什么是JPA?Java Persistence API简介
作为规范, Java Persistence API 关注 持久性 ,它将Java对象的创建过程和具体的创建形式解耦。并非所有Java对象都需要持久化,但大多数应用程序都会保留关键业务对象。JPA规范允许您定义应该保留 哪些 对象,以及 如何 在Java应用程序中保留这些对象。
JPA本身不是一个工具或框架; 相反,它定义了一组可以由任何工具或框架实现的概念。虽然JPA的对象关系映射(ORM)模型最初基于 Hibernate ,但它已经发展了。同样,虽然JPA最初打算用于关系/ SQL数据库,但是一些JPA实现已经扩展用于NoSQL数据存储。支持JPA和NoSQL的流行框架是 EclipseLink ,它是JPA 2.2的参考实现。
JPA和Hibernate
由于它们交织在一起的历史,Hibernate和JPA经常混为一谈。但是,与 Java Servlet 规范一样,JPA产生了许多兼容的工具和框架; Hibernate只是其中之一。
Hibernate 由Gavin King开发,于2002年初发布,是一个用于Java的ORM库。King开发了Hibernate作为 持久化实体bean 的 替代品 。该框架非常受欢迎,当时非常需要,它的许多想法都在第一个JPA规范中被采用和编纂。
今天, Hibernate ORM 是最成熟的JPA实现之一,并且仍然是Java中ORM的流行选项。 Hibernate ORM 5.3.8 (撰写本文时的当前版本)实现了JPA 2.2。此外,Hibernate的工具系列已经扩展到包括 Hibernate Search , Hibernate Validator 和 Hibernate OGM 等流行工具,后者支持NoSQL的域模型持久性。
什么是Java ORM?
虽然它们的执行不同,但每个JPA实现都提供某种ORM层。为了理解JPA和JPA兼容的工具,您需要掌握ORM。
对象关系映射是一项 任务 - 开发人员有充分的理由避免手动执行。像Hibernate ORM或EclipseLink这样的框架将该任务编码为库或框架,即 ORM层 。作为应用程序体系结构的一部分,ORM层负责管理软件对象的转换,以便与关系数据库中的表和列进行交互。在Java中,ORM层转换Java类和对象,以便可以在关系数据库中存储和管理它们。
默认情况下,持久化对象的名称将成为表的名称,字段将成为列。设置表后,每个表行对应于应用程序中的对象。对象映射是可配置的,但默认值往往效果很好。
图1说明了JPA和ORM层在应用程序开发中的作用。
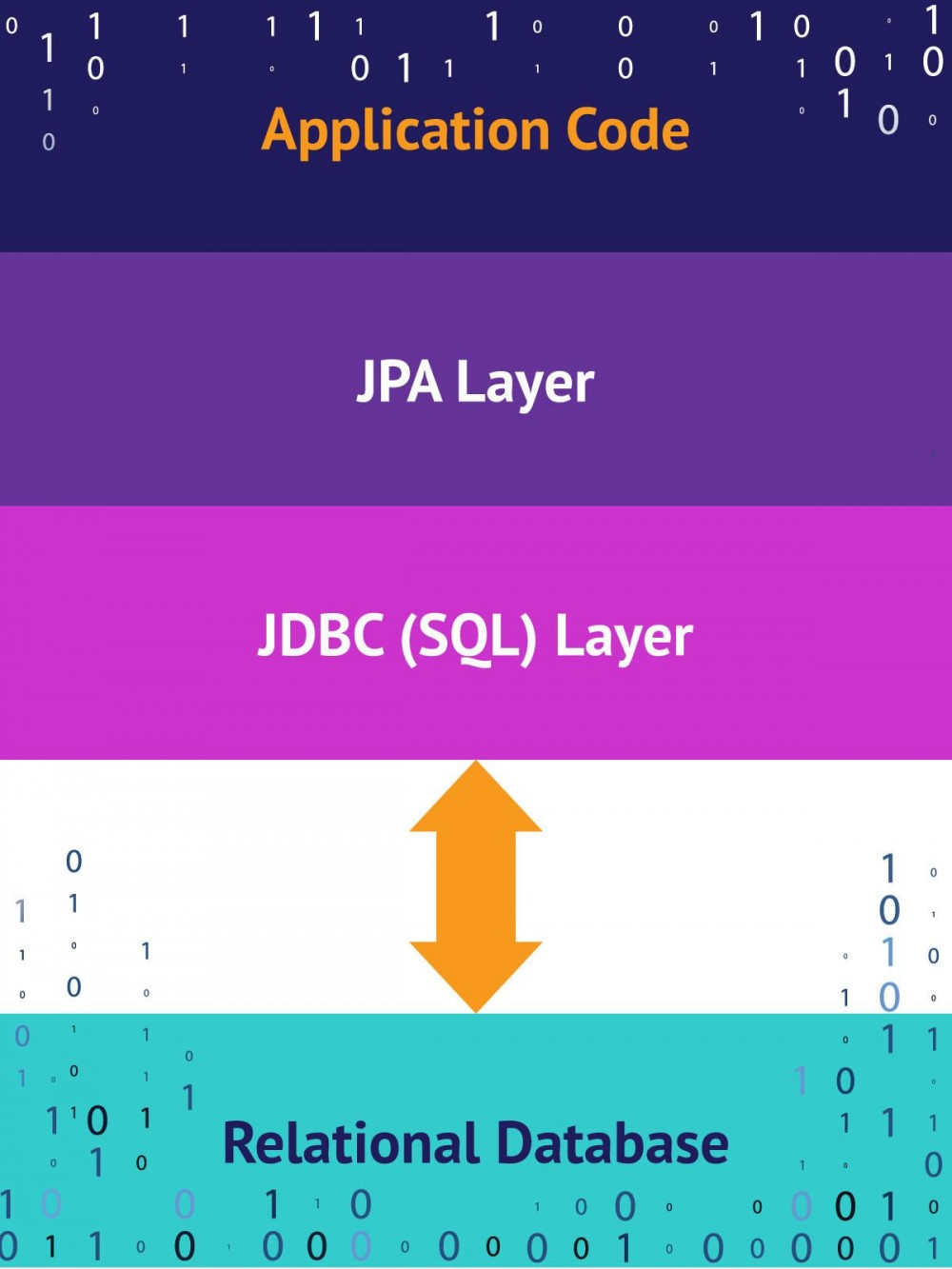
配置Java ORM层
