Apache Beam 实战指南 | 如何结合 ClickHouse 打造“AI 微服务”?
本文是 Apache Beam 实战指南系列文章的第四篇内容,将对 Beam 框架中的 ClickHouseIO 源码进行剖析,并结合应用示例和代码解读带你进一步了解如何结合 Beam 玩转大数据实时分析数据库 ClickHouse。系列文章第一篇回顾 Apache Beam 实战指南 | 基础入门 、第二篇回顾 Apache Beam 实战指南 | 玩转 KafkaIO 与 Flink 、第三篇回顾 Apache Beam 实战指南 | 玩转大数据存储 HdfsIO 。
关于 Apache Beam 实战指南系列文章
随着大数据 2.0 时代悄然到来,大数据从简单的批处理扩展到了实时处理、流处理、交互式查询和机器学习应用。近年来涌现出诸多大数据应用组件,如 HBase、Hive、Kafka、Spark、Flink 等。开发者经常要用到不同的技术、框架、API、开发语言和 SDK 来应对复杂应用的开发,这大大增加了选择合适工具和框架的难度,开发者想要将所有的大数据组件熟练运用几乎是一项不可能完成的任务。
面对这种情况,Google 在 2016 年 2 月宣布将大数据流水线产品(Google DataFlow)贡献给 Apache 基金会孵化,2017 年 1 月 Apache 对外宣布开源 Apache Beam,2017 年 5 月迎来了它的第一个稳定版本 2.0.0。在国内,大部分开发者对于 Beam 还缺乏了解,社区中文资料也比较少。InfoQ 期望通过 Apache Beam 实战指南系列文章 推动 Apache Beam 在国内的普及。
一.概述
loT 大时代背景趋势下,万物互联。AI 技术逐渐普及,以及延伸到各个行业中。图片识别,人脸识别等等应用演化出无数的智能应用。大数据也慢慢的从普通大数据演变也向着人工智能的“深数据”转变 ,传统的大数据架构正在面临着前所未有的挑战。物联网与互联网的边界变得越来越模糊。
在物联网通过构建集中化、主动化、智能化的视频运维管理中,对数量庞大、种类繁多的前端摄像机、编解码设备、门禁设备、对讲设备集报警设备等各类安防设备。怎样实现设备运行状态实时监测、视频质量情况智能诊断、设备故障事件第一时间主动告知,并能够及时、准确分析和定位故障根源,实现运维管理效率和服务管理质量的同步 在以上场景中数据量大,实时快速分析 Apache Beam 起到了怎样的作用呢?
Apache Beam 在不同的数据源,数据种类进行数据汇集,以流数据方式实时的上报到全国中心。同时进行 ETL 清洗,把数据实时写入 ClickHouse 或 Elasticsearch ,面对每天全国 PB 及以上的大数据架构是怎么设计呢?通过一个案例让我们进行了解一下 Beam 是怎样结合 ClickHouse 发挥优势的。
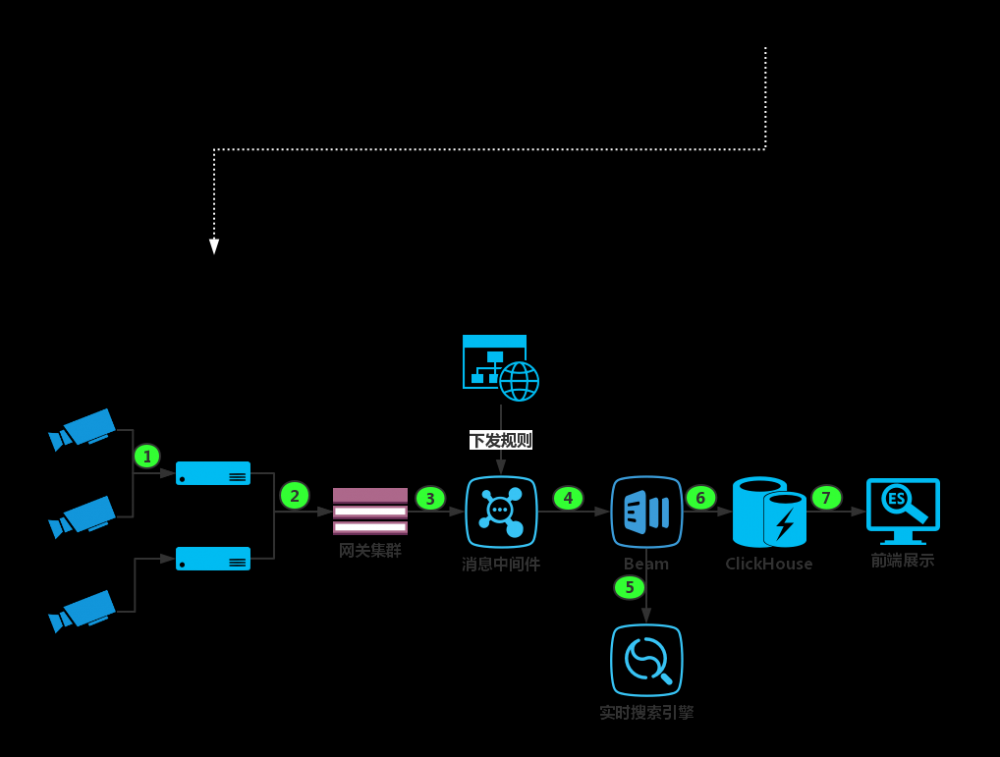
