
案例
public void testLockCoarsing (){
while(true){
synchronized(lock){
doSomething();
}
}
}
优化后
public void testLockCoarsing(){
synchronized(lock){
while(true){
doSomething();
}
}
}
对象头
在介绍偏向锁和轻量级锁之前,我们需要了解一个重要的概念:对象头
对象头介绍
在Hotspot虚拟机中,对象在内存中的布局分为三块区域:对象头、实例数据和对齐填充;Java对象头分为两部分信息:
-
Mark Word
用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程 ID、偏向时间戳等,这部分数据的长度在32位和64位虚拟机中分别对应32个和64个Bits,官方称它为“Mark Word”,它是实现轻量级锁和偏向锁的关键。
注:32位和64位虚拟机中Mark Word结构如下图所示:
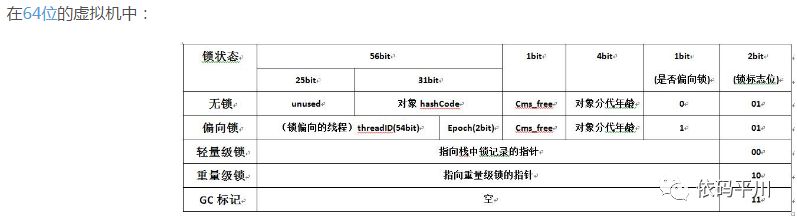
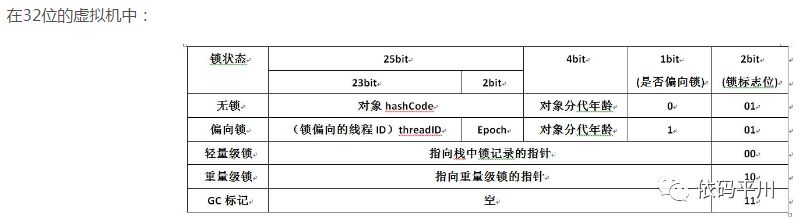
-
用于存储指向方法区对象类型数据的指针
如果是数组对象的话,还会有一个额外的部分用于存储数组长度
对象头在源码中的体现
如果想更深入了解对象头在JVM源码中的定义,需要关心几个文件,oop.hpp/markOop.hpp oop.hpp,每个 Java Object 在 JVM 内部都有一个 native 的 C++ 对象 oop/oopDesc 与之对应。先在oop.hpp中看oopDesc的定义
class oopDesc {
friend class VMStructs;
private:
volatile markOop _mark;
……
}
_mark 被声明在 oopDesc 类的顶部,所以这个 _mark 可以认为是头部, 头部保存了一些重要的状态和标识信息,在markOop.hpp文件中有一些注释说明markOop的内存布局
// 32 bits: // -------- // hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object) // JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object) // size:32 ------------------------------------------>| (CMS free block) // PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object) // // 64 bits: // -------- // unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object) // JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object) // PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object) // size:64 ----------------------------------------------------->| (CMS free block) // // unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object) // JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object) // narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object) // unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
synchronized的锁升级和获取过程
了解了对象头以后,接下来去分析synchronized的锁升级,就会非常简单了。前面讲过synchronized的锁是进行过优化的,引入了偏向锁、轻量级锁;锁的级别从低到高逐步升级, 无锁->偏向锁->轻量级锁->重量级锁.
