JVM 核心知识体系
1.问题
-
1、如何理解类文件结构布局?
-
2、如何应用类加载器的工作原理进行将应用辗转腾挪?
-
3、热部署与热替换有何区别,如何隔离类冲突?
-
4、JVM如何管理内存,有何内存淘汰机制?
-
5、JVM执行引擎的工作机制是什么?
-
6、JVM调优应该遵循什么原则,使用什么工具?
-
7、JPDA架构是什么,如何应用代码热替换?
-
8、JVM字节码增强技术有哪些?
2.关键词
类结构,类加载器,加载,链接,初始化,双亲委派,热部署,隔离,堆,栈,方法区,计数器,内存回收,执行引擎,调优工具,JVMTI,JDWP,JDI,热替换,字节码,ASM,CGLIB,DCEVM
3.全文概要(文末有惊喜,PC端阅读代码更佳)
作为三大工业级别语言之一的JAVA如此受企业青睐有加,离不开她背后JVM的默默复出。只是由于JAVA过于成功以至于我们常常忘了JVM平台上还运行着像Clojure/Groovy/Kotlin/Scala/JRuby/Jython这样的语言。我们享受着JVM带来跨平台“一次编译到处执行”台的便利和自动内存回收的安逸。本文从JVM的最小元素类的结构出发,介绍类加载器的工作原理和应用场景,思考类加载器存在的意义。进而描述JVM逻辑内存的分布和管理方式,同时列举常用的JVM调优工具和使用方法,最后介绍高级特性JDPA框架和字节码增强技术,实现热替换。从微观到宏观,从静态到动态,从基础到高阶介绍JVM的知识体系。
4.类的装载
4.1类的结构
我们知道不只JAVA文本文件,像Clojure/Groovy/Kotlin/Scala这些文本文件也同样会经过JDK的编译器编程成class文件。进入到JVM领域后,其实就跟JAVA没什么关系了,JVM只认得class文件,那么我们需要先了解class这个黑箱里面包含的是什么东西。
JVM规范严格定义了CLASS文件的格式,有严格的数据结构,下面我们可以观察一个简单CLASS文件包含的字段和数据类型。
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
详细的描述我们可以从JVM规范说明书里面查阅类文件格式( https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-4.html ),类的整体布局如下图展示的。

在我的理解,我想把每个CLASS文件类别成一个一个的数据库,里面包含的常量池/类索引/属性表集合就像数据库的表,而且表之间也有关联,常量池则存放着其他表所需要的所有字面量。了解完类的数据结构后,我们需要来观察JVM是如何使用这些从硬盘上或者网络传输过来的CLASS文件。
4.2加载机制
4.2.1类的入口
在我们探究JVM如何使用CLASS文件之前,我们快速回忆一下编写好的C语言文件是如何执行的?我们从C的HelloWorld入手看看先。
#include <stdio.h>
int main() {
/* my first program in C */
printf("Hello, World! /n");
return 0;
}
编辑完保存为hello.c文本文件,然后安装gcc编译器(GNU C/C++)
$ gcc hello.c $ ./a.out Hello, World!
这个过程就是gcc编译器将hello.c文本文件编译成机器指令集,然后读取到内存直接在计算机的CPU运行。从操作系统层面看的话,就是一个进程的启动到结束的生命周期。
下面我们看JAVA是怎么运行的。学习JAVA开发的第一件事就是先下载JDK安装包,安装完配置好环境变量,然后写一个名字为helloWorld的类,然后编译执行,我们来观察一下发生了什么事情?
先看源码,有够简单了吧。
package com.zooncool.example.theory.jvm;
public class HelloWorld {
public static void main(String[] args) {
System.out.println("my classLoader is " + HelloWorld.class.getClassLoader());
}
}
编译执行
$ javac src/main/java/com/zooncool/example/theory/jvm/HelloWorld.java $ java -cp src/main/java/ com.zooncool.example.theory.jvm.HelloWorld my classLoader is sun.misc.Launcher$AppClassLoader@2a139a55
对比C语言在命令行直接运行编译后的a.out二进制文件,JAVA的则是在命令行执行java classFile,从命令的区别我们知道操作系统启动的是java进程,而HelloWorld类只是命令行的入参,在操作系统来看java也就是一个普通的应用进程而已,而这个进程就是JVM的执行形态(JVM静态就是硬盘里JDK包下的二进制文件集合)。
学习过JAVA的都知道入口方法是public static void main(String[] args),缺一不可,那我猜执行java命令时JVM对该入口方法做了唯一验证,通过了才允许启动JVM进程,下面我们来看这个入口方法有啥特点。
-
去掉public限定
$ javac src/main/java/com/zooncool/example/theory/jvm/HelloWorld.java $ java -cp src/main/java/ com.zooncool.example.theory.jvm.HelloWorld 错误: 在类 com.zooncool.example.theory.jvm.HelloWorld 中找不到 main 方法, 请将 main 方法定义为: public static void main(String[] args) 否则 JavaFX 应用程序类必须扩展javafx.application.Application
说名入口方法需要被public修饰,当然JVM调用main方法是底层的JNI方法调用不受修饰符影响。
-
去掉static限定
$ javac src/main/java/com/zooncool/example/theory/jvm/HelloWorld.java $ java -cp src/main/java/ com.zooncool.example.theory.jvm.HelloWorld 错误: main 方法不是类 com.zooncool.example.theory.jvm.HelloWorld 中的static, 请将 main 方法定义为: public static void main(String[] args)
我们是从类对象调用而不是类创建的对象才调用,索引需要静态修饰
-
返回类型改为int
$ javac src/main/java/com/zooncool/example/theory/jvm/HelloWorld.java $ java -cp src/main/java/ com.zooncool.example.theory.jvm.HelloWorld 错误: main 方法必须返回类 com.zooncool.example.theory.jvm.HelloWorld 中的空类型值, 请 将 main 方法定义为: public static void main(String[] args)
void返回类型让JVM调用后无需关心调用者的使用情况,执行完就停止,简化JVM的设计。
-
方法签名改为main1
$ javac src/main/java/com/zooncool/example/theory/jvm/HelloWorld.java $ java -cp src/main/java/ com.zooncool.example.theory.jvm.HelloWorld 错误: 在类 com.zooncool.example.theory.jvm.HelloWorld 中找不到 main 方法, 请将 main 方法定义为: public static void main(String[] args) 否则 JavaFX 应用程序类必须扩展javafx.application.Application
这个我也不清楚,可能是约定俗成吧,毕竟C/C++也是用main方法的。
说了这么多main方法的规则,其实我们关心的只有两点:
-
HelloWorld类是如何被JVM使用的
-
HelloWorld类里面的main方法是如何被执行的
关于JVM如何使用HelloWorld下文我们会详细讲到。
我们知道JVM是由C/C++语言实现的,那么JVM跟CLASS打交道则需要JNI(Java Native Interface)这座桥梁,当我们在命令行执行java时,由C/C++实现的java应用通过JNI找到了HelloWorld里面符合规范的main方法,然后开始调用。我们来看下java命令的源码就知道了
/*
* Get the application's main class.
*/
if (jarfile != 0) {
mainClassName = GetMainClassName(env, jarfile);
... ...
mainClass = LoadClass(env, classname);
if(mainClass == NULL) { /* exception occured */
... ...
/* Get the application's main method */
mainID = (*env)->GetStaticMethodID(env, mainClass, "main", "([Ljava/lang/String;)V");
... ...
{/* Make sure the main method is public */
jint mods;
jmethodID mid;
jobject obj = (*env)->ToReflectedMethod(env, mainClass, mainID, JNI_TRUE);
... ...
/* Build argument array */
mainArgs = NewPlatformStringArray(env, argv, argc);
if (mainArgs == NULL) {
ReportExceptionDescription(env);
goto leave;
}
/* Invoke main method. */
(*env)->CallStaticVoidMethod(env, mainClass, mainID, mainArgs);
4.2.2类加载器
上一节我们留了一个核心的环节,就是JVM在执行类的入口之前,首先得找到类再然后再把类装到JVM实例里面,也即是JVM进程维护的内存区域内。我们当然知道是一个叫做类加载器的工具把类加载到JVM实例里面,抛开细节从操作系统层面观察,那么就是JVM实例在运行过程中通过IO从硬盘或者网络读取CLASS二进制文件,然后在JVM管辖的内存区域存放对应的文件。我们目前还不知道类加载器的实现,但是我们从功能上判断无非就是读取文件到内存,这个是很普通也很简单的操作。
如果类加载器是C/C++实现的话,那么大概就是如下代码就可以实现
char *fgets( char *buf, int n, FILE *fp );
如果是JAVA实现,那么也很简单
InputStream f = new FileInputStream("theory/jvm/HelloWorld.class");
从操作系统层面看的话,如果只是加载,以上代码就足以把类文件加载到JVM内存里面了。但是结果就是乱糟糟的把一堆毫无秩序的类文件往内存里面扔,没有良好的管理也没法用,所以需要我们需要设计一套规则来管理存放内存里面的CLASS文件,我们称为类加载的设计模式或者类加载机制,这个下文会重点解释。
根据官网的定义A class loader is an object that is responsible for loading classes. 类加载器就是负责加载类的。我们知道启动JVM的时候会把JRE默认的一些类加载到内存,这部分类使用的加载器是JVM默认内置的由C/C++实现的,比如我们上文加载的HelloWorld.class。但是内置的类加载器有明确的范围限定,也就是只能加载指定路径下的jar包(类文件的集合)。如果只是加载JRE的类,那可玩的花样就少很多,JRE只是提供了底层所需的类,更多的业务需要我们从外部加载类来支持,所以我们需要指定新的规则,以方便我们加载外部路径的类文件。
系统默认加载器
-
Bootstrap class loader
作用:启动类加载器,加载JDK核心类
类加载器:C/C++实现
类加载路径:
/jre/lib URL[] urls = sun.misc.Launcher.getBootstrapClassPath().getURLs(); /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/jre/lib/resources.jar ... /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/jre/lib/rt.jar
实现原理:本地方法由C++实现
-
Extensions class loader
作用:扩展类加载器,加载JAVA扩展类库。
类加载器:JAVA实现
类加载路径:
/jre/lib/ext System.out.println(System.getProperty("java.ext.dirs")); /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/jre/lib/ext:实现原理:扩展类加载器ExtClassLoader本质上也是URLClassLoader
Launcher.java