二.案例整体的架构流程图
2.1 案例架构流程图
-
摄像头以及 AI 智能设备产生的报警以及抓取的信息上报到后端智能设备。
-
智能设备产生的 AI 分析结果进行通过网关集群进行传输,注意网关集群地方要做流控及雪崩控制。
-
消息通过网关集群发送到消息中间件。注意:这边这个规则下发是针对前段的数据进行 ETL 清洗的清洗规则的下发。
-
Beam 集群接收下发规则的更新,并且根据规则进行数据清洗。
-
对于文档性的数据我们实时存储到实时搜索引擎。
-
需要复杂查询,统计以及报表的数据存储到 ClickHouse
-
进行 BI 套件的展示以及前端大屏幕的展示。
三.技术名称解释
Kafka
是一种高吞吐量的分布式发布订阅消息系统。针对流数据支持性比较高,是现在消息中间件应用非常广泛的开源的消息中间件。
ClickHouse
是一个开源的面向列的数据库管理系统,能够使用 SQL 实时查询并生成报表或报告。详细可参考我的文章 《比 Hive 快 800 倍!大数据实时分析领域黑马开源 ClickHouse》 ,此外在 ClickHouse 18.1.0 以后版本的 MergeTree 引擎中已经支持 修改和删除 功能以及标准 SQL Join 。
ElasticSearch
ElasticSearch 是一个基于 Lucene 的实时搜索服务器。现在应用云计算,大数据,LoT 等方面比较广泛。本文中运用它来做数据备份。
四.Apache Beam ClickHouseIO 源码剖析
Apache Beam ClickHouseIO 对 ClickHouse 支持依赖情况
ClickHouseIO 是 ClickHouse 的 API 封装,主要负责 ClickHouse 读取和写入消息。如果想使用 ClickHouseIO,必须依赖 beam-sdks-java-io-clickhouse ,ClickHouseIO 同时支持多个版本的 ClickHouse,使用时现在只有 V2.11.0 版本在 maven 中心仓库已经释放,其他的版本没有释放。需要下载源码自己进行编译。
Apache Beam ClickHouseIO 对各个 clickhouse-jdbc 版本的支持情况如下表:
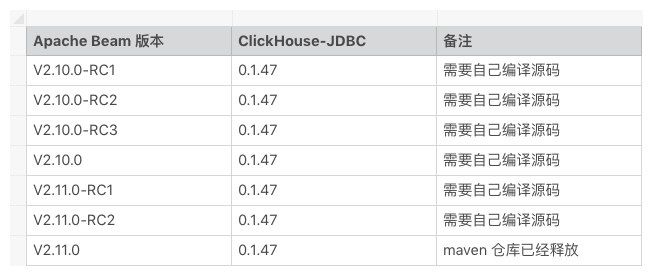
表 4-1 ClickHouseIO 与 clickhouse-jdbc 依赖关系表
ClickHouse 数据类型 与 Apache Beam 数据类型转换情况
Apache Beam 在本次案例中选择的是最新的版本 V2.11.0 , 因为其他版本的 clickhouse-jdbc 没有释放。因为 ClickHouse 更确切的是一个关系型数据库,但是它的数据格式跟 Beam 底层转换的时候还是存在着部分的不同点,我们通过一张表看一下 ClickHouse 的数据格式和 Apache Beam 的数据格式有哪些不一样?
