多线程中那些看不见的陷阱
多线程编程就像一个沼泽,中间遍布各种各样的陷阱。大多数开发者绝大部分时间都是在做上层应用的开发,并不需要过多地涉入底层细节。但是在多线程编程或者说是并发编程中,有非常多的陷阱被埋在底层细节当中。如果不知道这些底层知识,可能在编写过程中完全意识不到程序已经出现了漏洞,甚至在漏洞爆发之后也很难排查出具体原因进而解决漏洞。虽然前面提到的漏洞听起来很吓人,但是相信通过我们逐步的抽丝剥茧,在最后一定能掌握大量的实用工具来帮助我们解决这些问题,实现可靠的并发程序。
阅读本文需要了解并发的基本概念和Java多线程编程基础知识,还不了解的读者可以参考一下下面两篇文章:
- 并发的基本概念—— 当我们在说“并发、多线程”,说的是什么?
- Java多线程编程基础—— 这一次,让我们完全掌握Java多线程
数据竞争问题
为了了解多线程程序有什么隐藏的陷阱,我们先来看一段代码:
public class AccumulateWrong {
private static int count = 0;
public static void main(String[] args) throws Exception {
Runnable task = new Runnable() {
public void run() {
for (int i = 0; i < 1000000; ++i) {
count += 1;
}
}
};
Thread t1 = new Thread(task);
Thread t2 = new Thread(task);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("count = " + count);
}
}
这段代码实现的基本功能就是在两个线程中分别对一个整型累加一百万次,那么我们期望的输出应该总共是两百万。但在我的电脑上运行的结果只有1799369,而且每次都不一样,相信在你的电脑上也会运行得到一个不同的结果,但是肯定会达不到两百万。
这段代码出现问题的原因就在于,我们在执行 count += 1; 这行代码时,实际在CPU上运行的会是多条指令:
- 获取count变量的当前值
- 计算count + 1的值
- 将count + 1的结果值存到count变量中
所以就有可能会发生下面的执行顺序:
| t1 | t2 |
|---|---|
| 获取到count的值为100 | |
| 计算100 + 1 = 101 | |
| 获取到count的值为100 | |
| 把101保存到count变量中 | |
| 计算100+ 1 = 101 | |
| 把101保存到count变量中 |
这么一轮操作结束之后,虽然我们在两个线程中分别对count累加了一次,总共是两次,但是count的值只变大了1,这时结果就出现了问题。这种在多个线程中对共享数据进行竞争性访问的情况就被称为 数据竞争 ,可以理解为对共享数据的并发访问会导致问题的情况就是 数据竞争 。
那么我们如何解决这样的 数据竞争 问题呢?
synchronized关键字
相信大多数读者应该都知道 synchronized 这个关键字,它可以被用在方法定义或者是块结构上,那么它到底能发挥怎样的作用呢?我们把它以块结构的形式把 count += 1; 语句包围起来看看。
for (int i = 0; i < 1000000; ++i) {
synchronized (this) {
count += 1;
}
}
运行之后可以看到,这次的输出是两百万整了。在这里, synchronized 发挥的作用就是让两个线程互斥地执行 count += 1; 语句。所谓互斥也就是同一时间只能有一个线程执行,如果另一个线程同时也要执行的话则必须等到前一个线程完成操作退出 synchronized 语句块之后才能进入。
这种同一时间只能被一个线程访问的代码块就被称为 临界区 ,而 synchronized 这样的保护临界区同时只能被一个线程进入的机制就被称为 互斥锁 。当一个线程因为另外一个线程已经获取了锁而陷入等待时,我们可以称该线程被这个锁 阻塞 了。
在Java中, synchronized 的背后是对象锁,每个不同的对象都会对应一个不同的锁,同一个对象对应同一个锁。只有获取同一个锁才能达到互斥访问的作用,如果两个线程分别获取不同的锁,那么互相就不会影响了。所以在使用 synchronized 时,区分背后对应的是哪一个对象锁就至关重要了。 synchronized 关键字可以被用在方法定义和块结构两种情况中,具体对应的锁如下:
- 以块结构形式使用
synchronized关键字,则获取的就是synchronized关键字后小括号中的对象所对应的锁; -
synchronized被标记在实例方法上,则获取的就是this引用指向对象所对应的锁; -
synchronized被标记在类方法(静态方法)上时,获取的就是方法所在类的“类对象”所对应的锁,这里的类对象就可以理解为是每个类一个用于存放静态字段和静态方法的对象。
因为 synchronized 一定要有一个对应的对象,所以我们自然不能将基本类型的变量传入到 synchronized 后面的括号中。
ReentrantLock
在Java 5中JDK引入了 java.util.concurrent 包,也许大家都或多或少听说过这个包,在这个包中提供了大量使用的并发工具类,例如线程池、锁、原子数据类等等,对Java语言的并发编程易用性和实际效率产生了跨越性的提高。而 ReentrantLock 就是这个包中的一员。
ReentrantLock 发挥的作用与 synchronized 相同,都是作为互斥锁使用的。下面是把之前的累加代码改为使用 ReentrantLock 锁的版本:
final ReentrantLock lock = new ReentrantLock();
Runnable task = new Runnable() {
public void run() {
for (int i = 0; i < 1000000; ++i) {
lock.lock();
try {
count += 1;
} finally {
lock.unlock();
}
}
}
};
运行之后的结果依然是两百万,说明 ReentrantLock 确实能起到保障互斥访问临界区的作用。但是既然 ReentrantLock 和 synchronized 的作用相同,而且从代码来看使用 synchronized 还更方便,为什么还要专门定义一个 ReentrantLock 这样的类呢?