//构造方法返回扩展类加载器 public Launcher() { //定义扩展类加载器 Launcher.ExtClassLoader var1; try { //1、获取扩展类加载器 var1 = Launcher.ExtClassLoader.getExtClassLoader(); } catch (IOException var10) { throw new InternalError("Could not create extension class loader", var10); } ... } //扩展类加载器 static class ExtClassLoader extends URLClassLoader { private static volatile Launcher.ExtClassLoader instance; //2、获取扩展类加载器实现 public static Launcher.ExtClassLoader getExtClassLoader() throws IOException { if (instance == null) { Class var0 = Launcher.ExtClassLoader.class; synchronized(Launcher.ExtClassLoader.class) { if (instance == null) { //3、构造扩展类加载器 instance = createExtClassLoader(); } } } return instance; } //4、构造扩展类加载器具体实现 private static Launcher.ExtClassLoader createExtClassLoader() throws IOException { try { return (Launcher.ExtClassLoader)AccessController.doPrivileged(new PrivilegedExceptionAction<Launcher.ExtClassLoader>() { public Launcher.ExtClassLoader run() throws IOException { //5、获取扩展类加载器加载目标类的目录 File[] var1 = Launcher.ExtClassLoader.getExtDirs(); int var2 = var1.length; for(int var3 = 0; var3 < var2; ++var3) { MetaIndex.registerDirectory(var1[var3]); } //7、构造扩展类加载器 return new Launcher.ExtClassLoader(var1); } }); } catch (PrivilegedActionException var1) { throw (IOException)var1.getException(); } } //6、扩展类加载器目录路径 private static File[] getExtDirs() { String var0 = System.getProperty("java.ext.dirs"); File[] var1; if (var0 != null) { StringTokenizer var2 = new StringTokenizer(var0, File.pathSeparator); int var3 = var2.countTokens(); var1 = new File[var3]; for(int var4 = 0; var4 < var3; ++var4) { var1[var4] = new File(var2.nextToken()); } } else { var1 = new File[0]; } return var1; } //8、扩展类加载器构造方法 public ExtClassLoader(File[] var1) throws IOException { super(getExtURLs(var1), (ClassLoader)null, Launcher.factory); SharedSecrets.getJavaNetAccess().getURLClassPath(this).initLookupCache(this); } } -
System class loader
作用:系统类加载器,加载应用指定环境变量路径下的类
类加载器:sun.misc.Launcher$AppClassLoader
类加载路径:-classpath下面的所有类
实现原理:系统类加载器AppClassLoader本质上也是URLClassLoader
Launcher.java
//构造方法返回系统类加载器 public Launcher() { try { //获取系统类加载器 this.loader = Launcher.AppClassLoader.getAppClassLoader(var1); } catch (IOException var9) { throw new InternalError("Could not create application class loader", var9); } } static class AppClassLoader extends URLClassLoader { final URLClassPath ucp = SharedSecrets.getJavaNetAccess().getURLClassPath(this); //系统类加载器实现逻辑 public static ClassLoader getAppClassLoader(final ClassLoader var0) throws IOException { //类比扩展类加载器,相似的逻辑 final String var1 = System.getProperty("java.class.path"); final File[] var2 = var1 == null ? new File[0] : Launcher.getClassPath(var1); return (ClassLoader)AccessController.doPrivileged(new PrivilegedAction<Launcher.AppClassLoader>() { public Launcher.AppClassLoader run() { URL[] var1x = var1 == null ? new URL[0] : Launcher.pathToURLs(var2); return new Launcher.AppClassLoader(var1x, var0); } }); } //系统类加载器构造方法 AppClassLoader(URL[] var1, ClassLoader var2) { super(var1, var2, Launcher.factory); this.ucp.initLookupCache(this); } }
通过上文运行HelloWorld我们知道JVM系统默认加载的类大改是1560个,如下图
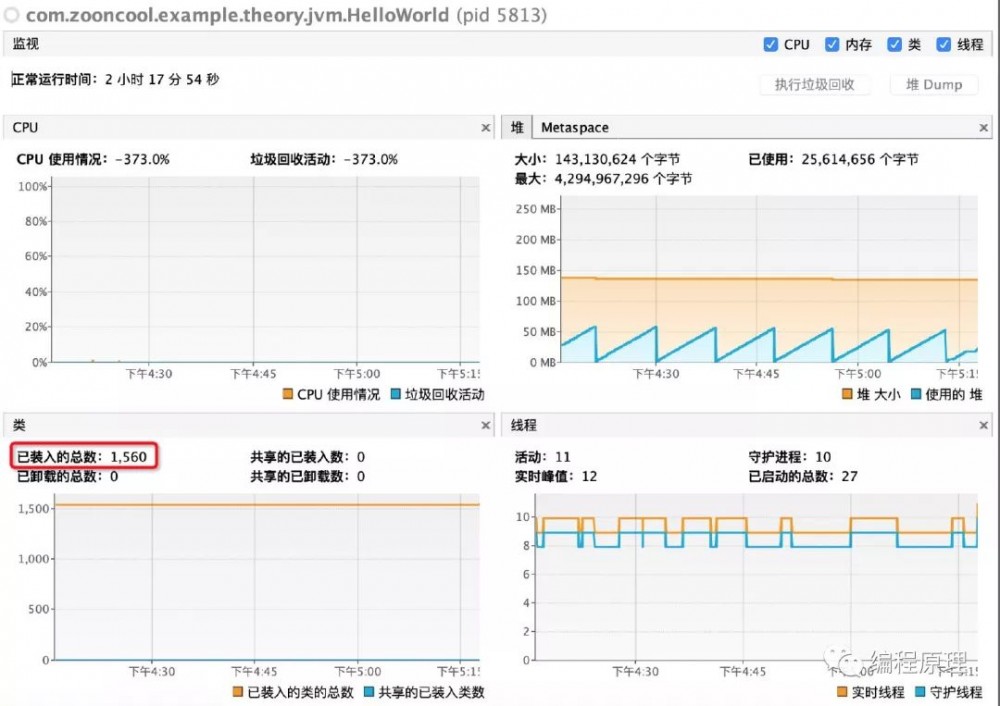
自定义类加载器
内置类加载器只加载了最少需要的核心JAVA基础类和环境变量下的类,但是我们应用往往需要依赖第三方中间件来完成额外的业务,那么如何把它们的类加载进来就显得格外重要了。幸好JVM提供了自定义类加载器,可以很方便的完成自定义操作,最终目的也是把外部的类文件加载到JVM内存。通过继承ClassLoader类并且复写findClass和loadClass方法就可以达到自定义获取CLASS文件的目的。
首先我们看ClassLoader的核心方法loadClass
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded,看缓存有没有没有才去找
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
//先看是不是最顶层,如果不是则parent为空,然后获取父类
if (parent != null) {
c = parent.loadClass(name, false);
} else {
//如果为空则说明应用启动类加载器,让它去加载
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
//如果还是没有就调用自己的方法,确保调用自己方法前都使用了父类方法,如此递归三次到顶
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
protected Class<?> findClass(String name) throws ClassNotFoundException {
throw new ClassNotFoundException(name);
}
通过复写loadClass方法,我们甚至可以读取一份加了密的文件,然后在内存里面解密,这样别人反编译你的源码也没用,因为class是经过加密的,也就是理论上我们通过自定义类加载器可以做到为所欲为,但是有个重要的原则下文介绍类加载器设计模式会提到。
一下给出一个自定义类加载器极简的案例,来说明自定义类加载器的实现。
package com.zooncool.example.theory.jvm;
import java.io.FileInputStream;
import static java.lang.System.out;
public class ClassIsolationPrinciple {
public static void main(String[] args) {
try {
String className = "com.zooncool.example.theory.jvm.ClassIsolationPrinciple$Demo"; //定义要加载类的全限定名
Class<?> class1 = Demo.class; //第一个类又系统默认类加载器加载
//第二个类MyClassLoader为自定义类加载器,自定义的目的是覆盖加载类的逻辑
Class<?> class2 = new MyClassLoader("target/classes").loadClass(className);
out.println("-----------------class name-----------------");
out.println(class1.getName());
out.println(class2.getName());
out.println("-----------------classLoader name-----------------");
out.println(class1.getClassLoader());
out.println(class2.getClassLoader());
Demo.example = 1;//这里修改的系统类加载器加载的那个类的对象,而自定义加载器加载进去的类的对象保持不变,也即是同时存在内存,但没有修改example的值。
out.println("-----------------field value-----------------");
out.println(class1.getDeclaredField("example").get(null));
out.println(class2.getDeclaredField("example").get(null));
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (NoSuchFieldException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
public static class Demo {
public static int example = 0;
}
public static class MyClassLoader extends ClassLoader{
private String classPath;
public MyClassLoader(String classPath) {
this.classPath = classPath;
}
//自定义类加载器继承了ClassLoader,称为一个可以加载类的加载器,同时覆盖了loadClass方法,实现自己的逻辑
@Override
public Class<?> loadClass(String name) throws ClassNotFoundException {
if(!name.contains("java.lang")){//排除掉加载系统默认需要加载的内心类,因为些类只能又默认类加载器去加载,第三方加载会抛异常,具体原因下文解释
byte[] data = new byte[0];
try {
data = loadByte(name);
} catch (Exception e) {
e.printStackTrace();
}
return defineClass(name,data,0,data.length);
}else{
return super.loadClass(name);
}
}
//把影片的二进制类文件读入内存字节流
private byte[] loadByte(String name) throws Exception {
name = name.replaceAll("//.", "/");
String dir = classPath + "/" + name + ".class";
FileInputStream fis = new FileInputStream(dir);
int len = fis.available();
byte[] data = new byte[len];
fis.read(data);
fis.close();
return data;
}
}
}
执行结果如下,我们可以看到加载到内存方法区的两个类的包名+名称是一样的,而对应的类加载器却不一样,而且输出被加载类的值也是不一样的。
-----------------class name----------------- com.zooncool.example.theory.jvm.ClassIsolationPrinciple2$Demo com.zooncool.example.theory.jvm.ClassIsolationPrinciple2$Demo -----------------classLoader name----------------- sun.misc.Launcher$AppClassLoader@18b4aac2 com.zooncool.example.theory.jvm.ClassIsolationPrinciple2$MyClassLoader@511d50c0 -----------------field value----------------- 1 0
4.2.3设计模式
现有的加载器分为内置类加载器和自定义加载器,不管它们是通过C或者JAVA实现的最终都是为了把外部的CLASS文件加载到JVM内存里面。那么我们就需要设计一套规则来管理组织内存里面的CLASS文件,下面我们就来介绍下通过这套规则如何来协调好内置类加载器和自定义类加载器之间的权责。
我们知道通过自定义类加载器可以干出很多黑科技,但是有个基本的雷区就是,不能随便替代JAVA的核心基础类,或者说即是你写了一个跟核心类一模一样的类,JVM也不会使用。你想一下,如果为所欲为的你可以把最基础本的java.lang.Object都换成你自己定义的同名类,然后搞个后门进去,而且JVM还使用的话,那谁还敢用JAVA了是吧,所以我们会介绍一个重要的原则,在此之前我们先介绍一下内置类加载器和自定义类加载器是如何协同的。
-
双亲委派机制
定义:某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父类加载器,依次递归,如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成此加载任务时,才自己去加载。
实现:参考上文loadClass方法的源码和注释,通过最多三次递归可以到启动类加载器,如果还是找不到这调用自定义方法。
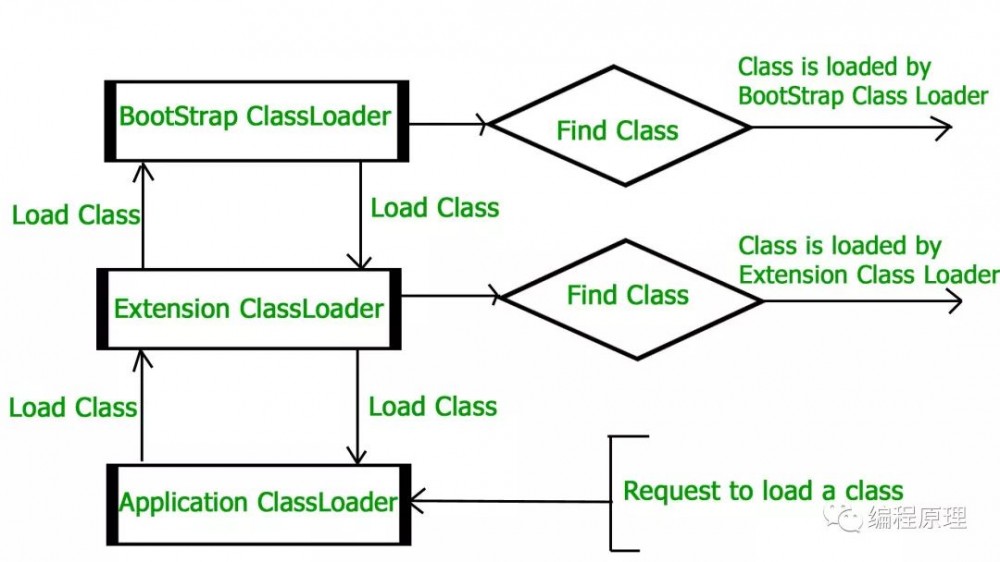
双亲委派机制很好理解,目的就是为了不重复加载已有的类,提高效率,还有就是强制从父类加载器开始逐级搜索类文件,确保核心基础类优先加载。下面介绍的是破坏双亲委派机制,了解为什么要破坏这种看似稳固的双亲委派机制。
-
破坏委派机制
定义:打破类加载自上而上委托的约束。
实现:1、继承ClassLoader并且重写loadClass方法体,覆盖依赖上层类加载器的逻辑;
2、”启动类加载器”可以指定“线程上下文类加载器”为任意类加载器,即是“父类加载器”委托“子类加载器”去加载不属于它加载范围的类文件;
说明:双亲委派机制的好处上面我们已经提过了,但是由于一些历史原因(JDK1.2加上双亲委派机制前的JDK1.1就已经存在,为了向前兼容不得不开这个后门让1.2版本的类加载器拥有1.1随意加载的功能)。还有就是JNDI的服务调用机制,例如调用JDBC需要从外部加载相关类到JVM实例的内存空间。
介绍完内置类加载器和自定义类加载器的协同关系后,我们要重点强调上文提到的重要原则。
-
唯一标识
定义:JVM实例由类加载器+类的全限定包名和类名组成类的唯一标志。
实现:加载类的时候,JVM 判断类是否来自相同的加载器,如果相同而且全限定名则直接返回内存已有的类。