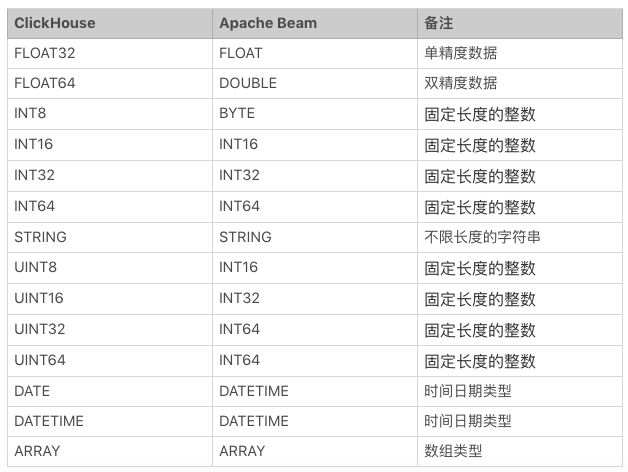
表 4-2 ClickHouse 数据类型 与 Apache Beam 数据类型转换对照表
对于 ClickHouse 的中是怎样把数据 转换成 Apache Beam 的数据的呢?其实它的转换是用 ClickHouseWriter.java 这个文件中的 writeValue() 的 switch 语句
复制代码
switch(columnType.typeName()) {
caseFLOAT32:
stream.writeFloat32((Float)value);
break;
caseFLOAT64:
stream.writeFloat64((Double)value);
break;
.....
ClickHouseIO 源码解析
ClickHouseIO 源码链接如下:
https://github.com/apache/beam/blob/v2.11.0/sdks/java/io/clickhouse/src/main/java/org/apache/beam/sdk/io/clickhouse/ClickHouseIO.java
在 ClickHouseIO 里面最主要的方法是 ClickHouse 的写方法,以及几个重要的 API 的的属性参数。
ClickHouseIO 写操作
复制代码
publicstatic<T>Write<T>write(StringjdbcUrl,Stringtable)
{...
- 源码中的写入类型 Beam 中是给定的是
泛型类型, 是可以制定自己自定义以及现有的数据类型。当然我们开发中一般很多时候以 json 类型和类对象为主,当然也有其他类型如 KV 类型等。 写入方法中传了两个比较简单的参数,String jdbcUrl 相当于咱们常用的 MySQL 连接地址一样的字符串,在 Beam 和 ClickHouse 的连接也选择了相同的方式。String table 这里是要进行操作的表名称,如果写入数据需要先检查是否存在相应的表。如果是单机直接写单机主机 IP 和端口就可以,集群则填写 Master Node 节点的地址,具体示例如下:
复制代码
ClickHouseIO.<Row>write("jdbc:clickhouse://101.201.*.*:8123/Alarm", "AlarmTable")
- 设置 ClickHouse 最大添加的块大小,注意这个块相当于 MySQL 中的 Batch 条数,并不是存储的块大小。 在 Beam ClickHouseIO 和 ClickHouse 官方的两个默认值分别为 1000000 和 1048576。如果是数据量特别大以及大数据迁移导入的时候设置 100W 行数据插入,速度约在 2-5 秒中,速度是非常快的。实时的场景可以采用 Beam 窗口方式,1-2 分钟批量添加一批。
复制代码
public Write<T>withMaxInsertBlockSize(longvalue){
returntoBuilder().maxInsertBlockSize(value).build();
}
- 设置每次写入 ClickHouse 的最大重试次数,Beam 默认为 5 次。
复制代码
public Write<T>withMaxRetries(intvalue){
returntoBuilder().maxRetries(value).build();
}
- 设置是否启用分布式节点的分片同步复制数据,如果是正式生产环境建议开启。很多场景都要保证数据的完整性。
复制代码
withInsertDistributedSync(@NullableBoolean value) {..