上面的代码中,虽然使用 ReentrantLock 还要专门写一个 try..finally 块来保证锁释放,比较麻烦,但是也能从中看到一个好处就是我们可以决定加锁的位置和释放锁的位置。我们甚至可以在一个方法中加锁,而在另一个方法中解锁,虽然这样做会有风险。相对于传统的 synchronized , ReentrantLock 还有下面的一些好处:
-
ReentrantLock可以实现带有超时时间的锁等待,我们可以通过tryLock方法进行加锁,并传入超时时间参数。如果超过了超时时间还么有获得锁的话,那么就tryLock方法就会返回false; -
ReentrantLock可以使用公平性机制,让先申请锁的线程先获得锁,防止线程一直等待锁但是获取不到; -
ReentrantLock可以实现读写锁等更丰富的类型。
更简便的方式——AtomicInteger
在 java.util.concurrent 包中,我们可以找到一个很有趣的子包 atomic ,在这个包中我们看到有很多以 Atomic 开头的“包装类型”,这些类会有什么用呢?我们先来看一下前面的累加程序使用 AtomicInteger 该如何实现。
public class AtomicIntegerDemo {
private static AtomicInteger count = new AtomicInteger(0);
public static void main(String[] args) throws Exception {
Runnable task = new Runnable() {
public void run() {
for (int i = 0; i < 1000000; ++i) {
count.incrementAndGet();
}
}
};
Thread t1 = new Thread(task);
Thread t2 = new Thread(task);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("count = " + count);
}
}
运行这个程序,我们也可以得到正确的结果两百万。在这个版本的代码中我们主要改了两处地方,一个是把 count 变量的类型修改为了 AtomicInteger 类型,然后把 Runnable 对象中的累加方式修改为了 count.incrementAndGet() 。
AtomicInteger 提供了原子性的变量值修改方式,原子性保证了整个累加操作可以被看成是一个操作,不会出现更细粒度的操作之间互相穿插导致错误结果的情况。在底层 AtomicInteger 是基于硬件的CAS原语来实现的,CAS是“Compare and Swap”的缩写,意思是在修改一个变量时会同时指定新值和旧值,只有在旧值等于变量的当前值时,才会把变量的值修改为新值。这个CAS操作在硬件层面是可以保证原子性的。
我们既可以用 Atomic 类来实现一些简单的并发修改功能,也可以使用它来对一些关键的控制变量进行控制,起到控制并发过程的目的。线程池类 ThreadPoolExecutor 中用于控制线程池状态和线程数的控制变量 ctl 就是一个 AtomicInteger 类型的字段。
内存可见性问题
看完了如何解决数据竞争问题,我们再来看一个略显神奇的例子。
public class MemoryVisibilityDemo {
private static boolean flag;
public static void main(String[] args) throws Exception {
for (int i = 0; i < 10000; ++i) {
flag = false;
final int no = i;
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
flag = true;
System.out.println(String.format("No.%d loop, t1 is done.", no));
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
while (!flag) ;
System.out.println(String.format("No.%d loop, t2 is done.", no));
}
});
t2.start();
t1.start();
t1.join();
t2.join();
}
}
}
这段程序在我的电脑上输出是这样的:
No.0 loop, t2 is done. No.0 loop, t1 is done. No.1 loop, t1 is done. No.1 loop, t2 is done. No.2 loop, t2 is done. No.2 loop, t1 is done. No.3 loop, t2 is done. No.3 loop, t1 is done. No.4 loop, t1 is done.
在上面的程序输出中我们可以看到,代码中的循环是10000次,但是在程序输出结果中到第五次就结束了。而且第五次运行中只有t1执行完了,t2的结束语句一直没输出。这说明程序被卡在了 while (!flag) ; 上,但是t1明明已经运行结束了,说明此时 flag = true 已经执行了,为什么t2还会被卡住呢?