说明:上文我们提到如何防止相同类的后门问题,有了这个黄金法则,即使相同的类路径和类,但是由于是由自定义类加载器加载的,即使编译通过能被加载到内存,也无法使用,因为JVM核心类是由内置类加载器加载标志和使用的,从而保证了JVM的安全加载。通过缓存类加载器和全限定包名和类名作为类唯一索引,加载重复类则抛异常提示”attempted duplicate class definition for name”。
原理:双亲委派机制父类检查缓存,源码我们介绍loadClass方法的时候已经讲过,破坏双亲委派的自定义类加载器在加载类二进制字节码后需要调用defineClass方法,而该方法同样会从JVM方法区检索缓存类,存在的话则提示重复定义。
4.2.4加载过程
至此我们已经深刻认识到类加载器的工作原理及其存在的意义,下面我们将介绍类从外部介质加载使用到卸载整个闭环的生命周期。
加载
上文花了不少的篇幅说明了类的结构和类是如何被加载到JVM内存里面的,那究竟什么时候JVM才会触发类加载器去加载外部的CLASS文件呢?通常有如下四种情况会触发到:
-
显式字节码指令集(new/getstatic/putstatic/invokestatic):对应的场景就是创建对象或者调用到类文件的静态变量/静态方法/静态代码块
-
反射:通过对象反射获取类对象时
-
继承:创建子类触发父类加载
-
入口:包含main方法的类首先被加载
JVM只定了类加载器的规范,但却不明确规定类加载器的目标文件,把加载的具体逻辑充分交给了用户,包括重硬盘加载的CLASS类到网络,中间文件等,只要加载进去内存的二进制数据流符合JVM规定的格式,都是合法的。
链接
类加载器加载完类到JVM实例的指定内存区域(方法区下文会提到)后,是使用前会经过验证,准备解析的阶段。
-
验证:主要包含对类文件对应内存二进制数据的格式、语义关联、语法逻辑和符合引用的验证,如果验证不通过则跑出VerifyError的错误。但是该阶段并非强制执行,可以通过-Xverify:none来关闭,提高性能。
-
准备:但我们验证通过时,内存的方法区存放的是被“紧密压缩”的数据段,这个时候会对static的变量进行内存分配,也就是扩展内存段的空间,为该变量匹配对应类型的内存空间,但还未初始化数据,也就是0或者null的值。
-
解析:我们知道类的数据结构类似一个数据库,里面多张不同类型的“表”紧凑的挨在一起,最大的节省类占用的空间。多数表都会应用到常量池表里面的字面量,这个时候就是把引用的字面量转化为直接的变量空间。比如某一个复杂类变量字面量在类文件里只占2个字节,但是通过常量池引用的转换为实际的变量类型,需要占用32个字节。所以经过解析阶段后,类在方法区占用的空间就会膨胀,长得更像一个”类“了。
初始化
方法区经过解析后类已经为各个变量占好坑了,初始化就是把变量的初始值和构造方法的内容初始化到变量的空间里面。这时候我们介质的类二进制文件所定义的内容,已经完全被“翻译”方法区的某一段内存空间了。万事俱备只待使用了。
使用
使用呼应了我们加载类的触发条件,也即是触发类加载的条件也是类应用的条件,该操作会在初始化完成后进行。
卸载
我们知道JVM有垃圾回收机制(下文会详细介绍),不需要我们操心,总体上有三个条件会触发垃圾回收期清理方法区的空间:
-
类对应实例被回收
-
类对应加载器被回收
-
类无反射引用
本节结束我们已经对整个类的生命周期烂熟于胸了,下面我们来介绍类加载机制最核心的几种应用场景,来加深对类加载技术的认识。
4.3应用场景
通过前文的剖析我们已经非常清楚类加载器的工作原理,那么我们该如何利用类加载器的特点,最大限度的发挥它的作用呢?
4.3.1热部署
背景
热部署这个词汇我们经常听说也经常提起,但是却很少能够准确的描述出它的定义。说到热部署我们第一时间想到的可能是生产上的机器更新代码后无需重启应用容器就能更新服务,这样的好处就是服务无需中断可持续运行,那么与之对应的冷部署当然就是要重启应用容器实例了。还有可能会想到的是使用IDE工具开发时不需要重启服务,修改代码后即时生效,这看起来可能都是服务无需重启,但背后的运行机制确截然不同,首先我们需要对热部署下一个准确的定义。
-
热部署(Hot Deployment):热部署是应用容器自动更新应用的一种能力。
首先热部署应用容器拥有的一种能力,这种能力是容器本身设计出来的,跟具体的IDE开发工具无关。而且热部署无需重启服务器,应用可以保持用户态不受影响。上文提到我们开发环境使用IDE工具通常也可以设置无需重启的功能,有别于热部署的是此时我们应用的是JVM的本身附带的热替换能力(HotSwap)。热部署和热替换是两个完全不同概念,在开发过程中也常常相互配合使用,导致我们很多人经常混淆概念,所以接下来我们来剖析热部署的实现原理,而热替换的高级特性我们会在下文字节码增强的章节中介绍。
原理
从热部署的定义我们知道它是应用容器蕴含的一项能力,要达到的目的就是在服务没有重启的情况下更新应用,也就是把新的代码编译后产生的新类文件替换掉内存里的旧类文件。结合前文我们介绍的类加载器特性,这似乎也不是很难,分两步应该可以完成。由于同一个类加载器只能加载一次类文件,那么新增一个类加载器把新的类文件加载进内存。此时内存里面同时存在新旧的两个类(类名路径一样,但是类加载器不一样),要做的就是如何使用新的类,同时卸载旧的类及其对象,完成这两步其实也就是热部署的过程了。也即是通过使用新的类加载器,重新加载应用的类,从而达到新代码热部署。
实现
理解了热部署的工作原理,下面通过一系列极简的例子来一步步实现热部署,为了方便读者演示,以下例子我尽量都在一个java文件里面完成所有功能,运行的时候复制下去就可以跑起来。
-
实现自定义类加载器
参考4.2.2中自定义类加载器区别系统默认加载器的案例,从该案例实践中我们可以将相同的类(包名+类名),不同”版本“(类加载器不一样)的类同时加载进JVM内存方法区。
-
替换自定义类加载器
既然一个类通过不同类加载器可以被多次加载到JVM内存里面,那么类的经过修改编译后再加载进内存。有别于上一步给出的例子只是修改对象的值,这次我们是直接修改类的内容,从应用的视角看其实就是应用更新,那如何做到在线程运行不中断的情况下更换新类呢?
下面给出的也是一个很简单的例子,ClassReloading启动main方法通过死循环不断创建类加载器,同时不断加载类而且执行类的方法。注意new MyClassLoader(“target/classes”)的路径更加编译的class路径来修改,其他直接复制过去就可以执行演示了。
package com.zooncool.example.theory.jvm;
import java.io.FileInputStream;
import java.lang.reflect.InvocationTargetException;
public class ClassReloading {
public static void main(String[] args)
throws NoSuchMethodException, ClassNotFoundException, IllegalAccessException, InstantiationException,
InvocationTargetException, InterruptedException {
for (;;){//用死循环让线程持续运行未中断状态
//通过反射调用目标类的入口方法
String className = "com.zooncool.example.theory.jvm.ClassReloading$User";
Class<?> target = new MyClassLoader("target/classes").loadClass(className);
//加载进来的类,通过反射调用execute方法
target.getDeclaredMethod("execute").invoke(targetClass.newInstance());
//HelloWorld.class.getDeclaredMethod("execute").invoke(HelloWorld.class.newInstance());
//如果换成系统默认类加载器的话,因为双亲委派原则,默认使用应用类加载器,而且能加载一次
//休眠是为了在删除旧类编译新类的这段时间内不执行加载动作
//不然会找不到类文件
Thread.sleep(10000);
}
}
//自定义类加载器加载的目标类
public static class User {
public void execute() throws InterruptedException {
//say();
ask();
}
public void ask(){
System.out.println("what is your name");
}
public void say(){
System.out.println("my name is lucy");
}
}
//下面是自定义类加载器,跟第一个例子一样,可略过
public static class MyClassLoader extends ClassLoader{
...
}
}
ClassReloading线程执行过程不断轮流注释say()和ask()代码,然后编译类,观察程序输出。
如下输出结果,我们可以看出每一次循环调用都新创建一个自定义类加载器,然后通过反射创建对象调用方法,在修改代码编译后,新的类就会通过反射创建对象执行新的代码业务,而主线程则一直没有中断运行。读到这里,其实我们已经基本触达了热部署的本质了,也就是实现了手动无中断部署。但是缺点就是需要我们手动编译代码,而且内存不断新增类加载器和对象,如果速度过快而且频繁更新,还可能造成堆溢出,下一个例子我们将增加一些机制来保证旧的类和对象能被垃圾收集器自动回收。
what is your name what is your name what is your name//修改代码,编译新类 my name is lucy my name is lucy what is your name//修改代码,编译新类
-
回收自定义类加载器
通常情况下类加载器会持有该加载器加载过的所有类的引用,所有如果类是经过系统默认类加载器加载的话,那就很难被垃圾收集器回收,除非符合根节点不可达原则才会被回收。
下面继续给出一个很简单的例子,我们知道ClassReloading只是不断创建新的类加载器来加载新类从而更新类的方法。下面的例子我们模拟WEB应用,更新整个应用的上下文Context。下面代码本质上跟上个例子的功能是一样的,只不过我们通过加载Model层、DAO层和Service层来模拟web应用,显得更加真实。
package com.zooncool.example.theory.jvm;
import java.io.FileInputStream;
import java.lang.reflect.InvocationTargetException;
//应用上下文热加载
public class ContextReloading {
public static void main(String[] args)
throws NoSuchMethodException, ClassNotFoundException, IllegalAccessException, InstantiationException,
InvocationTargetException, InterruptedException {
for (;;){
Object context = newContext();//创建应用上下文
invokeContext(context);//通过上下文对象context调用业务方法
Thread.sleep(5000);
}
}
//创建应用的上下文,context是整个应用的GC roots,创建完返回对象之前调用init()初始化对象
public static Object newContext()
throws ClassNotFoundException, NoSuchMethodException, IllegalAccessException, InstantiationException,
InvocationTargetException {
String className = "com.zooncool.example.theory.jvm.ContextReloading$Context";
//通过自定义类加载器加载Context类
Class<?> contextClass = new MyClassLoader("target/classes").loadClass(className);
Object context = contextClass.newInstance();//通过反射创建对象
contextClass.getDeclaredMethod("init").invoke(context);//通过反射调用初始化方法init()
return context;
}
//业务方法,调用context的业务方法showUser()
public static void invokeContext(Object context)
throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
context.getClass().getDeclaredMethod("showUser").invoke(context);
}
public static class Context{
private UserService userService = new UserService();
public String showUser(){
return userService.getUserMessage();
}
//初始化对象
public void init(){
UserDao userDao = new UserDao();
userDao.setUser(new User());
userService.setUserDao(userDao);
}
}
public static class UserService{
private UserDao userDao;
public String getUserMessage(){
return userDao.getUserName();
}
public void setUserDao(UserDao userDao) {
this.userDao = userDao;
}
}
public static class UserDao{
private User user;
public String getUserName(){
//关键操作,运行main方法后切换下面方法,编译后下一次调用生效
return user.getName();
//return user.getFullName();
}
public void setUser(User user) {
this.user = user;
}
}
public static class User{
private String name = "lucy";
private String fullName = "hank.lucy";
public String getName() {
System.out.println("my name is " + name);
return name;
}
public String getFullName() {
System.out.println("my full name is " + fullName);
return name;
}
}
//跟之前的类加载器一模一样,可以略过
public static class MyClassLoader extends ClassLoader{
...
