微服务调用链基本原理与使用
分布式系统之后,系统变的错综复杂,一般很难全盘理解整个系统,并且错误比较难定位,需要有调用链监控,快速的帮我们定位监控问题,了解微服务体系。
如果没有应用监控:
- 线上发布了服务,怎么知道一切正常
- 大量报错,到底是哪里产生的,谁才是原因
- 人工配置错误,通宵排查,劳民伤财
- 数据库问题,在出问题之前能洞察吗
任何可能出错的地方都会出错,微服务需要应用监控 —— 康威定律
如何尽早的发现问题?
-
实践1:要提升,必先能测量。需要给开发人员一把测量反馈的尺子
-
实践2:谁构建,谁允许,谁监控。运维不知道开发的上下文,理解有限,开发人员自助的话,能更好的提升系统
调用链监控原理
2010年的时候,谷歌发布过Dapper的论文,可以读一下论文。论文地址
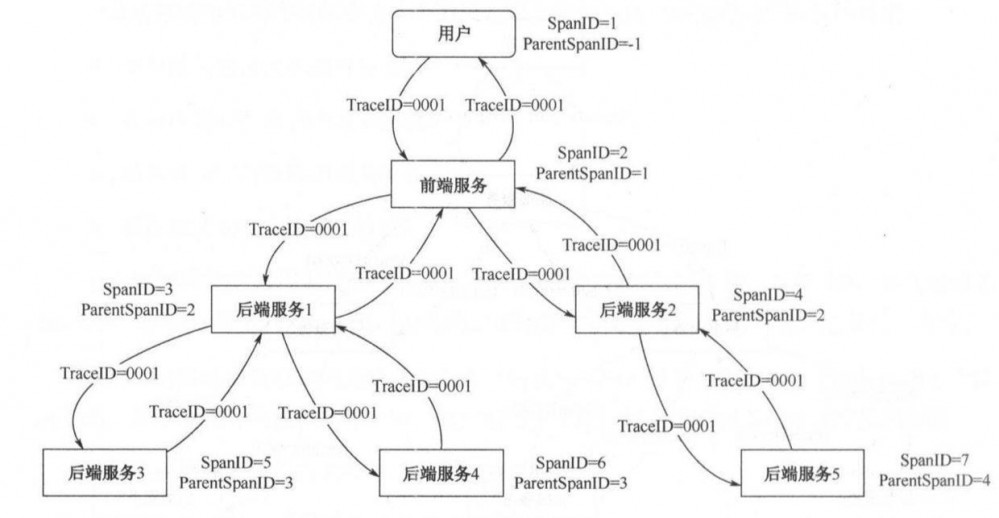
- traceid:有的会命名为requestNo,整个调用链路中的traceid是相同的,这样可以通过一个traceid找到系统间所有交互过的请求和响应
- spanid:仅仅有traceid,无法精确的得知到底是哪个服务先被调用的,哪个服务后被调用的,spanid和parentSpanid组合起来就可以表示成一个树形的调用关系。