这是因为 内存可见性 在作祟,在计算机中,我们的存储会分为很多不同的层次,大家比较常见的就是内存和外存,外存就是比如磁盘、SSD这样的持久性存储。其实在内存之上还有多个层次,较完整的计算机存储体系从下到上依次有外存、内存、“L3、L2、L1三层高速缓存”、寄存器这几层。在这个存储体系中从下到上是一个速度从慢到快的结构,越上层速度越快,所以当CPU操作内存数据时会尽量把数据读取到内存之上的高速缓存中再进行读写。
所以如果程序想要修改一个变量的值,那么系统会先把新值写到L1缓存中,之后在合适的时间才会将缓存中的数据写回内存当中。虽然这样的设置使系统的总体效率得到了提升,但是也带来了一个问题,那就是L1、L2两级高速缓存是核内缓存,也就是说多核处理器的每一个核心都有自己独立的L1、L2高速缓存。那么如果我们在一个核中运行的线程上修改了变量的值而没有写回内存的话,其他核心上运行的线程就看不到这个变量的最新值了。
结合我们前面的程序例子,因为修改和读取静态变量 flag 的代码在两个不同的线程中,所以在多核处理器上运行这段程序时,就有可能在两个不同的处理器核心上运行这两段代码。最终就会导致线程t1虽然已经把 flag 变量的值修改为true了,但是因为这个值还没有写回内存,所以线程t2看到的flag变量的值仍然是false,这就是之前的代码会被卡住的罪魁祸首。
那么我们如何解决这个问题呢?
volatile变量
最简单的方式是使用volatile变量,即把 flag 变量标记为 volatile ,如下所示:
private static volatile boolean flag;
这下程序就可以稳定地跑完了,那么 volatile 做了什么解决了内存可见性问题呢?根据编号为JSR-133的Java语言规范所定义的 Java内存模型(JMM) , volatile 变量保证了对该变量的写入操作和在其之后的读取操作之间存在同步关系,这个同步关系保证了对volatile变量的读取一定可以获取到该变量的最新值。在底层,对volatile变量的写入会触发高速缓存强制写回内存,该操作会使其他处理器核心中的同一个数据块无效化,必须从内存中重新读取。 Java内存模型 的具体内容在下一节中会有简单的介绍。
从上面的内存可见性问题我们可以发现,多线程程序中会出现的一些问题涉及一些非常底层的知识,而且不了解的人是很难事先预防和事后排查的。所以对于希望真正掌握多线程编程的朋友来说,这必然会是一场非常奇妙与漫长的旅程,希望大家都能坚持到最后。
Java内存模型
Java语言规范中的JSR-133定义了一系列决定不同线程之间指令的逻辑顺序,从而保证了不会出现内存可见性和指令重排序所引发的并发问题,这对完全掌握多线程程序的正确性至关重要。
在程序中,我们一般会认定程序语句是按代码中的顺序执行的,比如下面这段代码:
a = 0; a = 1; b = 2; c = 3;
我们当然会认为程序的执行顺序是 a = 0; -> a = 1; -> b = 2; -> c = 3; ,但实际上会有两种情况可能会破坏语句的执行顺序,一是编译器对指令的重排序可能会导致语句的顺序发生改变,二是前面提到的内存可见性。
对于编译器的指令重排序来说,虽然编译器会保证单个线程内语句的执行效果与顺序执行相同,但是在上面的代码中三个语句之间是没有依赖关系的,任意顺序执行的效果都是相同的,所以编译器是有可能对其中的语句进行重排序的。在单线程程序中这当然没有问题,任意顺序执行上面代码中的语句都是一样的,但是在多线程情况下,问题就复杂了。如果另外一个线程在变量b的值变为2后会打印变量a的值,那么按我们的期望这段程序应该打印出的 1 。但是如果 b = 2; 语句被重排序到了 a = 1; 之前和 a = 0; 之后,那么我们打印出的值就是 0 了。
对于内存可见性,如果 b = 2; 对变量b的修改结果先于 a = 1; 写回了内存中。那么在另一个线程中,当看到变量b的值变为2时还不能看到变量a的新值1,这同样会导致程序打印出不符合我们期望的值。
从上面的介绍我们可以看出,在这个问题中最重要的是语句的执行顺序,在默认情况下,我们可以保证单线程内的执行顺序所产生的结果一定是符合我们的期望的,但一旦进入多线程情况下,我们就不能做出这样的保证了。 那么我们如何保证多个线程之间语句的执行顺序关系呢? 这就要说到我们之前说到的Java内存模型了。
