这是一篇你能看懂 Java JVM 文章
(本文参考深入理解JAVA虚拟机第三版第2章) 复制代码
一、认识Java环境
在讲 JVM 之前,先讲讲 JDK、JRE和 JVM 的关系,如下面这张图(图片来自百度图片):

可以看到他们的包含关系是 JDK>JRE>JVM
- JDK :jdk是支持 JAVA程序开发的最小环境,集成了JRE和一些工具包,如 javac,jar等;比如一个可运行jar,你就需要安装了jdk,才能运行起来
- JRE :是Java运行时的标准环境,除了JVM的环境还有一些基本的JAVA库,比如界面的 swing、I/O等
JVM:熟称Java虚拟机,也叫运行时数据区域,是保证跨平台的基本,因为 jvm 只认识字节码,只要linux、window、mac 有jvm 都是可以编译执行的;当然它还有一个
而这里,我们就需要讲解 JVM 这个 运行时数据区域的分布了,如下图(图片来自百度图片,稍微修改了一点):
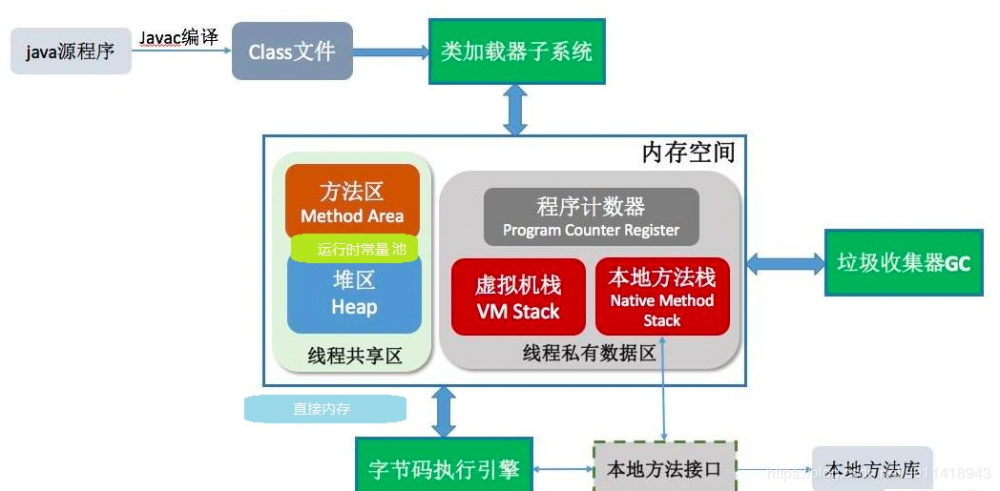
上面解释了一个java程序是怎么运行的,其中 内存空间这里,就是 JVM 了;
- 线程共享区 :即程序运行时,数据在各个线程之间是共享的,比如某个方法,某个类,还有一些运行时常量
- 线程私有区 :各个线程之间的数据是独立的,比如多线程的数据
为了方便解释,这里的顺序不会像上图那里的顺序来;
二、线程私有区
2.1、程序计算器
首先先了解程序计算器,线程(UI线程)中程序语句的执行都离不开它,对它的解释如下:
- 是一块较小的内存存于,可以看做当前线程执行字节码时的行号指示器
- 程序的运行,比如跳转、循环等指令,就是通过改变计算器的数值,来选取下一条需要执行的字节码指令
- 多线程时,每个线程的程序计算器都是独立的,相互不干扰,独立储存;即记录每次线程的位置,方便下次线程切换过来,知道上次线程的运行到哪了
2.2 虚拟机栈
结合方法去中的一些变量和常量去理解会比较好 复制代码
虚拟机栈也是线程私有的,与线程的生命周期相同;它对应着线程的内存模式,每个 方法 在执行的时候,都有一个 栈帧 用于存储局部表,操作数栈、动态链接、方法出口等信息;每个方法的执行,都对应着一个栈帧在虚拟机栈中的入栈和出栈,如下图(网上找的,当时保留的,具体哪位的有点忘了,看到可以联系我)
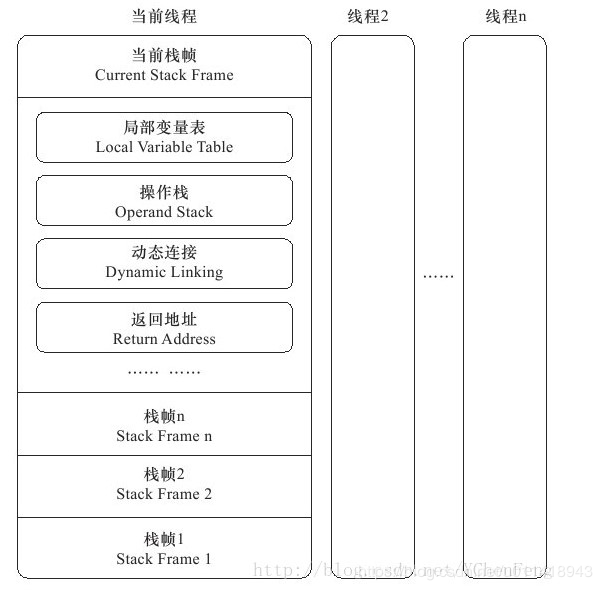
- 存储了编译器存放着各种基本数据类型(boolean、byte、char等)
- 对象引用类型,这里的对象不是对象本身,可能是对象的寻址指针,也可能是句柄或者相关位置
- returnAddress 类型,指向了一条字节码指令的地址
当进入一个 方法 时,这些 变量在帧中分配的内存大小时固定的,在运行时不会改变局部变量表的大小 。针对这个区域,规定了两种异常情况
- 如果虚拟机不支持动态扩展,当线程请求的栈大小大于虚拟机规定的大小时,抛出 StackOverflowError
- 如果虚拟机栈可以动态扩展,如果扩展时,无法申请到足够的内存,抛出 OutOfMemoryError
操作数栈:
操作数栈,也可以称做操作栈,它可以是 Java 的任意类型,在数据提取时入栈和出栈,比如 int a = 1 + 2;在把1,2入到这个操作的栈的时候,也会把1,2提取出来,再分配给 a; 动态连接:
可以这样理解,比如线程中的一个A方法,在类加载的时候,它只是一个符号引用,在运行期间,转换为直接引用,这种称为动态连接,关于符号引用,后面会说道。 方法出口: 其实就是返回地址,当方法执行完毕或者手动退出时,就出栈了,用来记录一些信息,比如恢复局部变量等信息
2.3 本地方法栈