}
}
输出结果跟上一个例子相似,可以自己运行试试。我们更新业务方法编译通过后,无需重启main方法,新的业务就能生效,而且也解决了旧类卸载的核心问题,因为context的应用对象的跟节点,context是由我们自定义类加载器所加载,由于User/Dao/Service都是依赖context,所以其类也是又自定义类加载器所加载。根据GC roots原理,在创建新的自定义类加载器之后,旧的类加载器已经没有任何引用链可访达,符合GC回收规则,将会被GC收集器回收释放内存。至此已经完成应用热部署的流程,但是细心的朋友可能会发现,我们热部署的策略是整个上下文context都替换成新的,那么用户的状态也将无法保留。而实际情况是我们只需要动态更新某些模块的功能,而不是全局。这个其实也好办,就是我们从业务上把需要热部署的由自定义类加载器加载,而持久化的类资源则由系统默认类加载器去完成。
-
自动加载类加载器
其实设计到代码设计优雅问题,基本上我们拿出设计模式23章经对号入座基本可以解决问题,毕竟这是前人经过千万实践锤炼出来的软件构建内功心法。那么针对我们热部署的场景,如果想把热部署细节封装出来,那代理模式无疑是最符合要求的,也就是咱们弄出个代理对象来面向用户,把类加载器的更替,回收,隔离等细节都放在代理对象里面完成,而对于用户来说是透明无感知的,那么终端用户体验起来就是纯粹的热部署了。至于如何实现自动热部署,方式也很简单,监听我们部署的目录,如果文件时间和大小发生变化,则判断应用需要更新,这时候就触发类加载器的创建和旧对象的回收,这个时候也可以引入观察者模式来实现。由于篇幅限制,本例子就留给读者朋友自行设计,相信也是不难完成的。
案例
上一节我们深入浅出的从自定义类加载器的开始引入,到实现多个类加载器加载同个类文件,最后完成旧类加载器和对象的回收,整个流程阐述了热部署的实现细节。那么这一节我们介绍现有实现热部署的通用解决方案,本质就是对上文原理的实现,加上性能和设计上的优化,注意本节我们应用的只是类加载器的技术,后面章节还会介绍的字节码层面的底层操作技术。
-
OSGI
OSGI(Open Service Gateway Initiative)是一套开发和部署应用程序的java框架。我们从官网可以看到OSGI其实是一套规范,好比Servlet定义了服务端对于处理来自网络请求的一套规范,比如init,service,destroy的生命周期。然后我们通过实行这套规范来实现与客户端的交互,在调用init初始化完Servlet对象后通过多线程模式使用service响应网络请求。如果从响应模式比较我们还可以了解下Webflux的规范,以上两种都是处理网络请求的方式,当然你举例说CGI也是一种处理网络请求的规范,CGI采用的是多进程方式来处理网络请求,我们暂时不对这两种规范进行优劣评价,只是说明在处理网络请求的场景下可以采用不同的规范来实现。
好了现在回到OSGi,有了上面的铺垫,相信对我们理解OSGI大有帮助。我们说OSGI首先是一种规范,既然是规范我们就要看看都规范了啥,比如Servlet也是一种规范,它规范了生命周期,规定应用容器中WEB-INF/classes目录或WEB-INF/lib目录下的jar包才会被Web容器处理。同样OSGI的实现框架对管辖的Bundle下面的目录组织和文本格式也有严格规范,更重要的是OSGI对模块化架构生命周期的管理。而模块化也不只是把系统拆分成不同的JAR包形成模块而已,真正的模块化必须将模块中类的引入/导出、隐藏、依赖、版本管理贯穿到生命周期管理中去。
定义:OSGI是脱胎于(OSGI Alliance)技术联盟由一组规范和对应子规范共同定义的JAVA动态模块化技术。实现该规范的OSGI框架(如Apache Felix)使应用程序的模块能够在本地或者网络中实现端到端的通信,目前已经发布了第7版。OSGI有很多优点诸如热部署,类隔离,高内聚,低耦合的优势,但同时也带来了性能损耗,而且基于OSGI目前的规范繁多复杂,开发门槛较高。
组成:执行环境,安全层,模块层,生命周期层,服务层,框架API
核心服务:
事件服务(Event Admin Service),
包管理服务(Package Admin Service)
日志服务(Log Service)
配置管理服务(Configuration Admin Service)
HTTP服务(HTTP Service)
用户管理服务(User Admin Service)
设备访问服务(Device Access Service)
IO连接器服务(IO Connector Service)
声明式服务(Declarative Services)
其他OSGi标准服务

本节我们讨论的核心是热部署,所以我们不打算在这里讲解全部得OSGI技术,在上文实现热部署后我们重点来剖析OSGI关于热部署的机制。至于OSGI模块化技术和java9的模块化的对比和关联,后面有时间会开个专题专门介绍模块化技术。
从类加载器技术应用的角度切入我们知道OSGI规范也是打破双亲委派机制,除了框架层面需要依赖JVM默认类加载器之外,其他Bundle(OSGI定义的模块单元)都是由各自的类加载器来加载,而OSGI框架就负责模块生命周期,模块交互这些核心功能,同时创建各个Bundle的类加载器,用于直接加载Bundle定义的jar包。由于打破双亲委派模式,Bundle类加载器不再是双亲委派模型中的树状结构,而是进一步发展为更加复杂的网状结构(因为各个Bundle之间有相互依赖关系),当收到类加载请求时,OSGi将按照下面的顺序进行类搜索:
1)将以java.*开头的类委派给父类加载器加载。
2)否则,将委派列表名单内(比如sun或者javax这类核心类的包加入白名单)的类委派给父类加载器加载。
3)否则,将Import列表中的类委派给Export这个类的Bundle的类加载器加载。
4)否则,查找当前Bundle的ClassPath,使用自己的类加载器加载。
5)否则,查找类是否在自己的Fragment Bundle(OSGI框架缓存包)中,如果在,则委派给Fragment Bundle的类加载器加载。
6)否则,查找Dynamic Import列表的Bundle,委派给对应Bundle的类加载器加载。
7)否则,类查找失败。
这一系列的类加载操作,其实跟我们上节实现的自定义类加载技术本质上是一样的,只不过实现OSGI规范的框架需要提供模块之间的注册通信组件,还有模块的生命周期管理,版本管理。OSGI也只是JVM上面运行的一个普通应用实例,只不过通过模块内聚,版本管理,服务依赖一系列的管理,实现了模块的即时更新,实现了热部署。
其他热部署解决方案多数也是利用类加载器的特点做文章,当然不止是类加载器,还会应用字节码技术,下面我们主要简单列举应用类加载器实现的热部署解决方案。
-
Groovy
Groovy兼顾动态脚本语言的功能,使用的时候无外乎也是通过GroovyClassLoader来加载脚本文件,转为JVM的类对象。那么每次更新groovy脚本就可以动态更新应用,也就达到了热部署的功能了。
Class groovyClass = classLoader.parseClass(new GroovyCodeSource(sourceFile)); GroovyObject instance = (GroovyObject)groovyClass.newInstance();//proxy
-
Clojure
-
JSP
JSP其实翻译为Servlet后也是由对应新的类加载器去加载,这跟我们上节讲的流程一模一样,所以这里就补展开讲解了。
介绍完热部署技术,可能很多同学对热部署的需求已经没有那么强烈,毕竟热部署过程中带来的弊端也不容忽视,比如替换旧的类加载器过程会产生大量的内存碎片,导致JVM进行高负荷的GC工作,反复进行热部署还会导致JVM内存不足而导致内存溢出,有时候甚至还不如直接重启应用来得更快一点,而且随着分布式架构的演进和微服务的流行,应用重启也早就实现服务编排化,配合丰富的部署策略,也可以同样保证系统稳定持续服务,我们更多的是通过热部署技术来深刻认识到JVM加载类的技术演进。
4.3.2类隔离
背景
先介绍一下类隔离的背景,我们费了那么大的劲设计出类加载器,如果只是用于加载外部类字节流那就过于浪费了。通常我们的应用依赖不同的第三方类库经常会出现不同版本的类库,如果只是使用系统内置的类加载器的话,那么一个类库只能加载唯一的一个版本,想加载其他版本的时候会从缓存里面发现已经存在而停止加载。但是我们的不同业务以来的往往是不同版本的类库,这时候就会出现ClassNotFoundException。为什么只有运行的是才会出现这个异常呢,因为编译的时候我们通常会使用MAVEN等编译工具把冲突的版本排除掉。另外一种情况是WEB容器的内核依赖的第三方类库需要跟应用依赖的第三方类库隔离开来,避免一些安全隐患,不然如果共用的话,应用升级依赖版本就会导致WEB容器不稳定。
基于以上的介绍我们知道类隔离实在是刚需,那么接下来介绍一下如何实现这个刚需。
原理
首先我们要了解一下原理,其实原理很简单,真的很简单,请允许我总结为“唯一标识原理”。我们知道内存里面定位类实例的坐标<类加载器,类全限定名>。那么由这两个因子组合起来我们可以得出一种普遍的应用,用不同类加载器来加载类相同类(类全限定名一致,版本不一致)是可以实现的,也就是在JVM看来,有相同类全名的类是完全不同的两个实例,但是在业务视角我们却可以视为相同的类。
public static void main(String[] args) {
Class<?> userClass1 = User.class;
Class<?> userClass2 = new DynamicClassLoader("target/classes")
.load("qj.blog.classreloading.example1.StaticInt$User");
out.println("Seems to be the same class:");
out.println(userClass1.getName());
out.println(userClass2.getName());
out.println();
out.println("But why there are 2 different class loaders:");
out.println(userClass1.getClassLoader());
out.println(userClass2.getClassLoader());
out.println();
User.age = 11;
out.println("And different age values:");
out.println((int) ReflectUtil.getStaticFieldValue("age", userClass1));
out.println((int) ReflectUtil.getStaticFieldValue("age", userClass2));
}
public static class User {
public static int age = 10;
}
实现
原理很简单,比如我们知道Spring容器本质就是一个生产和管理bean的集合对象,但是却包含了大量的优秀设计模式和复杂的框架实现。同理隔离容器虽然原理很简单,但是要实现一个高性能可扩展的高可用隔离容器,却不是那么简单。我们上文谈的场景是在内存运行的时候才发现问题,介绍内存隔离技术之前,我们先普及更为通用的冲突解决方法。
-
冲突排除
冲突总是先发生在编译时期,那么基本Maven工具可以帮我们完成大部分的工作,Maven的工作模式就是将我们第三方类库的所有依赖都依次检索,最终排除掉产生冲突的jar包版本。
-
冲突适配
当我们无法通过简单的排除来解决的时候,另外一个方法就是重新装配第三方类库,这里我们要介绍一个开源工具jarjar ( https://github.com/shevek/jarjar )。该工具包可以通过字节码技术将我们依赖的第三方类库重命名,同时修改代码里面对第三方类库引用的路径。这样如果出现同名第三方类库的话,通过该“硬编码”的方式修改其中一个类库,从而消除了冲突。
-
冲突隔离
上面两种方式在小型系统比较适合,也比较敏捷高效。但是对于分布式大型系统的话,通过硬编码方式来解决冲突就难以完成了。办法就是通过隔离容器,从逻辑上区分类库的作用域,从而对内存的类进行隔离。