偏向锁 偏向锁的概念
偏向锁也是JDK1.6中引入的一项锁优化,它的目的是消除数据在无竞争情况下的同步原语,进一步提高程序的运行性能。
JVM的开发人员发现,大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程ID,以后该线程进入和退出同步块时不需要进行CAS操作来加锁和解锁,只需简单地测试一下对象头的Mark Word里是否存储着指向当前线程的偏向锁。如果测试成功,表示线程已经获得了锁。如果测试失败,则需要再测试一下Mark Word中偏向锁的标识是否设置成1(表示当前是偏向锁):如果没有设置,则使用CAS竞争锁;如果设置了,则尝试使用CAS将对象头的偏向锁指向当前线程。
偏向锁的设置和撤销 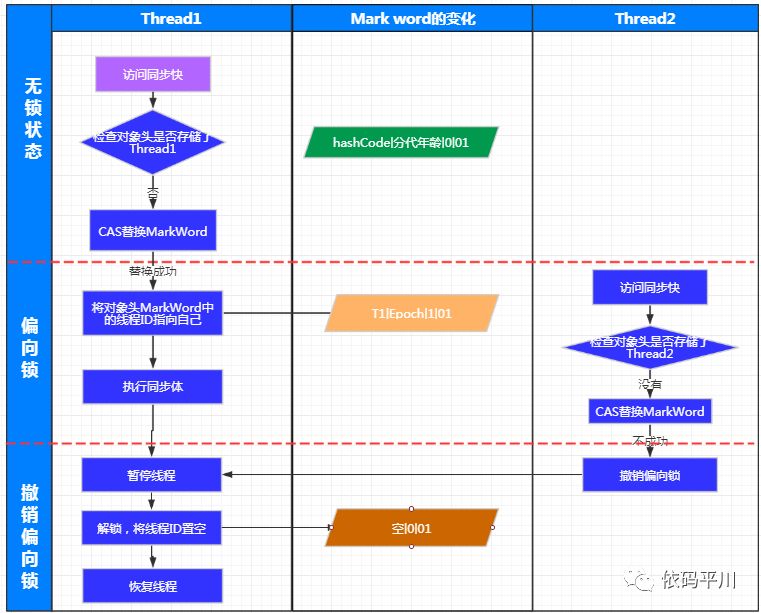
偏向锁的设置及撤销流程图
如果说轻量级锁是在无竞争的情况下使用CAS操作去消除同步使用的互斥量,那偏向锁就是在无竞争的情况下把整个同步都消除掉,连CAS操作都不做了。
辩证地看偏向锁的作用
偏向锁可以提高带有同步但无竞争的程序性能。它同样是一个带有效益权衡性质的优化,也就是说它并不一定总是对程序运行有利,如果程序中大多数的锁都是总被多个不同的线程访问,那偏向模式就是多余的。在具体问题具体分析的前提下,有时候使用参数-XX:-UseBaisedLocking 来禁止偏向锁优化反而可以提升性能。
轻量级锁
轻量级锁的概念
轻量级锁是JDK1.6中加入的新型锁机制,它名字中的“轻量级”是相对于使用操作系统互斥量来实现的传统所而言的,因此传统的锁机制就被称为“重量级”锁。需要强调一点的是,轻量级锁并不是用来代替重量级锁的,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。
轻量级锁及膨胀流程
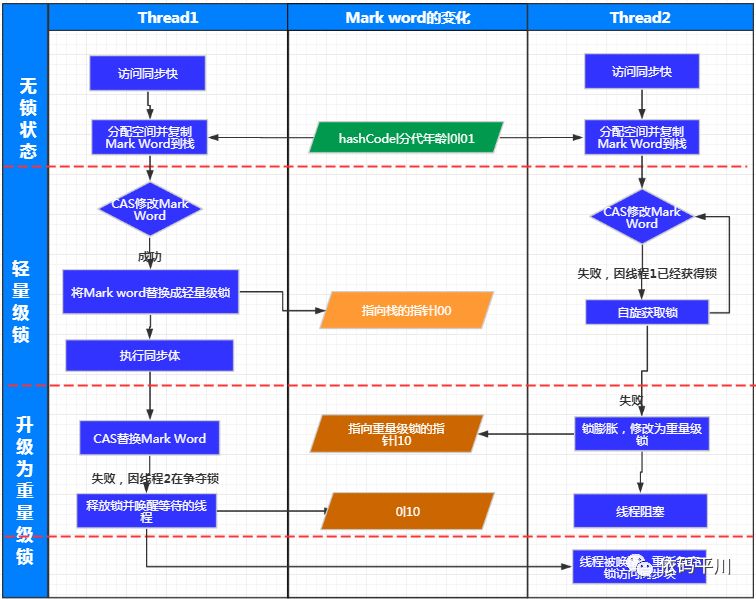 偏向锁的设置及撤销流程图
偏向锁的设置及撤销流程图
辩证地看待轻量级锁
轻量级锁能提升程序性能的依据是“对于绝大部分的锁,在整个同步周期内都是不存在竞争的”,这是一个经验数据, 如果没有竞争,轻量级锁使用CAS操作避免了使用互斥量的开销,但如果存在锁竞争,处理互斥量的开销外,还额外发生了CAS操作,因此在有竞争的情况下,轻量级锁会比传统的重量级锁更慢。
重量级锁
重量级锁的概念
重量级锁即我们一般概念上的synchronized锁,它通过用户态与内核态的转换,完成线程的上下文切换,通过阻塞的方式完成线程的暂停与恢复,处理起来开销较大,比较重。其满足原子性、可见性、有序性三大特性:
-
原子性是通过monitorenter,monitorexit指令间接调用内存操作指令lock,unlock实现。
注意,synchronized修饰方法时,通过javap查看字节码指令,是看不到monitorenter,monitorexit指令的,但是可以在方法的声明中看到“ACC_SYNCHRONIZED ”关键字,达到的效果是一样的:
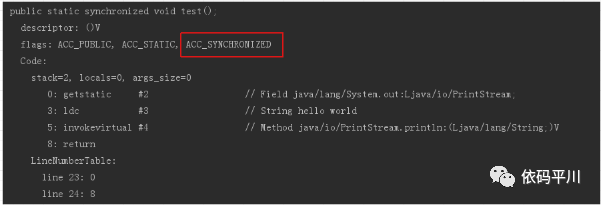
-
可见性是由JMM规范中“对一个变量执行unlock操作之前,必须先把变量同步回主内存中(执行store和write操作)”这条规则获得的”;
-
有序性是由“一个变量同一时刻只允许一条线程对其进行lock操作”这条规则获得的,这个规则决定了持有同一个锁的两个同步块只能串行地进入。
一旦锁升级成重量级锁,就不会再恢复到轻量级锁状态。当锁处于这个状态下,其他线程试图获取锁时,都会被阻塞住,当持有锁的线程释放锁之后会唤醒这些线程,被唤醒的线程就会进行新一轮的夺锁之争。
重量级锁的实现
说到重量级锁的实现,需要重点关注一个概念:Monitor
Monitor
什么是Monitor?我们可以把它理解为一个同步工具,也可以描述为一种同步机制。所有的Java对象是天生的Monitor,每个object的对象里 markOop->monitor() 里可以保存ObjectMonitor的对象。从源码层面分析一下monitor对象
-
oop.hpp下的oopDesc类是JVM对象的顶级基类,所以每个object对象都包含markOop
class oopDesc { friend class VMStructs; private: volatile markOop _mark; …… } -
markOop.hpp 中 markOopDesc继承自oopDesc,并扩展了自己的monitor方法,这个方法返回一个 ObjectMonitor指针对象
ObjectMonitor* monitor() const { assert(has_monitor(), "check"); // Use xor instead of &~ to provide one extra tag-bit check. return (ObjectMonitor*) (value() ^ monitor_value); } -
objectMonitor.hpp,在hotspot虚拟机中,采用ObjectMonitor类来实现monitor