本地方法栈与虚拟机栈的作用非常相似;只不过虚拟机栈执行的是 java 的字节码服务,而本地方法栈执行的是 Native 方法服务; 本地方法栈同样会穿件栈帧,如局部变量表、操作栈等信息,同时也有 StackOverflowError 和 OutOfMemoryError 异常
三、线程共享区
3.1 Java 堆:
是Java虚拟机锁管理的内存中最大的一块,在虚拟机启动创建时,此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都是在这分配内存的; Java 堆是内存回收的主要区域,也叫 GC 堆;根据规定,Java堆的物理地址可以是不连续的,只要保证逻辑上是连续的即可。由于Java 堆基本采用分代手机算法,所以也可以分为:新生代和老年代;再细致分,也可以分为 Eden空间,From Survivor 空间、To Surivivor 空间等涉及到的GC回收算法,后面再开章节介绍。
3.2 方法堆
方法堆也是线程共享的一个区域块,它用于存储虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区规定为 Java 堆的一个逻辑模块,但它还有一个方法,叫 Non-Heap (非堆) ,目的就是为了和 Java堆区分开来
3.2.1 运行时常量池
运行时常量池,其实算方法区的一部分。Class文件中除了有 类的版本、字段、方法、接口等信息外;还有一项信息就是常量池,用于存放编译期生成的字面量和字符引用,如下图: (图片来源 blog.csdn.net/wangbiao007… )

四、直接内存
在JDK1.4中,新增加了一个 NIO(New Inout/Outinput)类,引入了一种基于通道(channel)与缓冲区(buffer)的I/O方式,它可以使用 Native 函数库直接分配堆外内存,然后通过一个存储在Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样在一些场景中能够显著提升技能,避免了数据再 Java 堆和 Native 堆中来回复制数据,常见的通道类型有:
- FileChannel:从文件中读写数据
- DatagramChannel:从UDP中读写数据
- SocketChannel:从TCP中读写数据
- ServerSocketChannel:用来监听 websocket 的连接
具体案例可以查找NIO的具体案例 直接内存,不是虚拟机运行时内存区的一部分,也不是Java规范中定义的内存区域。但既然是内存,如果 超过了 RAM 和 SWAP 寻址空间限制,还是会报OutOfMemoryError的 。
五、HotSpot 虚拟机对象探秘
上面了解了 JVM 的一些知识之后,那么一个对象的创建是怎么样的呢?对象的创建,可以分为以下几个步骤

当虚拟机遇到一个 new 指令的时候,会先去检测这个指令的参数是否能定位到这个类的符号引用,并检查这个类是否被加载、解释或初始化过。如果没有,则执行类加载 (后面新开一章解释)
内存分配
在类加载通过之后,虚拟机将为新生对象分配内存,对象所需内存的大小在类加载完成后便可完全确定,相当于从Java堆中抽取一块内存出来;而根据内存的是否绝对规整,分为 指针碰撞 和 空闲列表 两种分配方式:
- 指针碰撞:假设Java堆中的内存只绝对规整的,分为空闲和非空闲两种,中间用一个指针当做划分界限的指示器;当一个新对象需要分配对象时,相当于把指针向空闲区域移动一段与对象大小相等的距离
- 空闲列表:假设Java堆的内存不是绝对规整的,空闲和非空闲是相互交错的,那就需要一个列表,用来记录哪些内存块是可以用的,在对象分配内存时,划分一块大小相等的区域给对象,并更新这个列表