5.内存管理
5.1内存结构
5.1.1逻辑分区
JVM内存从应用逻辑上可分为如下区域。
-
程序计数器:字节码行号指示器,每个线程需要一个程序计数器
-
虚拟机栈:方法执行时创建栈帧(存储局部变量,操作栈,动态链接,方法出口)编译时期就能确定占用空间大小,线程请求的栈深度超过jvm运行深度时抛StackOverflowError,当jvm栈无法申请到空闲内存时抛OutOfMemoryError,通过-Xss,-Xsx来配置初始内存
-
本地方法栈:执行本地方法,如操作系统native接口
-
堆:存放对象的空间,通过-Xmx,-Xms配置堆大小,当堆无法申请到内存时抛OutOfMemoryError
-
方法区:存储类数据,常量,常量池,静态变量,通过MaxPermSize参数配置
-
对象访问:初始化一个对象,其引用存放于栈帧,对象存放于堆内存,对象包含属性信息和该对象父类、接口等类型数据(该类型数据存储在方法区空间,对象拥有类型数据的地址)
而实际上JVM内存分类实际上的物理分区还有更为详细,整体上分为堆内存和非堆内存,具体介绍如下。
5.1.2 内存模型
堆内存
堆内存是运行时的数据区,从中分配所有java类实例和数组的内存,可以理解为目标应用依赖的对象。堆在JVM启动时创建,并且在应用程序运行时可能会增大或减小。可以使用-Xms 选项指定堆的大小。堆可以是固定大小或可变大小,具体取决于垃圾收集策略。可以使用-Xmx选项设置最大堆大小。默认情况下,最大堆大小设置为64 MB。
JVM堆内存在物理上分为两部分:新生代和老年代。新生代是为分配新对象而保留堆空间。当新生代占用完时,Minor GC垃圾收集器会对新生代区域执行垃圾回收动作,其中在新生代中生活了足够长的所有对象被迁移到老年代,从而释放新生代空间以进行更多的对象分配。此垃圾收集称为 Minor GC。新生代分为三个子区域:伊甸园Eden区和两个幸存区S0和S1。
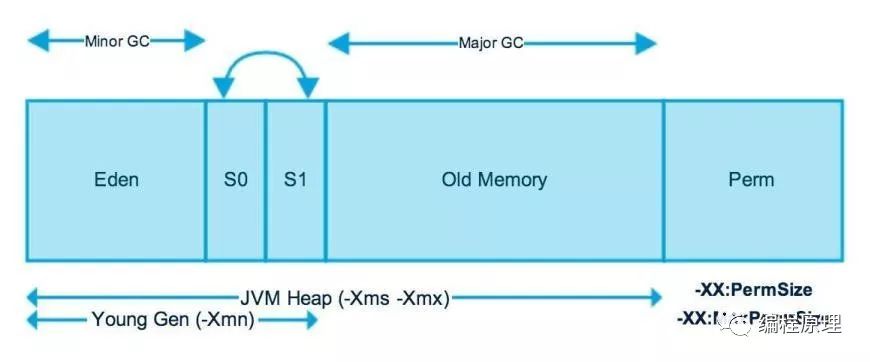
关于新生代内存空间:
-
大多数新创建的对象都位于Eden区内存空间
-
当Eden区填满对象时,执行Minor GC并将所有幸存对象移动到其中一个幸存区空间
-
Minor GC还会检查幸存区对象并将其移动到其他幸存者空间,也即是幸存区总有一个是空的
-
在多次GC后还存活的对象被移动到老年代内存空间。至于经过多少次GC晋升老年代则由参数配置,通常为15
当老年区填满时,老年区同样会执行垃圾回收,老年区还包含那些经过多Minor GC后还存活的长寿对象。垃圾收集器在老年代内存中执行的回收称为Major GC,通常需要更长的时间。
非堆内存
JVM的堆以外内存称为非堆内存。也即是JVM自身预留的内存区域,包含JVM缓存空间,类结构如常量池、字段和方法数据,方法,构造方法。类非堆内存的默认最大大小为64 MB。可以使用-XX:MaxPermSize VM选项更改此选项,非堆内存通常包含如下性质的区域空间:
-
元空间(Metaspace)
在Java 8以上版本已经没有Perm Gen这块区域了,这也意味着不会再由关于“java.lang.OutOfMemoryError:PermGen”内存问题存在了。与驻留在Java堆中的Perm Gen不同,Metaspace不是堆的一部分。类元数据多数情况下都是从本地内存中分配的。默认情况下,元空间会自动增加其大小(直接又底层操作系统提供),而Perm Gen始终具有固定的上限。可以使用两个新标志来设置Metaspace的大小,它们是:“ - XX:MetaspaceSize ”和“ -XX:MaxMetaspaceSize ”。Metaspace背后的含义是类的生命周期及其元数据与类加载器的生命周期相匹配。也就是说,只要类加载器处于活动状态,元数据就会在元数据空间中保持活动状态,并且无法释放。
-
代码缓存
运行Java程序时,它以分层方式执行代码。在第一层,它使用客户端编译器(C1编译器)来编译代码。分析数据用于服务器编译的第二层(C2编译器),以优化的方式编译该代码。默认情况下,Java 7中未启用分层编译,但在Java 8中启用了分层编译。实时(JIT)编译器将编译的代码存储在称为代码缓存的区域中。它是一个保存已编译代码的特殊堆。如果该区域的大小超过阈值,则该区域将被刷新,并且GC不会重新定位这些对象。Java 8中已经解决了一些性能问题和编译器未重新启用的问题,并且在Java 7中避免这些问题的解决方案之一是将代码缓存的大小增加到一个永远不会达到的程度。
-
方法区
方法区域是Perm Gen中空间的一部分,用于存储类结构(运行时常量和静态变量)以及方法和构造函数的代码。
-
内存池
内存池由JVM内存管理器创建,用于创建不可变对象池。内存池可以属于Heap或Perm Gen,具体取决于JVM内存管理器实现。
-
常量池
常量包含类运行时常量和静态方法,常量池是方法区域的一部分。
-
Java堆栈内存
Java堆栈内存用于执行线程。它们包含特定于方法的特定值,以及对从该方法引用的堆中其他对象的引用。
-
Java堆内存配置项
Java提供了许多内存配置项,我们可以使用它们来设置内存大小及其比例,常用的如下:
| VM Switch | 描述 |
|---|---|
| - Xms | 用于在JVM启动时设置初始堆大小 |
| -Xmx | 用于设置最大堆大小 |
| -Xmn | 设置新生区的大小,剩下的空间用于老年区 |
| -XX:PermGen | 用于设置永久区存初始大小 |
| -XX:MaxPermGen | 用于设置Perm Gen的最大尺寸 |
| -XX:SurvivorRatio | 提供Eden区域的比例 |
| -XX:NewRatio | 用于提供老年代/新生代大小的比例,默认值为2 |
5.2垃圾回收
5.2.1垃圾回收策略
流程
垃圾收集是释放堆中的空间以分配新对象的过程。垃圾收集器是JVM管理的进程,它可以查看内存中的所有对象,并找出程序任何部分未引用的对象,删除并回收空间以分配给其他对象。通常会经过如下步骤:
-
标记:标记哪些对象被使用,哪些已经是无法触达的无用对象
-
删除:删除无用对象并回收要分配给其他对象
-
压缩:性能考虑,在删除无用的对象后,会将所有幸存对象集中移动到一起,腾出整段空间
策略
虚拟机栈、本地栈和程序计数器在编译完毕后已经可以确定所需内存空间,程序执行完毕后也会自动释放所有内存空间,所以不需要进行动态回收优化。JVM内存调优主要针对堆和方法区两大区域的内存。通常对象分为Strong、sfot、weak和phantom四种类型,强引用不会被回收,软引用在内存达到溢出边界时回收,弱引用在每次回收周期时回收,虚引用专门被标记为回收对象,具体回收策略如下:
-
对象优先在Eden区分配:
-
新生对象回收策略Minor GC(频繁)
-
老年代对象回收策略Full GC/Major GC(慢)
-
大对象直接进入老年代:超过3m的对象直接进入老年区 -XX:PretenureSizeThreshold=3145728(3M)
-
长期存货对象进入老年区:
Survivor区中的对象经历一次Minor GC年龄增加一岁,超过15岁进入老年区
-XX:MaxTenuringThreshold=15
-
动态对象年龄判定:设置Survivor区对象占用一半空间以上的对象进入老年区
算法
垃圾收集有如下常用的算法:
-
标记-清除
-
复制
-
标记-整理
-
分代收集(新生用复制,老年用标记-整理)
5.2.2 垃圾回收器
分类
-
serial收集器:单线程,主要用于client模式
-
ParNew收集器:多线程版的serial,主要用于server模式
-
Parallel Scavenge收集器:线程可控吞吐量(用户代码时间/用户代码时间+垃圾收集时间),自动调节吞吐量,用户新生代内存区
-
Serial Old收集器:老年版本serial
-
Parallel Old收集器:老年版本Parallel Scavenge
-
CMS(Concurrent Mark Sweep)收集器:停顿时间短,并发收集
-
G1收集器:分块标记整理,不产生碎片
配置
-
串行GC(-XX:+ UseSerialGC):串行GC使用简单的标记-扫描-整理方法,用于新生代和老年代的垃圾收集,即Minor和Major GC
-
并行GC(-XX:+ UseParallelGC):并行GC与串行GC相同,不同之处在于它为新生代垃圾收集生成N个线程,其中N是系统中的CPU核心数。我们可以使用-XX:ParallelGCThreads = n JVM选项来控制线程数
-
并行旧GC(-XX:+ UseParallelOldGC):这与Parallel GC相同,只是它为新生代和老年代垃圾收集使用多个线程
-
并发标记扫描(CMS)收集器(-XX:+ UseConcMarkSweepGC):CMS也称为并发低暂停收集器。它为老年代做垃圾收集。CMS收集器尝试通过在应用程序线程内同时执行大多数垃圾收集工作来最小化由于垃圾收集而导致的暂停。年轻一代的CMS收集器使用与并行收集器相同的算法。我们可以使用-XX限制CMS收集器中的线程数 :ParallelCMSThreads = n
-
G1垃圾收集器(-XX:+ UseG1GC):G1从长远看要是替换CMS收集器。G1收集器是并行,并发和递增紧凑的低暂停垃圾收集器。G1收集器不像其他收集器那样工作,并且没有年轻和老一代空间的概念。它将堆空间划分为多个大小相等的堆区域。当调用垃圾收集器时,它首先收集具有较少实时数据的区域,因此称为“Garbage First”也即是G1
6.执行引擎
6.1执行流程
类加载器加载的类文件字节码数据流由基于JVM指令集架构的执行引擎来执行。执行引擎以指令为单位读取Java字节码。我们知道汇编执行的流程是CPU执行每一行的汇编指令,同样JVM执行引擎就像CPU一个接一个地执行机器命令。字节码的每个命令都包含一个1字节的OpCode和附加的操作数。执行引擎获取一个OpCode并使用操作数执行任务,然后执行下一个OpCode。但Java是用人们可以理解的语言编写的,而不是用机器直接执行的语言编写的。因此执行引擎必须将字节码更改为JVM中的机器可以执行的语言。字节码可以通过以下两种方式之一转化为合适的语言。
-
解释器:逐个读取,解释和执行字节码指令。当它逐个解释和执行指令时,它可以快速解释一个字节码,但是同时也只能相对缓慢的地执行解释结果,这是解释语言的缺点。
-
JIT(实时)编译器:引入了JIT编译器来弥补解释器的缺点。执行引擎首先作为解释器运行,并在适当的时候,JIT编译器编译整个字节码以将其更改为本机代码。之后,执行引擎不再解释该方法,而是直接使用本机代码执行。本地代码中的执行比逐个解释指令要快得多。由于本机代码存储在高速缓存中,因此可以快速执行编译的代码。
但是,JIT编译器编译代码需要花费更多的时间,而不是解释器逐个解释代码。因此,如果代码只执行一次,最好是选择解释而不是编译。因此,使用JIT编译器的JVM在内部检查方法执行的频率,并仅在频率高于某个级别时编译方法。
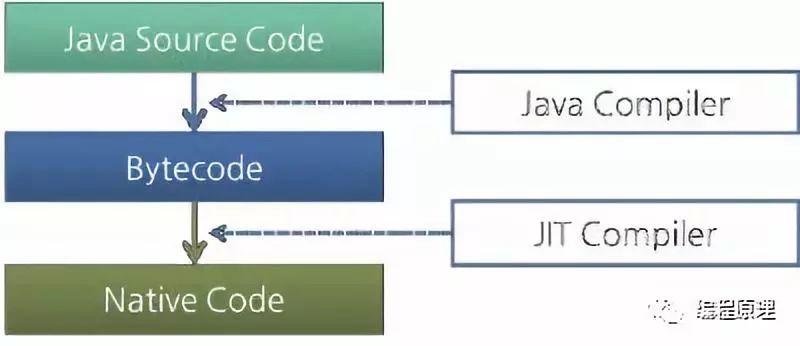
JVM规范中未定义执行引擎的运行方式。因此,JVM厂商使用各种技术改进其执行引擎,并引入各种类型的JIT编译器。 大多数JIT编译器运行如下图所示:
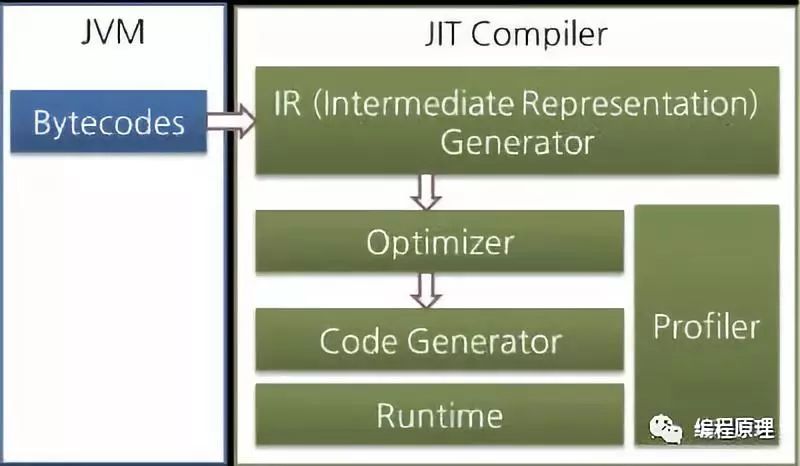
JIT编译器将字节码转换为中间级表达式IR,以执行优化,然后将表达式转换为本机代码。Oracle Hotspot VM使用名为Hotspot Compiler的JIT编译器。它被称为Hotspot,因为Hotspot Compiler通过分析搜索需要以最高优先级进行编译的“Hotspot”,然后将热点编译为本机代码。如果不再频繁调用编译了字节码的方法,换句话说,如果该方法不再是热点,则Hotspot VM将从缓存中删除本机代码并以解释器模式运行。Hotspot VM分为服务器VM和客户端VM,两个VM使用不同的JIT编译器。
大多数Java性能改进都是通过改进执行引擎来实现的。除了JIT编译器之外,还引入了各种优化技术,因此可以不断改进JVM性能。初始JVM和最新JVM之间的最大区别是执行引擎。
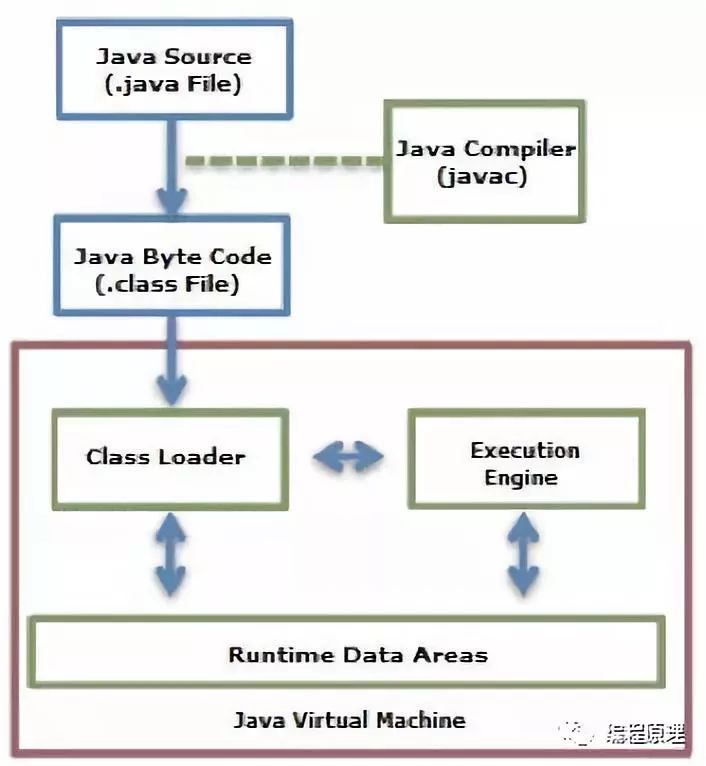