Java内存模型中定义了不同线程中的语句的顺序关系,这被称为Happens-Before关系,以下简称HB。这个关系指的是如果“操作A”HB于“操作B”,那么 如果“操作A”确实在“操作B”之前已经发生了 ,那么“操作B”一定会像在“操作A”之后发生一样:看到“操作A”发生后所产生的所有结果,比如变量值的修改。如果“操作A”把变量a的值修改为了2,那么所有“操作B”都一定能看到变量a的值为2,不论是编译器对指令的重排序还是不同处理器核心之间的内存可见性都不能破坏这个结果。
正是因为这种指令执行先后关系的核心就是看到之前执行指令 在内存中体现的结果 ,所以这个规范才被称为 Java内存模型 。
常用的Happens-Before关系规则:
- 同一个线程中,“先执行的语句” HB于 “之后执行的所有语句”;
- “对volatile变量的写操作” HB于 “对同一个变量的读操作”;
- “对锁的释放操作” HB于 “对同一个锁的加锁操作”;
- “对Thread对象的start操作” HB于 “该线程任务中的第一行语句”;
- “线程任务中的最后一行语句” HB于 “对该线程对应的Thread对象的join操作”;
- 传递性规则:如果“操作B” HB于 “操作A”,“操作C” HB于 “操作B”,那么“操作C” 也HB于 “操作A”。
通过第一条规则我们就确定了单线程内的语句的执行顺序,而通过规则2到规则4,我们就可以线程间确定具体的语句执行顺序了。最后的规则6传递性规则是整个规则体系的补充,利用这条规则我们就可以把规则1中的线程内顺序和规则2到4的线程间规则进行结合,得到最终的完整顺序体系了。
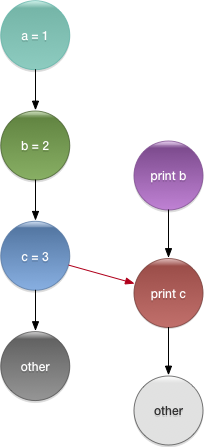
在下图中,左边一列和右边一列分别是两条不同的线程中执行的语句及其顺序。如果变量c是一个volatile变量,那么根据规则2,我们可以知道操作 c = 3 HB于 操作 print c ,下图中用红线标明了这个关系。所以根据JMM的定义, print c 将可以看到变量c的值已经被修改为3了,打印结果将是3,如果在 print c 语句下方继续执行对变量a和b的打印,那么结果必然分别是1和2。
但是我们不能保证右侧的第一条 print b 语句一定会打印出2的值,即使它在时间上发生于 b = 2 之后。因为指令重排序或者内存可见性问题都有可能会使它只能看到变量b在 b = 2 之前的原值。也就是说HB关系是没办法指定两条线程中在HB关系之前的语句相互之间的顺序关系的,在下图的例子中就是 print b 并不能保证一定可以打印出值2,也有可能打印出变量b原来的值。
总结
在这篇文章中我们主要介绍了如何保证多线程程序的正确性,使运行过程和结果符合我们的预期。通过对多线程程序正确性问题的探索,我们介绍了 三种常用的线程同步方式 ,分别是锁、CAS与volatile变量。其中,锁有synchronized关键字和 ReentrantLock 两种实现方式。
在这个过程中,我们深入到了计算机系统的底层,了解了计算机存储体系结构和 volatile 对高速缓存与内存的影响。多线程编程是一个非常好的切入口,让我们可以将以前曾经学过的计算机理论知识与编程实践结合起来,这种结合对非常多的高级知识领域都是至关重要的。
因为错误的程序是没有价值的,所以对一个程序来说最重要的当然是正确性。但是在实现了正确性的前提下,我们也必须要想办法提升程序的性能。因为多线程的目标就是通过多个线程的协作来提升程序的性能,如果达不到这个目标的话我们辛辛苦苦写的多线程代码就没有意义了。在下一篇文章中我们将会具体测试多线程程序的性能,通过发现多线程中那些会让多线程程序运行得比单线程程序更慢的性能陷阱,最终我们将找到解决这些陷阱的性能优化方法。下一篇文章将在下周发布,有兴趣的读者可以关注一下。
正文到此结束
- 本文标签: 线程同步 tar 多线程 开发 同步 处理器 性能优化 漏洞 参数 总结 Atom js IDE 快的 final 线程池 模型 https 数据 实例 锁 文章 id 并发 tab 开发者 App volatile http 希望 缓存 测试 UI 时间 重排序 ask IO synchronized 编译 线程 代码 并发编程 src executor 静态方法 java swap 内存模型 Java内存模型 ThreadPoolExecutor ORM
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

