使用Gensim进行主题建模(二)
在上一篇文章中,我们将使用Mallet版本的LDA算法对此模型进行改进,然后我们将重点介绍如何在给定任何大型文本语料库的情况下获得最佳主题数。
16.构建LDA Mallet模型
到目前为止,您已经看到了Gensim内置的LDA算法版本。然而,Mallet的版本通常会提供更高质量的主题。
Gensim提供了一个包装器,用于在Gensim内部实现Mallet的LDA。您只需要下载 zip 文件,解压缩它并在解压缩的目录中提供mallet的路径。看看我在下面如何做到这一点。 gensim.models.wrappers.LdaMallet
# Download File: http://mallet.cs.umass.edu/dist/mallet-2.0.8.zipmallet_path = 'path/to/mallet-2.0.8/bin/mallet' # update this pathldamallet = gensim.models.wrappers.LdaMallet(mallet_path, corpus=corpus, num_topics=20, id2word=id2word)
# Show Topicspprint(ldamallet.show_topics(formatted=False))# Compute Coherence Scorecoherence_model_ldamallet = CoherenceModel(model=ldamallet, texts=data_lemmatized, dictionary=id2word, coherence='c_v')coherence_ldamallet = coherence_model_ldamallet.get_coherence()print('/nCoherence Score: ', coherence_ldamallet)
[(13, [('god', 0.022175351915726671), ('christian', 0.017560827817656381), ('people', 0.0088794630371958616), ('bible', 0.008215251235200895), ('word', 0.0077491376899412696), ('church', 0.0074112053696280414), ('religion', 0.0071198844038407759), ('man', 0.0067936049221590383), ('faith', 0.0067469935676330757), ('love', 0.0064556726018458093)]), (1, [('organization', 0.10977647987951586), ('line', 0.10182379194445974), ('write', 0.097397469098389255), ('article', 0.082483883409554246), ('nntp_post', 0.079894209047330425), ('host', 0.069737542931658306), ('university', 0.066303010266865026), ('reply', 0.02255404338163719), ('distribution_world', 0.014362591143681011), ('usa', 0.010928058478887726)]), (8, [('file', 0.02816690014008405), ('line', 0.021396171035954908), ('problem', 0.013508104862917751), ('program', 0.013157894736842105), ('read', 0.012607564538723234), ('follow', 0.01110666399839904), ('number', 0.011056633980388232), ('set', 0.010522980454939631), ('error', 0.010172770328863986), ('write', 0.010039356947501835)]), (7, [('include', 0.0091670556506405262), ('information', 0.0088169700741662776), ('national', 0.0085576474249260924), ('year', 0.0077667133447435295), ('report', 0.0070406099268710129), ('university', 0.0070406099268710129), ('book', 0.0068979824697889113), ('program', 0.0065219646283906432), ('group', 0.0058866241377521916), ('service', 0.0057180644157460714)]), (..truncated..)]Coherence Score: 0.632431683088
只需改变LDA算法,我们就可以将相干得分从.53增加到.63。不错!
17.如何找到LDA的最佳主题数量?
我找到最佳主题数的方法是构建具有不同主题数量(k)的许多LDA模型,并选择具有最高一致性值的LDA模型。
选择一个标志着主题连贯性快速增长的“k”通常会提供有意义和可解释的主题。选择更高的值有时可以提供更细粒度的子主题。
如果您在多个主题中看到相同的关键字重复,则可能表示'k'太大。
compute_coherence_values()(见下文)训练多个LDA模型,并提供模型及其对应的相关性分数。