下面我们通过下图可以看出JAVA执行的流程。
6.2栈帧结构
每个方法调用开始到执行完成的过程,对应这一个栈帧在虚拟机栈里面从入栈到出栈的过程。
-
栈帧包含:局部变量表,操作数栈,动态连接,方法返回
-
方法调用:方法调用不等于方法执行,而且确定调用方法的版本。
-
方法调用字节码指令:invokestatic,invokespecial,invokevirtual,invokeinterface
-
静态分派:静态类型,实际类型,编译器重载时通过参数的静态类型来确定方法的版本。(选方法)
-
动态分派:invokevirtual指令把类方法符号引用解析到不同直接引用上,来确定栈顶的实际对象(选对象)
-
单分派:静态多分派,相同指令有多个方法版本。
-
多分派:动态单分派,方法接受者只能确定唯一一个。
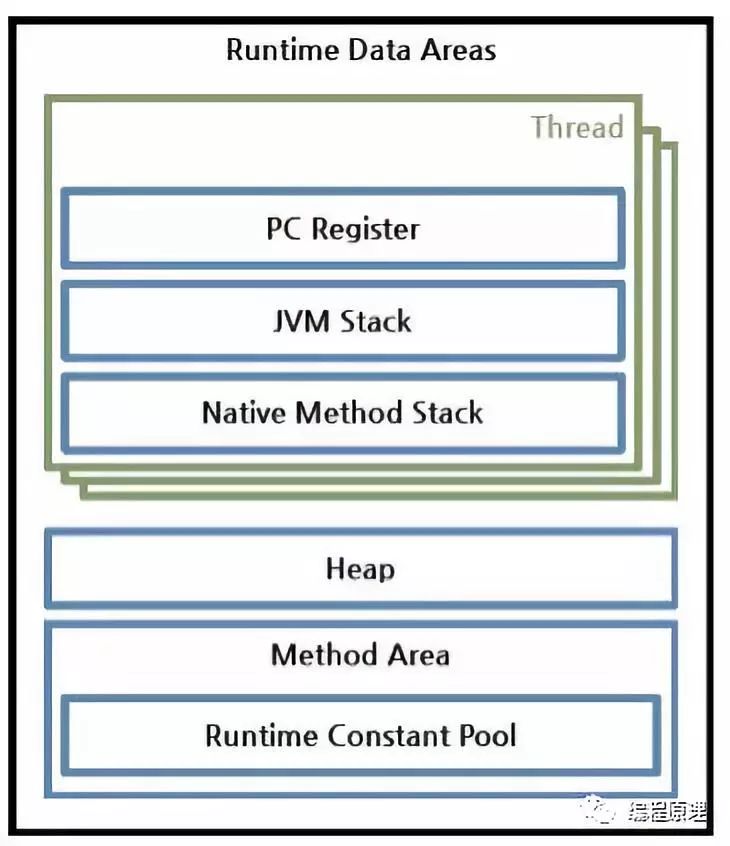
下图是JVM实例执行方法是的内存布局。
6.3早期编译
-
javac编译器:解析与符号表填充,注解处理,生成字节码
-
java语法糖:语法糖有助于代码开发,但是编译后就会解开糖衣,还原到基础语法的class二进制文件
重载要求方法具备不同的特征签名(不包括返回值),但是class文件中,只要描述不是完全一致的方法就可以共存。
6.4晚期编译
HotSpot虚拟机内的即时编译
解析模式 -Xint
编译模式 -Xcomp
混合模式 Mixed mode
分层编译:解释执行 -> C1(Client Compiler)编译 -> C2编译(Server Compiler)
触发条件:基于采样的热点探测,基于计数器的热点探测
7.性能调优
7.1调优原则
我们知道调优的前提是,程序没有达到我们的预期要求,那么第一步要做的是衡量我们的预期。程序不可能十全十美,我们要做的是通过各种指标来衡量系统的性能,最终整体达到我们的要求。
7.1.1 环境
首先我们要了解系统的运行环境,包括操作系统层面的差异,JVM版本,位数,乃至于硬件的时钟周期,总线设计甚至机房温度,都可能是我们需要考虑的前置条件。
7.1.2 度量
首先我们要先给出系统的预期指标,在特定的硬件/软件的配置,然后给出目标指标,比如系统整体输出接口的QPS,RT,或者更进一层,IO读写,cpu的load指标,内存的使用率,GC情况都是我们需要预先考察的对象。
7.1.3 监测
确定了环境前置条件,分析了度量指标,第三步是通过工具来监测指标,下一节提供了常用JVM调优工具,可以通过不同工具的组合来发现定位问题,结合JVM的工作机制已经操作系统层面的调度流程,按图索骥来发现问题,找出问题后才能进行优化。
7.1.4 原则
总体的调优原则如下图

图片来源《Java Performance》
7.2 调优参数
上节给出了JVM性能调优的原则,我们理清思路后应用不同的JVM工具来发现系统存在的问题,下面列举的是常用的JVM参数,通过这些参数指标可以更快的帮助我们定位出问题所在。
7.2.1内存查询
最常见的与性能相关的做法之一是根据应用程序要求初始化堆内存。这就是我们应该指定最小和最大堆大小的原因。以下参数可用于实现它:
-Xms<heap size>[unit] -Xmx<heap size>[unit]
unit表示要初始化内存(由 堆大小 表示)的单元。单位可以标记为GB的 “g” ,MB的 “m” 和KB的 “k” 。例如JVM分配最小2 GB和最大5 GB:
-Xms2G -Xmx5G
从Java 8开始Metaspace的大小未被定义,一旦达到限制JVM会自动增加它,为了避免不必要的不稳定性,我们可以设置 Metaspace 大小:
-XX:MaxMetaspaceSize=<metaspace size>[unit]
默认情况下YG的最小大小为1310 MB ,最大大小不受限制,我们可以明确地指定它们:
-XX:NewSize=<young size>[unit] -XX:MaxNewSize=<young size>[unit]
7.2.2垃圾回收
JVM有四种类型的 GC 实现:
-
串行垃圾收集器
-
并行垃圾收集器
-
CMS垃圾收集器
-
G1垃圾收集器
可以使用以下参数声明这些实现:
-XX:+UseSerialGC -XX:+UseParallelGC -XX:+USeParNewGC -XX:+UseG1GC
7.2.3GC记录
要严格监视应用程序运行状况,我们应始终检查JVM的垃圾收集性能,使用以下参数,我们可以记录 GC 活动:
-XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=< number of log files > -XX:GCLogFileSize=< file size >[ unit ] -Xloggc:/path/to/gc.log
UseGCLogFileRotation指定日志文件滚动的政策,就像log4j的,s4lj等 NumberOfGCLogFiles 表示单个应用程序记录生命周期日志文件的最大数量。 GCLogFileSize 指定文件的最大大小。 loggc 表示其位置。这里要注意的是,还有两个可用的JVM参数( -XX:+ PrintGCTimeStamps 和 -XX:+ PrintGCDateStamps ),可用于在 GC 日志中打印日期时间戳。
7.2.4内存溢出
大型应用程序面临内存不足的错误是很常见的,这是一个非常关键的场景,很难复制以解决问题。
这就是JVM带有一些参数的原因,这些参数将堆内存转储到一个物理文件中,以后可以用它来查找泄漏:
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./java_pid<pid>.hprof -XX:OnOutOfMemoryError="< cmd args >;< cmd args >" -XX:+UseGCOverheadLimit
这里有几点需要注意:
-
在OutOfMemoryError的情况下, HeapDumpOnOutOfMemoryError 指示JVM将堆转储到物理文件中
-
HeapDumpPath表示要写入文件的路径; 任何文件名都可以给出; 但是如果JVM在名称中找到 标记,则导致内存不足错误的进程ID将以 .hprof 格式附加到文件名
-
OnOutOfMemoryError 用于发出紧急命令,以便在出现内存不足错误时执行; 应该在cmd args的空间中使用正确的命令。例如,如果我们想在内存不足时重新启动服务器,我们可以设置参数:
-XX:OnOutOfMemoryError="shutdown -r"
-
UseGCOverheadLimit是一种策略,用于限制在抛出 OutOfMemory 错误之前在GC中花费的VM时间的比例
7.2.5其他配置
-
-server :启用“Server Hotspot VM”; 默认情况下,此参数在64位JVM中使用
-
-XX:+ UseStringDeduplication : Java 8引入了这个JVM参数,通过创建相同 String的 太多实例来减少不必要的内存使用 ; 这通过将重复的 String 值减少到单个全局char []数组来优化堆内存
-
-XX:+ UseLWPSynchronization :设置基于 LWP ( 轻量级进程 )的同步策略而不是基于线程的同步
-
-XX:LargePageSizeInBytes:设置用于Java堆的大页面大小; 它采用GB / MB / KB的参数; 通过更大的页面大小,我们可以更好地利用虚拟内存硬件资源; 但是这可能会导致 PermGen的 空间大小增加,从而可以强制减小Java堆空间的大小
-
-XX:MaxHeapFreeRatio :设置 GC 后堆的最大自由百分比,以避免收缩
-
-XX:MinHeapFreeRatio :设置 GC 后堆的最小自由百分比以避免扩展,监视堆使用情况
-
-XX:SurvivorRatio :Eden区 /幸存者空间大小的比例
-
-XX:+ UseLargePages :如果系统支持,则使用大页面内存; 如果使用此JVM参数,OpenJDK 7往往会崩溃
-
-XX:+ UseStringCache:启用 字符串 池中可用的常用分配字符串的缓存
-
-XX:+ UseCompressedStrings :对 String 对象使用 byte [] 类型,可以用纯ASCII格式表示
-
-XX:+ OptimizeStringConcat:它尽可能优化 字符串 连接操作
7.3 调优工具
7.3.1命令行工具
-
虚拟机进程状况工具:jps -lvm
-
诊断命令工具:jcmd
用来发送诊断命令请求到JVM,这些请求是控制Java的运行记录,它必须在运行JVM的同一台机器上使用,并且具有用于启动JVM的相同有效用户和分组,可以使用以下命令创建堆转储(hprof转储):
jcmd
GC.heap_dump filename = -
虚拟机统计信息监视工具:jstat
提供有关运行的应用程序的性能和资源消耗的信息。在诊断性能问题时,可以使用该工具,特别是与堆大小调整和垃圾回收相关的问题。jstat不需要虚拟机启动任何特殊配置。
jstat -gc pid interval count
-
java配置信息工具:jinfo
jinfo -flag pid
-
java内存映像工具:jmap
用于生成堆转储文件
jmap -dump:format=b,file=java.bin pid
-
虚拟机堆转储快照分析工具:jhat
jhat file 分析堆转储文件,通过浏览器访问分析文件
-
java堆栈跟踪工具:jstack
用于生成虚拟机当前时刻的线程快照threaddump或者Javacore
jstack [ option ] vmid
-
堆和CPU分析工具:HPROF
HPROF是每个JDK版本附带的堆和CPU分析工具。它是一个动态链接库(DLL),它使用Java虚拟机工具接口(JVMTI)与JVM连接。该工具将分析信息以ASCII或二进制格式写入文件或套接字。HPROF工具能够显示CPU使用情况,堆分配统计信息和监视争用配置文件。此外,它还可以报告JVM中所有监视器和线程的完整堆转储和状态。在诊断问题方面,HPROF在分析性能,锁争用,内存泄漏和其他问题时非常有用。
java -agentlib:hprof = heap = sites target.class
7.3.2可视化工具
-
jconsole
-
jvisualvm
8.字节增强
我们从类加载的应用介绍了热部署和类隔离两大应用场景,但是基于类加载器的技术始终只是独立于JVM内核功能而存在的,也就是所有实现都只是基于最基础的类加载机制,并无应用其他JVM 高级特性,本章节我们开始从字节增强的层面介绍JVM的一些高级特性。
说到字节增强我们最先想到的是字节码,也就是本文最开头所要研究的class文件,任何合法的源码编译成class后被类加载器加载进JVM的方法区,也就是以字节码的形态存活在JVM的内存空间。这也就是我们为什么现有讲明白类的结构和加载过程,而字节码增强技术不只是在内存里面对class的字节码进行操纵,更为复杂的是class联动的上下游对象生命周期的管理。
首先我们回忆一下我们开发过程中最为熟悉的一个场景就是本地debug调试代码。可能很多同学都已经习惯在IDE上对某句代码打上断点,然后逐步往下追踪代码执行的步骤。我们进一步想想,这个是怎么实现的,是一股什么样的力量能把已经跑起来的线程踩下刹车,一步一步往前挪?我们知道线程运行其实就是在JVM的栈空间上不断的把代码对应的JVM指令集不断的送到CPU执行。那能阻止这个流程的力量也肯定是发生在JVM范围内,所以我们可以很轻松的预测到这肯定是JVM提供的机制,而不是IDE真的有这样的能力,只不过是JVM把这种能力封装成接口暴露出去,然后提供给IDE调用,而IDE只不过是通过界面交互来调用这些接口而已。那么下面我们就来介绍JVM这种重要的能力。
8.1JPDA
上面所讲的JVM提供的程序运行断点能力,其实JVM提供的一个工具箱JVMTI(JVM TOOL Interface)提供的接口,而这个工具箱是一套叫做JPDA的架构定义的,本节我们就来聊聊JPDA。
JPDA(Java Platform Debugger Architecture)Java平台调试架构,既不是一个应用程序,也不是调试工具,而是定义了一系列设计良好的接口和协议用于调试java代码,我们将会从三个层面来讲解JPDA。
