使用模式构建:近似值模式(The Approximation Pattern)
假设现在有一个相当规模的城市,大约有3.9万人。人口的确切数字是相当不稳定的,人们会搬入搬出、有婴儿会出生、有人会死亡。我们也许要花上整天的时间来得到每天确切的居民数量。但在大多数情况下,39,000这个数字已经“足够好”了。同样,在许多我们开发的应用程序中,知道“足够好”程度的数字就可以了。如果一个“足够好”的数字就够了,那么这就是一个应用 近似值模式 的好机会。
近似值模式
在所需要的计算非常有挑战性或消耗的资源昂贵(时间、内存、CPU周期)时,如果精度不是首要考虑因素时,那么我们就可以使用近似值模式。再回顾一下人口问题, 精确 计算这个数字的成本是多少?从我开始计算起,它将会改变还是可能会改变?如果这个数字被报告为39,000,而实际上是39,012,这会对这个城市的规划战略产生什么影响?
从应用程序的角度看,我们可以构建一个近似因子,它允许对数据库进行更少写入的同时仍然提供统计上有效的数字。例如,假设我们的城市规划是基于每10000人需要一台消防车,那么用100人作为这个计划的“更新”周期看起来就不错。“我们正接近下一个阈值了,最好现在开始做预算吧。”
在应用程序中,我们不需要每次更改都去更新数据库中的人口数。我们可以构建一个计数器,只在每达到100的时候才去更新数据库,这样只用原来1%的时间。在这个例子里,我们的写操作显著减少了99%。还有一种做法是创建一个返回随机数的函数。比如该函数返回一个0到100之间的数字,它在大约1%的时间会返回0。当这个条件满足时,我们就把计数器增加100。
我们为什么需要关心这个?当数据量很大或用户量很多时,对写操作性能的影响也会变得很明显。规模越大,影响也越大,而当数据有一定规模时,这通常是你最需要关心的。通过减少写操作以及不必要的“完美”,可以极大地提高性能。
应用场景示例
人口统计的方式是近似值模式的一个示例。另一个可以应用此模式的用例是网站视图。一般来说,知道访问过该网站的人数是700,000还是699,983并不重要。因此,我们可以在应用程序中构建一个计数器,并在满足阈值时再更新数据库。
这可能会极大地降低网站的性能。在关键业务数据的写入上花费时间和资源才是有意义的,而把它们全部花在一个页面计数器上似乎并不是对资源很好的利用。
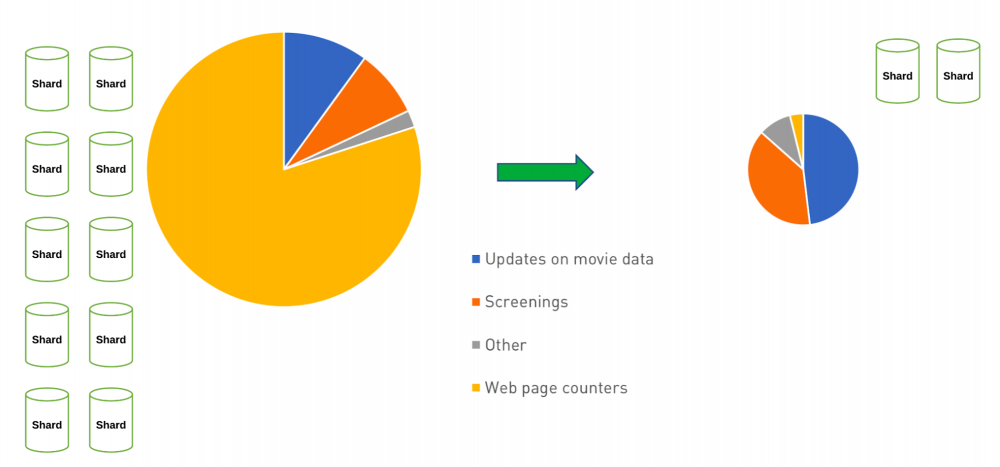
电影网站 – 写操作负载降低
在上图中,我们看到了如何使用 近似值模式 ,这不仅可以减少计数操作的写入,还可以通过减少这些写入来降低架构的复杂性和开销。这可以带来更多的收益,而不仅仅是写操作时间的减少。与前面讨论过的 计算模式(The Computed Pattern) 类似,它通过降低计算的频率,从而在总体上节约了CPU的使用。
结论
近似值模式 对于处理难以计算和/或计算成本高昂的数据,并且这些数字的精确度不太关键的应用程序是一个很好的解决方案。我们可以减少对数据库的写入,从而提高性能,并且保持数字仍然在统计上是有效的。然而,使用这种模式的代价是精确的数字无法被表示出来,并且必须在应用程序本身中实现。
本系列的下一篇文章将介绍 树形模式(Tree Pattern) 。
如果你有任何问题,请在下面留言。
使用模式构建系列:
- 多态模式(The Polymorphic Pattern)
- 属性模式(The Attribute Pattern)
- 桶模式(The Bucket Pattern)
- 异常值模式(The Outlier Pattern)
- 计算模式(The Computed Pattern)
- 子集模式(The Subset Pattern)
- 扩展引用模式(The Extended Reference Pattern)
本文译自: Building with Patterns: The Approximation Pattern
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