当系统出错的时候:
- 把traceid收集到一个集合中,包含请求与响应
- 通过spanid与parentSpanId恢复成树形调用
- 识别超时与出错的节点,进行标记
- 把上面的信息与出错节点信息展示出来
现在开源的调用链监控系统:
- Cat,美团点评开源,原型和理念源自ebay的CAL系统 ,我们公司是基于Cat进行改造的。 github.com/dianping/ca…
- Zipkin:基于谷歌Dapper论文的开源实现,zipkin.io/
美团点评Cat
介绍可以参考官方文档,提供了监控,报警。
- 报表丰富,有助于从各个角度了解系统整理概括
- 便于快速发现和根音问题
- 有助于培养互联网人的:DevOPS自主和自助的意识,卓越质量意识
- 发现技术债,红黑榜,性能好系统的放在红榜,性能差的系统放在黑榜,督促人员优化
使用
这里显示的是基于Cat做了一些改造。
报错大盘
- 快速发现分钟级异常状况
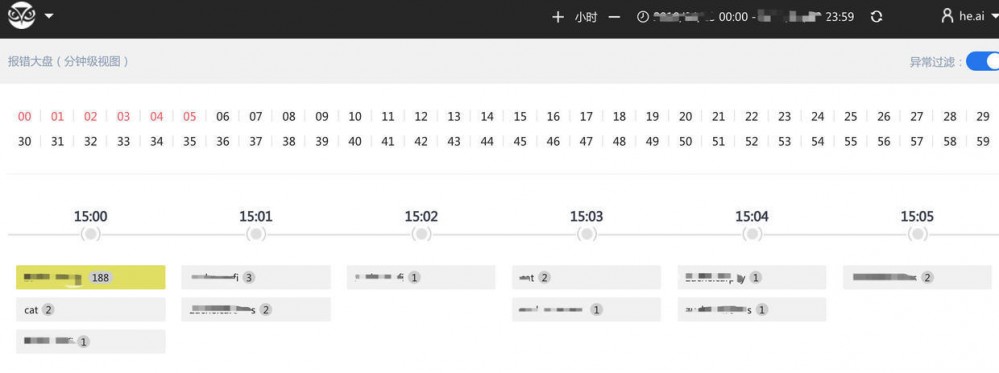
- 点进去查看异常的类型与具体信息
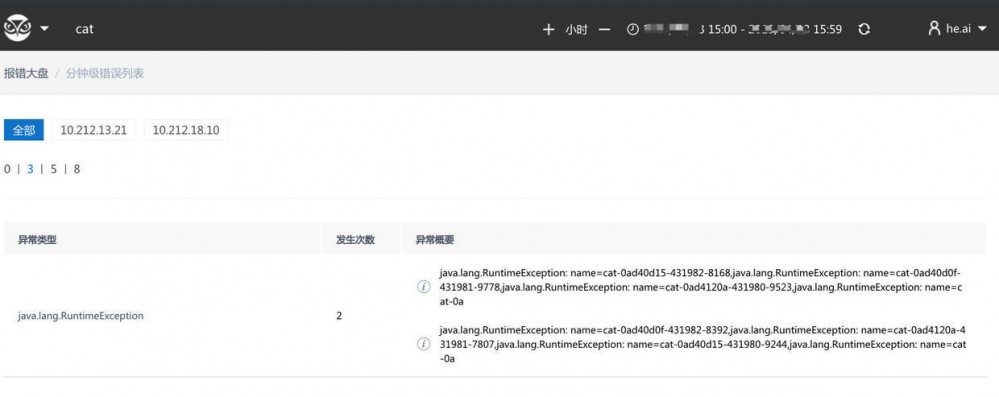