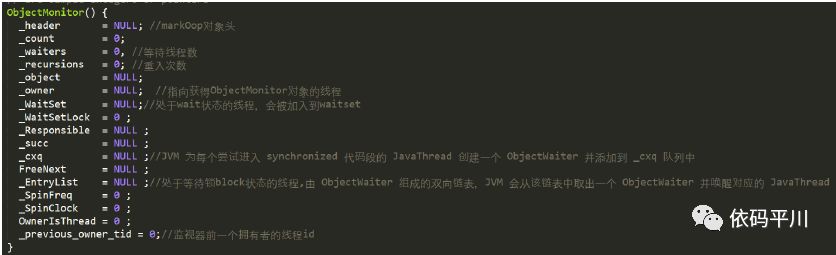
注:synchronized锁的关键处理就在于这个ObjectMonitor对象了,详见上图中对 _waiters,_owner,_waitSet,_cxq,_EntryList 等关键属性的注释。
synchronized的锁处理原理
了解了monitor这个对象,就比较好理解synchronized锁处理的原理了,在hotspot虚拟机中,通过ObjectMonitor类来实现monitor,它的锁的获取、释放、阻塞等处理过程如下图所示:
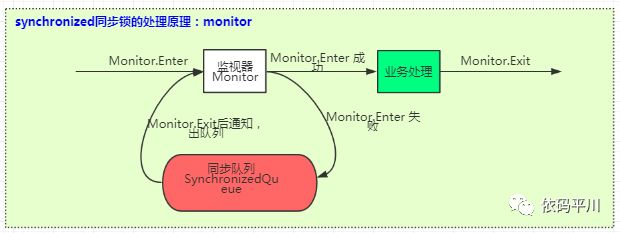
wait和notify|notifyAll的原理
wait,notify|notifyAll基于synchronized而来,在上图的基础上加了"waitSet"的等待队列,当发生wait操作时会将当前线程放入waitSet队列(线程状态将变为Waiting或Timed_Waiting),当前线程阻塞,同时释放锁,等待其他线程调用notify|notifyAll进行唤醒,notify()方法将从waitSet队列中取出一条记录放入同步队列,notifyAll()方法将从waitSet队列中通过遍历的方式取出所有记录放入EnterList同步队列(此时线程状态为Blocked),具体处理流程详见下图:
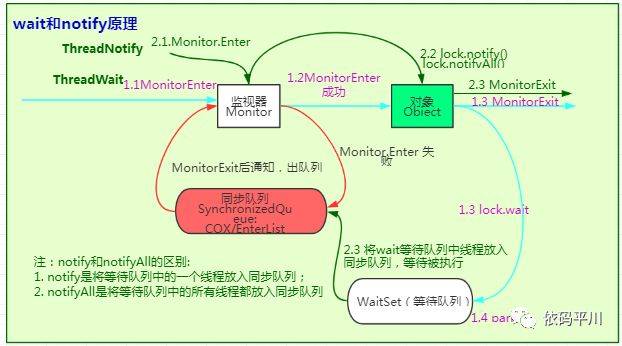
wait和notify为什么需要在synchronized里面?
wait方法的语义有两个,一个是释放当前的对象锁、另一个是使得当前线程进入阻塞队列, 而这些操作都和监视器是相关的,所以wait必须要获得一个监视器锁 而对于notify来说也是一样,它是唤醒一个线程,既然要去唤醒,首先得知道它在哪里?所以就必须要找到这个对象获取到这个对象的锁,然后到这个对象的等待队列中去唤醒一个线程。
几种锁的优缺点对比
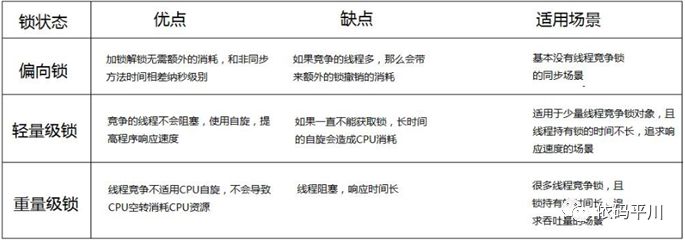
总结
至此,深入理解Java虚拟机——高效并发部分就介绍完了,这块主要围绕两大块内容展开:一、内存模型与线程;二、线程安全与锁优化,你get到多少了呢?这块内容涉及到的细节非常多,建议没事多回顾几遍,我敢保证,每次认真梳理一遍,你都会有新的感悟和收获。
接下来的章节将会从jdk层面,来深入了解下我们常用的一些并发相关类的使用及其底层原理。
欢迎持续关注。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