设置数据复制的副本数量,服务器默认为禁用此设置,需要服务器配置,0 表示禁用,null 表示服务器默认值。
复制代码
withInsertQuorum(@NullableLong value){..
- 设置插入块数据中有重复数据,进行删除重复数据。默认为启用,null 表示服务器默认值。
复制代码
withInsertDeduplicate(Booleanvalue){..
- 设置操作失败后的退出初始时间和总时间。
复制代码
withMaxCumulativeBackoff(Durationvalue)
withInitialBackoff(Durationvalue){
关于性能的注意事项
(1)数据压缩
对于 loT 场景下 3-5 年的警情数据需要进行冷数据压缩,而节省空间开销。ClickHouse 的数据可以采用数据压缩的方式进行压缩。
(2) 物化视图
ClickHouse 针对多维大数据查询,支持物化视图的建立。
五. Apache Beam 和 ClickHouse 实战
本节通过解读一个真正的 ClickHouseIO 和 Apache Beam 实战案例,帮助大家更深入地了解 ClickHouse 和 Apache Beam 的运用。
设计架构图和设计思路解读

Apache Beam 外部数据流程图
设计思路:设备事件,报警等消息通过 Netty 集群 把消息发送到 Kafka 集群 Apache Beam 程序通过 KafkaIO 接收前端业务消息 并且写入 ClickHouse 。

Apache Beam 内部数据处理流程图
Apache Beam 程序通过 kafkaIO 读取 Kafka 集群的数据,进行数据格式转换。通过 ClickHouseIO 写操作把消息写入 ClickHouse。最后把程序运行在 Flink 的计算平台上。
软件环境和版本说明
-
系统版本 centos 7
-
Kafka 集群版本: kafka_2.11-2.0.0.tgz
-
Flink 版本:flink-1.5.2-bin-hadoop27-scala_2.11.tgz
-
ClickHouse 19.3.5
ClickHouse 集群或单机以及 Docker 可以在开源 中文社区 获取,大家可以去网上搜一下配置文章,操作比较简单,这里就不赘述了。
实践步骤
1)在 pom 文件中添加 jar 引用
复制代码
<!-- 本地运行 Runners --> <dependency> <groupId>org.apache.beam</groupId> <artifactId>beam-runners-direct-java</artifactId> <version>2.11.0</version> </dependency> <!-- 运行 Runners 核心 jar --> <dependency> <groupId>org.apache.beam</groupId> <artifactId>beam-runners-core-java</artifactId> <version>2.11.0</version> </dependency> <!-- 引入 Beam clickhouse jar --> <dependency> <groupId>org.apache.beam</groupId> <artifactId>beam-sdks-java-io-clickhouse</artifactId> <version>2.11.0</version> </dependency> <dependency> <groupId>ru.yandex.clickhouse</groupId> <artifactId>clickhouse-jdbc</artifactId> <version>0.1.47</version> </dependency> <dependency> <groupId>org.apache.beam</groupId> <artifactId>beam-sdks-java-core</artifactId> <version>2.11.0</version> </dependency> <!-- BeamSQL --> <dependency> <groupId>org.apache.beam</groupId> <artifactId>beam-sdks-java-extensions-sql</artifactId> <version>2.11.0</version> </dependency> <!-- 引入 elasticsearch--> <dependency> <groupId>org.apache.beam</groupId> <artifactId>beam-sdks-java-io-elasticsearch</artifactId> <version>2.11.0</version> </dependency> <!-- kafka --> <dependency> <groupId>org.apache.beam</groupId> <artifactId>beam-sdks-java-io-kafka</artifactId> <version>2.11.0</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.0.0</version> </dependency> <!