- 点击异常概要,查看异常的完整调用链路,点击发生时间,可以看到异常的方法调用链

关于报错大盘的使用,参考我之前的一篇记录:记一次简单排错经历
性能分析
- 查看埋点的性能,平均调用时长,最大时长,95%的调用耗时等,可以快速定位性能波动情况
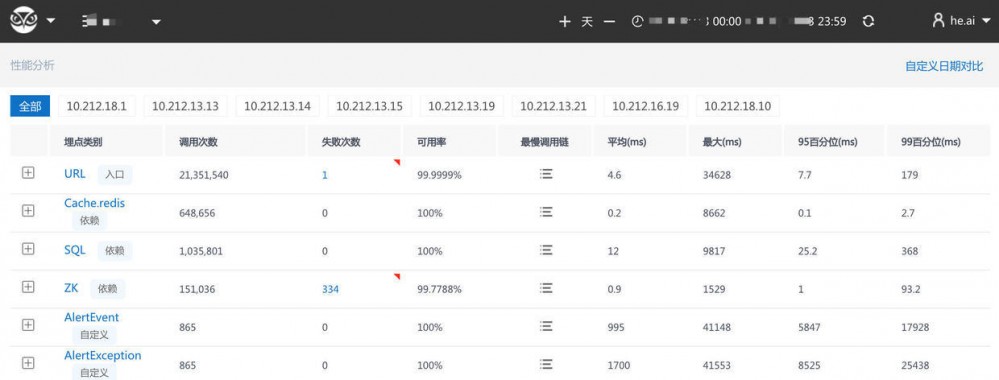
- 针对某一时刻的调用,进行分析。
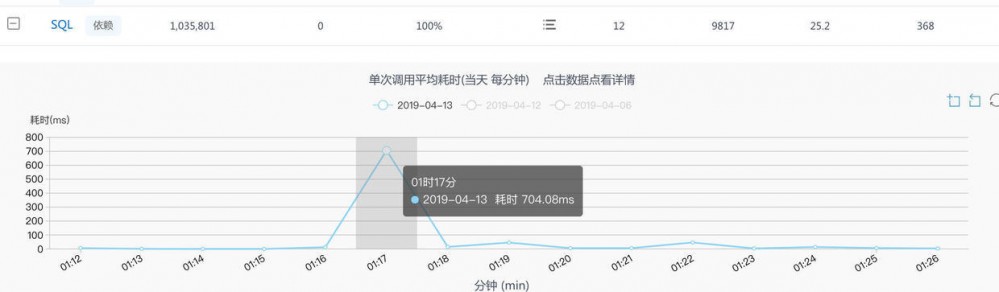
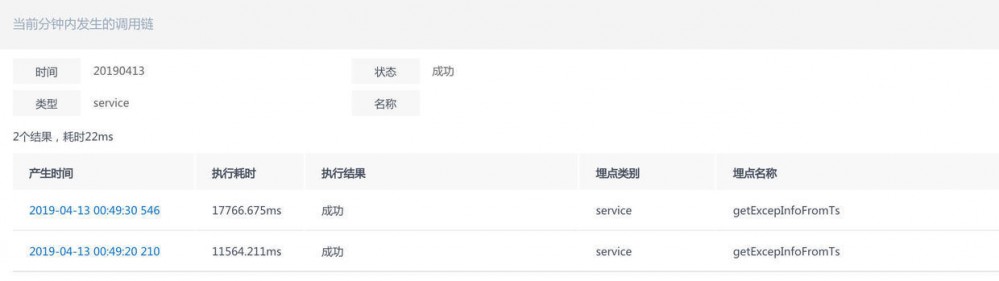
- 点击某一点时刻的调用,可以看到分钟级的调用统计,再对某一个调用进行跟踪可以到上面报错分析的调用链。
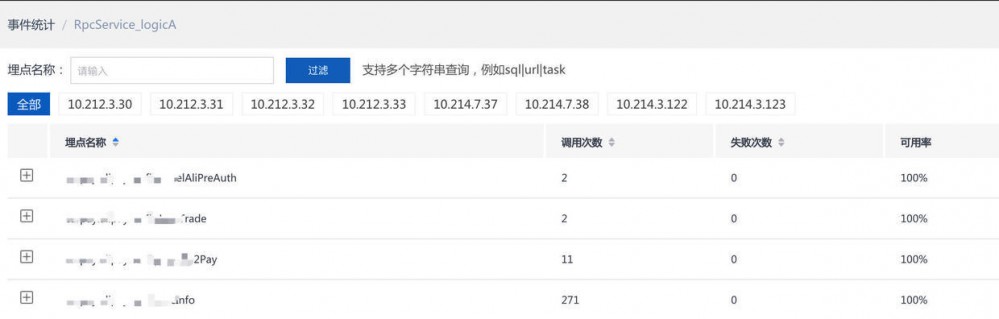
事件统计
- 对上面性能分析中的服务点进去,查看具体某些服务都调用了多少次
服务关系
查看某个系统被那些系统调用过,我们调用了那些系统
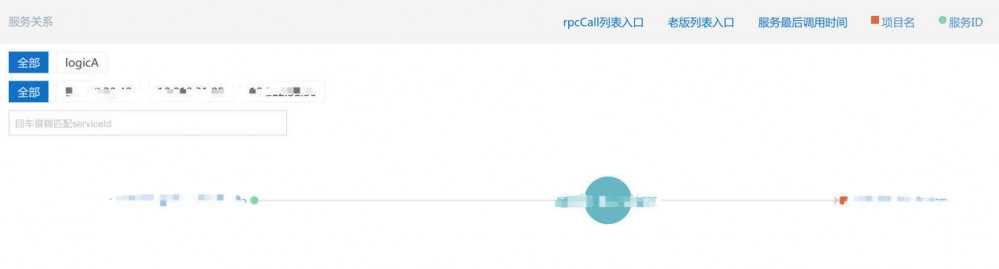
某一个服务,可以看到是谁调用的

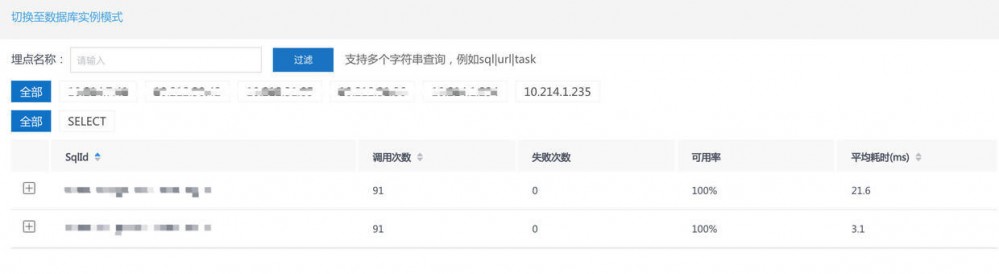
