SpringBoot+Mybatis+ Druid+PageHelper 实现多数据源并分页
前言
本篇文章主要讲述的是 SpringBoot 整合 Mybatis 、 Druid 和 PageHelper 并实现多数据源和分页。其中SpringBoot整合Mybatis这块,在之前的的一篇文章中已经讲述了,这里就不过多说明了。重点是讲述在多数据源下的如何配置使用Druid和PageHelper 。
Druid介绍和使用
在使用 Druid 之前,先来简单的了解下Druid。
Druid是一个数据库连接池。Druid可以说是目前最好的数据库连接池!因其优秀的功能、性能和扩展性方面,深受开发人员的青睐。
Druid已经在阿里巴巴部署了超过600个应用,经过一年多生产环境大规模部署的严苛考验。Druid是阿里巴巴开发的号称为监控而生的数据库连接池!
同时Druid不仅仅是一个数据库连接池,Druid 核心主要包括三部分:
-
基于Filter-Chain模式的插件体系。
-
DruidDataSource 高效可管理的数据库连接池。
-
SQLParser
Druid的主要功能如下:
介绍方面这块就不再多说,具体的可以看官方文档。
那么开始介绍Druid如何使用。
首先是Maven依赖,只需要添加druid这一个jar就行了。
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.8</version>
</dependency>
配置方面,主要的只需要在 application.properties 或 application.yml 添加如下就可以了。
说明:因为这里我是用来两个数据源,所以稍微有些不同而已。Druid 配置的说明在下面中已经说的很详细了,这里我就不在说明了。
## 默认的数据源 master.datasource.url=jdbc:mysql://localhost:3306/springBoot?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true master.datasource.username=root master.datasource.password=123456 master.datasource.driverClassName=com.mysql.jdbc.Driver ## 另一个的数据源 cluster.datasource.url=jdbc:mysql://localhost:3306/springBoot_test?useUnicode=true&characterEncoding=utf8 cluster.datasource.username=root cluster.datasource.password=123456 cluster.datasource.driverClassName=com.mysql.jdbc.Driver # 连接池的配置信息 # 初始化大小,最小,最大 spring.datasource.type=com.alibaba.druid.pool.DruidDataSource spring.datasource.initialSize=5 spring.datasource.minIdle=5 spring.datasource.maxActive=20 # 配置获取连接等待超时的时间 spring.datasource.maxWait=60000 # 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 spring.datasource.timeBetweenEvictionRunsMillis=60000 # 配置一个连接在池中最小生存的时间,单位是毫秒 spring.datasource.minEvictableIdleTimeMillis=300000 spring.datasource.validationQuery=SELECT 1 FROM DUAL spring.datasource.testWhileIdle=true spring.datasource.testOnBorrow=false spring.datasource.testOnReturn=false # 打开PSCache,并且指定每个连接上PSCache的大小 spring.datasource.poolPreparedStatements=true spring.datasource.maxPoolPreparedStatementPerConnectionSize=20 # 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙 spring.datasource.filters=stat,wall,log4j # 通过connectProperties属性来打开mergeSql功能;慢SQL记录 spring.datasource.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
成功添加了配置文件之后,我们再来编写Druid相关的类。
首先是 MasterDataSourceConfig.java 这个类,这个是默认的数据源配置类。
@Configuration
@MapperScan(basePackages = MasterDataSourceConfig.PACKAGE, sqlSessionFactoryRef = "masterSqlSessionFactory")
public class MasterDataSourceConfig {
static final String PACKAGE = "com.pancm.dao.master";
static final String MAPPER_LOCATION = "classpath:mapper/master/*.xml";
@Value("${master.datasource.url}")
private String url;
@Value("${master.datasource.username}")
private String username;
@Value("${master.datasource.password}")
private String password;
@Value("${master.datasource.driverClassName}")
private String driverClassName;
@Value("${spring.datasource.initialSize}")
private int initialSize;
@Value("${spring.datasource.minIdle}")
private int minIdle;
@Value("${spring.datasource.maxActive}")
private int maxActive;
@Value("${spring.datasource.maxWait}")
private int maxWait;
@Value("${spring.datasource.timeBetweenEvictionRunsMillis}")
private int timeBetweenEvictionRunsMillis;
@Value("${spring.datasource.minEvictableIdleTimeMillis}")
private int minEvictableIdleTimeMillis;
@Value("${spring.datasource.validationQuery}")