def compute_coherence_values(dictionary, corpus, texts, limit, start=2, step=3): """ Compute c_v coherence for various number of topics Parameters: ---------- dictionary : Gensim dictionary corpus : Gensim corpus texts : List of input texts limit : Max num of topics Returns: ------- model_list : List of LDA topic models coherence_values : Coherence values corresponding to the LDA model with respective number of topics """ coherence_values = [] model_list = [] for num_topics in range(start, limit, step): model = gensim.models.wrappers.LdaMallet(mallet_path, corpus=corpus, num_topics=num_topics, id2word=id2word) model_list.append(model) coherencemodel = CoherenceModel(model=model, texts=texts, dictionary=dictionary, coherence='c_v') coherence_values.append(coherencemodel.get_coherence()) return model_list, coherence_values
# Can take a long time to run.model_list, coherence_values = compute_coherence_values(dictionary=id2word, corpus=corpus, texts=data_lemmatized, start=2, limit=40, step=6)
# Show graphlimit=40; start=2; step=6;x = range(start, limit, step)plt.plot(x, coherence_values)plt.xlabel("Num Topics")plt.ylabel("Coherence score")plt.legend(("coherence_values"), loc='best')plt.show()
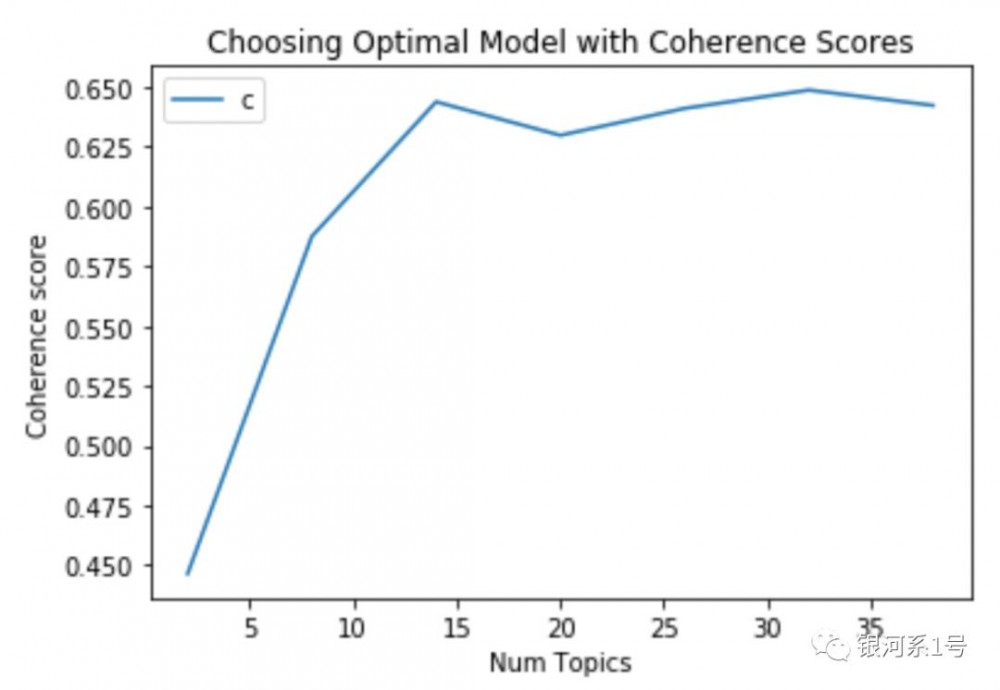
选择最佳数量的LDA主题
# Print the coherence scoresfor m, cv in zip(x, coherence_values): print("Num Topics =", m, " has Coherence Value of", round(cv, 4))
Num Topics = 2 has Coherence Value of 0.4451Num Topics = 8 has Coherence Value of 0.5943Num Topics = 14 has Coherence Value of 0.6208Num Topics = 20 has Coherence Value of 0.6438Num Topics = 26 has Coherence Value of 0.643Num Topics = 32 has Coherence Value of 0.6478Num Topics = 38 has Coherence Value of 0.6525
如果相关性得分似乎在不断增加,那么选择在展平之前给出最高CV的模型可能更有意义。这就是这种情况。
因此,对于进一步的步骤,我将选择具有20个主题的模型。
# Select the model and print the topicsoptimal_model = model_list[3]model_topics = optimal_model.show_topics(formatted=False)pprint(optimal_model.print_topics(num_words=10))
[(0, '0.025*"game" + 0.018*"team" + 0.016*"year" + 0.014*"play" + 0.013*"good" + ' '0.012*"player" + 0.011*"win" + 0.007*"season" + 0.007*"hockey" + ' '0.007*"fan"'), (1, '0.021*"window" + 0.015*"file" + 0.012*"image" + 0.010*"program" + ' '0.010*"version" + 0.009*"display" + 0.009*"server" + 0.009*"software" + ' '0.008*"graphic" + 0.008*"application"'), (2, '0.021*"gun" + 0.019*"state" + 0.016*"law" + 0.010*"people" + 0.008*"case" + ' '0.008*"crime" + 0.007*"government" + 0.007*"weapon" + 0.007*"police" + ' '0.006*"firearm"'), (3, '0.855*"ax" + 0.062*"max" + 0.002*"tm" + 0.002*"qax" + 0.001*"mf" + ' '0.001*"giz" + 0.001*"_" + 0.001*"ml" + 0.001*"fp" + 0.001*"mr"'), (4, '0.020*"file" + 0.020*"line" + 0.013*"read" + 0.013*"set" + 0.012*"program" ' '+ 0.012*"number" + 0.010*"follow" + 0.010*"error" + 0.010*"change" + ' '0.009*"entry"'), (5, '0.021*"god" + 0.016*"christian" + 0.008*"religion" + 0.008*"bible" + ' '0.007*"life" + 0.007*"people" + 0.007*"church" + 0.007*"word" + 0.007*"man" ' '+ 0.006*"faith"'), (..truncated..)]