数据库大盘
查看某些sql调用了多少次,失败次数,可用率,平均耗时之类的
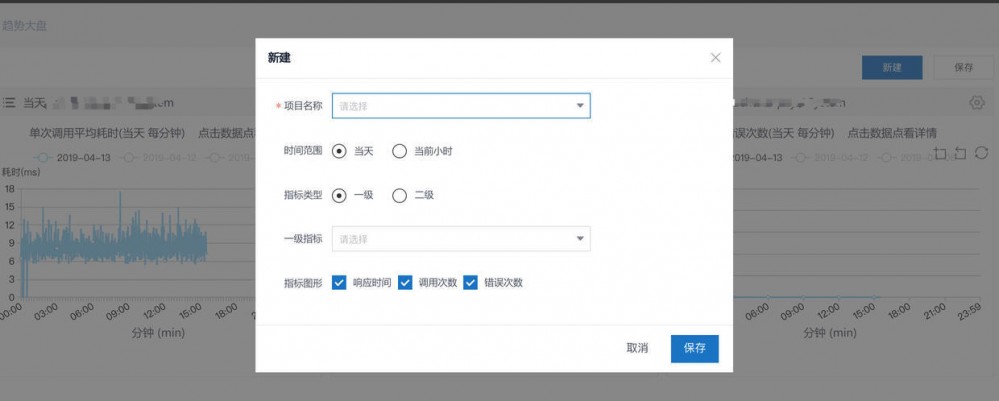
趋势大盘
自定义自己想要看的系统的指标,新建的指标会放在个人面板中
服务状态
查看主机的信息,CPU,内存,网络,JVM,线程池,磁盘等信息,Cat自身不适合做这些监控信息,对于主机的监控也可以选择其他的系统。
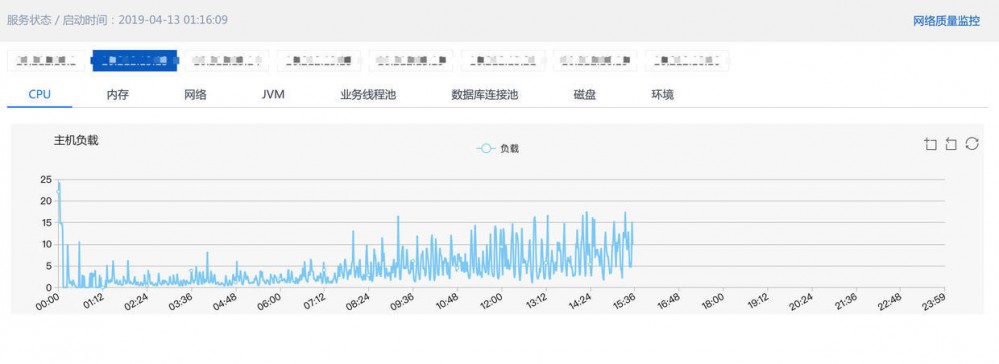
有时候错误也可能出现在磁盘问题上,所以这个也要注意下。
生产实践
在cat项目的github站点上,它已经做了一些集成好的埋点,集成地址: github.com/dianping/ca…
埋点:
- 跨进程的时候,要把上下文的信息传递下去,比如Http调用,可以把调用信息放在Http的Header中。
- Cat埋点是有侵入的,如果不想侵入代码的话,可以基于AOP,基于注解做一些埋点
部署:
- 建议采用物理机,做集群
- 如果长期存储数据,可以使用HDFS
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