设置新项目以使用JPA时,需要配置数据存储区和JPA提供程序。您将配置 数据存储连接器 以连接到您选择的数据库(SQL或NoSQL)。您还将包含和配置 JPA提供程序 ,它是一个框架,如Hibernate或EclipseLink。虽然您可以手动配置JPA,但许多开发人员选择使用Spring的开箱即用支持。有关手动和基于Spring的JPA安装和设置的演示,请参阅下面的“ JPA安装和设置 ”。
Java数据对象
Java Data Objects是一个标准化的持久性框架,它与JPA的不同之处主要在于支持对象中的持久性逻辑,以及它长期以来对使用非关系数据存储的支持。JPA和JDO足够相似,JDO提供者也经常支持JPA。请参阅 Apache JDO项目 ,以了解有关JDO与JPA和JDBC等其他持久性标准相关的更多信息。
Java中的数据持久性
从编程的角度来看,ORM层是一个 适配器层 :它使对象图的语言适应SQL和关系表的语言。ORM层允许面向对象的开发人员构建持久保存数据的软件,而无需离开面向对象的范例。
使用JPA时,可以创建从数据存储区到应用程序的数据模型对象的 映射 。您可以定义对象和数据库之间的映射,而不是定义对象的保存和检索方式,然后调用JPA来保存它们。如果您正在使用关系数据库,那么应用程序代码和数据库之间的大部分实际连接将由JDBC( Java数据库连接API)处理 。
作为规范,JPA提供 元数据注释 ,您可以使用它来定义对象和数据库之间的映射。每个JPA实现都为JPA注释提供了自己的引擎。JPA规范还提供了 PersistanceManager 或者 EntityManager ,它们是与JPA系统联系的关键点(其中您的业务逻辑代码告诉系统如何处理映射对象)。
为了使所有这些更具体,请考虑清单1,这是一个用于为音乐家建模的简单数据类。
清单1. Java中的一个简单数据类
public class Musician {
private Long id;
private String name;
private Instrument mainInstrument;
private ArrayList performances = new ArrayList<Performance>();
public Musician( Long id, String name){ /* constructor setters... */ }
public void setName(String name){
this.name = name;
}
public String getName(){
return this.name;
}
public void setMainInstrument(Instrument instr){
this.instrument = instr;
}
public Instrument getMainInstrument(){
return this.instrument;
}
// ...Other getters and setters...