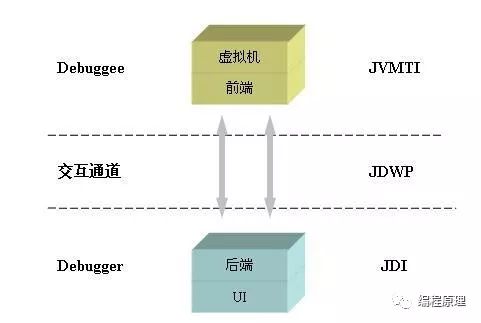
8.1.1概念
-
JVMTI
JVMTI(Java Virtual Machine Tool Interface)Java 虚拟机调试接口,处于最底层,是我们上文所提到的JVM开放的能力,JPDA规定了JDK必须提供一个叫做JVMTI(Java6之前是由JVMPI和JVMDI组成,Java6开始废弃掉统一为JVMTI)的工具箱,也就是定义了一系列接口能力,比如获取栈帧、设置断点、断点响应等接口,具体开放的能力参考JVMDI官方API文档。
-
JDWP
JDWP(Java Debug Wire Protocol)Java 调试连线协议,存在在中间层,定义信息格式,定义调试者和被调试程序之间请求的协议转换,位于JDI下一层,JDI更为抽象,JDWP则关注实现。也就是说JVM定义好提供的能力,但是如何调用JVM提供的接口也是需要规范的,就比如我们Servlet容器也接收正确合法的HTTP请求就可以成功调用接口。JPDA同样也规范了调用JVMTI接口需要传入数据的规范,也就是请求包的格式,类别HTTP的数据包格式。但是JPDA并不关心请求来源,也就是说只要调用JVMTI的请求方式和数据格式对了就可以,不论是来做远程调用还是本地调用。JDWP制定了调试者和被调试应用的字节流动机制,但没有限定具体实现,可以是远程的socket连接,或者本机的共享内存,当然还有自定义实现的通信协议。既然只是规范了调用协议,并不局限请求来源,而且也没限制语言限制,所以非java语言只要发起调用符合规范就可以,这个大大丰富了异构应用场景,具体的协议细节可以参考JDWP官方规范文档。
-
JDI
JDI(Java Debug Interface)Java调试接口处在最上层,基于Java开发的调试接口,也就是我们调试客户端,客户端代码封装在jdk下面tools.jar的com.sun.jdi包里面,java程序可以直接调用的接口集合,具体提供的功能可以参考JDI官方API文档。
8.1.2原理
介绍完JPDA的架构体系后,我们了解到JAVA调试平台各个层级的作用,这一节我们更近一步讲解JPDA各个层面的工作原理,以及三个层级结合起来时如何交互的。
JVMTI
我们JVMTI是JVM提供的一套本地接口,包含了非常丰富的功能,我们调试和优化代码需要操作JVM,多数情况下就是调用到JVMTI,从官网我们可以看到,JVMTI包含了对JVM线程/内存/堆/栈/类/方法/变量/事件/定时器处理等的20多项功能。但其实我们通常不是直接调用JVMTI,而是创建一个代理客户端,我们可以自由的定义对JVMTI的操作然后打包到代理客户端里面如libagent.so。当目标程序执行时会启动JVM,这个时候在目标程序运行前会加载代理客户端,所以代理客户端是跟目标程序运行在同一个进程上。这样一来外部请求就通过代理客户端间接调用到JVMTI,这样的好处是我们可以在客户端Agent里面定制高级功能,而且代理客户端编译打包成一个动态链接库之后可以复用,提高效率。我们简单描述一下代理客户端Agent的工作流程。
建立代理客户端首先需要定义Agent的入口函数,犹如Java类的main方法一样:
JNIEXPORT jint JNICALL Agent_OnLoad(JavaVM *vm, char *options, void *reserved);
然后JVM在启动的时候就会把JVMTI的指针JavaVM传给代理的入口函数,options则是传参,有了这个指针后代理就可以充分调用JVMTI的函数了。
//设置断点,参数是调试目标方法和行数位置 jvmtiError SetBreakpoint(jvmtiEnv* env,jmethodID method,jlocation location); //当目标程序执行到指定断点,目标线程则被挂起 jvmtiError SuspendThread(jvmtiEnv* env,jthread thread);
当然除了JVM启动时可以加载代理,运行过程中也是可以的,这个下文我们讲字节码增强还会再说到。
JNIEXPORT jint JNICALL Agent_OnAttach(JavaVM* vm, char *options, void *reserved);
有兴趣的同学可以自己动手写一个Agent试试,通过调用JVMTI接口可以实现自己定制化的调试工具。
JDWP
上文我们知道调用JVMTI需要建立一个代理客户端,但是假如我建立了包含通用功能的Agent想开发出去给所有调试器使用,有一种方式是资深开发者通过阅读我的文档后进行开发调用,还有另外一种方式就是我在我的Agent里面加入了JDWP协议模块,这样调试器就可以不用关心我的接口细节,只需按照阅读的协议发起请求即可。JDWP是调试器和JVM中间的协议规范,类似HTTP协议一样,JDWP也定义规范了握手协议和报文格式。
调试器发起请求的握手流程:
1)调试器发送一段包含“JDWP-Handshake”的14个bytes的字符串
2)JVM回复同样的内容“JDWP-Handshake”
完成握手流程后就可以像HTTP一样向JVM的代理客户端发送请求数据,同时回复所需参数。请求和回复的数据帧也有严格的结构,请求的数据格式为Command Packet,回复的格式为Reply Packet,包含包头和数据两部分,具体格式参考官网。实际上JDWP却是也是通过建立代理客户端来实现报文格式的规范,也就是JDWP Agent 里面的JDWPTI实现了JDWP对协议的定义。JDWP的功能是由JDWP传输接口(Java Debug Wire Protocol Transport Interface)实现的,具体流程其实跟JVMTI差不多,也是讲JDWPTI编译打包成代理库后,在JVM启动的时候加载到目标进程。那么调试器调用的过程就是JDWP Agent接收到请求后,调用JVMTI Agent,JDWP负责定义好报文数据,而JDWPTI则是具体的执行命令和响应事件。
JDI
前面已经解释了JVMTI和JDWP的工作原理和交互机制,剩下的就是搞清楚面向用户的JDI是如何运行的。首先JDI位于JPDA的最顶层入口,它的实现是通过JAVA语言编写的,所以可以理解为Java调试客户端对JDI接口的封装调用,比如我们熟悉的IDE界面启动调试,或者JAVA的命令行调试客户端JDB。
通常我们设置好目标程序的断点之后启动程序,然后通过调试器启动程序之前,调试器会先获取JVM管理器,然后通过JVM管理器对象virtualMachineManager获取连接器Connector,调试器与虚拟机获得链接后就可以启动目标程序了。如下代码:
VirtualMachineManager virtualMachineManager = Bootstrap.virtualMachineManager();
JDI完成调试需要实现的功能有三个模块:数据、链接、事件
-
数据
调试器要调试的程序在目标JVM上,那么调试之前肯定需要将目标程序的执行环境同步过来,不然我们压根就不知道要调试什么,所以需要一种镜像机制,把目标程序的堆栈方法区包含的数据以及接收到的事件请求都映射到调试器上面。那么JDI的底层接口Mirror就是干这样的事,具体数据结构可以查询文档。
-
链接
我们知道调试器跟目标JVM直接的通讯是双向的,所以链接双方都可以发起。一个调试器可以链接多个目标JVM,但是一个目标虚拟机只能提供给一个调试器,不然就乱套了不知道听谁指令了。JDI定义三种链接器:启动链接器(LaunchingConnector)、依附链接器(AttachingConnector)、监听链接器(ListeningConnector)和。分别对应的场景是目标程序JVM启动时发起链接、调试器中途请求接入目标程序JVM和调试器监听到被调试程序返回请求时发起的链接。
-
事件
也就是调试过程中对目标JVM返回请求的响应。
讲解完JPDA体系的实现原理,我们再次梳理一下调试的整个流程:
调试器 —> JDI客户端 —> JDWP Agent—> JVMTI Agent —>> JVMTI —> Application
8.1.3 实现
现在我们已经对整个JPDA结构有了深入理解,接下来我们就通过对这些朴素的原理来实现程序的断点调试。当然我们不会在这里介绍从IDE的UI断点调试的过程,因为对这套是使用已经非常熟悉了,我们知道IDE的UI断点调试本质上是调试器客户端对JDI的调用,那我们就通过一个调试的案例来解释一下这背后的原理。
搭建服务
首先我们需要先搭建一个可供调试的web服务,这里我首选springboot+来搭建,通过官网生成样例project或者maven插件都可以,具体的太基础的就不在这里演示,该服务只提供一个Controller包含的一个简单方法。如果使用Tomcat部署,则可以通过自有的开关catalina jpda start来启动debug模式。
package com.zooncool.debug.rest;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController("/debug")
public class DebugController {
@GetMapping
public String ask(@RequestParam("name") String name) {
String message = "are you ok?" + name;
return message;
}
}
启动服务
搭建好服务之后我们先启动服务,我们通过maven来启动服务,其中涉及到的一些参数下面解释。
mvn spring-boot:run -Drun.jvmArguments="-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8001" 或者 mvn spring-boot:run -Drun.jvmArguments="-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=8001"
-
mvn:maven的脚本命令这个不用解释
-
Spring-boot:run:启动springboot工程
-
-Drun.jvmArguments:执行jvm环境的参数,里面的参数值才是关键
-
-Xdebug
Xdebug开启调试模式,为非标准参数,也就是可能在其他JVM上面是不可用的,Java5之后提供了标准的执行参数agentlib,下面两种参数同样可以开启debug模式,但是在JIT方面有所差异,这里先不展开。
java -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8001
java -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=8001
-
Xrunjdwp/jdwp=transport:表示连接模式是本地内存共享还是远程socket连接
-
server:y表示打开socket监听调试器的请求;n表示被调试程序像客户端一样主动连接调试器
-
suspend:y表示被调试程序需要等到调试器的连接请求之后才能启动运行,在此之前都是挂起的,n表示被调试程序无需等待直接运行。
-
address:被调试程序启动debug模式后监听请求的地址和端口,地址缺省为本地。
执行完上述命令后,就等着我们调试器的请求接入到目标程序了。
调试接入
我们知道java的调试器客户端为jdb,下面我们就使用jdb来接入我们的目标程序。
#jdb 通过attach参数选择本地目标程序,同时附上目标程序的源码,回想之前我们讲到的JDI的镜像接口,就是把目标程序的堆栈结构同步过来,如果能我们提供的源码对应上,那就可以在源码上面显示断点标志
$ jdb -attach localhost:8001 -sourcepath /Users/linzhenhua/Documents/repositories/practice/stackify-master/remote-debugging/src/main/java/
设置未捕获的java.lang.Throwable
设置延迟的未捕获的java.lang.Throwable
正在初始化jdb...