从上面的解释看,用哪种分配方式,是通过Java堆的内存块是否绝对规整决定的。
内存分配
但对象的创建是频繁的,在并发的情况,多线程不一定是安全的,即存在A对象在分配内存,指针还未来得及修改,B对象也同时使用了原来的指针来分配对象。所以又衍生了两种解决办法, CAS+失败重试 和 TLAB 两种方式
- CAS+失败重试:虚拟机采用CAS配上失败重试的方式保证更新操作的原子性 (关于CAS锁,是乐观锁的一种实现,解释起来也比较麻烦,可以参考这里: www.cnblogs.com/javalyy/p/8… )
- TLAB:本地线程分配缓冲,把内存分配的动作按照线程分配划分在不同的空间中进行,即每个线程在Java堆中预先分配一小块内存,哪个线程需要需要分配,先在 TLAB 中分配,用完了并重新分配新的TLAB时,才需要同步锁定。
初始值为零
在内存分配完成之后,虚拟机需要将分配到的内存空间初始化为零值 (除对象头外),这一步操作也 保证了对象的实例字段在java代码中可以不赋初始值就可以使用,因为程序能访问这些字段的数据类型所对应的零值 。
设置对象头
初始值设置之后,怎么知道对象是哪个类的实例,如何才能找到类的元数据信息、哈希码、GC分代年龄等信息呢?这就需要对对象头进行一些必要的设置,才能定位到,详细在5.2节介绍。
入栈,执行init指令:
从虚拟机来看,对象已经分配产生完成了,且入栈了;但 Java 程序来看,这才刚开始,所以,new 之后,则执行 init 方法,进行初始化。
5.2 对象的内存分布
上面讲解了对象在 虚拟机的分配之后,再扩展一下,对象在内存中是怎么分配的呢,对象在内存中的存储布局可分为 3个部分:
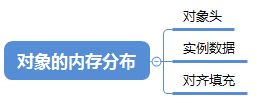
其中,对象头可以再细分为两部分:
- 存储对象自身的运行时数据 :如哈希码、GC分代年龄、锁状态标志、线程持有的、偏向线程ID等信息
- 类型指针 :即对象指向它的类元数据的指针,虚拟机通过这个来确定这个对象是哪个类的实例
实例数据
是对象真正储存的有效信息,比如程序中定义的各种类型的字段内容,无论父类和子类都会记录下来;在分配时,相同宽度的字段会被分配到一起,这也是父类定义的变量会出现在子类之前的原因。
对齐填充
没啥实际意义,只是为了保证对象是8字节的整数倍,没对齐时,用来补全而已。
5.3 对象的访问定位
建立对象是为了使用对象,Java 程序需要通过栈上的 reference 数据来操作堆上的具体对象;但这些访问方式取决于虚拟机实现而定,目前主流有句柄和直接指针两种:
- 句柄 :从Java 堆中划分出一块内存用来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄包含了对象实例数据与类型数据各自的具体地址信息,如下图(图片来自Java虚拟机第三版)
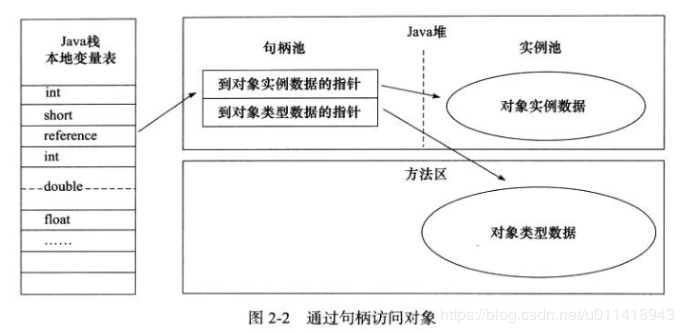
- 直接指针在直接指针中,reference 储存的就是对象地址,所以,需要考虑的是如何防止访问类型数据的相关信息(图片来自Java虚拟机第三版)
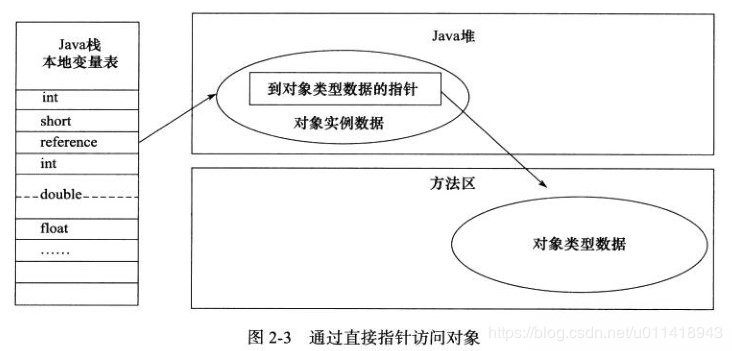
优点介绍: 句柄 :使用句柄好处是,reference中存放的是文档的句柄地址,对象被移动时,只改变句柄的实例数据指针,而reference 本身不需要修改 直接指针 :使用直接指针的最大好处就是速度更快,节省了指针定位的开销;
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