-- Flink --> <dependency> <groupId>org.apache.beam</groupId> <artifactId>beam-runners-flink_2.11</artifactId> <version>2.11.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.5.2</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_2.11</artifactId> <version>1.5.2</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-core</artifactId> <version>1.5.2</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-runtime_2.11</artifactId> <version>1.5.2</version> <!--<scope>provided</scope> --> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.11</artifactId> <version>1.5.2</version> <!--<scope>provided</scope> --> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-metrics-core</artifactId> <version>1.5.2</version> <!--<scope>provided</scope> --> </dependency>
2)新建 kafkaToClickhouseIO.java 类
3)KafkaToClickhouseIO 编写以下代码:
复制代码
public static void main(String[]args) {
// 创建管道工厂
PipelineOptions options =PipelineOptionsFactory.create();
// 显式指定 PipelineRunner:FlinkRunner 必须指定如果不制定则为本地
options.setRunner(FlinkRunner.class);
Pipeline pipeline =Pipeline.create(options);// 设置相关管道
// 这里 kV 后说明 kafka 中的 key 和 value 均为 String 类型
PCollection<KafkaRecord<String, String>> lines =
pipeline.apply(KafkaIO.<String,String>read().withBootstrapServers("101.*.*.77:9092")// 必需设置 kafka 的服务器地址和端口
.withTopic("TopicAlarm")// 必需,设置要读取的 kafka 的 topic 名称 .withKeyDeserializer(StringDeserializer.class)// 必需序列化 key .withValueDeserializer(StringDeserializer.class)// 必需序列化 value
.updateConsumerProperties(ImmutableMap.<String, Object>of("auto.offset.reset","earliest")));// 这个属性 kafka 最常见的
// 设置 Schema 的的字段名称和类型
final Schematype=Schema.of(
Schema.Field.of("alarmid", FieldType.STRING),Schema.Field.of("alarmTitle", FieldType.STRING),
Schema.Field.of("deviceModel", FieldType.STRING),Schema.Field.of("alarmSource", FieldType.INT32),Schema.Field.of("alarmMsg", FieldType.STRING));
// 从 kafka 中读出的数据转换成 AlarmTable 实体对象
PCollection<AlarmTable> kafkadata = lines.apply("Remove Kafka Metadata",ParDo.of(newDoFn<KafkaRecord<String, String>, AlarmTable>(){
privatestatic final long serialVersionUID =1L;
@ProcessElement
public void processElement(ProcessContextctx){
Gson gon =newGson();
AlarmTable modelTable = null;