}
清单1中的 Musician 类用于保存数据。它可以包含原始数据,例如 名称 字段。它还可以与其他类(如 mainInstrument 和 performances )保持关系。
Musician 存在的 原因 是包含数据。这种类有时称为DTO或 数据传输对象 。DTO是软件开发的常见功能。虽然它们包含多种数据,但它们不包含任何业务逻辑。持久化数据对象是软件开发中普遍存在的挑战。
JDBC的数据持久性
将 Musician 类的实例保存到关系数据库的一种方法是使用JDBC库。JDBC是一个抽象层,它允许应用程序发出SQL命令而无需考虑底层数据库实现。
清单2显示了如何使用JDBC 来持久化 Musician 类。
清单2.插入记录的JDBC
Musician georgeHarrison = new Musician(0, "George Harrison");
String myDriver = "org.gjt.mm.mysql.Driver";
String myUrl = "jdbc:mysql://localhost/test";
Class.forName(myDriver);
Connection conn = DriverManager.getConnection(myUrl, "root", "");
String query = " insert into users (id, name) values (?, ?)";
PreparedStatement preparedStmt = conn.prepareStatement(query);
preparedStmt.setInt (1, 0);
preparedStmt.setString (2, "George Harrison");
preparedStmt.setString (2, "Rubble");
preparedStmt.execute();
conn.close();
// Error handling removed for brevity
清单2中的代码是相当自我记录的。该 georgeHarrison 对象可以来自任何地方(前端提交,外部服务等),并设置其ID和name字段。然后,对象上的字段用于提供SQL insert 语句的值。( PreparedStatement 该类是JDBC的一部分,提供了一种将值安全地应用于SQL查询的方法。)
虽然JDBC允许手动配置附带的控件,但与JPA相比,它很麻烦。要修改数据库,首先需要创建一个SQL查询,该查询从Java对象映射到关系数据库中的表。然后,只要对象签名发生更改,就必须修改SQL。使用JDBC,维护SQL本身就成了一项任务。
JPA的数据持久性
现在考虑清单3,我们使用JPA 持久化 Musician 类。
清单3.使用JPA保留George Harrison
Musician georgeHarrison = new Musician(0, "George Harrison"); musicianManager.save(georgeHarrison);
清单3用一行 session.save() 替换了清单2中的手动SQL ,它指示JPA持久保存该对象。从那时起,SQL转换由框架处理,因此您永远不必离开面向对象的范例。
JPA中的元数据注释
清单3中的魔力是 配置 的结果,该 配置 是使用JPA的 注释 创建的。开发人员使用注释来告知JPA应该保留哪些对象,以及如何保留它们。
清单4显示了具有单个JPA注释的 Musician 类。
清单4. JPA的@Entity注释
@Entity
public class Musician {
// ..class body
}
持久对象有时称为 实体 。附加 @Entity 到类, Musician 告知JPA应该保留此类及其对象。
配置JPA
与大多数现代框架一样,JPA 遵循约定编码 (也称为约定优于配置),其中框架提供基于行业最佳实践的默认配置。作为一个示例,名为 Musician 的类将默认映射到名为 Musician 的数据库表。
传统配置是节省时间的,并且在许多情况下它运行良好。也可以自定义JPA配置。例如,您可以使用JPA的 @Table 注释来指定应该存储 Musician 类的表。
清单5. JPA的@Table注释
@Entity
@Table(name="musician")
public class Musician {
// ..class body
}
清单5告诉JPA将实体( Musician 类)持久化到 musician 表中。
主键
在JPA中, 主键 是用于唯一标识数据库中每个对象的字段。主键可用于引用对象并将对象与其他实体相关联。每当您在表中存储对象时,您还将指定要用作其主键的字段。
在清单6中,我们告诉JPA要使用哪个字段作为 Musician 主键。
清单6.指定主键
@Entity
public class Musician {
@Id
private Long id;
在这种情况下,我们使用JPA的 @Id 注释将 id 字段指定为 Musician 主键。默认情况下,此配置假定主键将由数据库设置 - 例如,当字段设置为在表上自动递增时。
JPA支持生成对象主键的其他策略。它还有用于更改单个字段名称的注释。通常,JPA足够灵活,可以适应您可能需要的任何持久性映射。
CRUD操作
将类映射到数据库表并建立其主键后,即可拥有在数据库中创建,检索,删除和更新该类所需的一切。调用 session.save() 将创建或更新指定的类,具体取决于主键字段是否为null或是否适用于现有实体。调用 entityManager.remove() 将删除指定的类。
JPA中的实体关系
简单地使用原始字段持久化对象只是方程式的一半。JPA还具有管理彼此相关实体的能力。在表和对象中都有四种实体关系:
- 一到多
- 许多到一
- 许多一对多
- 一比一
每种类型的关系描述了实体与其他实体的关系。例如, Musician 实体可以与由诸如 List 或 Set 的集合表示的实体具有 一对多的关系 。
如果 Musician 包含一个 Band 字段,这些实体之间的关系可以是 多对一的 ,这意味着在单个 Band 类上有 Musician集合 。(假设每个音乐家只在一个乐队中演奏。)
如果 Musician 包含 BandMates 字段,则可以表示与其他 Musician 实体 的多对多关系 。
最后, Musician 可能与 Quote 实体有 一对一的关系 ,用于表示一个着名的引语: Quote famousQuote = new Quote() 。
定义关系类型
JPA为每种关系映射类型提供注解。清单7显示了如何注解 Musician 和 Performance s 之间的一对多关系。
清单7.注释一对多关系
public class Musician {
@OneToMany
@JoinColumn(name="musicianId")
private List<Performance> performances = new ArrayList<Performance>();
//...