private String validationQuery;
@Value("${spring.datasource.testWhileIdle}")
private boolean testWhileIdle;
@Value("${spring.datasource.testOnBorrow}")
private boolean testOnBorrow;
@Value("${spring.datasource.testOnReturn}")
private boolean testOnReturn;
@Value("${spring.datasource.poolPreparedStatements}")
private boolean poolPreparedStatements;
@Value("${spring.datasource.maxPoolPreparedStatementPerConnectionSize}")
private int maxPoolPreparedStatementPerConnectionSize;
@Value("${spring.datasource.filters}")
private String filters;
@Value("{spring.datasource.connectionProperties}")
private String connectionProperties;
@Bean(name = "masterDataSource")
@Primary
public DataSource masterDataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl(url);
dataSource.setUsername(username);
dataSource.setPassword(password);
dataSource.setDriverClassName(driverClassName);
//具体配置
dataSource.setInitialSize(initialSize);
dataSource.setMinIdle(minIdle);
dataSource.setMaxActive(maxActive);
dataSource.setMaxWait(maxWait);
dataSource.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis);
dataSource.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis);
dataSource.setValidationQuery(validationQuery);
dataSource.setTestWhileIdle(testWhileIdle);
dataSource.setTestOnBorrow(testOnBorrow);
dataSource.setTestOnReturn(testOnReturn);
dataSource.setPoolPreparedStatements(poolPreparedStatements);
dataSource.setMaxPoolPreparedStatementPerConnectionSize(maxPoolPreparedStatementPerConnectionSize);
try {
dataSource.setFilters(filters);
} catch (SQLException e) {
e.printStackTrace();
}
dataSource.setConnectionProperties(connectionProperties);
return dataSource;
}
@Bean(name = "masterTransactionManager")
@Primary
public DataSourceTransactionManager masterTransactionManager() {
return new DataSourceTransactionManager(masterDataSource());
}
@Bean(name = "masterSqlSessionFactory")
@Primary
public SqlSessionFactory masterSqlSessionFactory(@Qualifier("masterDataSource") DataSource masterDataSource)
throws Exception {
final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();
sessionFactory.setDataSource(masterDataSource);
sessionFactory.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources(MasterDataSourceConfig.MAPPER_LOCATION));
return sessionFactory.getObject();
}
}
其中这两个注解说明下:
-
@Primary :标志这个 Bean 如果在多个同类 Bean 候选时,该 Bean
-
优先被考虑。多数据源配置的时候注意,必须要有一个主数据源,用 @Primary 标志该 Bean。
-
@MapperScan : 扫描 Mapper 接口并容器管理。
需要注意的是 sqlSessionFactoryRef 表示定义一个唯一 SqlSessionFactory 实例。
上面的配置完之后,就可以将Druid作为连接池使用了。但是Druid并不简简单单的是个连接池,它也可以说是一个监控应用,它自带了web监控界面,可以很清晰的看到SQL相关信息。
在 SpringBoot 中运用 Druid 的监控作用,只需要编写 StatViewServlet 和 WebStatFilter 类,实现注册服务和过滤规则。这里我们可以将这两个写在一起,使用 @Configuration 和 @Bean 。
为了方便理解,相关的配置说明也写在代码中了,这里就不再过多赘述了。
代码如下:
@Configuration
public class DruidConfiguration {
@Bean
public ServletRegistrationBean druidStatViewServle() {
//注册服务
ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(
new StatViewServlet(), "/druid/*");
// 白名单(为空表示,所有的都可以访问,多个IP的时候用逗号隔开)
servletRegistrationBean.addInitParameter("allow", "127.0.0.1");
// IP黑名单 (存在共同时,deny优先于allow)
servletRegistrationBean.addInitParameter("deny", "127.0.0.2");
// 设置登录的用户名和密码
servletRegistrationBean.addInitParameter("loginUsername", "pancm");
servletRegistrationBean.addInitParameter("loginPassword", "123456");
// 是否能够重置数据.