try{// 进行序列号代码
modelTable = gon.fromJson(ctx.element().getKV().getValue(),AlarmTable.class);
} catch (Exception e) {
System.out.print("json 序列化出现问题:"+ e);
}
ctx.output(modelTable);// 回传实体
}
}));
// 备份写入 Elasticsearch
String[]addresses = {"http://101.*.*.77:9200/"};
PCollection<String> jsonCollection=kafkadata
.setCoder(AvroCoder.of(AlarmTable.class))
.apply("covert json",ParDo.of(newDoFn<AlarmTable, String>(){
privatestatic final long serialVersionUID =1L;
@ProcessElement
public void processElement(ProcessContextctx){
Gson gon =newGson();
String jString="";
try{// 进行序列号代码
jString = gon.toJson(ctx.element());
System.out.print(" 序列化后的数据:"+ jString);
} catch (Exception e) {
System.out.print("json 序列化出现问题:"+ e);
}
ctx.output(jString);// 回传实体
}
}));
// 所有的 Beam 数据写入 ES 的数据统一转换成 json 才可以正常插入
jsonCollection.apply(ElasticsearchIO.write().withConnectionConfiguration(ElasticsearchIO.ConnectionConfiguration.create(addresses,"alarm","TopicAlarm")
));
PCollection<Row> modelPCollection = kafkadata
//.setCoder(AvroCoder.of(AlarmTable.class))// 如果上面设置下面就不用设置
.apply(ParDo.of(newDoFn<AlarmTable, Row>(){// 实体转换成 Row
privatestatic final long serialVersionUID =1L;
@ProcessElement
public void processElement(ProcessContextc){
AlarmTable modelTable = c.element();
System.out.print(modelTable.getAlarmMsg());
Row alarmRow =Row.withSchema(type)
.addValues(modelTable.getAlarmid(),modelTable.getAlarmTitle(), modelTable.getDeviceModel(), modelTable.getAlarmSource(), modelTable.getAlarmMsg()).build();// 实体赋值 Row 类型
c.output(alarmRow);
}
}));
// 写入 ClickHouse
modelPCollection.setRowSchema(type).apply(
ClickHouseIO.<Row>write("jdbc:clickhouse://101.201.56.77:8123/Alarm","AlarmTable").withMaxRetries(3)// 重试次数
.withMaxInsertBlockSize(5)// 添加最大块的大小
.withInitialBackoff(Duration.standardSeconds(5))
.withInsertDeduplicate(true)// 重复数据是否删除
.withInsertDistributedSync(false));
pipeline.run().waitUntilFinish();
}
AlarmTable.java 为从数据库映射出来的实体对象类,注意此处为没有任何业务逻辑的实体对象。
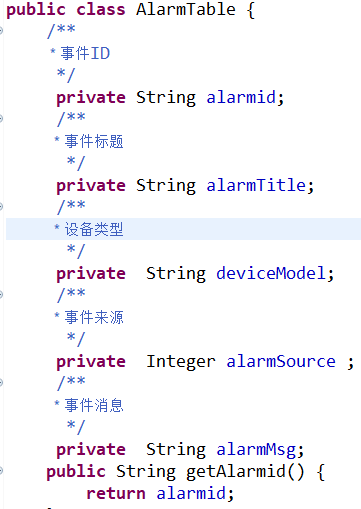
4)打包 jar,本示例是简单的实战, 可以采用 Docker 虚拟化自动部署。
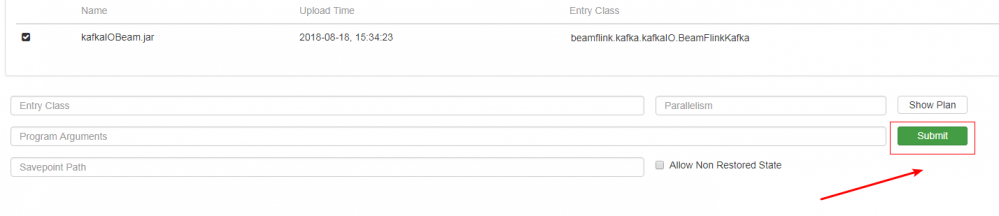
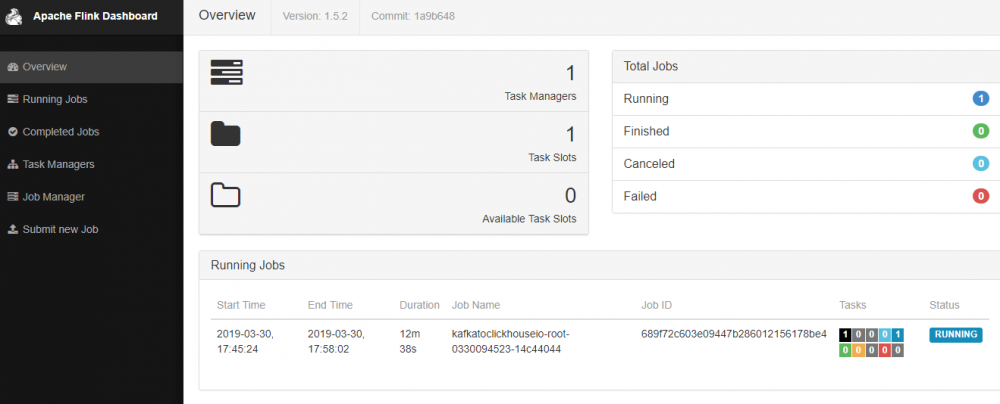
5)通过 Apache Flink Dashboard 提交 job,也可以用后台用命令提交。
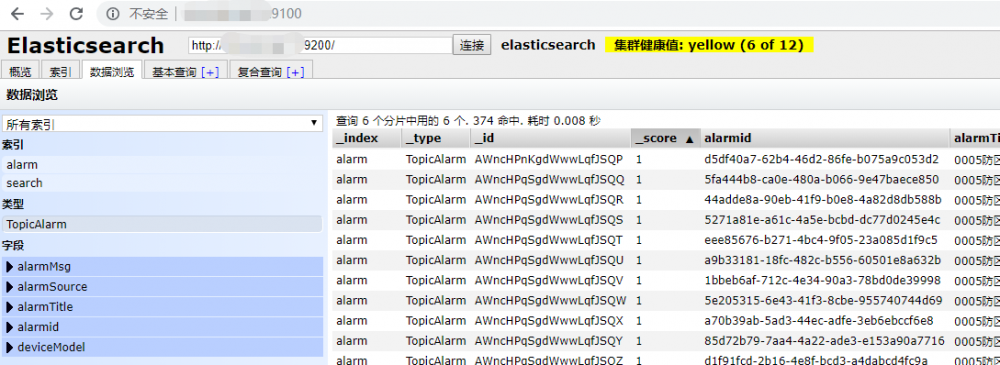
6)查看结果,视图中显示着运行着一直等待接收 kafka 队列的消息。如果有消息会自动插入 Clickhouse.