}
需要注意的一点是 @JoinColumn 告诉JPA Performance 表上的哪一列将映射到 Musician 实体。每个performance都将与单个 Musician 关联,该列由此列跟踪。当JPA将一个 Musician 或一个 Performance 加载到数据库中时,它将使用此信息重新构建对象图。
在JPA中获取策略
除了知道 在 数据库中放置相关实体的位置之外,JPA还需要知道 如何 加载它们。 获取策略 告诉JPA如何加载相关实体。加载和保存对象时,JPA框架必须能够微调对象图的处理方式。例如,如果 Musician 类有一个 bandMate 字段(如清单7所示),加载 george 可能导致整个 Musician 表从数据库加载!
我们需要的是定义相关实体的 延迟加载 的能力- 当然,认识到 JPA 中的 关系可能是eager或 lazy的。您可以使用注释来自定义提取策略,但JPA的默认配置通常可以直接使用,无需更改:
- 一对多:lazy
- 多对一:eager
- 多对多:lazy
- 一对一:eager
JPA安装和设置
最后,我们将简要介绍如何为Java应用程序安装和设置JPA。在本演示中,我将使用EclipseLink,即JPA参考实现。
安装JPA的常用方法是在项目中 包含 JPA提供程序。清单8显示了如何将EclipseLink作为Maven pom.xml 文件中的依赖项包含在内。
清单8.将EclipseLink包含为Maven依赖项
org.eclipse.persistence eclipselink 2.5.0-RC1
您还需要包含数据库的驱动程序,如清单9所示。
清单9. MySql连接器的Maven依赖关系
mysql mysql-connector-java 5.1.32
接下来,您需要告诉系统您的数据库和提供程序。这在 persistence.xml 文件中完成,如清单10所示。
清单10. Persistence.xml
http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd"> <persistence-unit name="MyUnit" transaction-type="RESOURCE_LOCAL"> <properties> <property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/foo_bar"/> <property name="javax.persistence.jdbc.user" value=""/> <property name="javax.persistence.jdbc.password" value=""/> <property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/> </properties> </persistence-unit> </persistence>
还有其他方法可以向系统提供此信息,包括以编程方式。我建议使用该 persistence.xml 文件,因为以这种方式存储依赖项使得在不修改代码的情况下更新应用程序非常容易。
清单10. Persistence.xml
http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd"> <persistence-unit name="MyUnit" transaction-type="RESOURCE_LOCAL"> <properties> <property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/foo_bar"/> <property name="javax.persistence.jdbc.user" value=""/> <property name="javax.persistence.jdbc.password" value=""/> <property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/> </properties> </persistence-unit> </persistence>
还有其他方法可以向系统提供此信息,包括以编程方式。我建议使用该 persistence.xml 文件,因为以这种方式存储依赖项使得在不修改代码的情况下更新应用程序非常容易。
JPA的Spring配置
使用Spring将极大地简化JPA与应用程序的集成。例如,将 @SpringBootApplication 注释放在应用程序头中会指示Spring 根据您指定的配置自动扫描类并根据需要注入 EntityManager 。
如果您希望Spring为您的应用程序提供JPA支持,清单11显示了要包含的依赖项。
清单11.在Maven中添加Spring JPA支持
org.springframework.boot
spring-boot-starter
2.1.3.RELEASE
org.springframework.boot
spring-boot-starter-data-jpa
2.1.3.RELEASE
结论
处理数据库的每个应用程序都应该定义一个应用程序层,其唯一目的是隔离持久性代码。正如您在本文中看到的,Java Persistence API引入了一系列功能并支持Java对象持久性。简单的应用程序可能不需要JPA的所有功能,在某些情况下,配置框架的开销可能不值得。然而,随着应用程序的增长,JPA的结构和封装确实能够保持不变。使用JPA可以简化目标代码,并提供用于访问Java应用程序中的数据的传统框架。
英文原文: https://www.javaworld.com/article/3379043/what-is-jpa-introduction-to-the-java-persistence-api.html
正文到此结束
- 本文标签: value src Persistence validator root struct NOSQL 代码 Connection neToMany id 适配器 apache ip sql API XML Java类 JPA 希望 Statement java servlet 安全 管理 实例 开发 数据模型 IO JDBC spring eclipse cat NSA HTML 一对多 Word ORM ArrayList mysql pom 数据库 数据 App REST 删除 bean session maven tar UI CTO 软件 http Action 模型 db 配置 注释 list entity Property springboot tab https 安装 时间
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