servletRegistrationBean.addInitParameter("resetEnable", "false");
return servletRegistrationBean;
}
@Bean
public FilterRegistrationBean druidStatFilter() {
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(
new WebStatFilter());
// 添加过滤规则
filterRegistrationBean.addUrlPatterns("/*");
// 添加不需要忽略的格式信息
filterRegistrationBean.addInitParameter("exclusions",
"*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*");
System.out.println("druid初始化成功!");
return filterRegistrationBean;
}
}
编写完之后,启动程序,在浏览器输入:http://127.0.0.1:8084/druid/index.html ,然后输入设置的用户名和密码,便可以访问Web界面了。
多数据源配置
在进行多数据源配置之前,先分别在 springBoot 和 springBoot_test 的 mysql 数据库中执行如下脚本。
-- springBoot库的脚本 CREATE TABLE `t_user` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增id', `name` varchar(10) DEFAULT NULL COMMENT '姓名', `age` int(2) DEFAULT NULL COMMENT '年龄', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8 -- springBoot_test库的脚本 CREATE TABLE `t_student` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(16) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8
注:为了偷懒,将两张表的结构弄成一样了!不过不影响测试!
在 application.properties 中已经配置这两个数据源的信息,上面已经贴出了一次配置,这里就不再贴了。
这里重点说下 第二个数据源的配置。和上面的 MasterDataSourceConfig.java 差不多,区别在与没有使用 @Primary 注解和名称不同而已。需要注意的是 MasterDataSourceConfig.java 对package和mapper的扫描是精确到目录的,这里的第二个数据源也是如此。那么代码如下:
@Configuration
@MapperScan(basePackages = ClusterDataSourceConfig.PACKAGE, sqlSessionFactoryRef = "clusterSqlSessionFactory")
public class ClusterDataSourceConfig {
static final String PACKAGE = "com.pancm.dao.cluster";
static final String MAPPER_LOCATION = "classpath:mapper/cluster/*.xml";
@Value("${cluster.datasource.url}")
private String url;
@Value("${cluster.datasource.username}")
private String username;
@Value("${cluster.datasource.password}")
private String password;
@Value("${cluster.datasource.driverClassName}")
private String driverClass;
// 和MasterDataSourceConfig一样,这里略
@Bean(name = "clusterDataSource")
public DataSource clusterDataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl(url);
dataSource.setUsername(username);
dataSource.setPassword(password);
dataSource.setDriverClassName(driverClass);
// 和MasterDataSourceConfig一样,这里略 ...
return dataSource;
}
@Bean(name = "clusterTransactionManager")
public DataSourceTransactionManager clusterTransactionManager() {
return new DataSourceTransactionManager(clusterDataSource());
}
@Bean(name = "clusterSqlSessionFactory")
public SqlSessionFactory clusterSqlSessionFactory(@Qualifier("clusterDataSource") DataSource clusterDataSource)
throws Exception {
final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();
sessionFactory.setDataSource(clusterDataSource);
sessionFactory.setMapperLocations(new PathMatchingResourcePatternResolver().getResources(ClusterDataSourceConfig.MAPPER_LOCATION));
return sessionFactory.getObject();
}
}
成功写完配置之后,启动程序,进行测试。
分别在 springBoot 和 springBoot_test 库中使用接口进行添加数据。
t_user
POST http://localhost:8084/api/user
{"name":"张三","age":25}
{"name":"李四","age":25}
{"name":"王五","age":25}
t_student
POST http://localhost:8084/api/student
{"name":"学生A","age":16}
{"name":"学生B","age":17}
{"name":"学生C","age":18}
成功添加数据之后,然后进行调用不同的接口进行查询。
请求:
GET http://localhost:8084/api/user?name=李四
返回:
{
"id": 2,
"name": "李四",
"age": 25
}
请求:
GET http://localhost:8084/api/student?name=学生C
返回:
{
"id": 1,
"name": "学生C",
"age": 16
}
通过数据可以看出,成功配置了多数据源了。
PageHelper 分页实现
PageHelper是Mybatis的一个分页插件,非常的好用!这里强烈推荐!!!