看一下 Clickhouse 数据库:
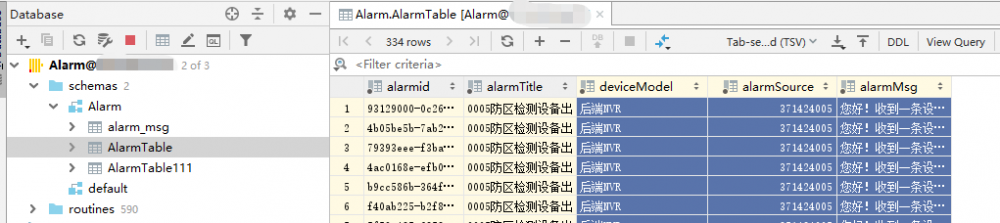
最后就可以进行各种报表统计,数据计算等操作。
写入 Elasticsearch 结果
六.实战解析
本次实战在源码分析中已经做过详细解析,在这里不做过多的描述,只选择部分问题再重点解释一下。此外,如果还没有入门,甚至连管道和 Runner 等概念都还不清楚,建议先阅读本系列的第一篇文章 《Apache Beam 实战指南之基础入门》 。
1. 在 ClickHouseIO 有个很关键的关键字 Schema,Row 这几个关键字在各个版本有一定的 API 的变化。希望实战者要注意,如下表。
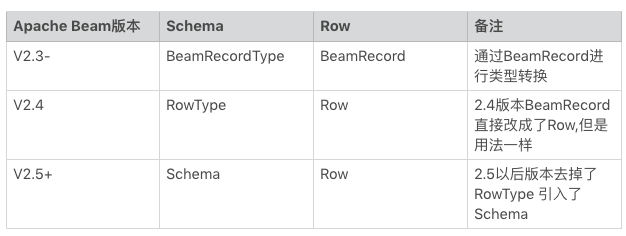
通过上个表格可以一目了然的看到在 BeamAPI 演进过程中的 Row 和 Schema 变化。在 Beam2.5+ 以后版本都是基本没有太大变动,只是做 API 的优化以及实战过程中的优化。如果是 2.4 版本则是:
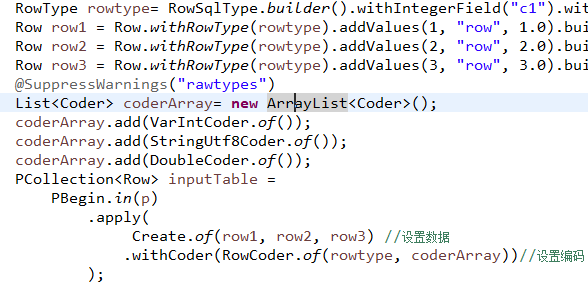
总体来说 2.4 版本其实还是很稳定的。2.5 版本是一共过渡版本,往后的改动不是 API 的大变化改动。
- Coder 是 Beam SDK 中非常重要的一个协议转换的角色。如果不设置会出现 “No Coder has been manually specified; you may do so using .setCoder()” 的错误提示。其实在 Flink 的数据转换中也是存在的,例如文中的 我是设置了对象 AvroCoder, 大家都知道 Avro 是一种序列化和反序列化的格式。
复制代码
.setCoder(AvroCoder.of(AlarmTable.class))
在项目实战中 Beam 的序列化是可以自定义的,但是都必须重写 encode 和 decode, 用过 Netty 的都知道在接收和回传消息都需要编码器和解码器,在 Beam 中 多了一共验证的方法 verifyDeterministic() 验证类型正确性。个人是不建议自定义编码的,因为在 Beam coders 中已经提供了 45 种的编码类型, 基本覆盖了 java 的所有的类型编码。再有就是因为自己写的自定义编码还需要大量的稳定性测试以及性能测试。
- ElasticsearchIO 的写操作,在 Beam 中从 kafka 流出的数据 是同时可以写入 Elasticsearch 和 Clickhouse 的。我们可以理解成一根水管,我们对接了两根子水管,一根是 A 水管 Elasticsearch 和 B 水管 Clickhouse。A 和 B 的数据是相同的如图 A 和 B 的数据对比。

- Elasticsearch 写入的格式要求。
因为 Elasticsearch 是一个文档性质数据库所以在写入的时候之前所有的数据都要转换成相应的 Json 格式的数据。
- Elasticsearch 生产环境一般都是要做高可用集群,在 Beam 提供了 Elasticsearch 集群的配置数组写法如下:
复制代码
String[]addresses= {"http://101.*.*.77:9200/"};
- Elasticsearch 的索引和分片设置