#stop,选择对应方法设置断点
> stop in com.zooncool.debug.rest.DebugController.ask(java.lang.String)
设置断点com.zooncool.debug.rest.DebugController.ask(java.lang.String)
#如果我们设置不存在的方法为断点,则会有错误提示
> stop in com.zooncool.debug.rest.DebugController.ask2(java.lang.String)
无法设置断点com.zooncool.debug.rest.DebugController.ask2(java.lang.String): com.zooncool.debug.rest.DebugController中没有方法ask2
#这时候我们已经设置完断点,就可以发起个HTTP请求
#http://localhost:7001/remote-debugging/debug/ask?name=Jack
#发起请求后我们回到jdb控制台,观察是否命中断点
> 断点命中: "线程=http-nio-7001-exec-5", com.zooncool.debug.rest.DebugController.ask(), 行=14 bci=0
14 String message = "are you ok?" + name;
#list,对照源码,确实是进入ask方法第一行命中断点,也就是14行,这时候我们可以查看源码
http-nio-7001-exec-5[1] list
10 @RestController("/debug")
11 public class DebugController {
12 @GetMapping
13 public String ask(@RequestParam("name") String name) {
14 => String message = "are you ok?" + name;
15 return message;
16 }
17 }
#locals,观察完源码,我们想获取name的传参,跟URL传入的一致
http-nio-7001-exec-5[1] locals
方法参数:
name = "Jack"
本地变量:
#print name,打印入参
http-nio-7001-exec-5[1] print name
name = "Jack"
#where,查询方法调用的栈帧,从web容器入口调用方法到目标方法的调用链路
http-nio-7001-exec-5[1] where
[1] com.zooncool.debug.rest.DebugController.ask (DebugController.java:14)
...
[55] java.lang.Thread.run (Thread.java:748)
#step,下一步到下一行代码
http-nio-7001-exec-5[1] step
> 已完成的步骤: "线程=http-nio-7001-exec-5", com.zooncool.debug.rest.DebugController.ask(), 行=15 bci=20
15 return message;
#step up,完成当前方法的调用
http-nio-7001-exec-5[1] step up
> 已完成的步骤: "线程=http-nio-7001-exec-5", sun.reflect.NativeMethodAccessorImpl.invoke(), 行=62 bci=103
#cont,结束调试,执行完毕
http-nio-7001-exec-5[1] cont
>
#clear,完成调试任务,清除断点
> clear
断点集:
断点com.zooncool.debug.rest.DebugController.ask(java.lang.String)
断点com.zooncool.debug.rest.DebugController.ask2(java.lang.String)
#选择一个断点删除
> clear com.zooncool.debug.rest.DebugController.ask(java.lang.String)
已删除: 断点com.zooncool.debug.rest.DebugController.ask(java.lang.String)
我们已经完成了命令行调试的全部流程,stop/list/locals/print name/where/step/step up/cont/clear这些命令其实就是IDE的UI后台调用的脚本。而这些脚本就是基于JDI层面的接口所提供的能力,下面我们还有重点观察一个核心功能,先从头再设置一下断点。
#stop,选择对应方法设置断点 > stop in com.zooncool.debug.rest.DebugController.ask(java.lang.String) 设置断点com.zooncool.debug.rest.DebugController.ask(java.lang.String) #这时候我们已经设置完断点,就可以发起个HTTP请求 #http://localhost:7001/remote-debugging/debug/ask?name=Jack #发起请求后我们回到jdb控制台,观察是否命中断点 > 断点命中: "线程=http-nio-7001-exec-5", com.zooncool.debug.rest.DebugController.ask(), 行=14 bci=0 14 String message = "are you ok?" + name; #print name,打印入参 http-nio-7001-exec-5[1] print name name = "Jack" #如果这个时候我们想替换掉Jack,换成Lucy http-nio-7001-exec-6[1] set name = "Lucy" name = "Lucy" = "Lucy" #进入下一步 http-nio-7001-exec-6[1] step > 已完成的步骤: "线程=http-nio-7001-exec-6", com.zooncool.debug.rest.DebugController.ask(), 行=15 bci=20 15 return message; #查看变量,我们发现name的值已经被修改了 http-nio-7001-exec-6[1] locals 方法参数: name = "Lucy" 本地变量: message = "are you ok?Lucy"
至此我们已经完成了JPDA的原理解析到调试实践,也理解了JAVA调试的工作机制,其中留下一个重要的彩蛋就是通过JPDA进入调试模式,我们可以动态的修改JVM内存对象和类的内容,这也讲引出下文我们要介绍的字节码增强技术。
8.2 热替换
8.2.1概念
终于来到热替换这节了,前文我们做了好多铺垫,介绍热替换之前我们稍稍回顾一下热部署。我们知道热部署是“独立”于JVM之外的一门对类加载器应用的技术,通常是应用容器借助自定义类加载器的迭代,无需重启JVM缺能更新代码从而达到热部署,也就是说热部署是JVM之外容器提供的一种能力。而本节我们介绍的热替换技术是实打实JVM提供的能力,是JVM提供的一种能够实时更新内存类结构的一种能力,这种实时更新JVM方法区类结构的能力当然也是无需重启JVM实例。
热替换HotSwap是Sun公司在Java 1.4版本引入的一种新实验性技术,也就是上一节我们介绍JPDA提到的调试模式下可以动态替换类结构的彩蛋,这个功能被集成到JPDA框架的接口集合里面,首先我们定义好热替换的概念。
热替换(HotSwap):使用字节码增强技术替换JVM内存里面类的结构,包括对应类的对象,而不需要重启虚拟机。
8.2.2原理
前文从宏观上介绍了JVM实例的内存布局和垃圾回收机制,微观上也解释了类的结构和类加载机制,上一节又学习了JAVA的调试框架,基本上我们对JVM的核心模块都已经摸透了,剩下的就是攻克字节码增强的技术了。而之前讲的字节码增强技术也仅仅是放在JPDA里面作为实验性技术,而且仅仅局限在方法体和变量的修改,无法动态修改方法签名或者增删方法,因为字节码增强涉及到垃圾回收机制,类结构变更,对象引用,即时编译等复杂问题。在HotSwap被引进后至今,JCP也未能通过正式的字节码增强实现。
JAVA是一门静态语言,而字节码增强所要达的效果就是让Java像动态语言一样跑起来,无需重启服务器。下面我们介绍字节码增强的基本原理。
-
反射代理
反射代理不能直接修改内存方法区的字节码,但是可以抽象出一层代理,通过内存新增实例来实现类的更新
-
原生接口
jdk上层提供面向java语言的字节码增强接口java.lang.instrument,通过实现ClassFileTransformer接口来操作JVM方法区的类文件字节码。
-
JVMTI代理
JVM的JVMTI接口包含了操作方法区类文件字节码的函数,通过创建代理,将JVMTI的指针JavaVM传给代理,从而拥有JVM 本地操作字节码的方法引用。
-
类加载器织入
字节码增强接口加上类加载器的织入,结合起来也是一种热替换技术。
-
JVM增强
直接新增JVM分支,增加字节码增强功能。
8.2.3实现
但是尽管字节码增强是一门复杂的技术,这并不妨碍我们进一步的探索,下面我们介绍几种常见的实现方案。
-
Instrumentation
-
AspectJ
-
ASM
-
DCEVM
-
JREBEL
-
CGLIB
-
javassist
-
BCEL
具体的我会挑两个具有代表性的工具深入讲解,篇幅所限,这里就补展开了。
9.总结
JVM是程序发展至今的一颗隗宝,是程序设计和工程实现的完美结合。JVM作为作为三大工业级程序语言为首JAVA的根基,本文试图在瀚如烟海的JVM海洋中找出其中最耀眼的冰山,并力求用简洁的逻辑线索把各个冰山串起来,在脑海中对JVM的观感有更加立体的认识。更近一步的认识JVM对程序设计的功力提示大有裨益,而本文也只是将海平面上的冰山链接起来,但这只是冰山一角,JVM更多的底层设计和实现细节还远远没有涉及到,而且也不乏知识盲区而没有提及到的,路漫漫其修远兮,JVM本身也在不断的推陈出新,借此机会总结出JVM的核心体系,以此回顾对JVM知识的查漏补缺,也是一次JVM的认知升级。最后还是例牌来两张图结束JVM的介绍,希望对更的同学有帮助。

关注公众号《编程原理》,升级你的编程知识体系

正文到此结束
- 本文标签: 图片 description Master map 本质 Bootstrap synchronized 时间 微服务 parse 插件 volatile 同步 目录 core 编译 jstack 端口 scala git cache find 希望 安全 bug IDE 构造方法 需求 Agent 解析 组织 开发 Java类 src ssl 生命 cmd Transport ip ORM 科技 虚拟内存 政策 模型 数据 静态方法 代码 QPS HTML 敏捷 操作系统 java基础 lib 服务器 关键词 tab message tomcat bean swap HTTP协议 cat springboot 调试 Full GC GitHub 缓存 App 部署 list 解决方法 开源 client root 删除 源码 Job servlet tar 工作原理 进程 高可用 开发者 字节码 内存模型 cglib CTO 递归 value 参数 性能问题 build web http classpath 下载 占用空间 constant 垃圾回收 线程 分布式 UI JVM 多线程 Proxy 空间 加密 实例 快的 总结 example apache ECS 定制 文章 maven Service IO 数据库 id 配置 索引 API JDBC 设计模式 并发 URLs REST final 企业 java ask 翻译 Architect db Action js NIO Oracle 服务端 安装 token 管理 类加载器 注释 stream Document 软件 锁 jvisualvm spring 统计 协议 ACE remote Property https
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