PageHelper的使用很简单,只需要在Maven中添加pagehelper这个依赖就可以了。
Maven的依赖如下:
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.2.3</version>
</dependency>
注:这里我是用springBoot版的!也可以使用其它版本的。
添加依赖之后,只需要添加如下配置或代码就可以了。
第一种,在 application.properties 或 application.yml 添加
pagehelper: helperDialect: mysql offsetAsPageNum: true rowBoundsWithCount: true reasonable: false
第二种,在mybatis.xml配置中添加
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<!-- 扫描mapping.xml文件 -->
<property name="mapperLocations" value="classpath:mapper/*.xml"></property>
<!-- 配置分页插件 -->
<property name="plugins">
<array>
<bean class="com.github.pagehelper.PageHelper">
<property name="properties">
<value>
helperDialect=mysql
offsetAsPageNum=true
rowBoundsWithCount=true
reasonable=false
</value>
</property>
</bean>
</array>
</property>
</bean>
第三种,在代码中添加,使用 @Bean 注解在启动程序的时候初始化。
@Bean
public PageHelper pageHelper(){
PageHelper pageHelper = new PageHelper();
Properties properties = new Properties();
//数据库
properties.setProperty("helperDialect", "mysql");
//是否将参数offset作为PageNum使用
properties.setProperty("offsetAsPageNum", "true");
//是否进行count查询
properties.setProperty("rowBoundsWithCount", "true");
//是否分页合理化
properties.setProperty("reasonable", "false");
pageHelper.setProperties(properties);
}
因为这里我们使用的是多数据源,所以这里的配置稍微有些不同。我们需要在 sessionFactory 这里配置。这里就对 MasterDataSourceConfig.java 进行相应的修改。在 masterSqlSessionFactory 方法中,添加如下代码。
@Bean(name = "masterSqlSessionFactory")
@Primary
public SqlSessionFactory masterSqlSessionFactory(@Qualifier("masterDataSource") DataSource masterDataSource)
throws Exception {
final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();
sessionFactory.setDataSource(masterDataSource);
sessionFactory.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources(MasterDataSourceConfig.MAPPER_LOCATION));
//分页插件
Interceptor interceptor = new PageInterceptor();
Properties properties = new Properties();
//数据库
properties.setProperty("helperDialect", "mysql");
//是否将参数offset作为PageNum使用
properties.setProperty("offsetAsPageNum", "true");
//是否进行count查询
properties.setProperty("rowBoundsWithCount", "true");
//是否分页合理化
properties.setProperty("reasonable", "false");
interceptor.setProperties(properties);
sessionFactory.setPlugins(new Interceptor[] {interceptor});
return sessionFactory.getObject();
}
注:其它的数据源也想进行分页的时候,参照上面的代码即可。
这里需要注意的是 reasonable 参数,表示分页合理化,默认值为false。如果该参数设置为 true 时,pageNum<=0 时会查询第一页,pageNum>pages(超过总数时),会查询最后一页。默认false 时,直接根据参数进行查询。
设置完PageHelper 之后,使用的话,只需要在查询的sql前面添加 PageHelper.startPage(pageNum,pageSize); ,如果是想知道总数的话,在查询的sql语句后买呢添加 page.getTotal() 就可以了。
代码示例:
public List<T> findByListEntity(T entity) {
List<T> list = null;
try {
Page<?> page =PageHelper.startPage(1,2);
System.out.println(getClassName(entity)+"设置第一页两条数据!");
list = getMapper().findByListEntity(entity);
System.out.println("总共有:"+page.getTotal()+"条数据,实际返回:"+list.size()+"两条数据!");
} catch (Exception e) {
logger.error("查询"+getClassName(entity)+"失败!原因是:",e);
}
return list;
}
代码编写完毕之后,开始进行最后的测试。
查询 t_user 表的所有的数据,并进行分页。
请求:
GET http://localhost:8084/api/user
返回:
[
{
"id": 1,
"name": "张三",
"age": 25
},
{
"id": 2,
"name": "李四",
"age": 25
}
]
控制台打印:
开始查询... User设置第一页两条数据! 2018-04-27 19:55:50.769 DEBUG 6152 --- [io-8084-exec-10] c.p.d.m.UserDao.findByListEntity_COUNT : ==> Preparing: SELECT count(0) FROM t_user WHERE 1 = 1 2018-04-27 19:55:50.770 DEBUG 6152 --- [io-8084-exec-10] c.p.d.m.UserDao.findByListEntity_COUNT : ==> Parameters: 2018-04-27 19:55:50.771 DEBUG 6152 --- [io-8084-exec-10] c.p.d.m.UserDao.findByListEntity_COUNT : <== Total: 1 2018-04-27 19:55:50.772 DEBUG 6152 --- [io-8084-exec-10] c.p.dao.master.UserDao.findByListEntity : ==> Preparing: select id, name, age from t_user where 1=1 LIMIT ? 2018-04-27 19:55:50.773 DEBUG 6152 --- [io-8084-exec-10] c.p.dao.master.UserDao.findByListEntity : ==> Parameters: 2(Integer) 2018-04-27 19:55:50.774 DEBUG 6152 --- [io-8084-exec-10] c.p.dao.master.UserDao.findByListEntity : <== Total: 2 总共有:3条数据,实际返回:2两条数据!