Elasticsearch 索引相当于 MySQL 的数据库名,分片相当于 MySQL 的表名。 在 Beam 设置比较简单,设置成功后,也不需要单独手工创建分片名和字段属性。执行 Beam 程序后自动创建分片及字段并写入数据。文中我设置的索引和分片为 alarm 和 TopicAlarm。
- 实战延伸,应对万变需求,规则调整。
在实际项目中,例如警情的去重,区域事件的实时统计,在 loT 场景中 AI 人脸识别的人像特征值获取上报等等 都有自己的规则, 虽然规则不是很频繁,但是做为整体架构设计要做到灵活易用。这个时候就会结合我们的 Beam SQL 进行规则,可以通过 Spring boot 或 Spring Cloud 结合 一些配置管理系统等做一些规则下发,当然通过中间件也可以进行实现。
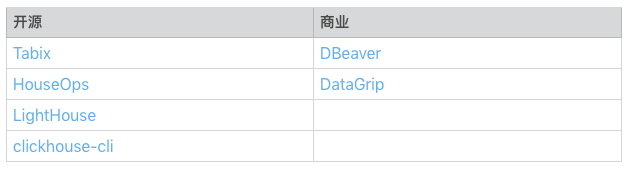
8. 支持 ClickHouse 的可视化界面工具有哪些?
七.小结
在 loT 场景下,Apache Beam 作为大一统的技术框架,随着人工智能飞速发展,赋能于前后端设备,并对分析后的结果数据做实时性的处理,起到了 " 闪送 " 数据、清洗数据的功能;而 ClickHouse 则作为后端的数据实时分析系统飞速提供结果 , Apache Beam +ClickHouse 组成了实时清洗分析一条龙架构。此外,Apache Beam 和 ClickHouse 完美结合构建了属于自己的 "AI 微服务 " ,用于对这些深数据快速加工并支撑不同场景的应用落地。
作者介绍
张海涛,目前就职于海康威视云基础平台,负责云计算大数据的基础架构设计和中间件的开发,专注云计算大数据方向。Apache Beam 中文社区发起人之一,如果想进一步了解最新 Apache Beam 和 ClickHouse 动态和技术研究成果,请加微信 cyrjkj 入群共同研究和运用。
传送门:
-
系列文章第一篇 《Apache Beam 实战指南 | 基础入门》
-
系列文章第二篇 《Apache Beam 实战指南 | 手把手教你玩转 KafkaIO 与 Flink》
-
系列文章第三篇 《 Apache Beam 实战指南 | 手把手教你玩转大数据存储 HdfsIO 》
正文到此结束
- 本文标签: Elasticsearch 协议 JDBC maven tar centos 数据 GitHub 解析 开发 build 删除 Collection rmi 高可用 编译 AIO db HDFS 开发者 Google App 参数 schema http IO 云 分布式 服务器 索引 node js 集群 UI Netty 智能 快的 Connection 主机 图片 虚拟化 Spring Boot 备份 Dashboard 端口 部署 https 搜索引擎 基金 API CTO 软件 同步 统计 物联网 mysql id apache Spring cloud tab tk git cat 配置 管理 空间 value consumer core scala Master update 架构设计 Hadoop CST ip 产品 map 大数据 时间 key src Job 希望 java 万物 源码 stream 质量 互联网 sql Bootstrap 需求 Docker 开源 dist 下载 spring 专注 测试 微服务 pom 数据库 HBase IDE 代码 json final client 文章 MQ
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