这些是所选LDA模型的主题。
18.在每个句子中找到主要话题
主题建模的一个实际应用是确定给定文档的主题。
为了找到这个,我们找到该文档中贡献百分比最高的主题编号。
下面的函数很好地将此信息聚合在一个可呈现的表中。 format_topics_sentences()
def format_topics_sentences(ldamodel=lda_model, corpus=corpus, texts=data): # Init output sent_topics_df = pd.DataFrame() # Get main topic in each document for i, row in enumerate(ldamodel[corpus]): row = sorted(row, key=lambda x: (x[1]), reverse=True) # Get the Dominant topic, Perc Contribution and Keywords for each document for j, (topic_num, prop_topic) in enumerate(row): if j == 0: # => dominant topic wp = ldamodel.show_topic(topic_num) topic_keywords = ", ".join([word for word, prop in wp]) sent_topics_df = sent_topics_df.append(pd.Series([int(topic_num), round(prop_topic,4), topic_keywords]), ignore_index=True) else: break sent_topics_df.columns = ['Dominant_Topic', 'Perc_Contribution', 'Topic_Keywords'] # Add original text to the end of the output contents = pd.Series(texts) sent_topics_df = pd.concat([sent_topics_df, contents], axis=1) return(sent_topics_df)df_topic_sents_keywords = format_topics_sentences(ldamodel=optimal_model, corpus=corpus, texts=data)# Formatdf_dominant_topic = df_topic_sents_keywords.reset_index()df_dominant_topic.columns = ['Document_No', 'Dominant_Topic', 'Topic_Perc_Contrib', 'Keywords', 'Text']# Showdf_dominant_topic.head(10)

每个文档的主导主题
19.找到每个主题最具代表性的文件
有时,主题关键字可能不足以理解主题的含义。因此,为了帮助理解该主题,您可以找到给定主题最有贡献的文档,并通过阅读该文档来推断该主题。呼!
# Group top 5 sentences under each topicsent_topics_sorteddf_mallet = pd.DataFrame()sent_topics_outdf_grpd = df_topic_sents_keywords.groupby('Dominant_Topic')for i, grp in sent_topics_outdf_grpd: sent_topics_sorteddf_mallet = pd.concat([sent_topics_sorteddf_mallet, grp.sort_values(['Perc_Contribution'], ascending=[0]).head(1)], axis=0)# Reset Indexsent_topics_sorteddf_mallet.reset_index(drop=True, inplace=True)# Formatsent_topics_sorteddf_mallet.columns = ['Topic_Num', "Topic_Perc_Contrib", "Keywords", "Text"]# Showsent_topics_sorteddf_mallet.head()
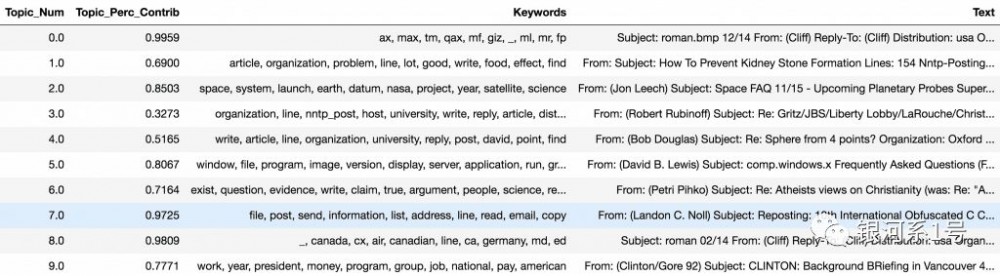
每个文档的最具代表性的主题
上面的表格输出实际上有20行,每个主题一个。它有主题编号,关键字和最具代表性的文档。该 Perc_Contribution 列只是给定文档中主题的百分比贡献。
20.主题文件分发
最后,我们希望了解主题的数量和分布,以判断讨论的范围。下表公开了该信息。
# Number of Documents for Each Topictopic_counts = df_topic_sents_keywords['Dominant_Topic'].value_counts()# Percentage of Documents for Each Topictopic_contribution = round(topic_counts/topic_counts.sum(), 4)# Topic Number and Keywordstopic_num_keywords = df_topic_sents_keywords[['Dominant_Topic', 'Topic_Keywords']]# Concatenate Column wisedf_dominant_topics = pd.concat([topic_num_keywords, topic_counts, topic_contribution], axis=1)# Change Column namesdf_dominant_topics.columns = ['Dominant_Topic', 'Topic_Keywords', 'Num_Documents', 'Perc_Documents']# Showdf_dominant_topics

主题卷分布
21.结论
我们开始了解建模可以做什么主题。我们使用Gensim的LDA构建了一个基本主题模型,并使用pyLDAvis可视化主题。然后我们构建了mallet的LDA实现。您了解了如何使用一致性分数找到最佳主题数量,以及如何理解如何选择最佳模型。
最后,我们看到了如何聚合和呈现结果,以产生可能更具可操作性的见解。
希望你喜欢读这篇文章。如果您将您的想法留在下面的评论部分,我将不胜感激。
编辑:我看到你们中的一些人在使用LDA Mallet时遇到了错误,但我没有针对某些问题的解决方案。所以,我已经实现了一个变通方法和更有用的主题模型可视化。希望你会发现它很有帮助。变通模型的地址:https://www.machinelearningplus.com/nlp/topic-modeling-visualization-how-to-present-results-lda-models/
上一篇文章链接地址: http://www.apexyun.com/shi-yong-gensimjin-xing-zhu-ti-jian-mo-python/
查看英文原文
查看更多文章
公众号:银河系1号
联系邮箱:public@space-explore.com
(未经同意,请勿转载)
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