查询 t_student 表的所有的数据,并进行分页。
请求:
GET http://localhost:8084/api/student
返回:
[
{
"id": 1,
"name": "学生A",
"age": 16
},
{
"id": 2,
"name": "学生B",
"age": 17
}
]
控制台打印:
开始查询... Studnet设置第一页两条数据! 2018-04-27 19:54:56.155 DEBUG 6152 --- [nio-8084-exec-8] c.p.d.c.S.findByListEntity_COUNT : ==> Preparing: SELECT count(0) FROM t_student WHERE 1 = 1 2018-04-27 19:54:56.155 DEBUG 6152 --- [nio-8084-exec-8] c.p.d.c.S.findByListEntity_COUNT : ==> Parameters: 2018-04-27 19:54:56.156 DEBUG 6152 --- [nio-8084-exec-8] c.p.d.c.S.findByListEntity_COUNT : <== Total: 1 2018-04-27 19:54:56.157 DEBUG 6152 --- [nio-8084-exec-8] c.p.d.c.StudentDao.findByListEntity : ==> Preparing: select id, name, age from t_student where 1=1 LIMIT ? 2018-04-27 19:54:56.157 DEBUG 6152 --- [nio-8084-exec-8] c.p.d.c.StudentDao.findByListEntity : ==> Parameters: 2(Integer) 2018-04-27 19:54:56.157 DEBUG 6152 --- [nio-8084-exec-8] c.p.d.c.StudentDao.findByListEntity : <== Total: 2 总共有:3条数据,实际返回:2两条数据!
查询完毕之后,我们再来看Druid 的监控界面。在浏览器输入:http://127.0.0.1:8084/druid/index.html
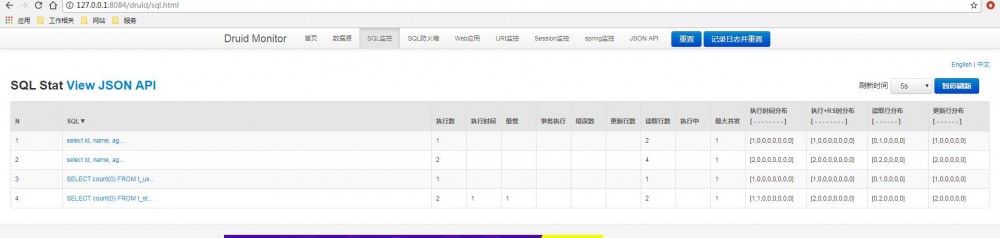
可以很清晰的看到操作记录!
如果想知道更多的Druid相关知识,可以查看官方文档!
结语
这篇终于写完了,在进行代码编写的时候,碰到过很多问题,然后慢慢的尝试和找资料解决了。本篇文章只是很浅的介绍了这些相关的使用,在实际的应用可能会更复杂。如果有有更好的想法和建议,欢迎留言进行讨论!
正文到此结束
- 本文标签: sqlsession bug 部署 spring maven find UI 时间 key final Word springboot pagehelper 目录 db tar 配置 代码 XML 开发 http mapper id druid mysql tab js map GitHub 实例 参数 统计 SqlSessionFactory Master Qualifier classpath https sql API Select 分页 entity bean IO Statement 测试 git 阿里巴巴 管理 parse mybatis src Action NIO JDBC root ip cat NSA HTML 插件 lib Property cache 连接池 web servlet 学生 CSS App list Connection 文章 plugin session java 数据库 数据 CTO value dataSource ACE
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

